

This blog is used to note down all the knowledge I’ve learned in this lesson.
Here is some links to this lesson.
Home Page ( fall 2020 version )
Textbook:
- P&H: 采用Patterson和Hennessy合著的《Computer Organization and Design RISC-V Edition book 》中文翻译《计算机组成与设计:RISC-V版》第一版(简称“P&H”)——fall 2020 的课 程推荐的是第一版目前最新版本是第二版。
- K&R: 使用Kernighan和Ritchie所著 《The C Programming Language》 中文翻译《C程序设计语言》第二版(简称“K&R”),并在阅读作业中引用其章节。若你已熟悉其他书籍,也可选用,但我们的授课将基于K&R内容。
- WSC: 最后,我们将参考《The Datacenter as a Computer: An Introduction to the Design of Warehouse-Scale Machines》中文翻译《数据中心即计算机:仓库级机器设计导论》(简称“WSC”)。
Video:
使用B站上的中英版本
My Repo:github
(lec 01) Introduction
lec01-Great Ideas in Computer Architecture, Intro
CS61C: Learn 6 great ideas in computer architecture to enable high performance programming via parallelism, not just learn C
计算机体系结构历史上6个重要的idea
- Abstraction (Layers of Representation / Interpretation)
- Moore’s Law
- Principle of Locality/Memory Hierarchy
- Parallelism
- Performance Measurement and Improvement
- Dependability via Redundancy
在这里我们把一些课程中非常重要的图放在这儿,可以说是对每个版块的总结:
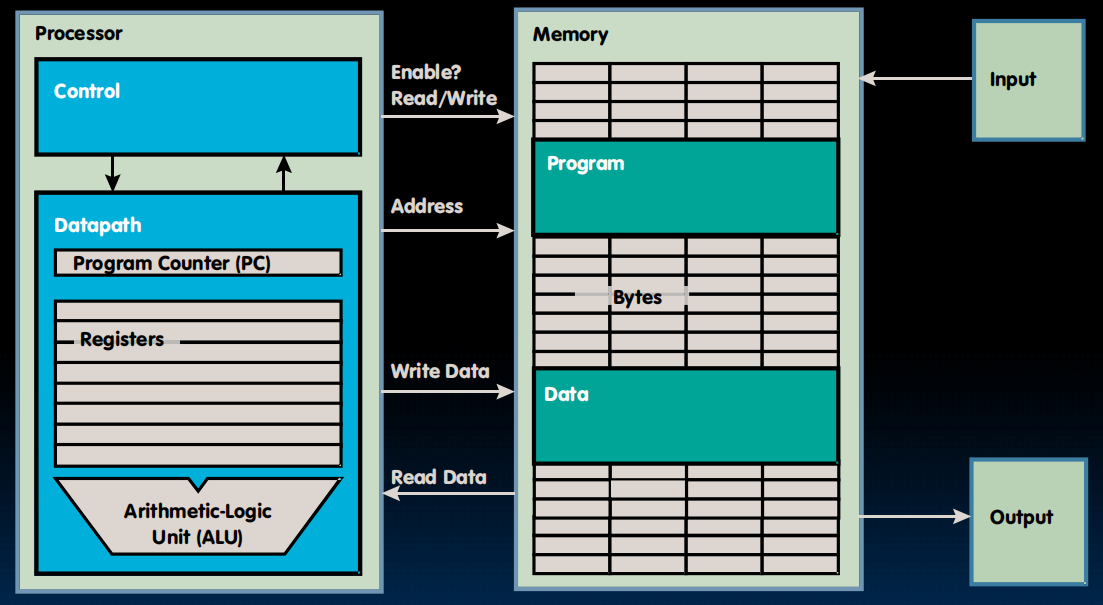
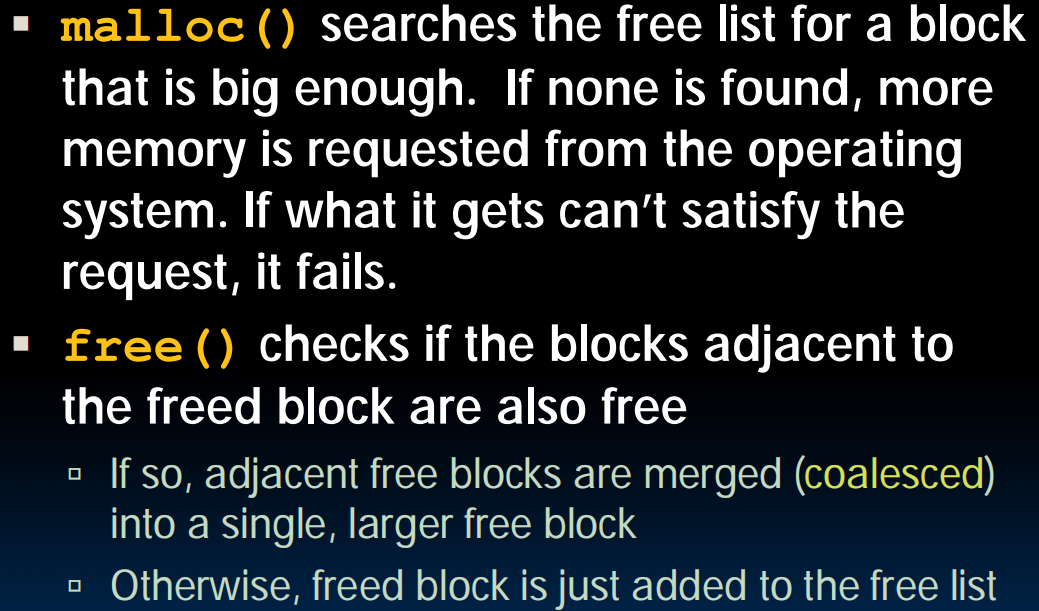
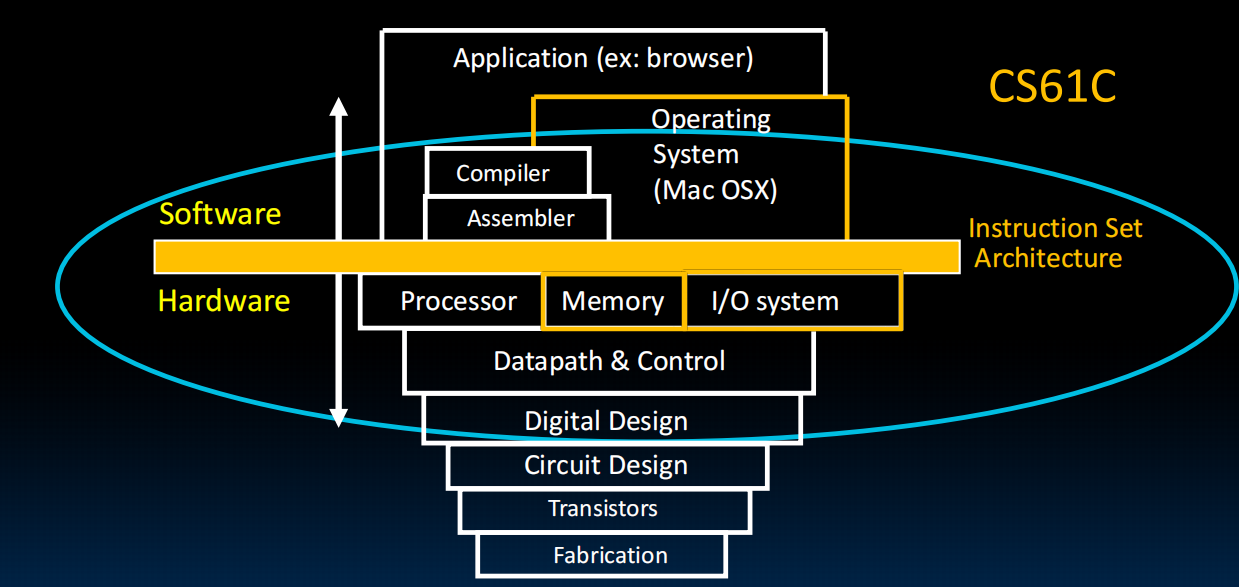
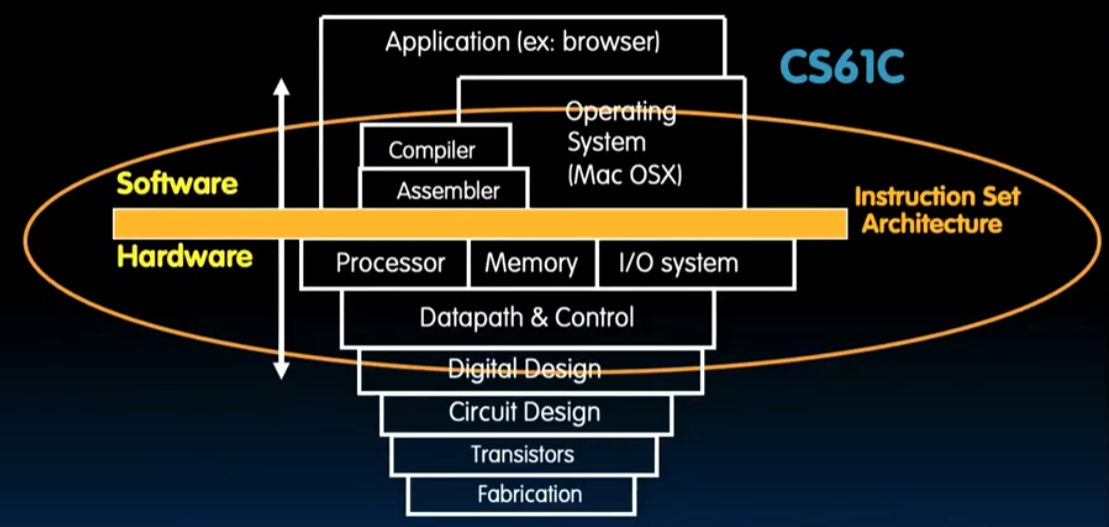
RISC-V、计算机组成、Registers、Memory的交互、IO:
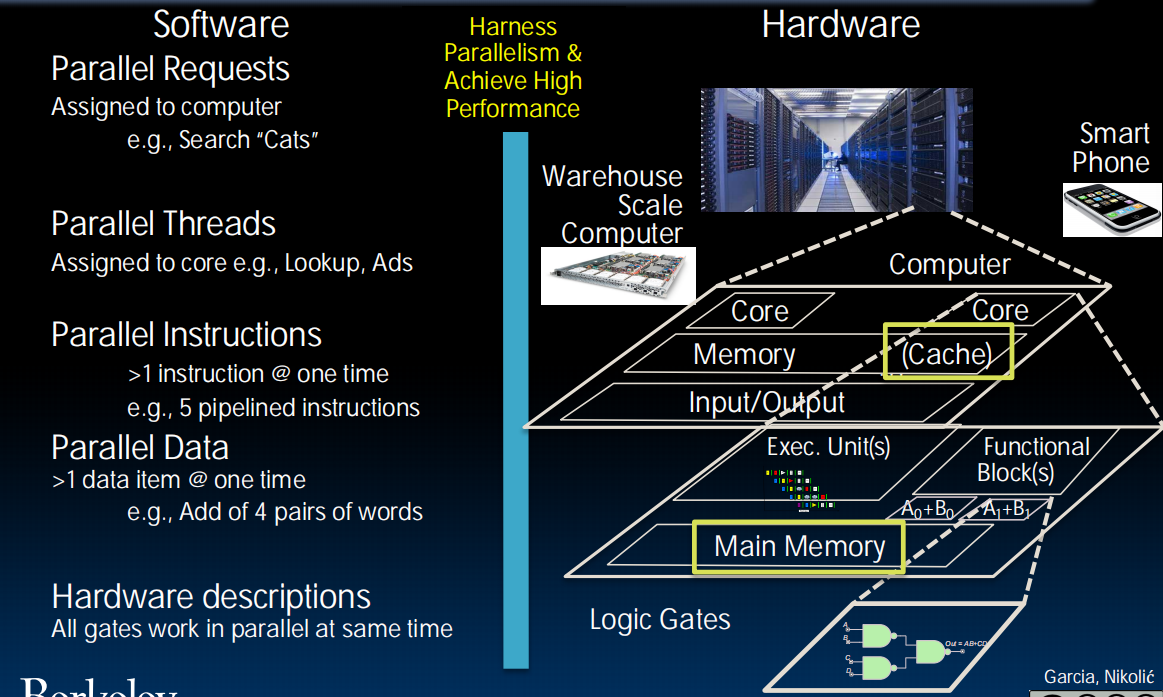
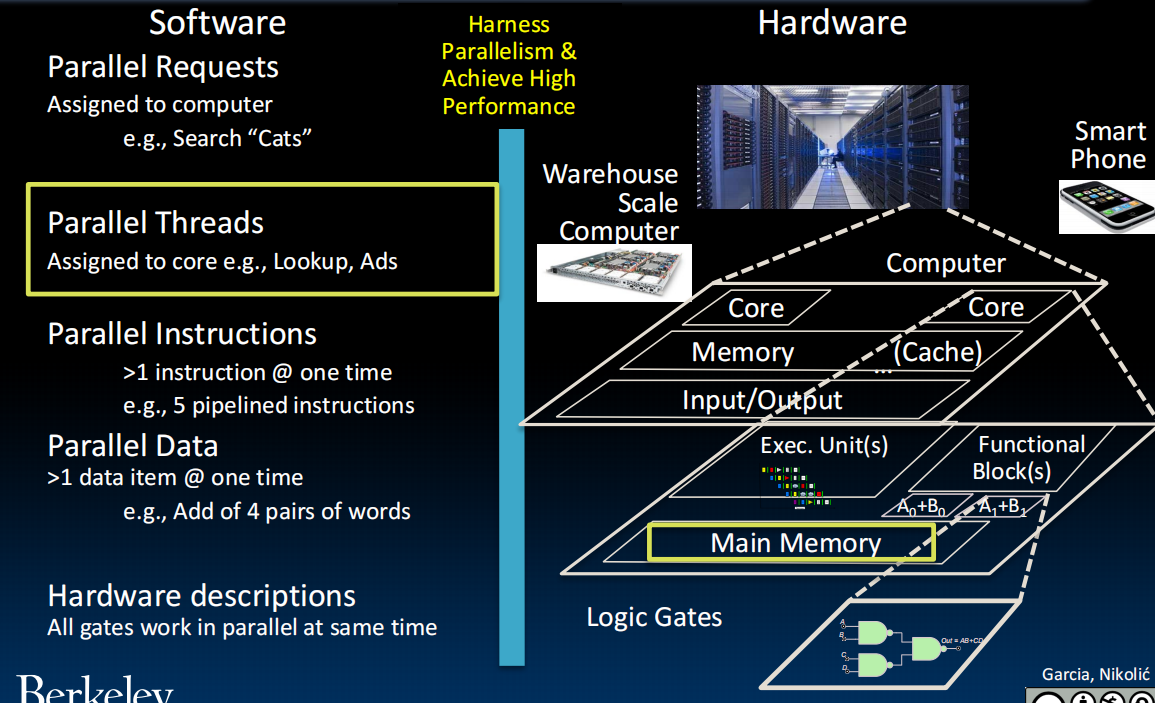
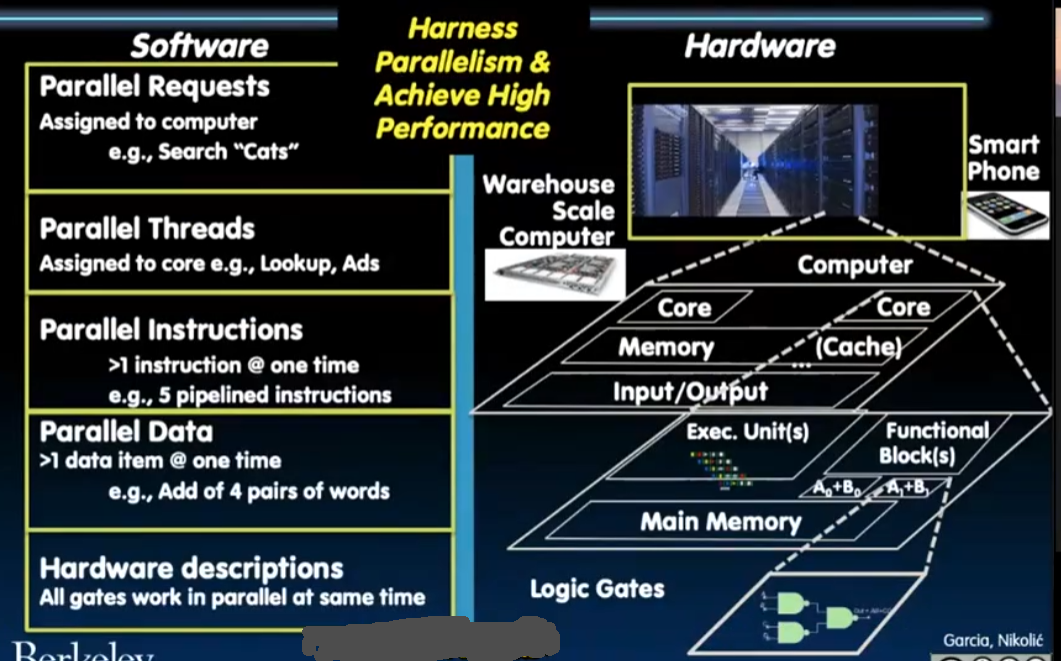
Parallelism软硬件的并行架构:
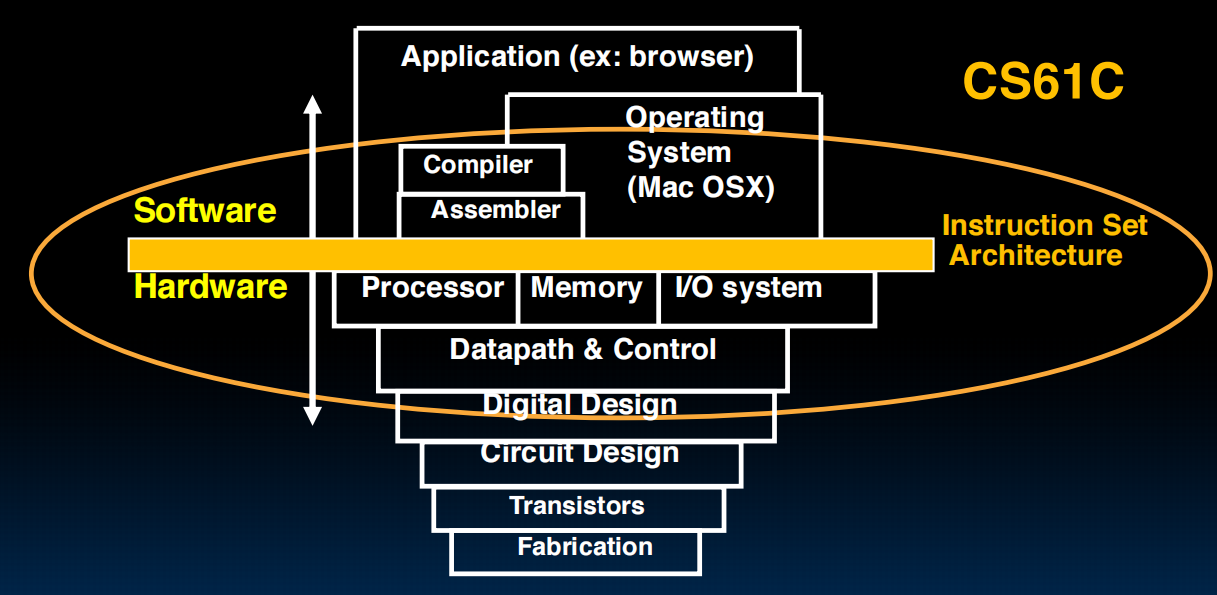
体系结构:
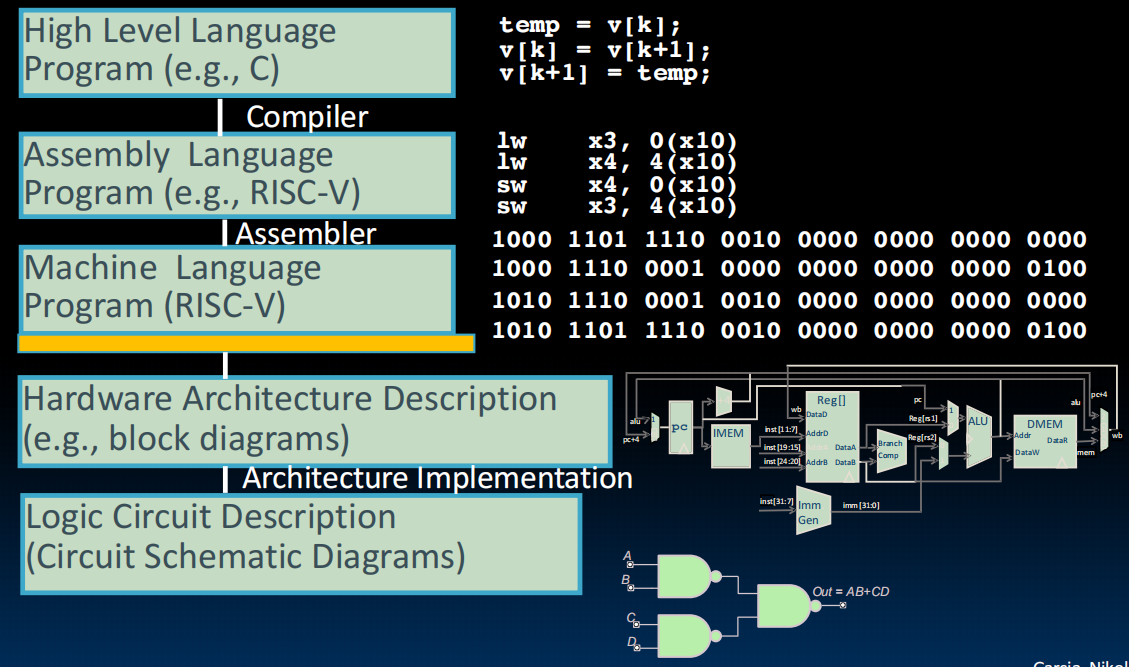
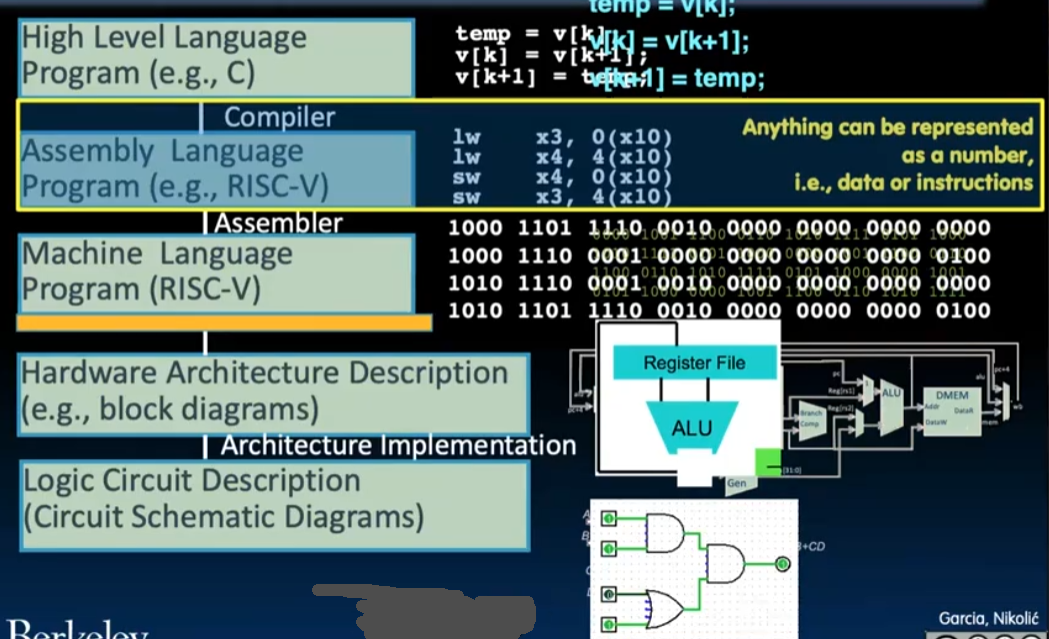
从高级语言到汇编到处理器到电路:
CPU Datapath:(未加流水线及其Hazard版本)
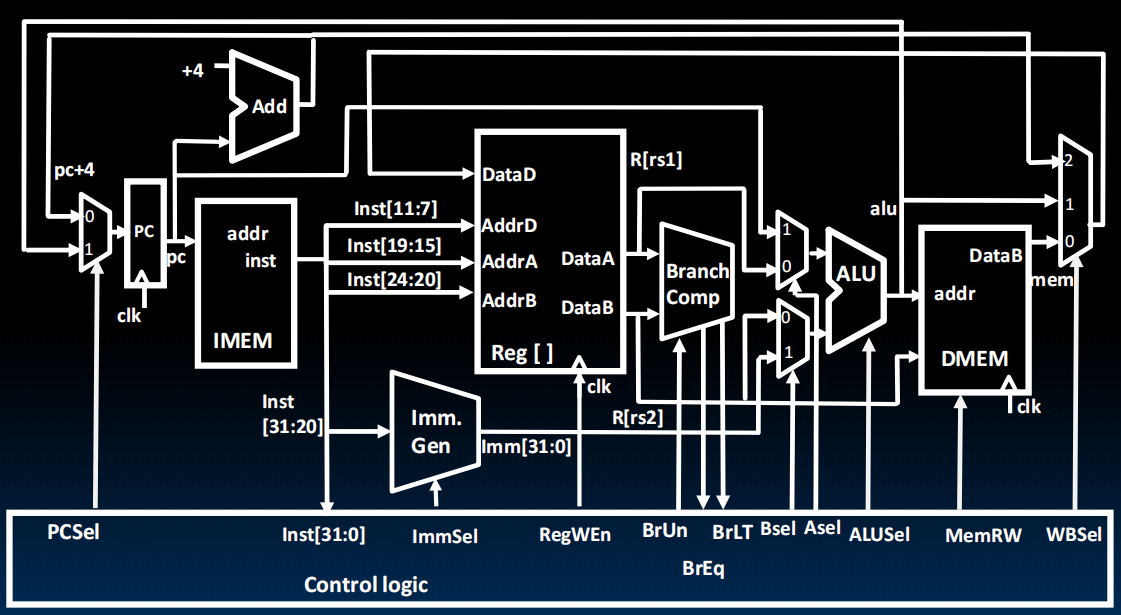
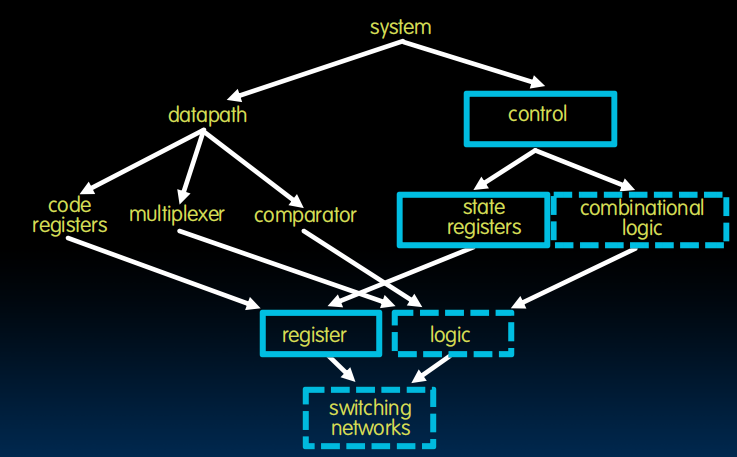
从开关到register到状态机、逻辑、control到整个系统
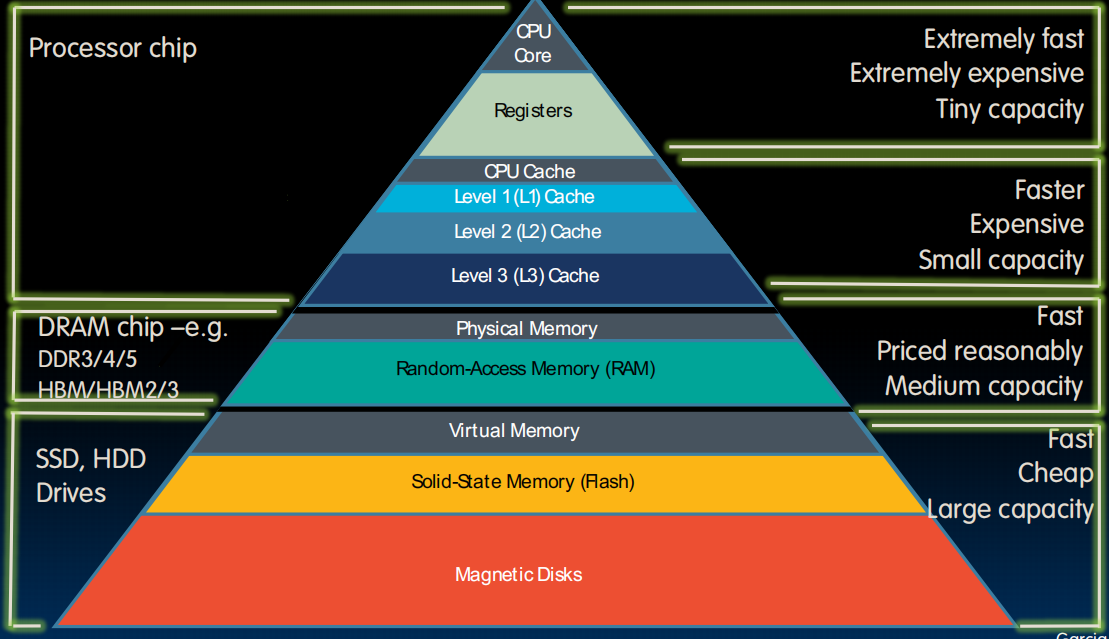
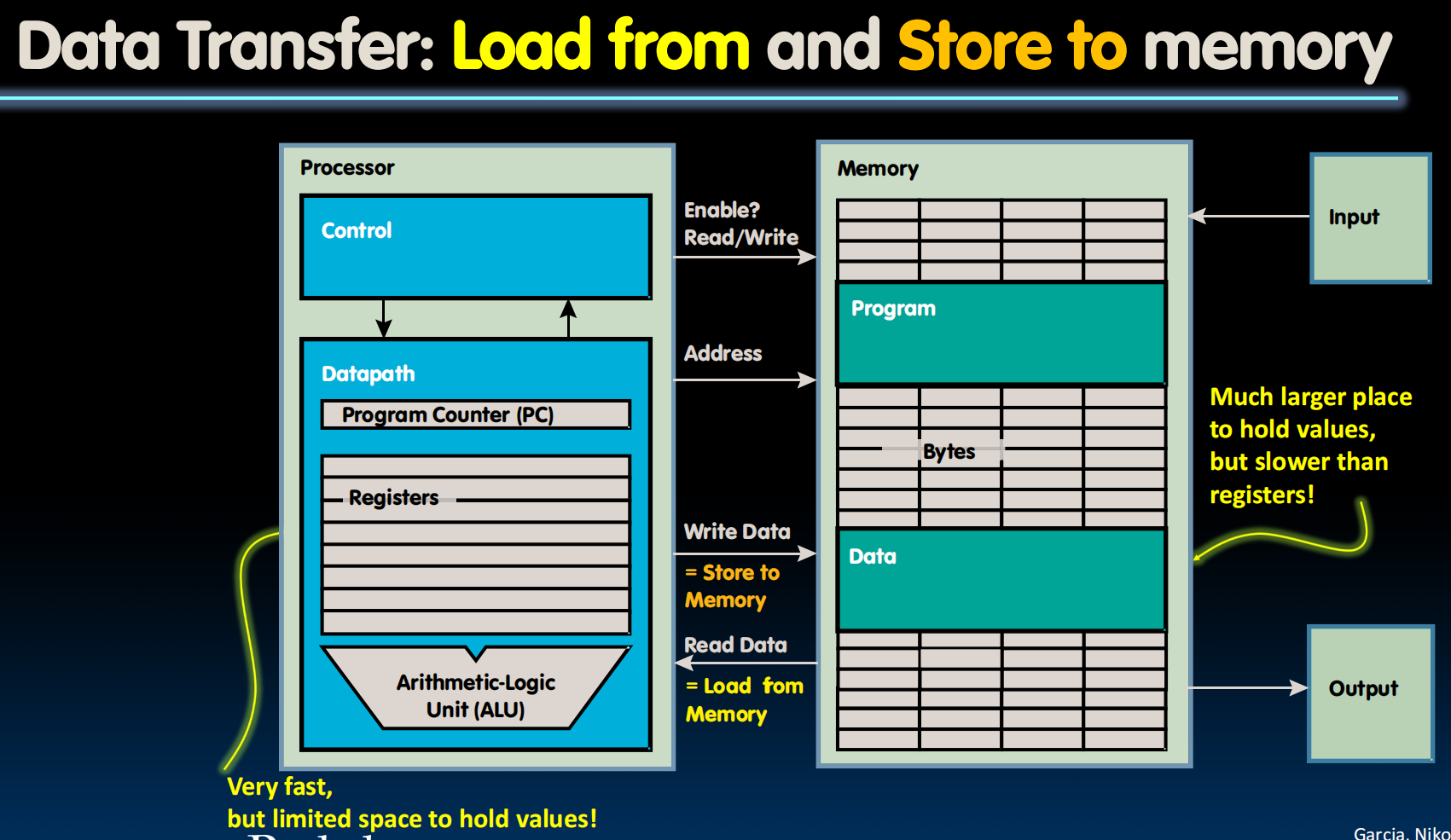
Memory Hierarchy(分级存储器体系)
(lec02~06) C Language Introduction
lec02-Number Representation

lec03~05-Introduction to C



p: 指针变量存储的内容 (一个地址)
*p: 指针指向的地址里的内容 (一个值)
&p: 存储指针变量p本身的地址

堆的内存可能会碎片化,由一个个块构成的循环链表。malloc在链表中找足够大的块,free释放并把连续的内存块合起来。比较慢


lec06-Floating Point



float:加法不可交换、precision:精度,accuracy:准确度,rounding(舍入)
Unum:标识是否是准确表示
(lec 07~13) RISC-V ISA
lec07-RISC-V Intro

Registers在CPU旁边,数量少,比如RISC-V只有32个寄存器,所以速度极快——<0.25ns
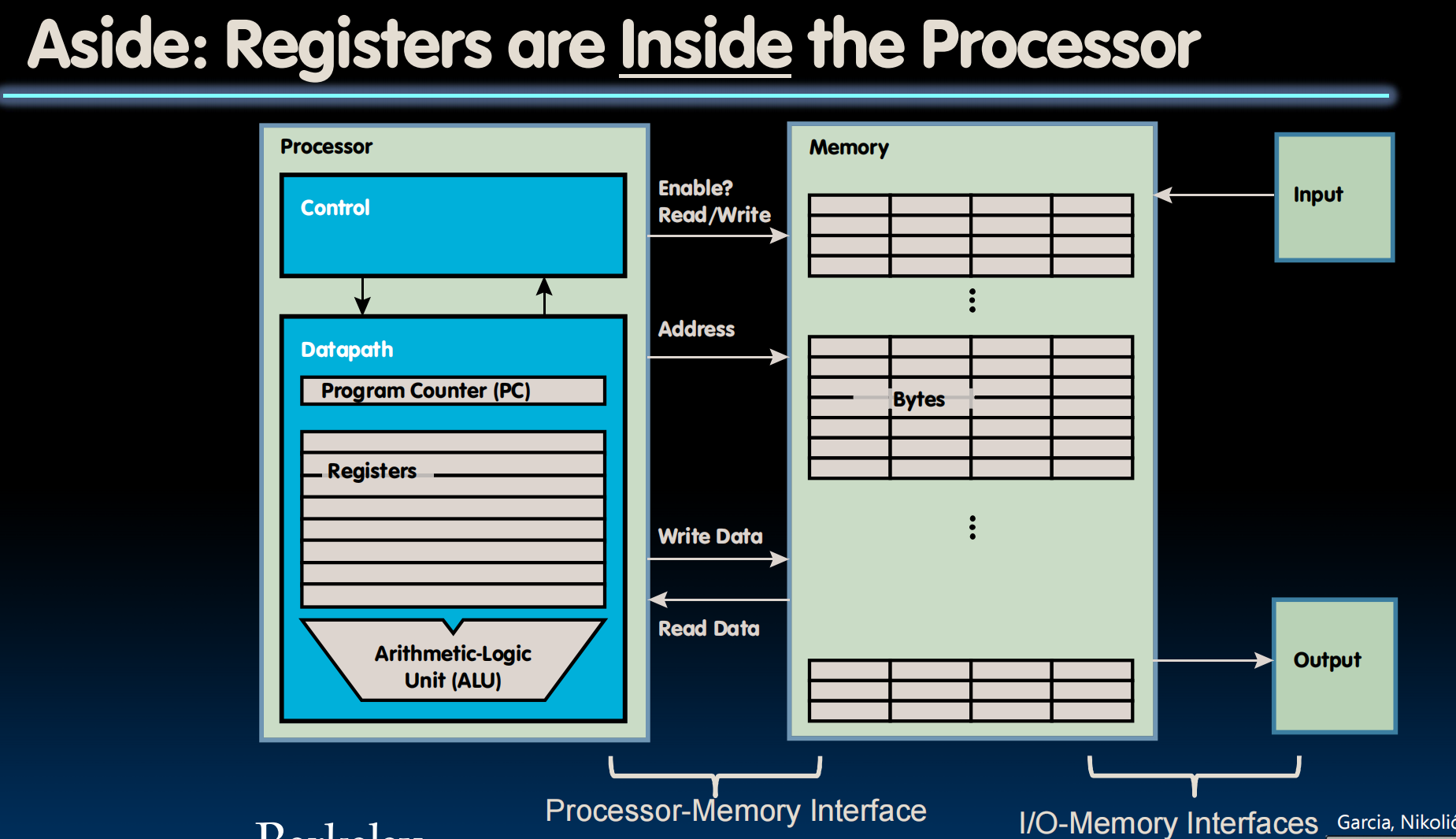
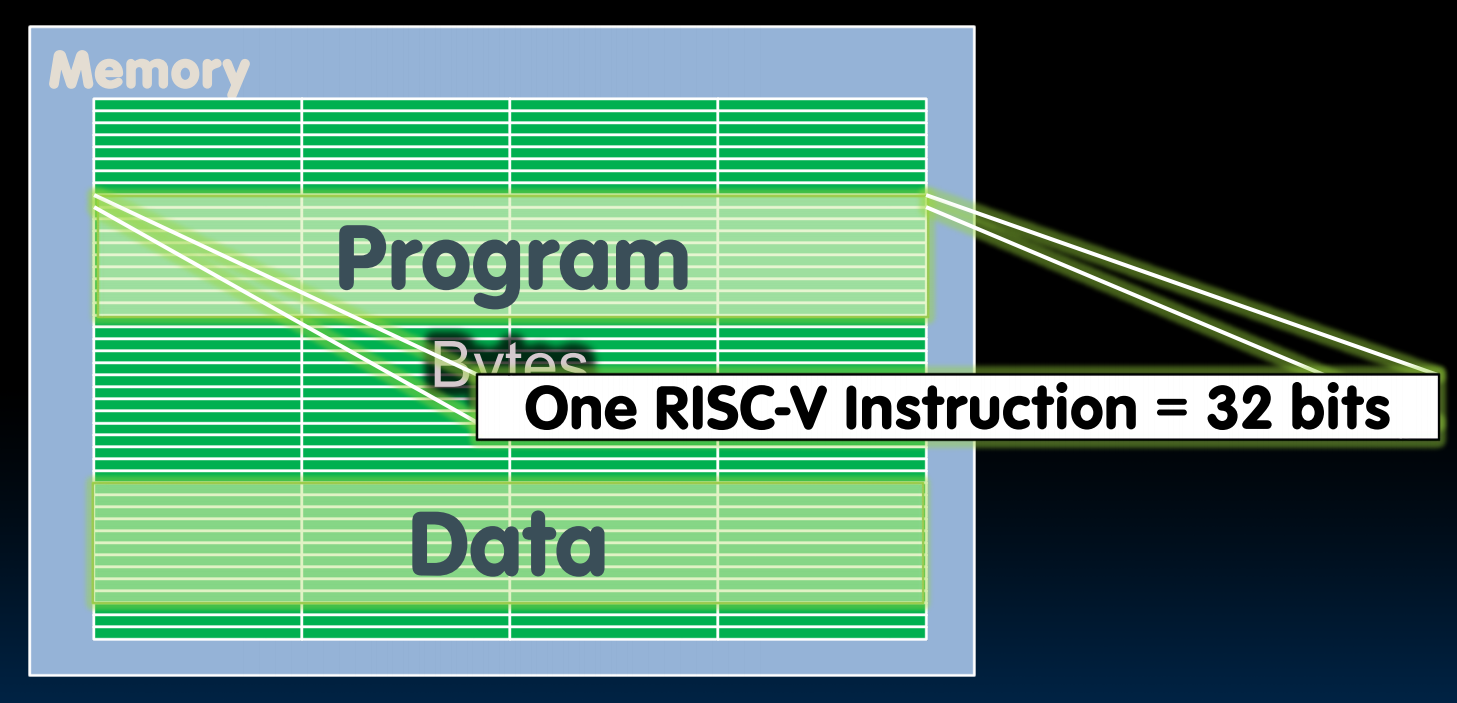
每个RISC-V是32bits长的,一个32bits长称为一个word
32个Register,x0~x31,x0始终保持0
Instructions


lec08-RISC-V lw, sw, Decisions I
8bit称为一个byte,1word=4bytes

DRAM:单个存取比Registers慢50~500倍,但连续的取多个会快一些
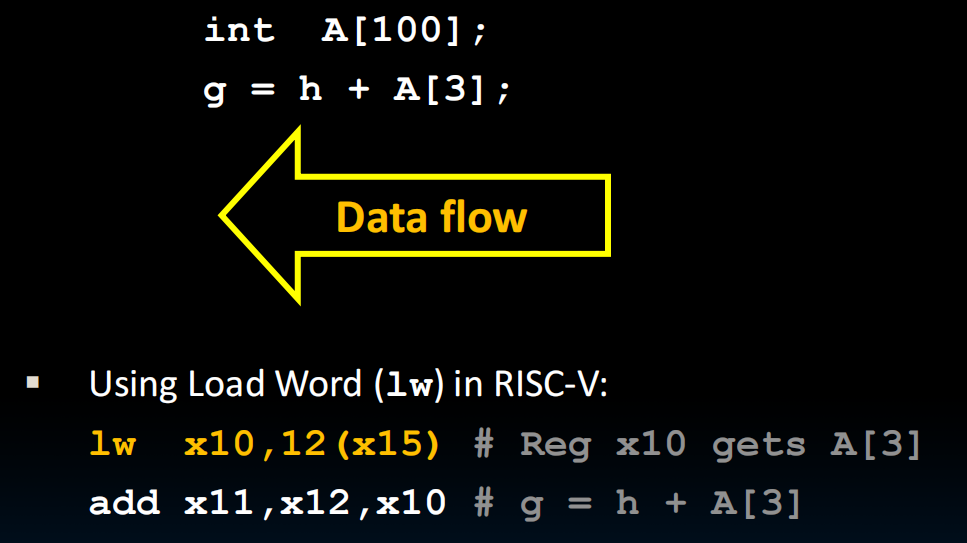
lw x10 , 12(x15)指的是:x15存了A数组的地址(DRAM中的),然后lw的时候取出x15中写着的这个Memory地址,然后偏移12位,此时这个地址就指向了A[3]的位置。
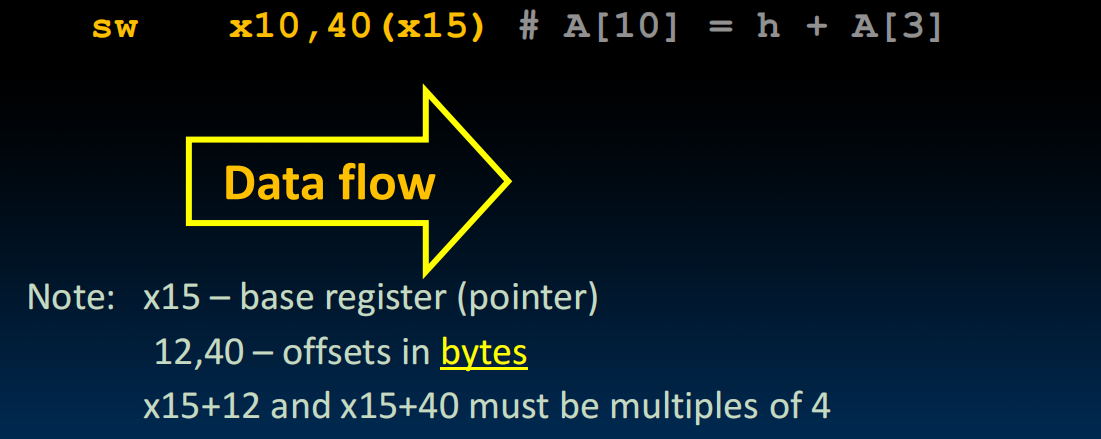
同样的,sw

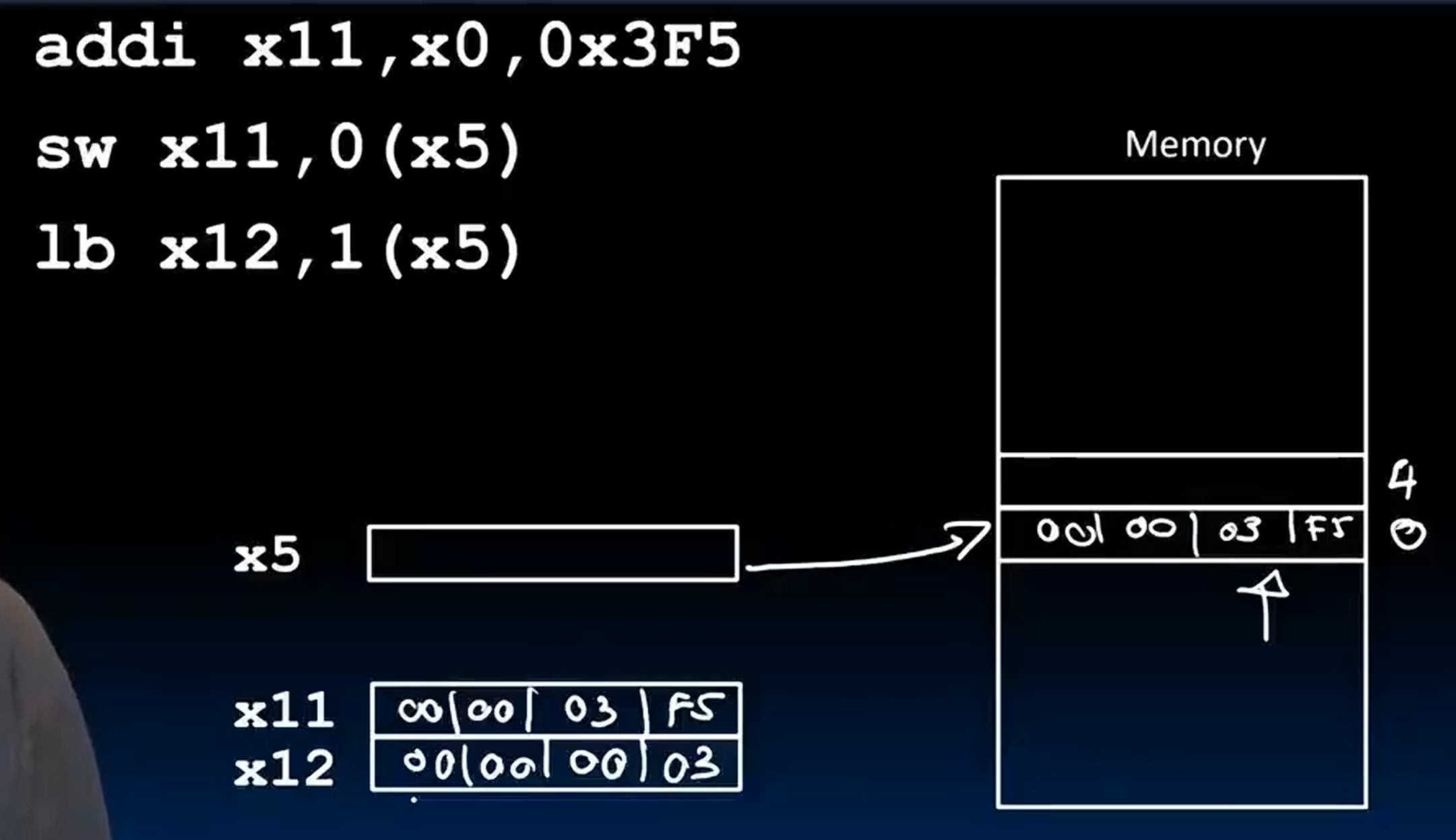
这是对于byte的存取。由于我们平时存取的都是signed byte,所以需要符号拓展,把byte的最高位复制到更高的24位上,构成32位放到目标的register。同样的,我们也可以使用lbu不拓展。sb由于是存储,不会拓展。
举例:
Decision making:


blt/bge:把后两个reg中的值当成有符号数来比较(比较补码),bltu/bgeu:当成无符号数比较
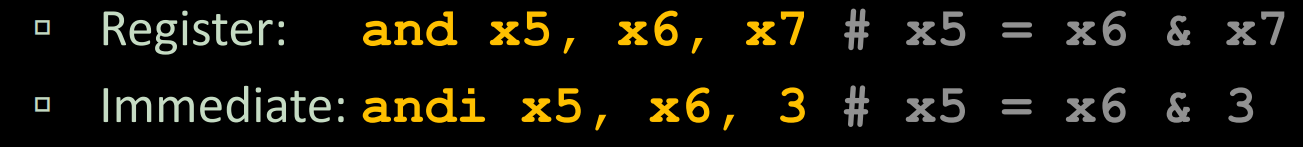



写好的Machine Program是怎么运行的?
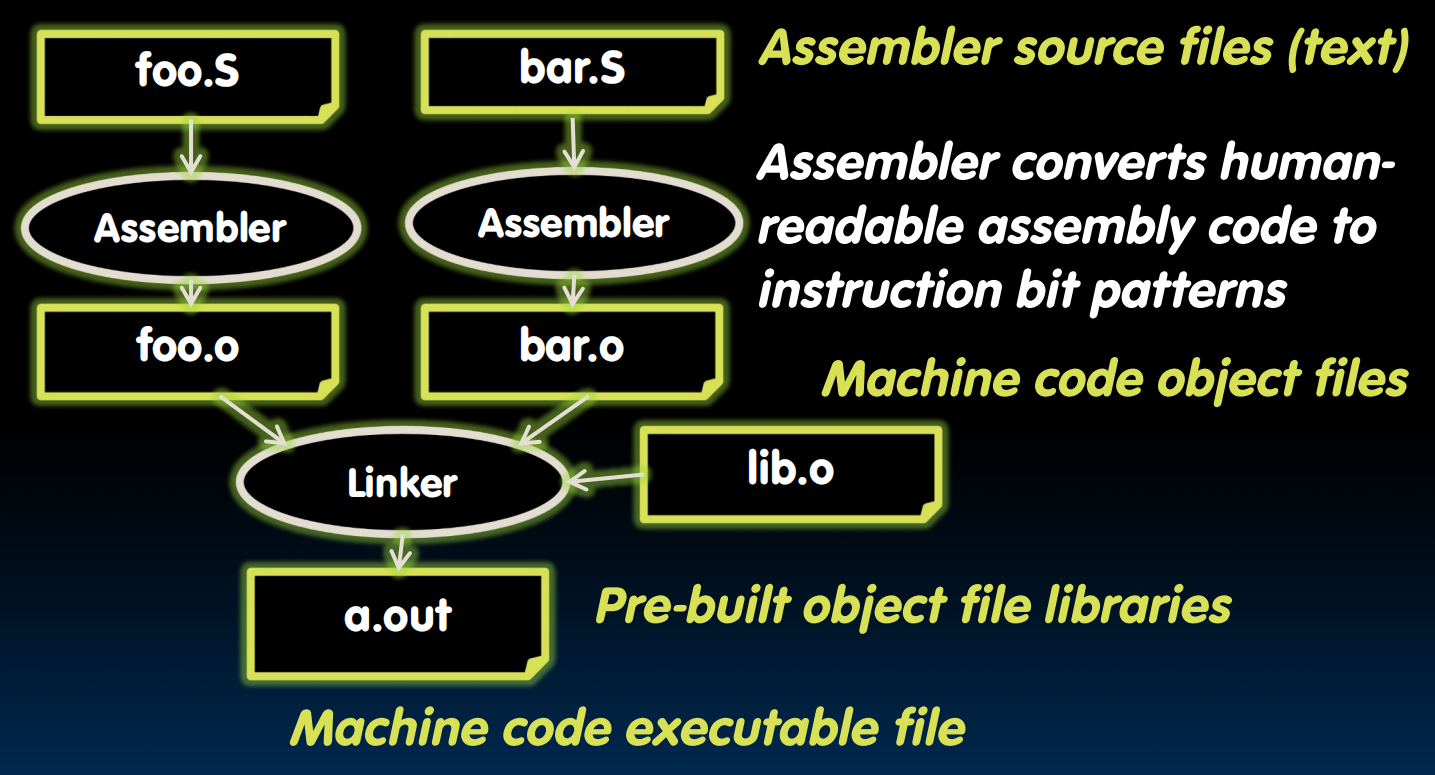
a.out存在memory的一个单独区域
简化:(伪指令)

函数的编码:

j和jr:j是在编译的时候写好的指令,比如Loop: … j Loop
jr跳到一个register中存的地址,比如
1 | 1008 addi ra,zero,1016 |
整合为一个jal


函数调用的流程:
函数需要存一些参数等等,所以需要用栈。sp作为栈指针指向栈内存最后的地方。
x0放zero,x1放函数return的地方,x2放sp的地址

于是在调用函数的时候就可以如下图(prelogal->调用->epilogal->return)(s0,s1存函数计算过程中需要的东西,首先把s0,s1中的东西拿出去存在栈里,然后在函数调用的时候就可以用s0,s1来运算了,运算完再把s0,s1的东西从栈放回来并且把栈的指针挪回去即可)
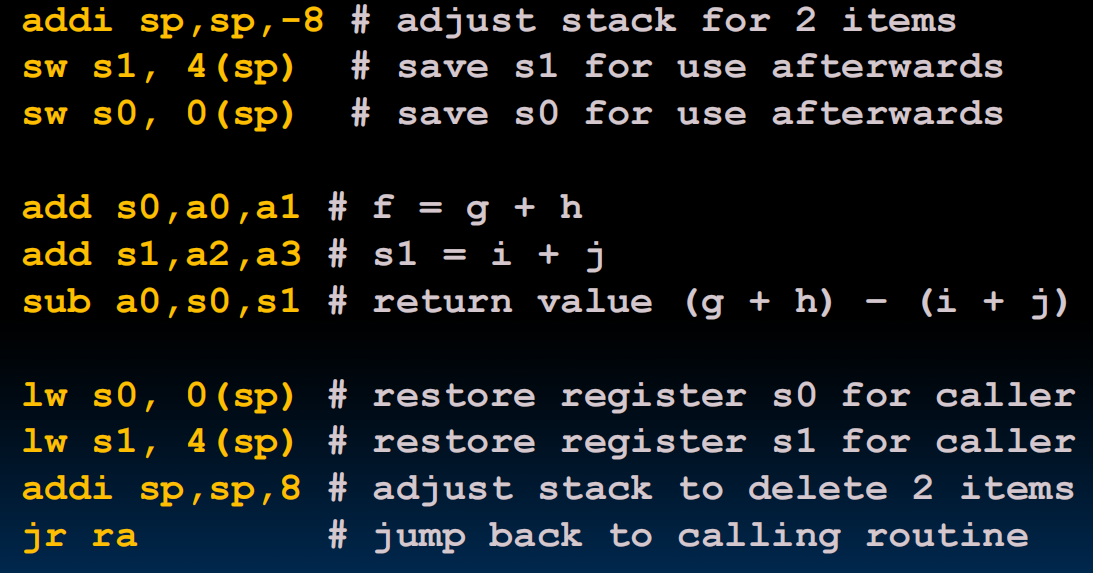
单层的函数调用会了,但多层的呢?nested function call
Caller:调用程序,Callee:被调用程序
比如,当我的一个函数要调用另一个函数的时候,a0,a1…,ra(x1)会被覆盖,怎么办?将32个register分为两类:preserved:安全的 和 not preserved:不安全的

给出所有的register的命名,右侧指出了这个register应该由谁来保存:

于是nested函数调用便是这样:
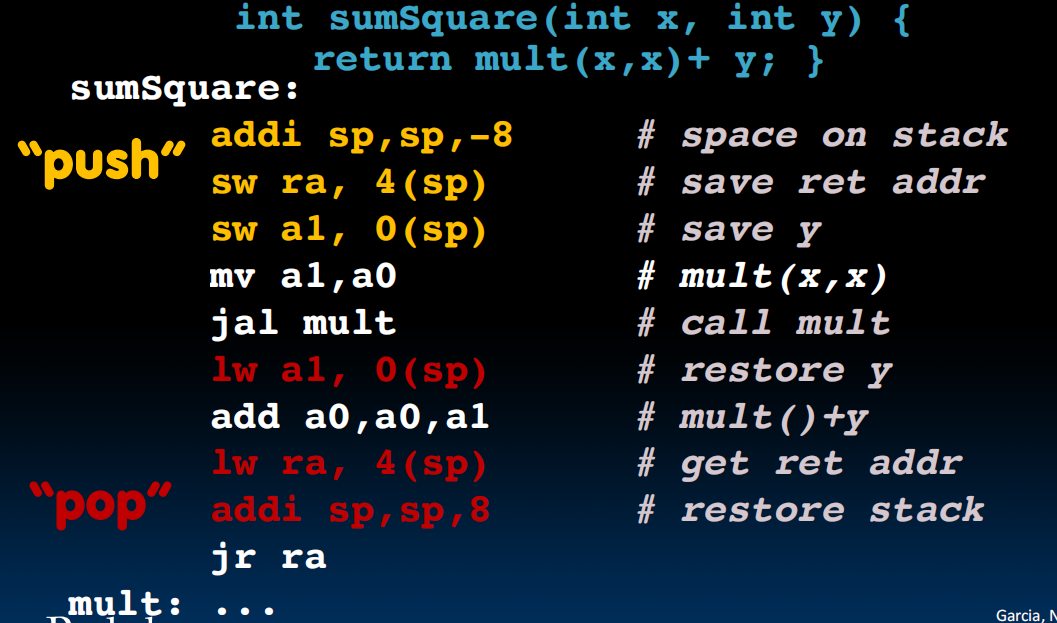
memory allocation:
lec11-RISC-V Instruction Formats I

history:ENIAC->EDSAC->
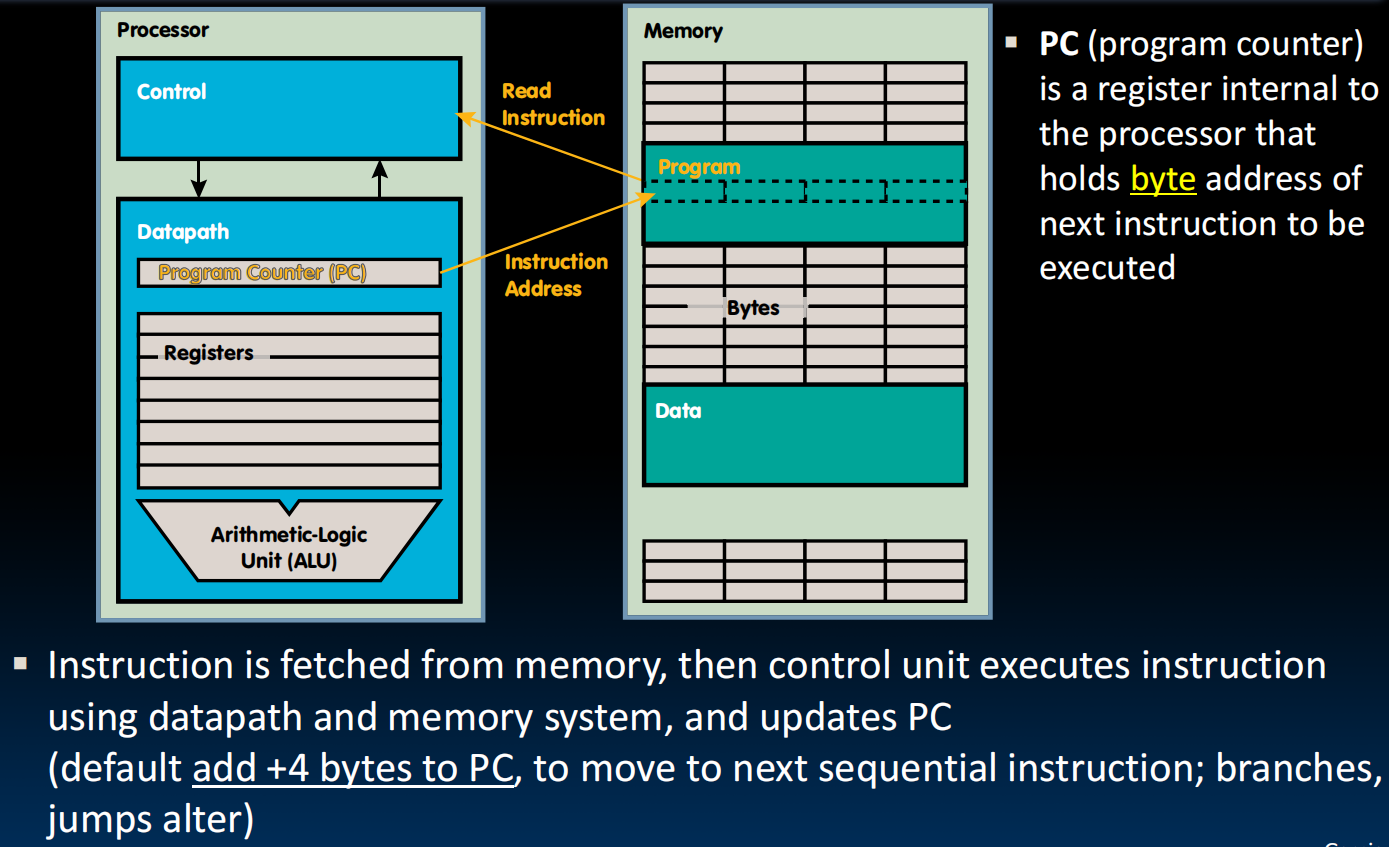
Since all instructions and data are stored in memory, everything has a memory address: instructions, data words
Program Counter(PC)持有执行的指令的地址(Instruction Pointer)


32位的指令数字分为若干field,每一个field告诉计算机是什么类型的指令(上图)


soga. rd是register destination的意思,rs 是register sources的意思
opcode是大类,funct3 , funct7是特定的指令代码
例子:

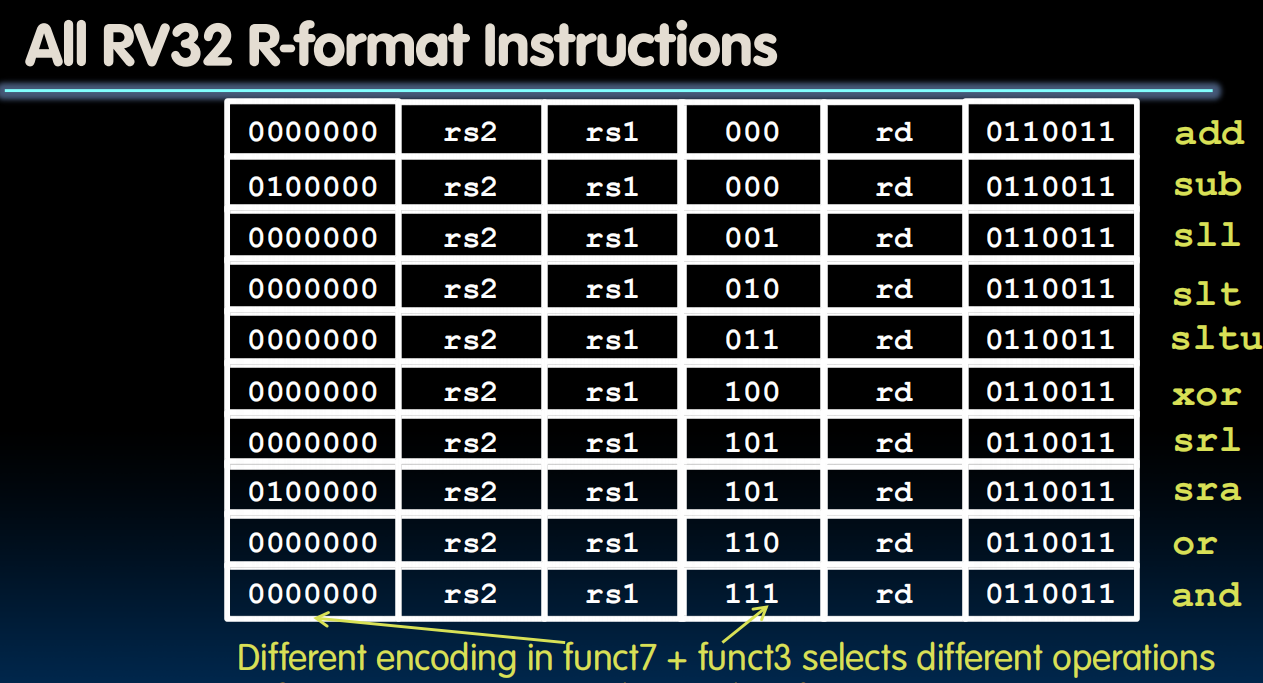
R-format
funct7中的某一位可能代表着要用某一个硬件,比如第二位为1代表要用signed extension。相似的操作编码类似,比如add&sub.
I-format
把不用的rs2和funct7作为immediates的存储位置,总是signed extension


Recall that Load也是归在I-Format里的


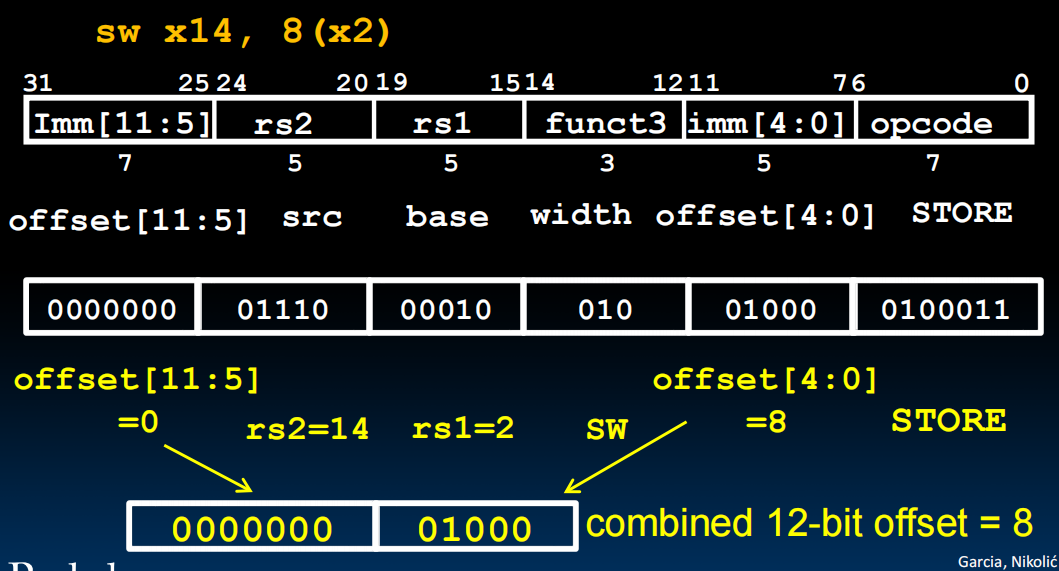
S-format
Imm被切成了两半,虽然看起来很丑,但是无所谓(

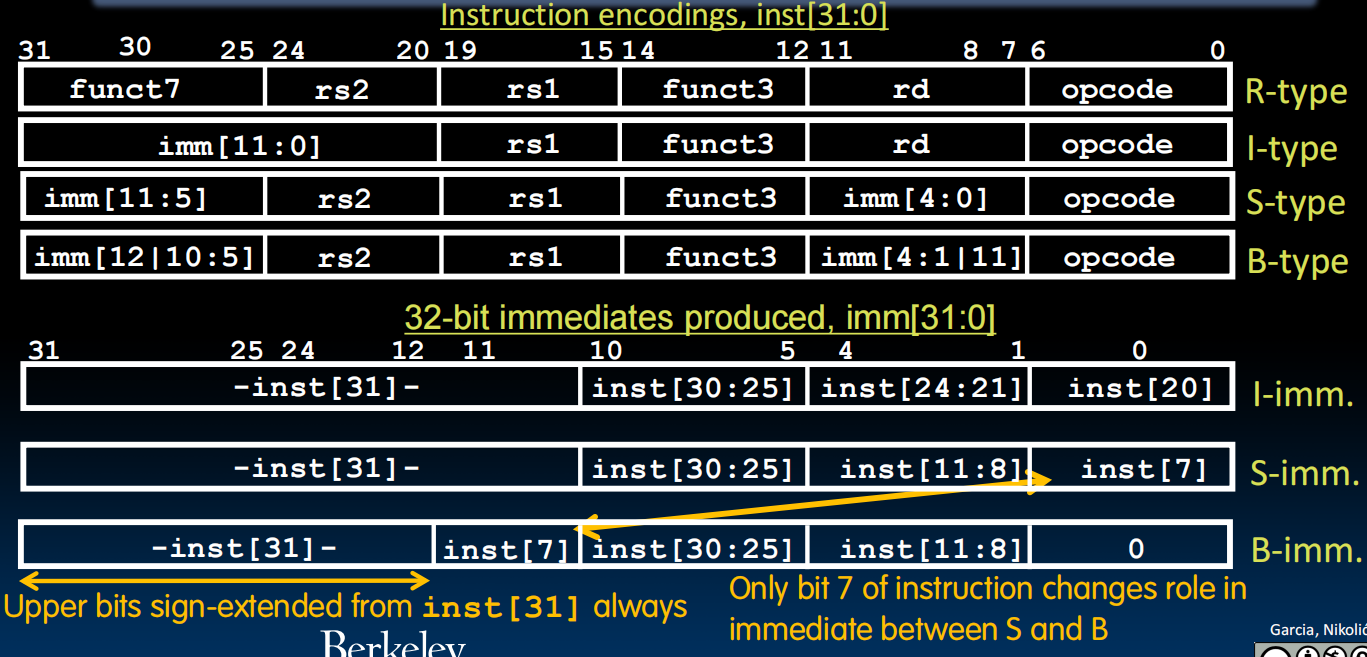
lec12-RISC-V Instruction Formats II
B-format
E.g., beq x1, x2, Label
Branches read two registers but don’t write to a register (similar to stores)
Branches typically used for loops (if-else, while, for)
Recall: Instructions stored in a localized area of memory (Code/Text)
PC-Relative Addressing: Use the immediate field as a two’s-complement offset to PC
相对位置寻址,用PC,code是存在memory里的
每个instruction是32bits的,所以我们可以到达 的指令位置

这里4是4bytes
但是!!!RV有一个subset用的是16bit的instruction!所以我们不乘4,而是乘2,能走的范围也小了一倍,但也够用。
表示:immediate要乘2才是移动的bytes,因为最后一位始终是0,所以我们省略他

为什么要拆开的那么奇怪?下图:上半部分是不同format,下半部分是immediates被符号扩展之后的样子(inst[i]表示之前在instruction encoding里面是第几位),注意到这样之后几乎是一样的,计算机方便理解。

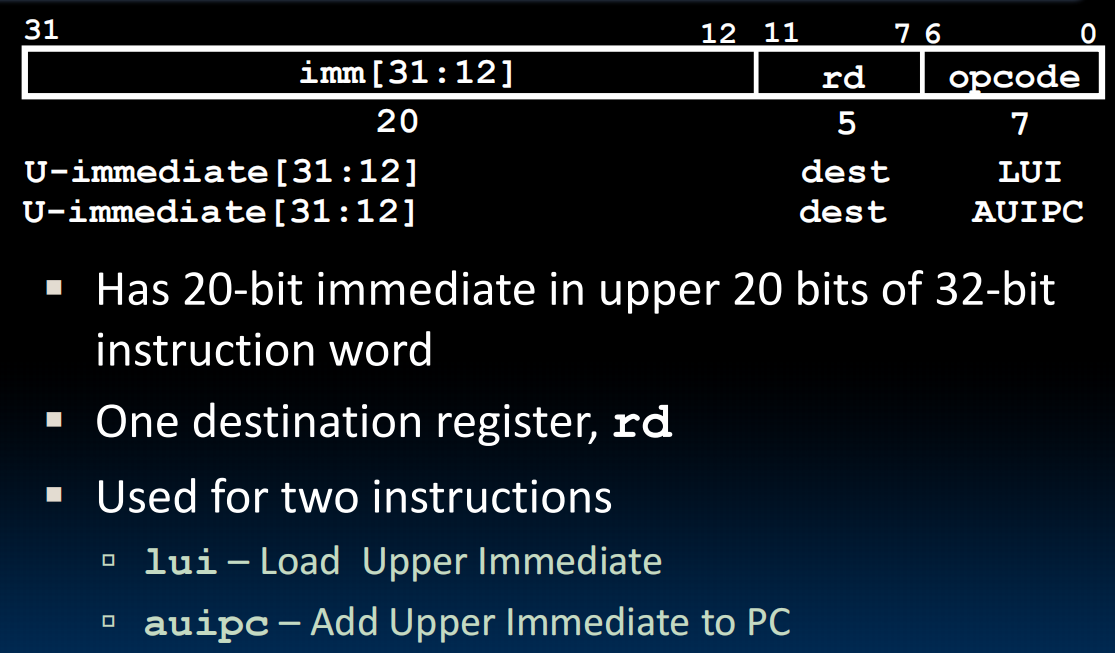
U-format
Long Immediates:


但是有问题:由于addi过程有符号扩展,会把下面例子的0xEEF扩展为前面全是1,再加上去的时候相当于-1,导致了:

手动+1(好草台班子…)。然后设置一个伪指令整合它:

AUIPC:rd = PC + (immediate << 12) 下面的指令存下来了当前的指令地址到x10中。相对位置编码

1 | // 假设 my_data 与代码位于同一可执行文件中 |
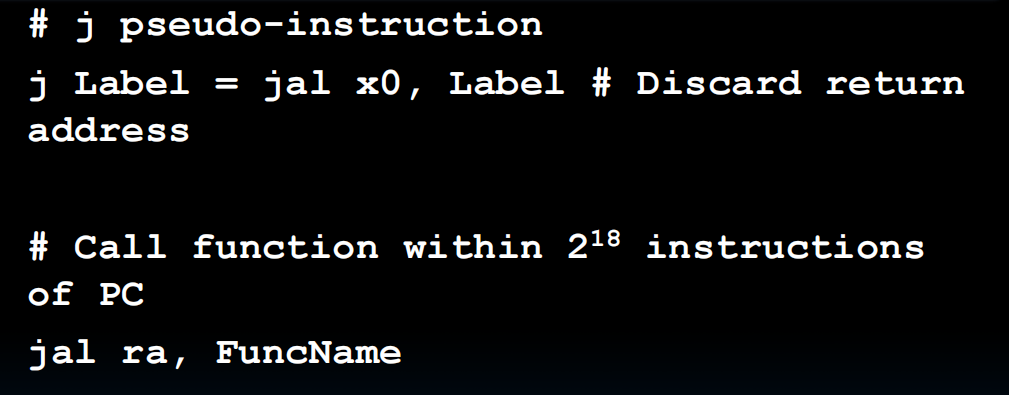
J-format

jal用于函数,会保存地址到rd,j不保存,直接跳
jalr:I-format

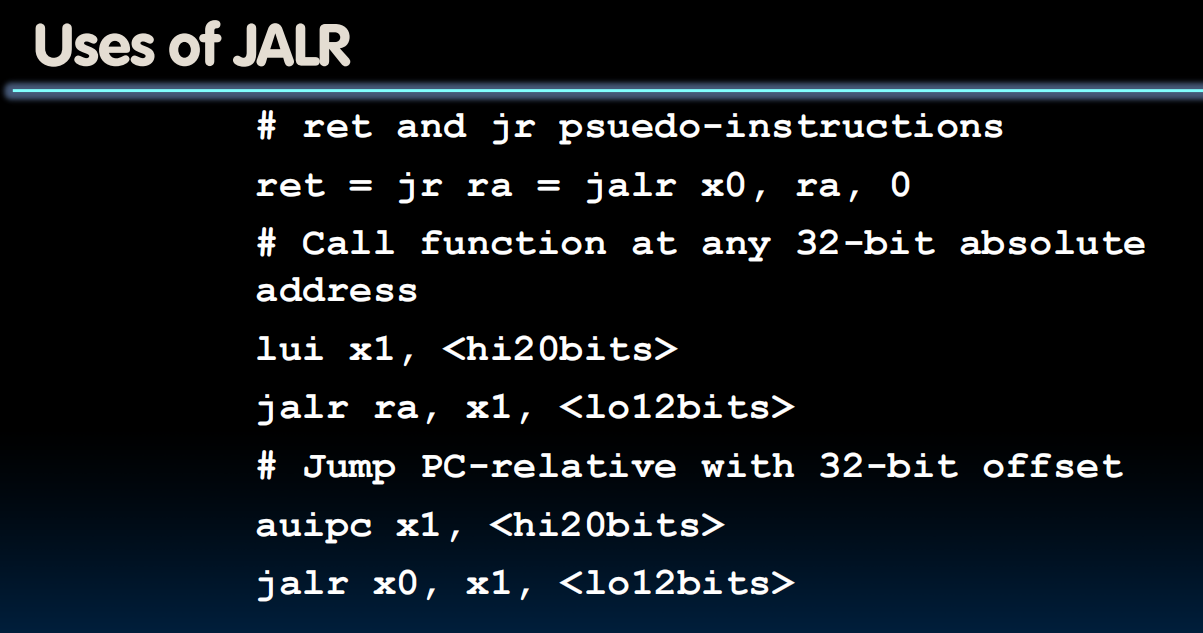
All in all:

Complete ISA (Instruction Set Architecture) !
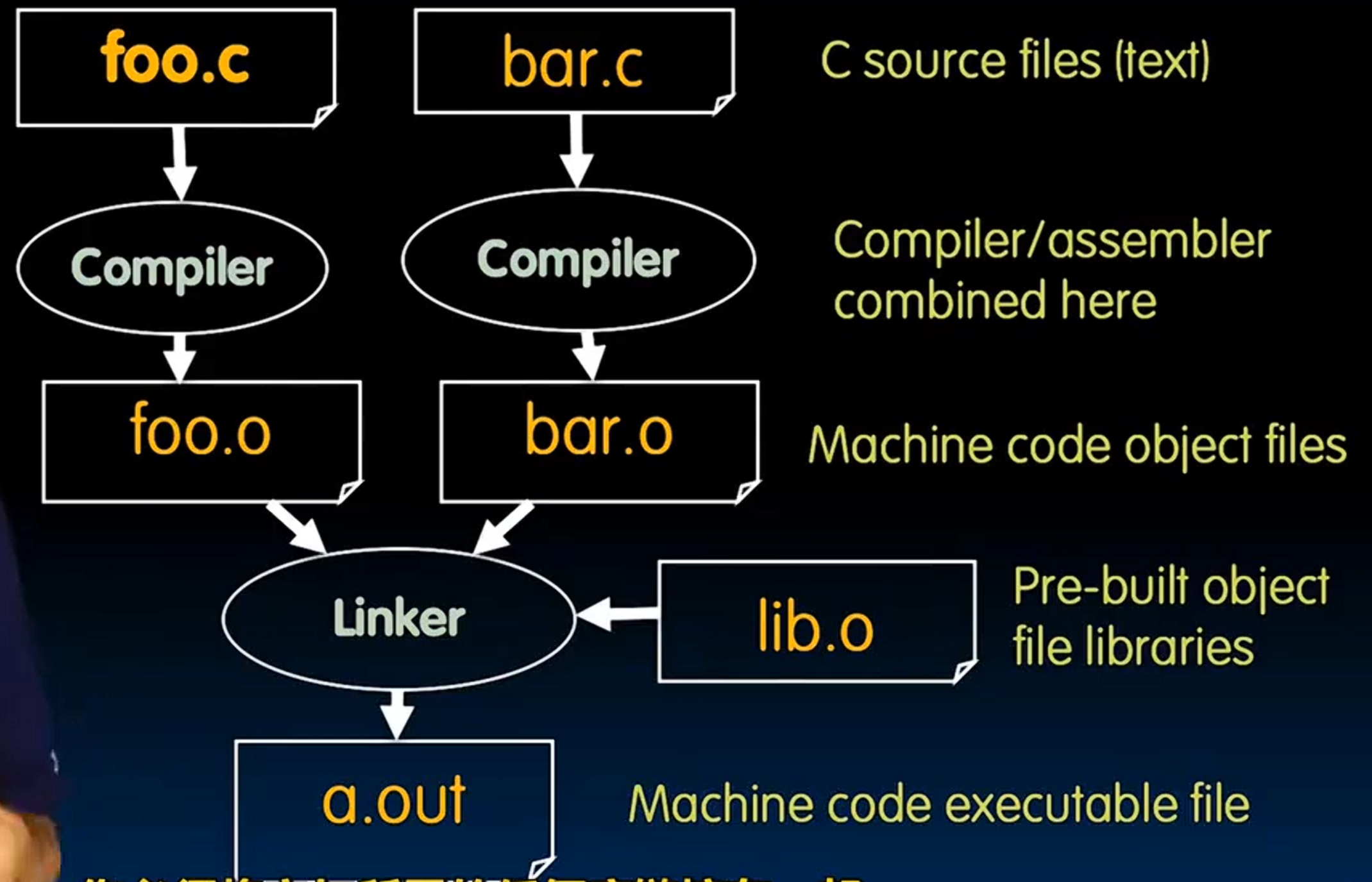
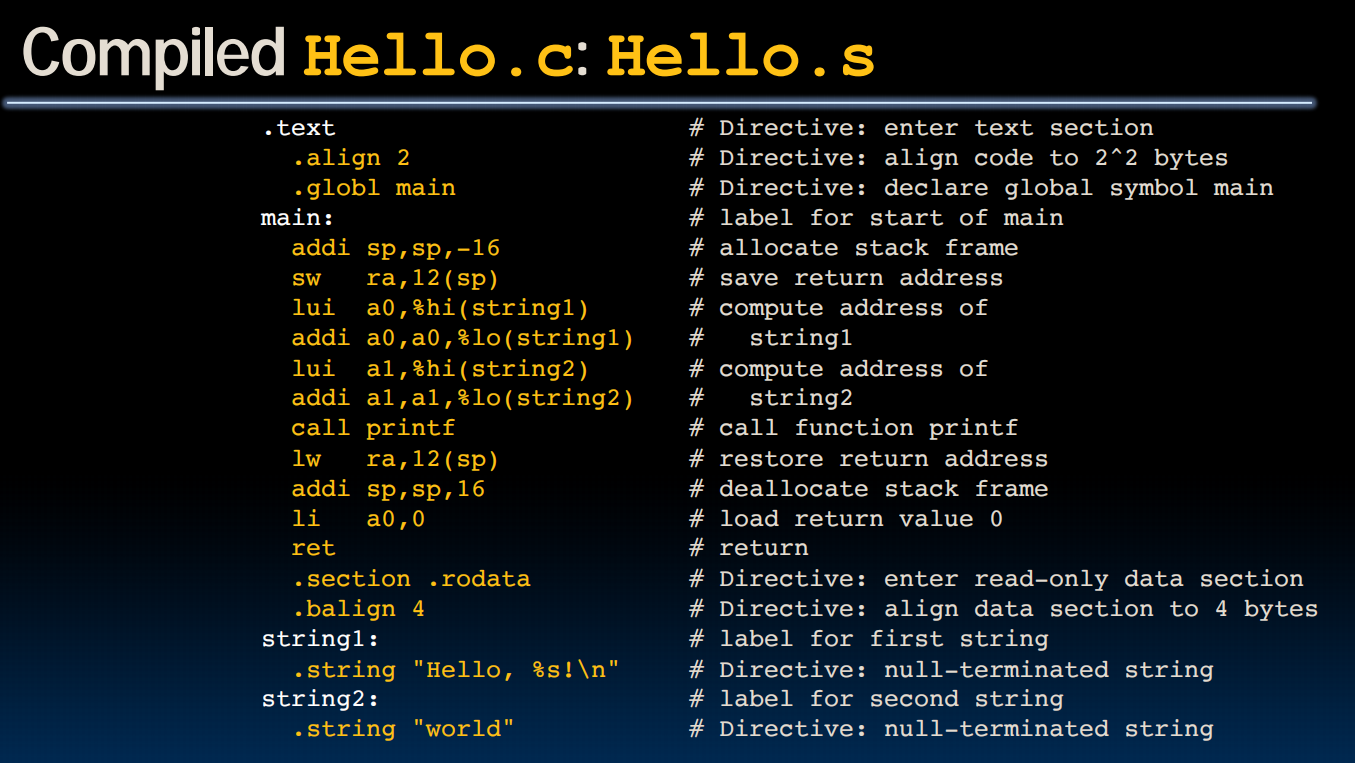
lec13-Compilation, Assembly, Linking, Loading

解释器:慢,用于不关心速度或者向后兼容时
翻译器:翻译成更底层的语言,变快
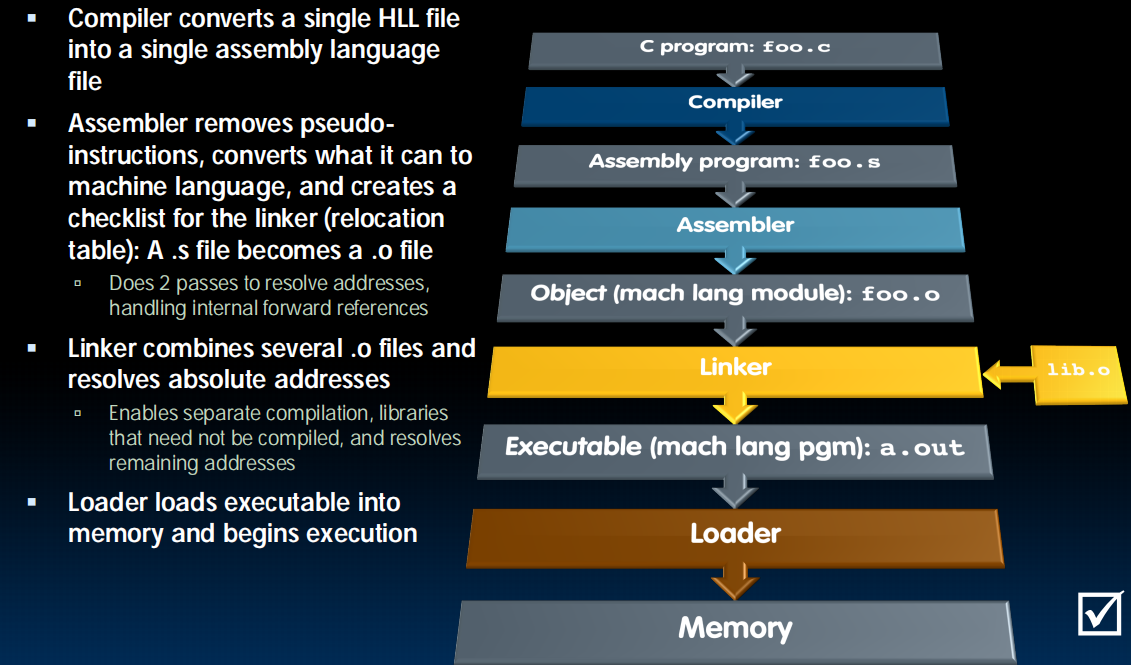
Compiler
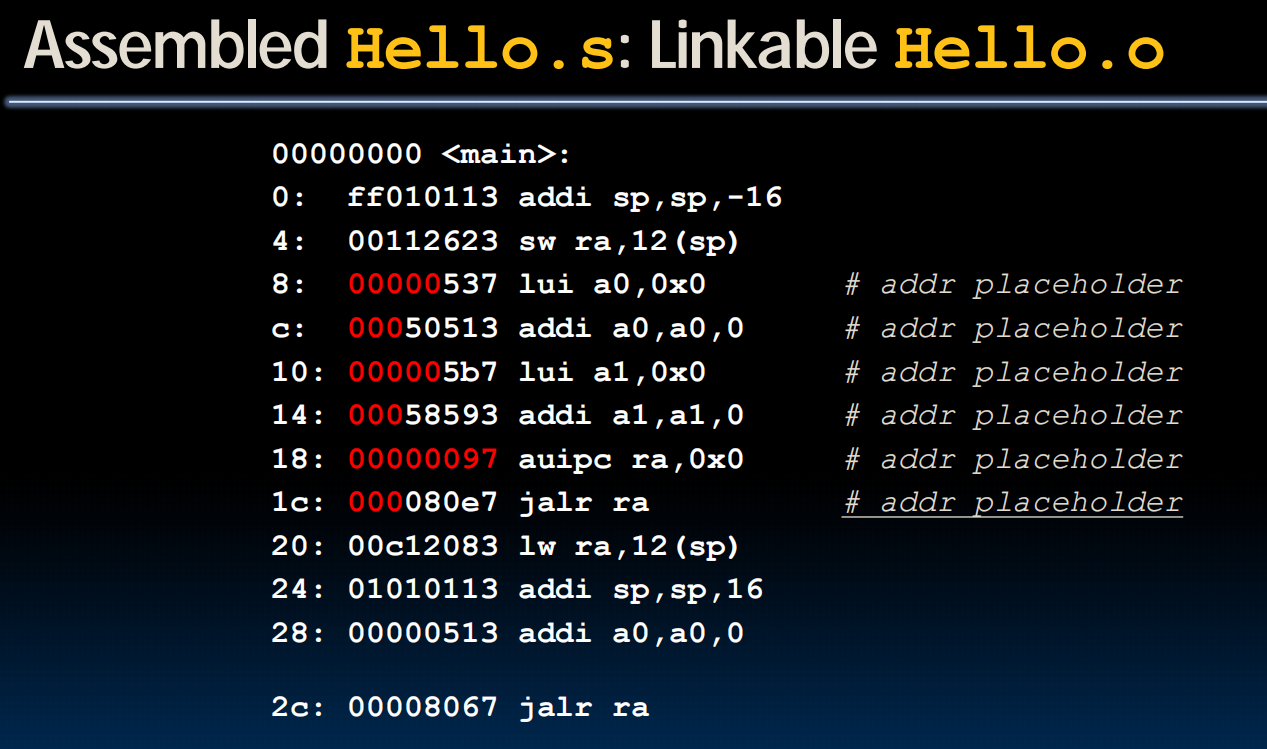
Assembling

扫描三遍:替换伪指令,扫描所有标签,运行

something that need to do but not yet


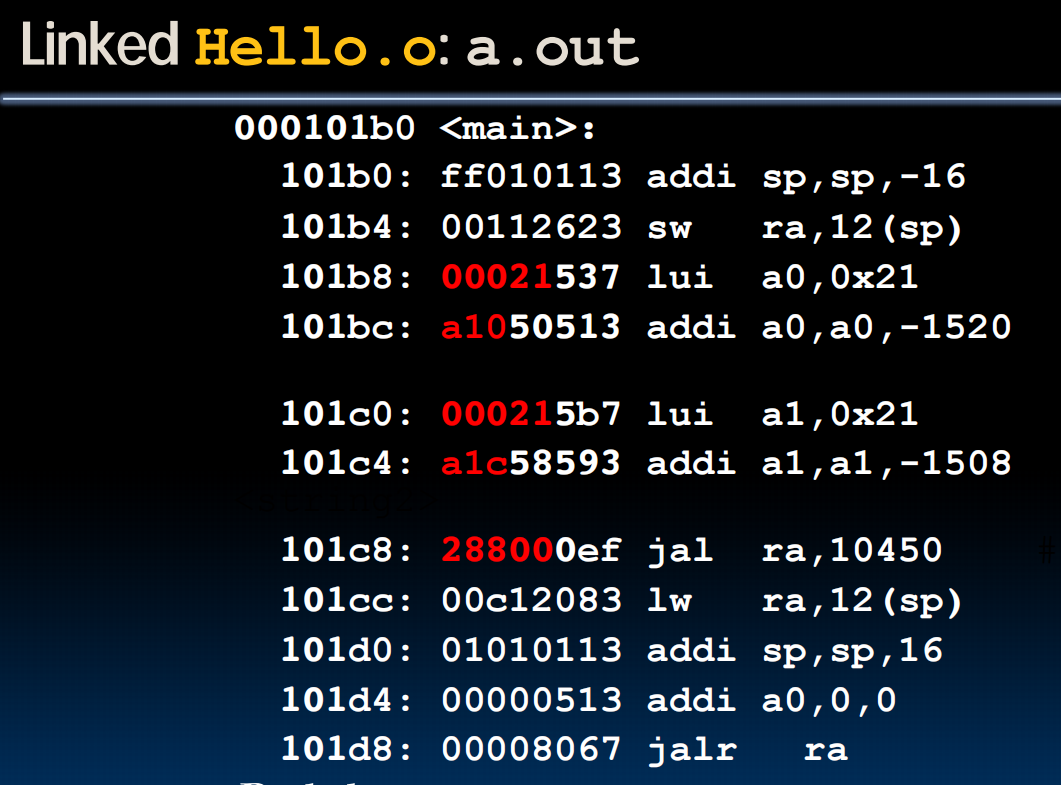
Linking
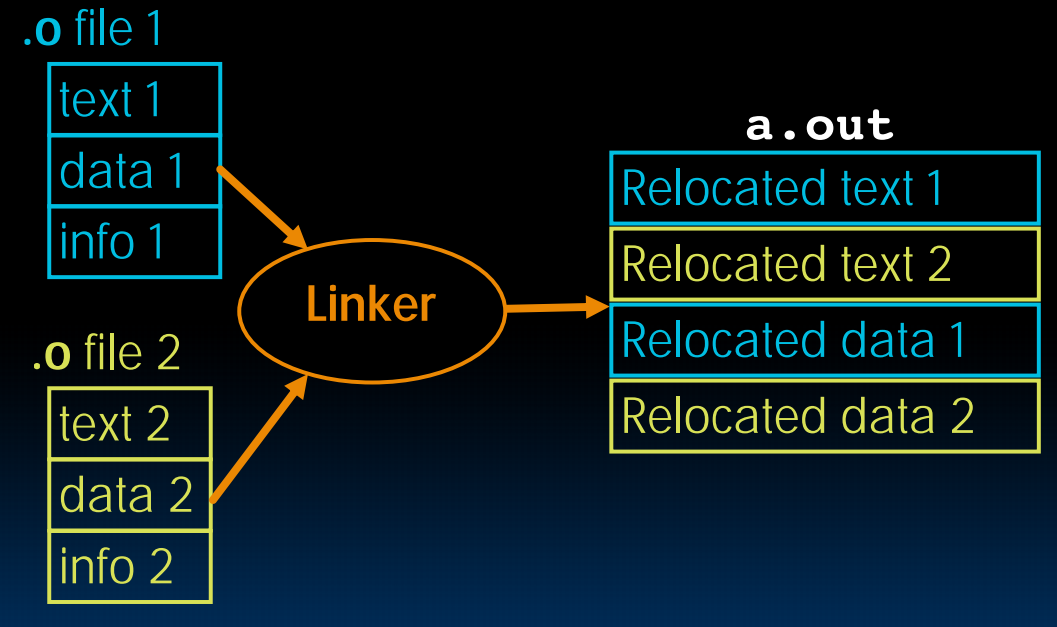

链接过程中,只有第一个不需要relocate




动态链接也有一些缺点:
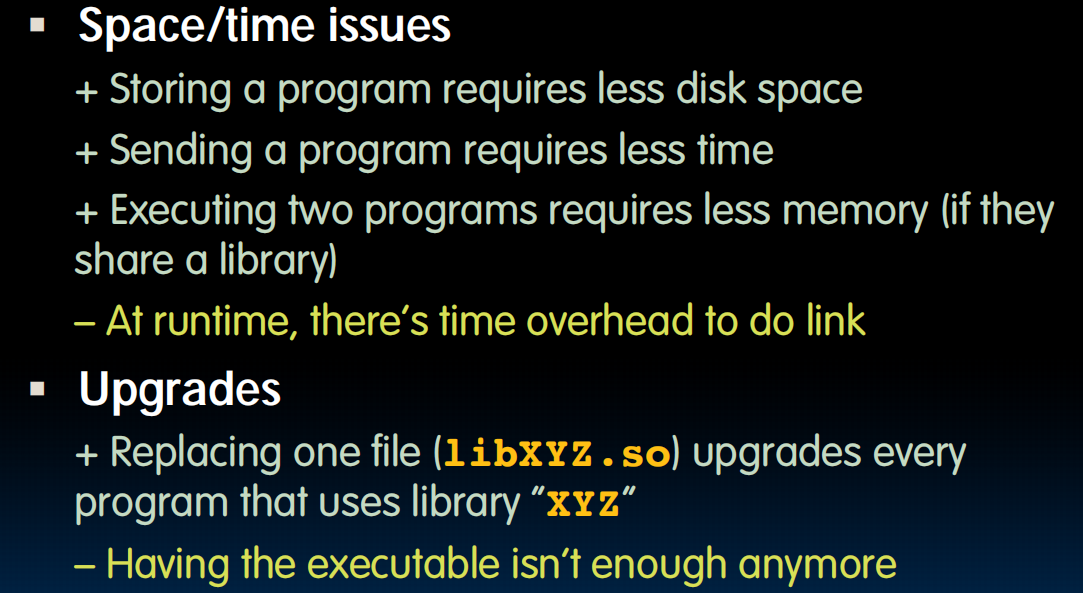
Prevailing approach to dynamic linking uses machine code as the “lowest common denominator”
在最低级别——机器代码级别去link
Loading

An example:

(lec 14~17) Synchronous Digital Systems
lec14-Intro to Synchronous Digital Systems
Switches(开关)->Transistor(晶体管)MOS
Source、Drain、Gate
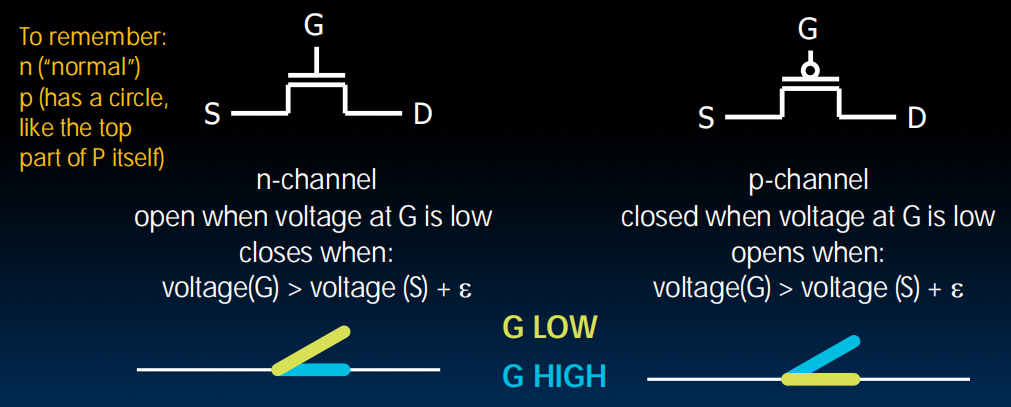
两种:n-channel和p-channel
n-channel在G高电压下close
构成Transistor Corcuit
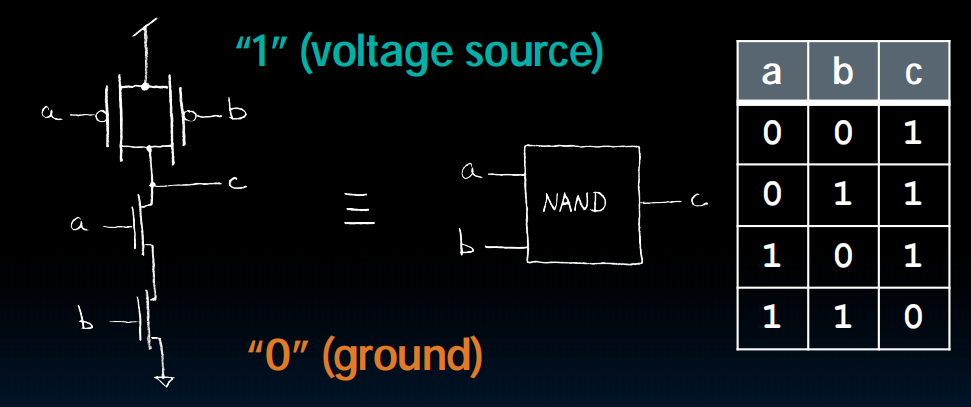
有State的circuits:
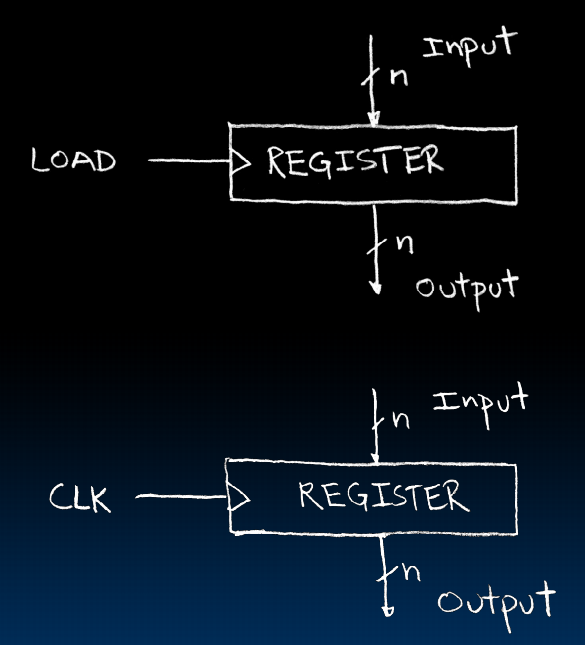
每次load的时候,register转身抓住input并作为之后的output ,也可以用clock
lec15-State, State Machines
Accumulator:累加器
register
可以feedback作为+的输入
register内部构造:flipflop

输入和输出是n位的,每个flipflop就是把一位的data挪到output。n个flipflop同时运作

但是会有延迟!所以我们需要三条黄线(上图)前两条构成的区间是data必须保持稳定的区间,setup time ~ hold time 最后一条黄线代表着clk-to-q delay
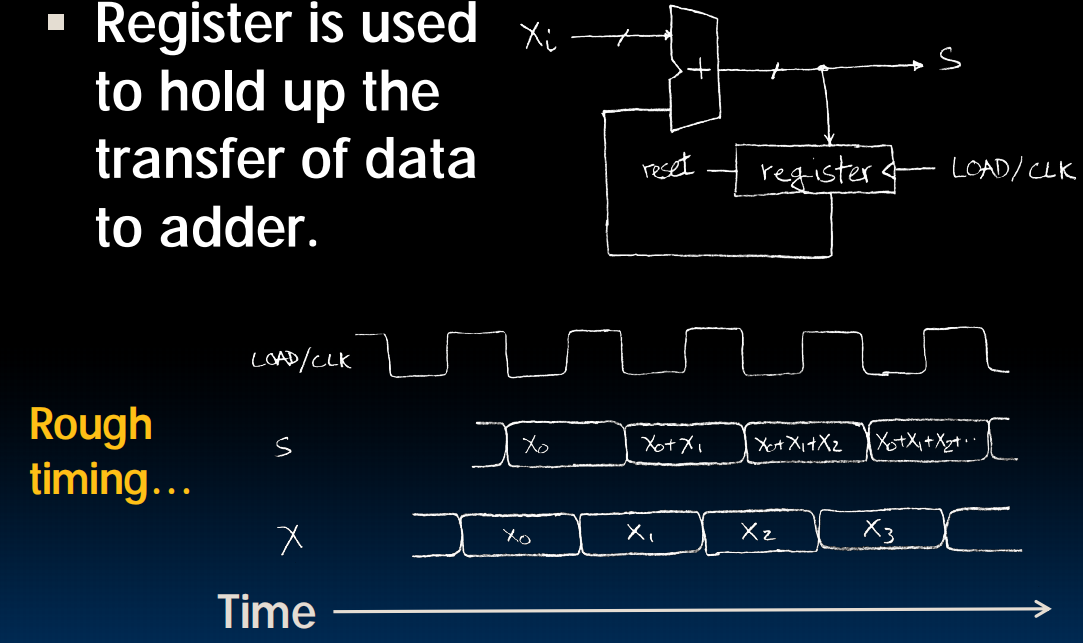
回到Accumulator:
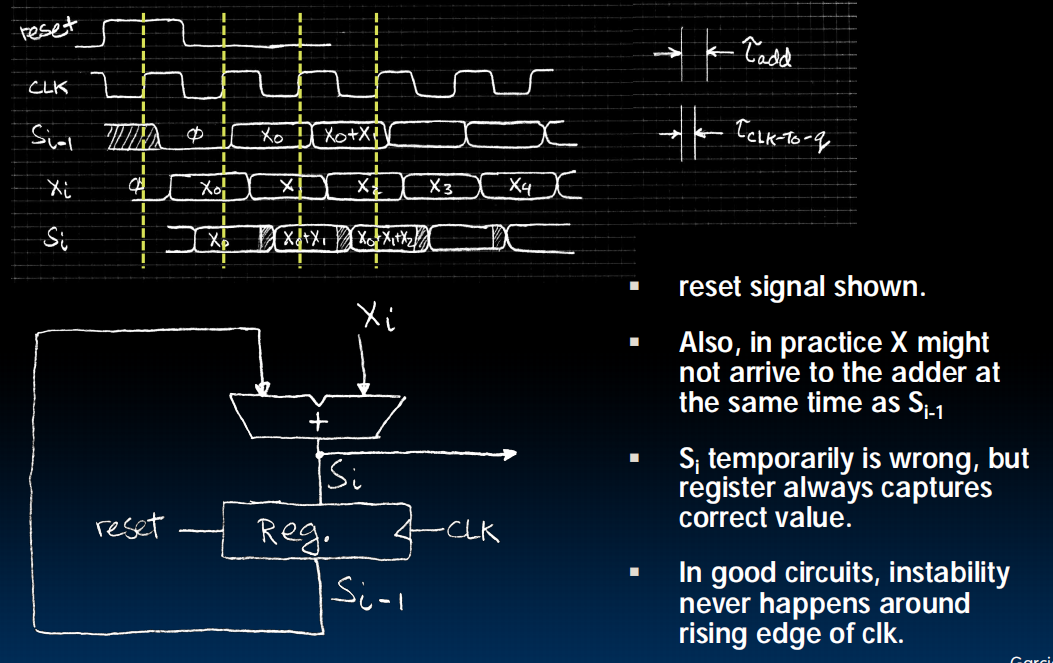
当频率变高时会出现不稳定,因为 会有一小段错误的值
pipelining to improve performance:

变为:

例子:
工匠A负责装底盘(耗时5小时)。
工匠B负责装引擎(耗时5小时)。
第一辆车出厂,仍然需要10小时(这就是延迟增加了)。
但是! 当工匠B在为第一辆车装引擎时,工匠A已经开始为第二辆车装底盘了。
因此,从第二辆车开始,每5小时就能有一辆新车下线! 工厂的吞吐率翻倍了。
时钟周期的长度只需要满足最慢的那个阶段的耗时即可,也就是 max(T_adder, T_shifter)
“表现” (Performance) 指的不是单个任务执行得有多快,而是指“吞吐率” (Throughput)。
吞吐率 (Throughput):单位时间内能完成多少个任务。图中的原话是 “More outputs per second”(每秒能产生更多的输出),这正是吞吐率的定义。
Finite State Machines(FSM)
state transition diagram
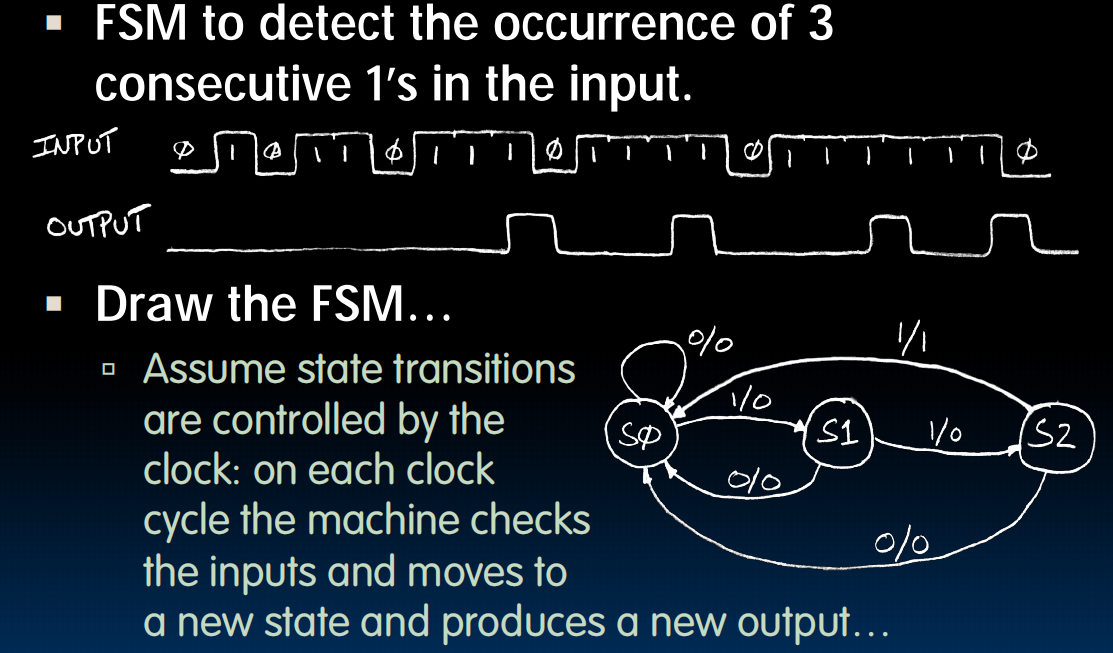
1/0表示此时input如果是1,我就走这个箭头更换state并且输出一个0
有限状态机可以用我们之前学的电路来表示出来:
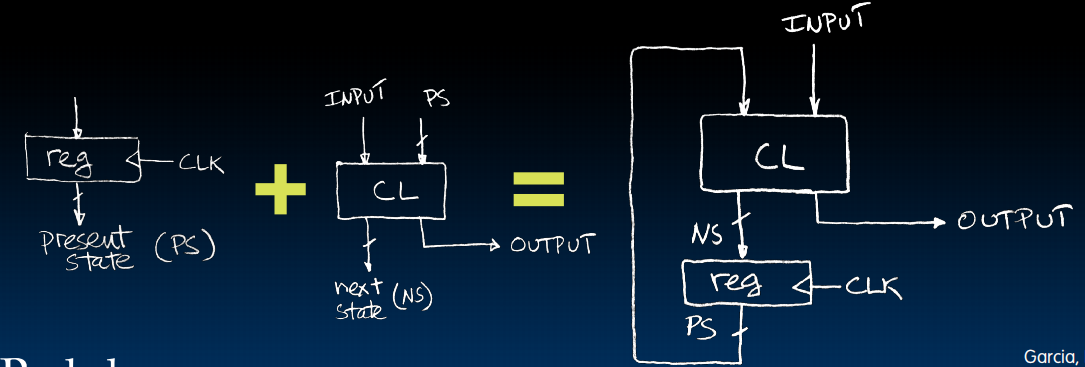
register会记得我们现在的状态是什么
Synchronous Digital Systems
lec16-Combinational Logic
Truth Tables

Logic Gates

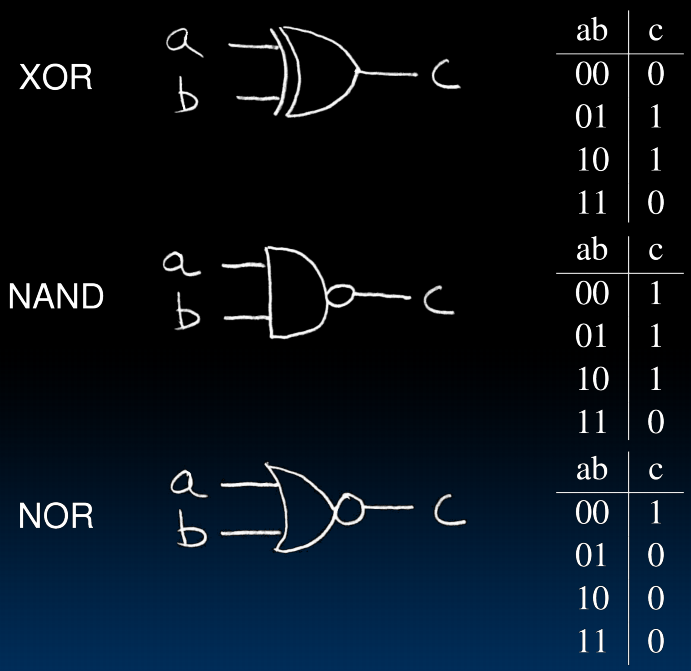
2->n
n个输入的xor:输入中1的个数为奇数则输出1
Boolean algebra and its laws
means OR, means AND, means NOT
列出方程之后尽可能化简
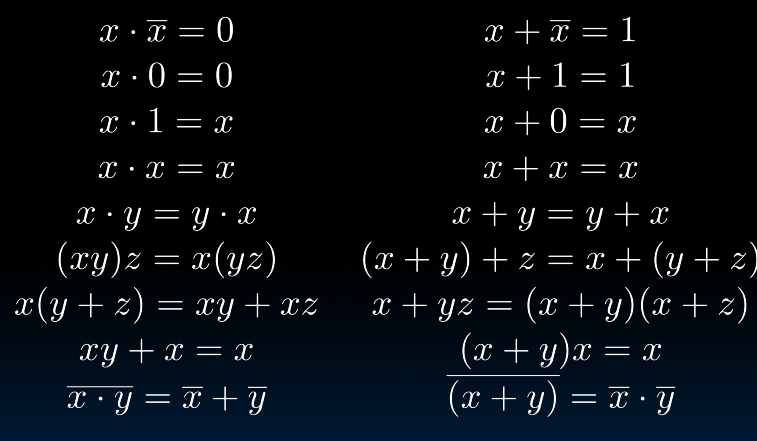
Canonical forms
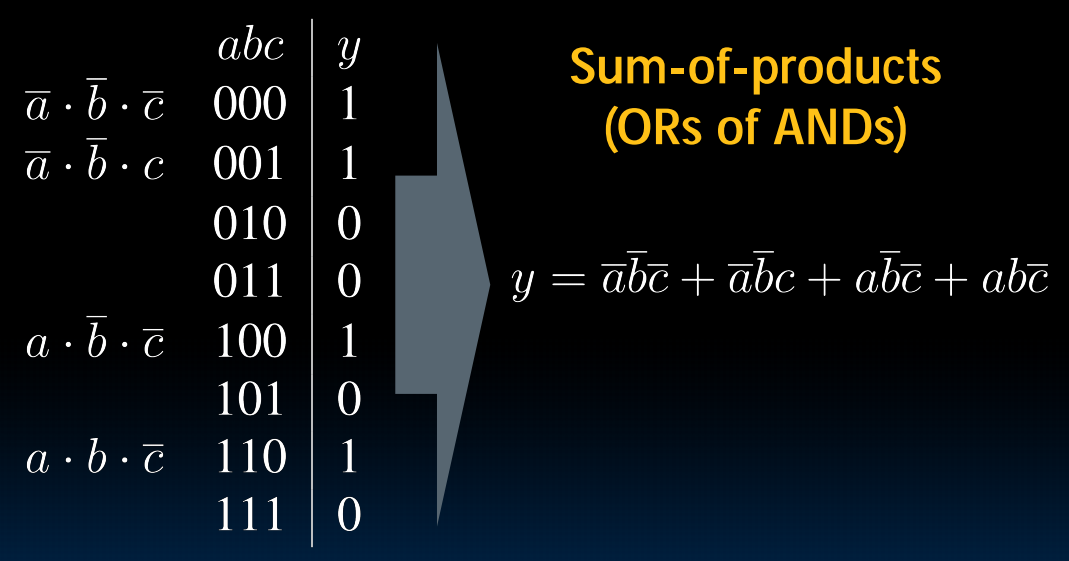
这样就可以把任意一个真值表构造出对应的方程。然后再慢慢化简:
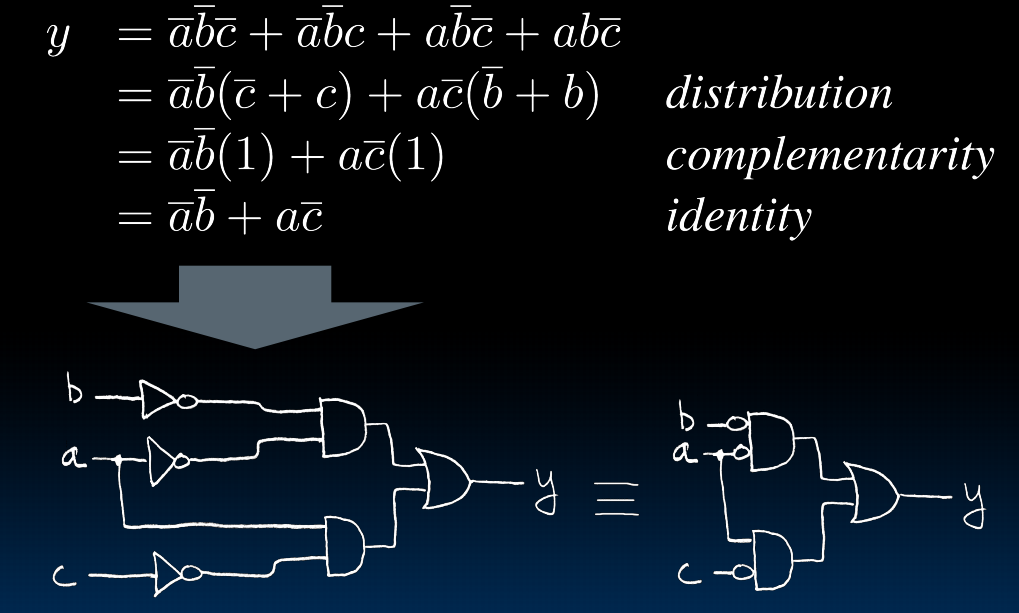
lec17-Combinational Logic Blocks
Data Multiplexor
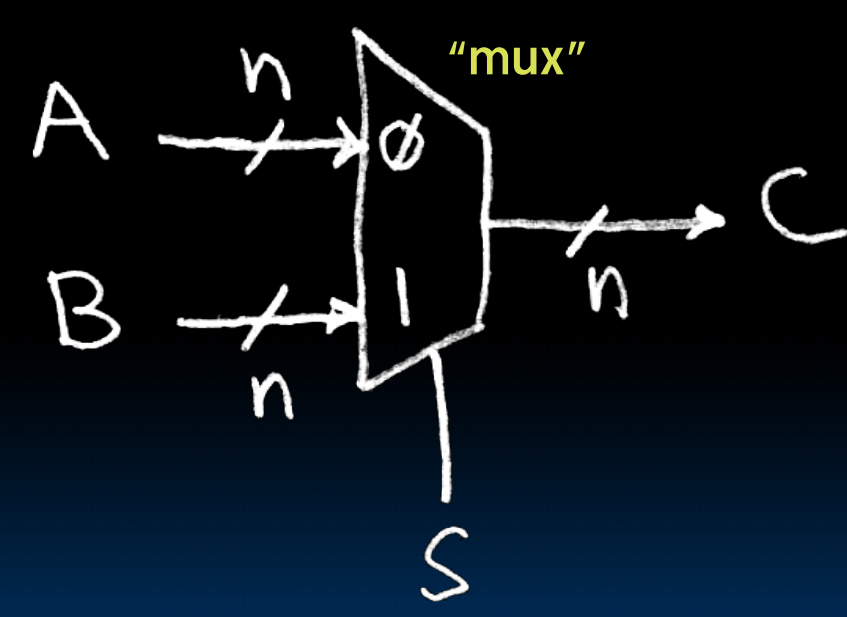
等价于 ,也可以画出对应的电路
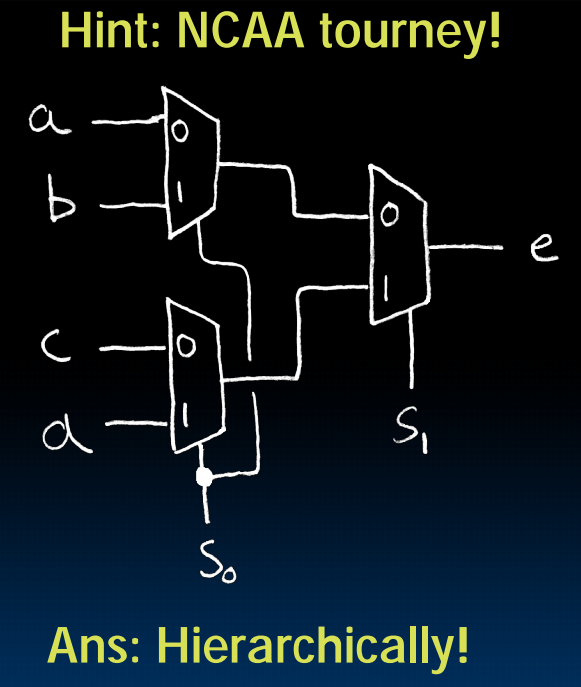
4-to-1 multiplexor:
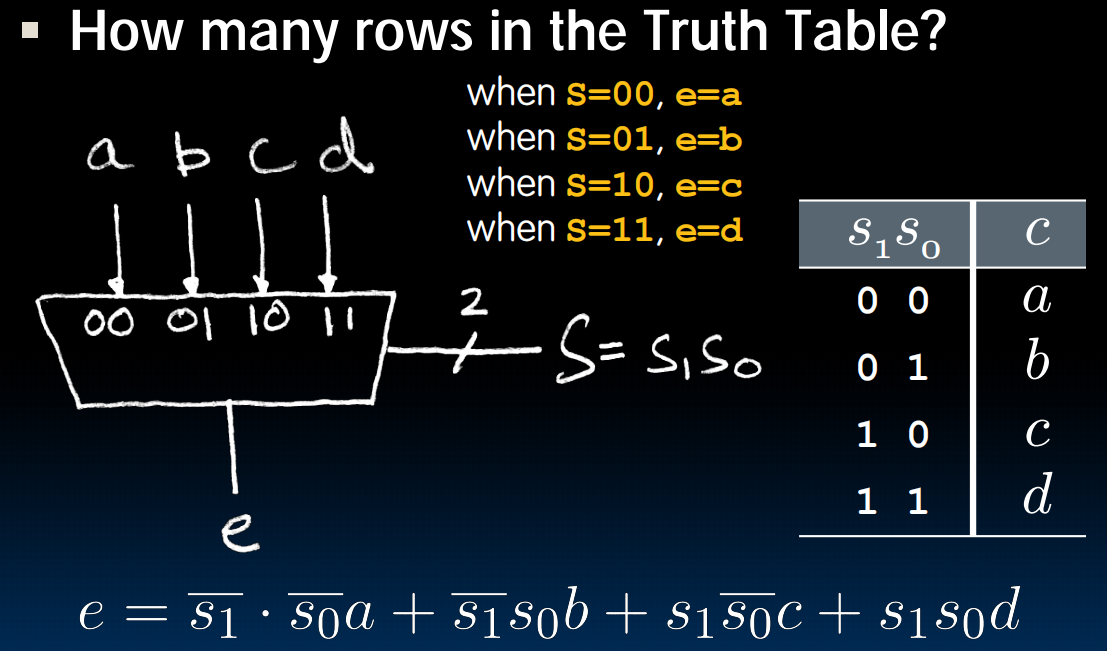
Another way:
Arithmetic and Logic Unit(ALU 算术逻辑单元)

我们不用真值表来实现,而是组合之前我们造出来的东西:
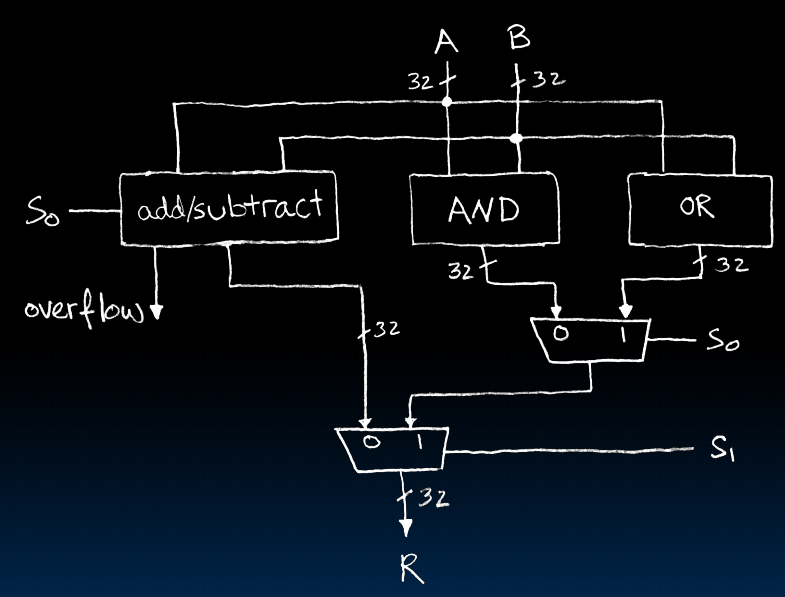
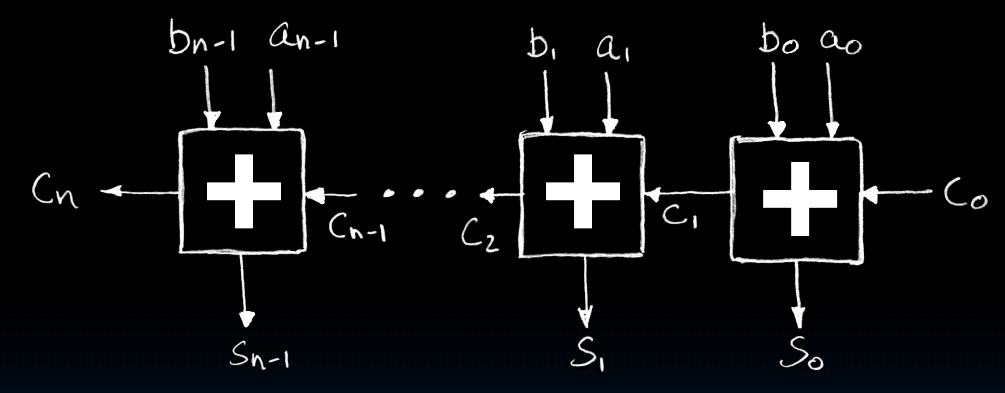
Adder/Subtracter
one-bit:
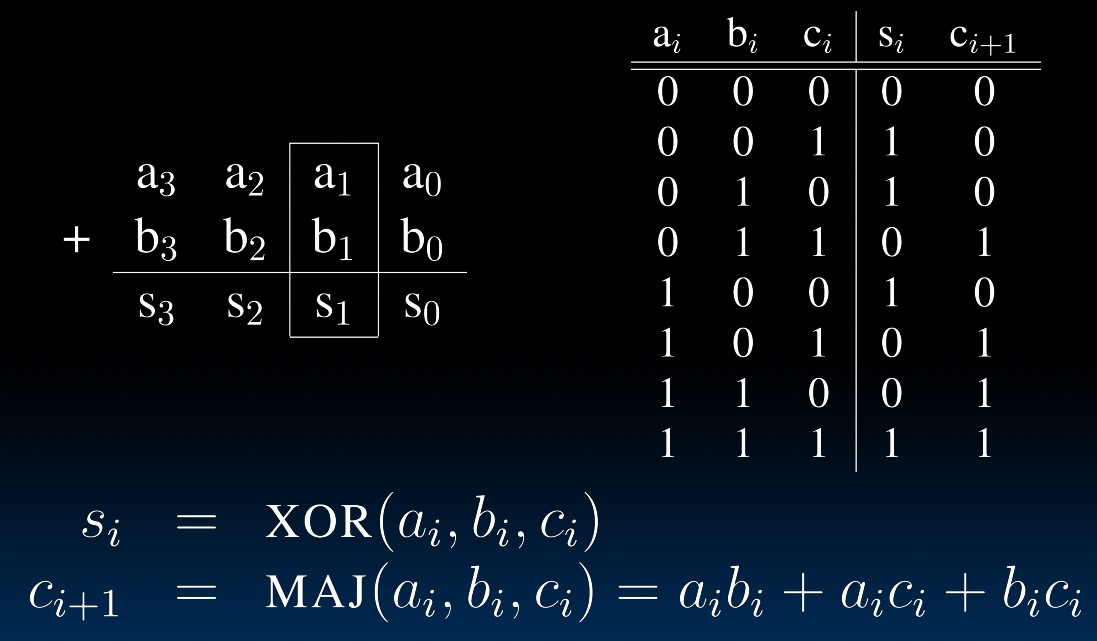
有符号数呢?下图中都是在对补码操作。
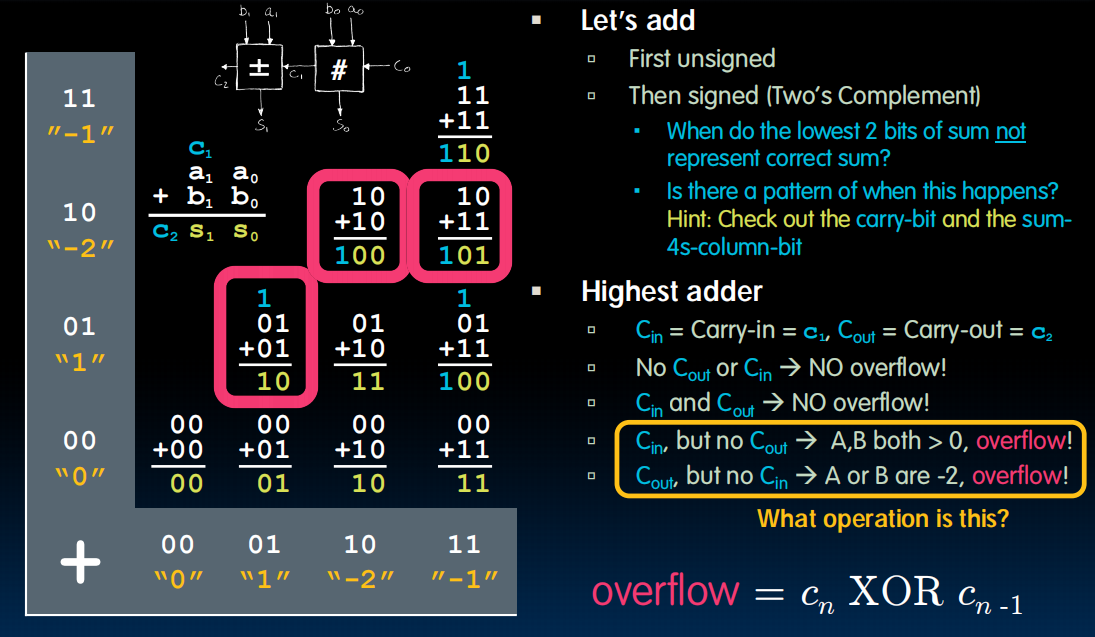
2-bit:首先做无符号数,然后得到c1,c2,可以看看表中,会发现除了红框的内容之外都是对的。当且仅当二者恰好一个是1的时候会出现overflow
Subtractor Design
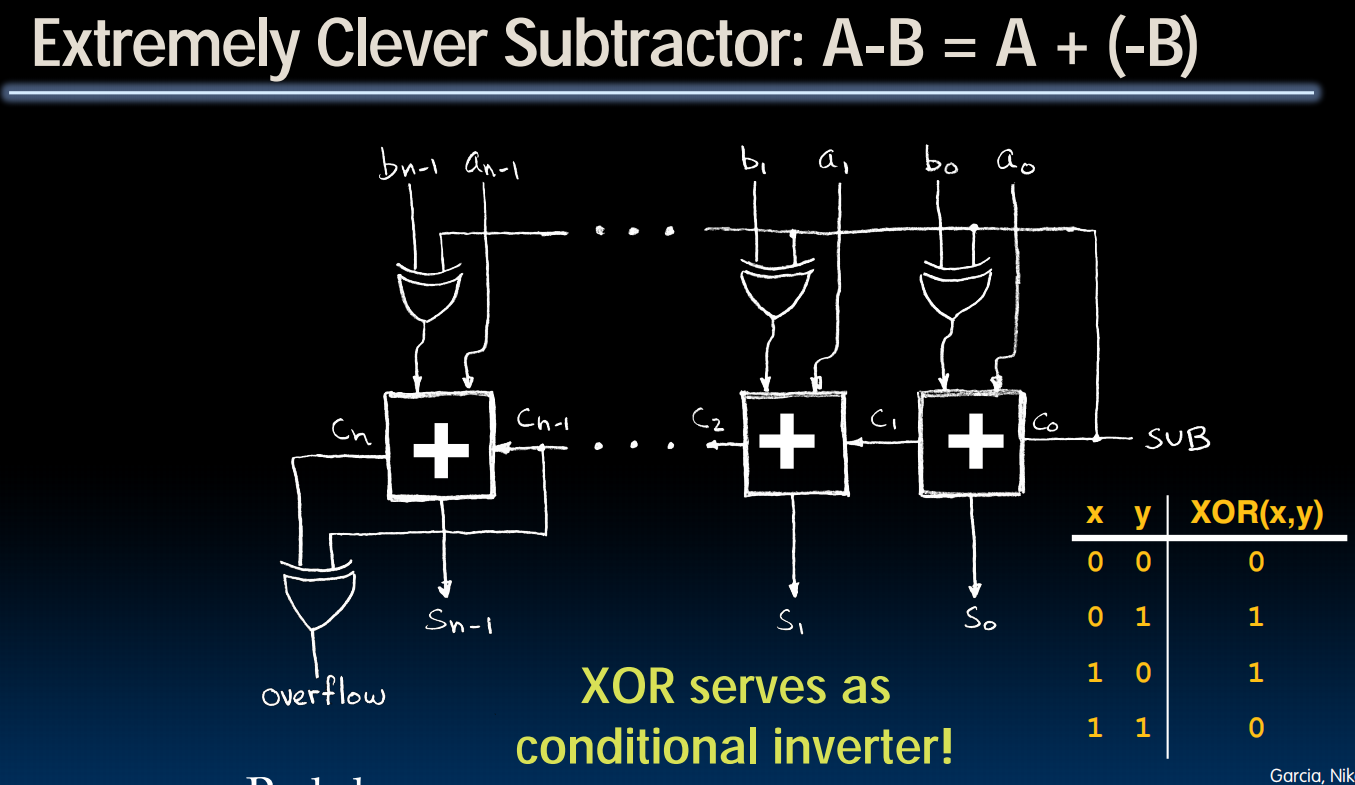
首先,我们的目标是复用加法器来构造减法器。
B变成-B只需要所有位翻转并+1.而当SUB信号为1的时候对每一位异或1就是翻转功能。直接把SUB加进去相当于加了1
lec14~17 In conclusion:
(lec18~27) CPU、Pipeline and Cache
lec18-Single-Cycle CPU Datapath I

Processor、datapath(用于处理ISA的硬件部分) and control(控制datapath的处理)
Building a RISC-V Processor
相当于造一个State machine
PC: program counter
IMEM: instruction memory
REG: register
DMEM: data memory
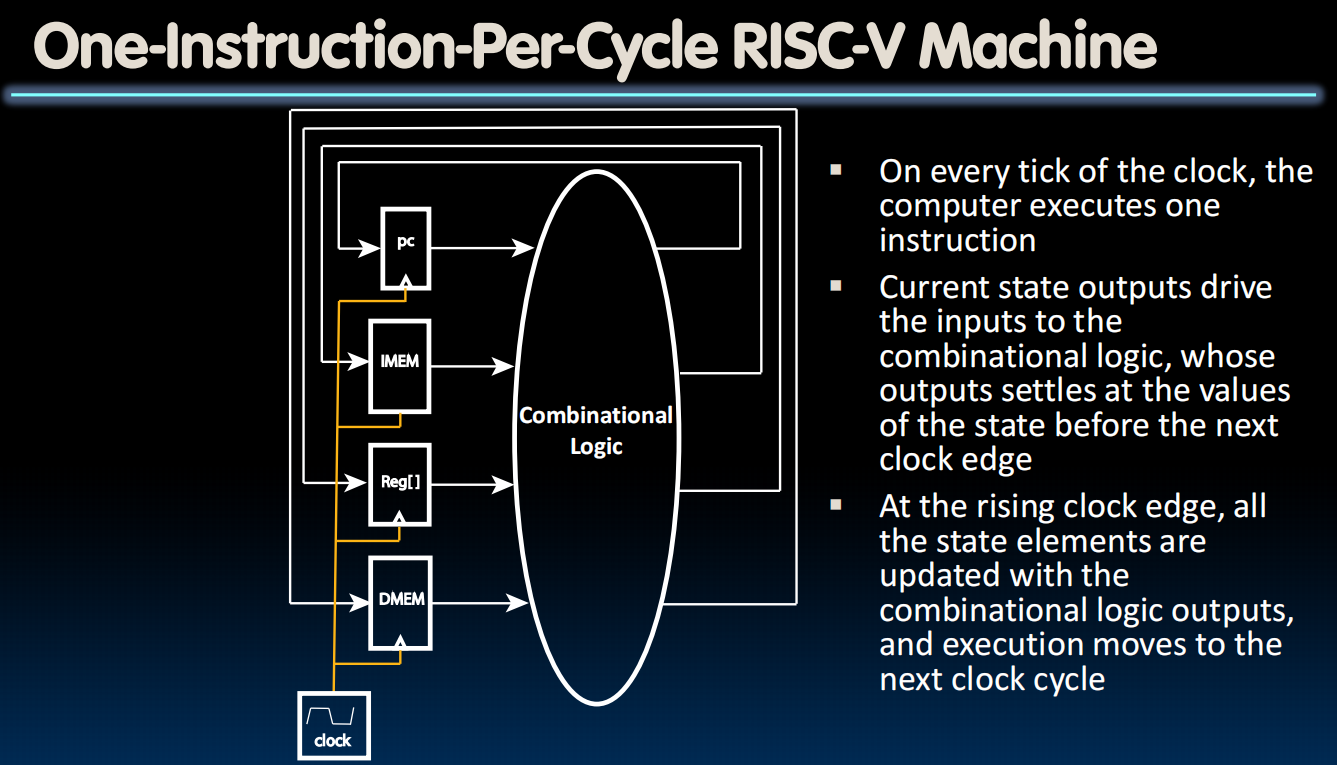
五个步骤:

具体而言(抽象层面的具体):这些步骤会在一个clock周期中完成
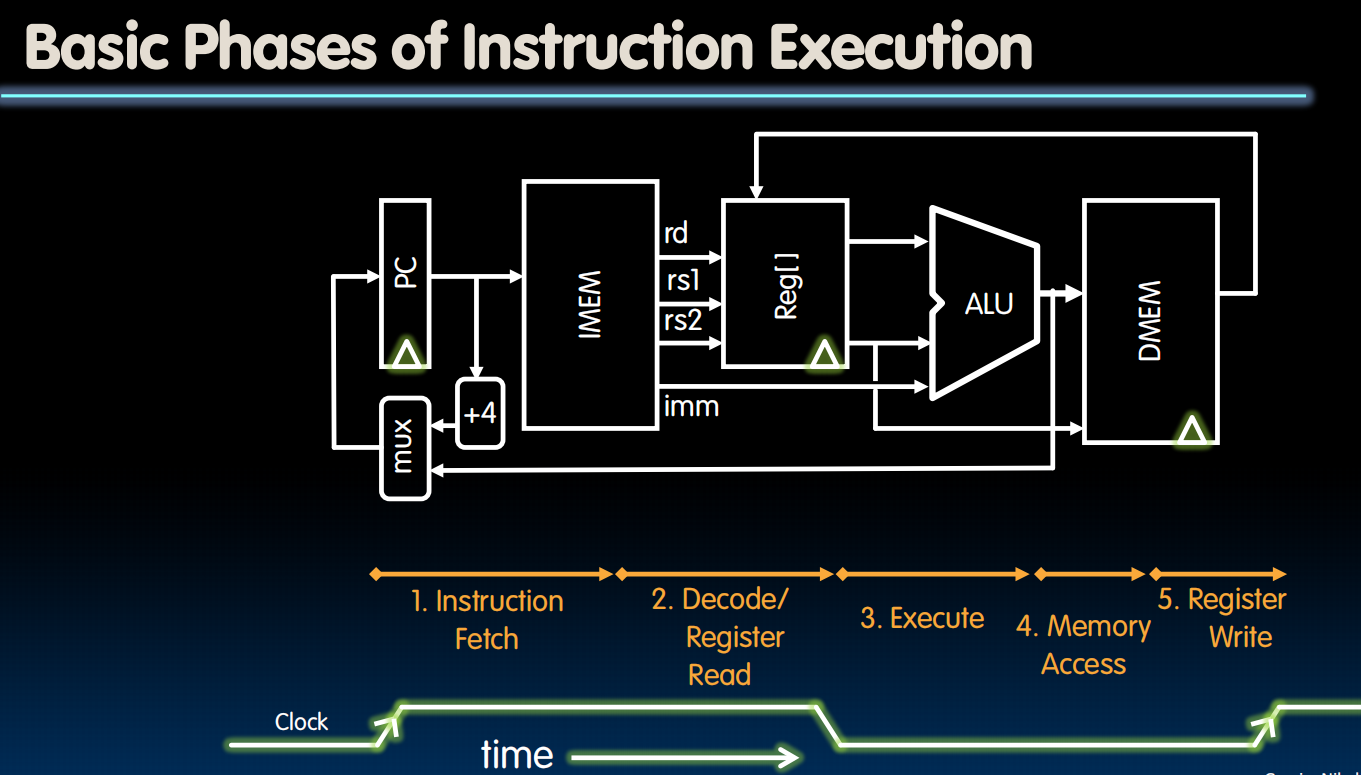
datapath怎么构成?

Datapath Elements: State and Sequencing
state存在registers上:

每个register相当于32个flipflop
register file(RF)存放着我们的32个registers,我们每次只能读的register的个数和写的个数是有限定的,比如下图:两个读端口和一个写端口。

bus是总线,物理上就是一些导线,信息层面是一条通道,来运输数据。
读取数据:
写RA,比如写上5,然后Register File 就会进过一个短暂的延迟之后把A(5号reg)(32个数,所以是五位)的数据放到busA这个通道上运出来。
写入数据:
将你想要写入的目标寄存器的地址5放到 RW 这5条地址线上。将你想要写入的32位数据放到 **busW ** 这个32位的输入总线上。将 Write Enable 这个控制信号设置为 1(安全锁)。最后等待clock跳为1,这个时候,就把东西写进去了。

内存是同理的。
State Required by RV32I ISA

R-Type Datapath
R-Type Add Datapath
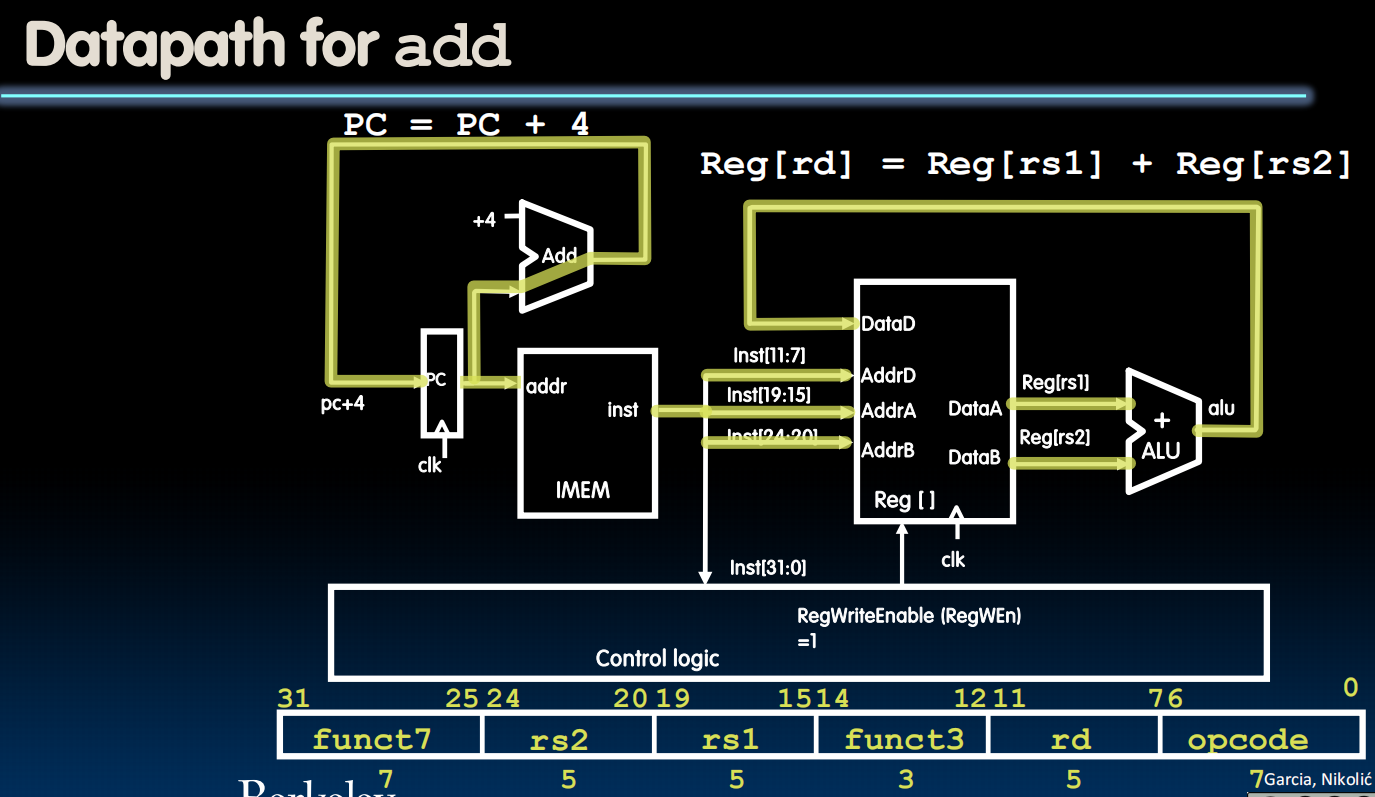
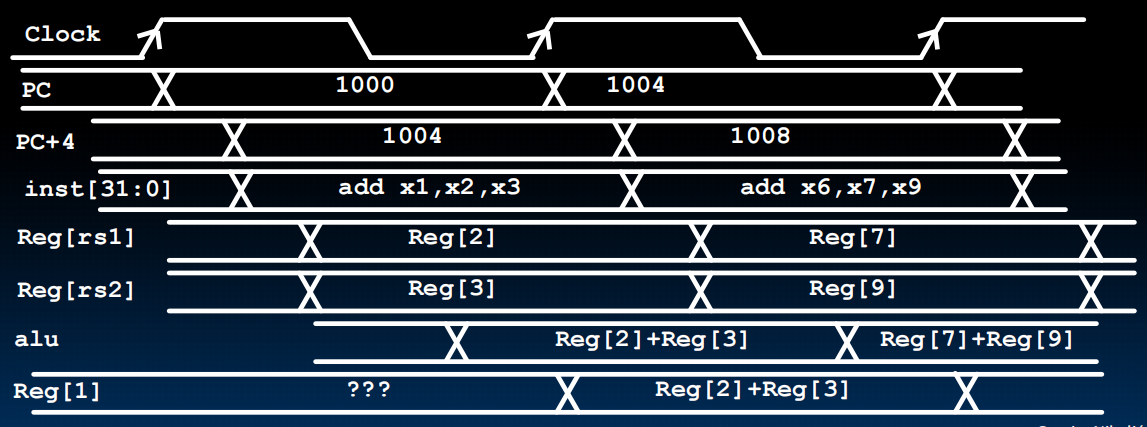
R-Type Sub Datapath
注意这里不是新建了一个Datapath,而是扩展Add Datapath使得它同时可以实现两个操作
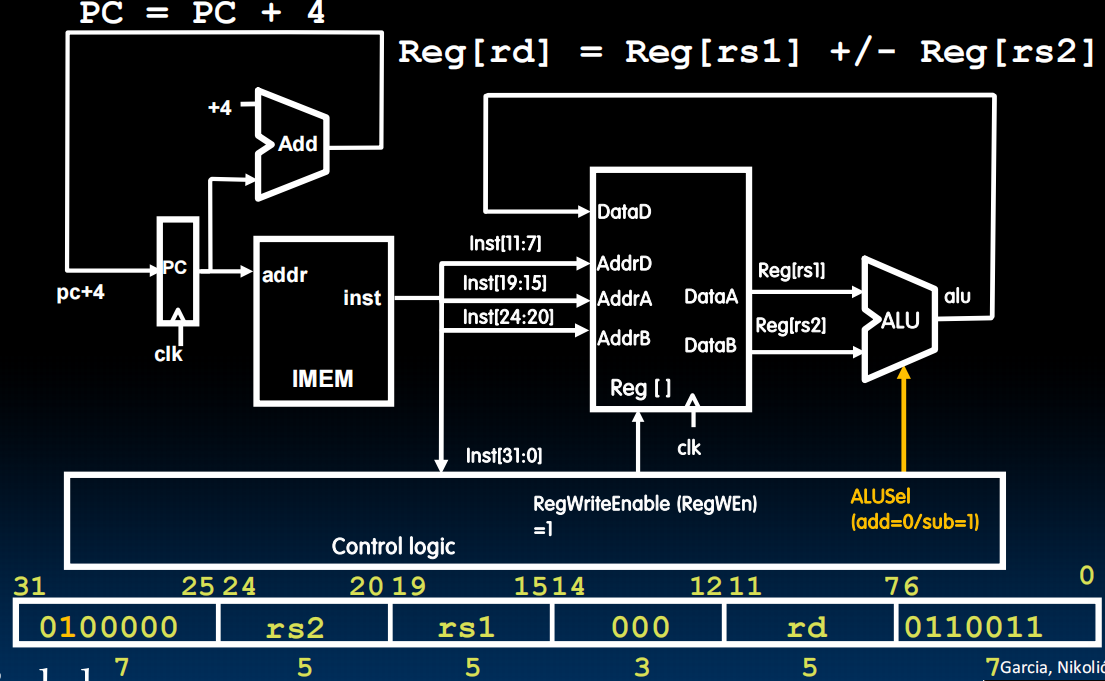
其他R-Type同理
Datapath With Immediates (I-Type Datapath)
同样的,我们也想要扩展原来的Datapath而不是新建一个。

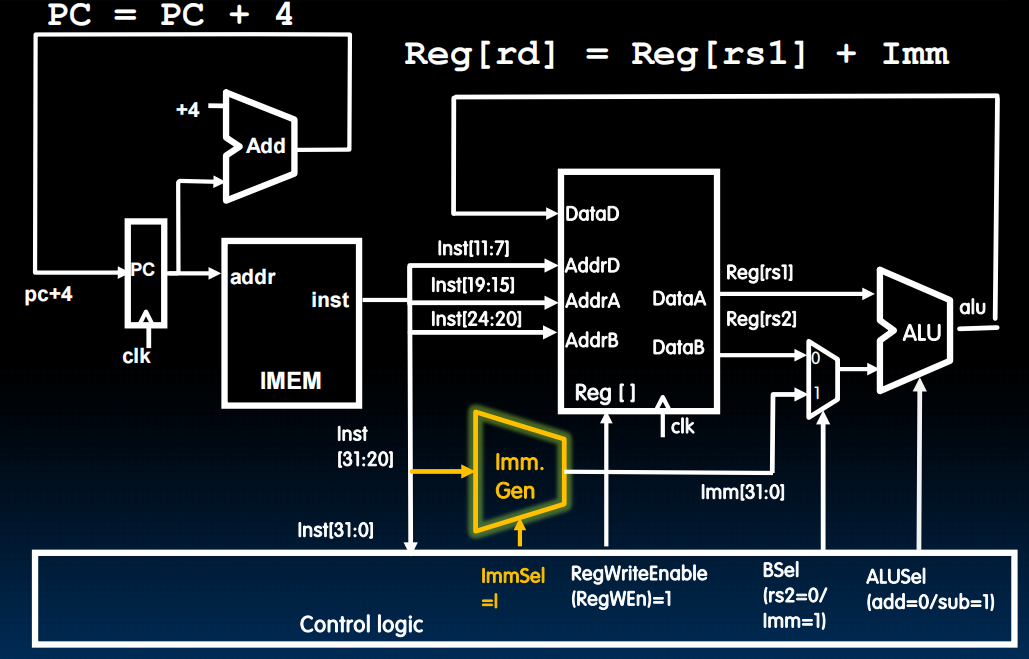
Immediate Generator:我们要把指令中的12位的立即数转换为32位

lec19-Single-Cycle CPU Datapath II
Datapath for Loads
1 | lw a0, 8(a1) |
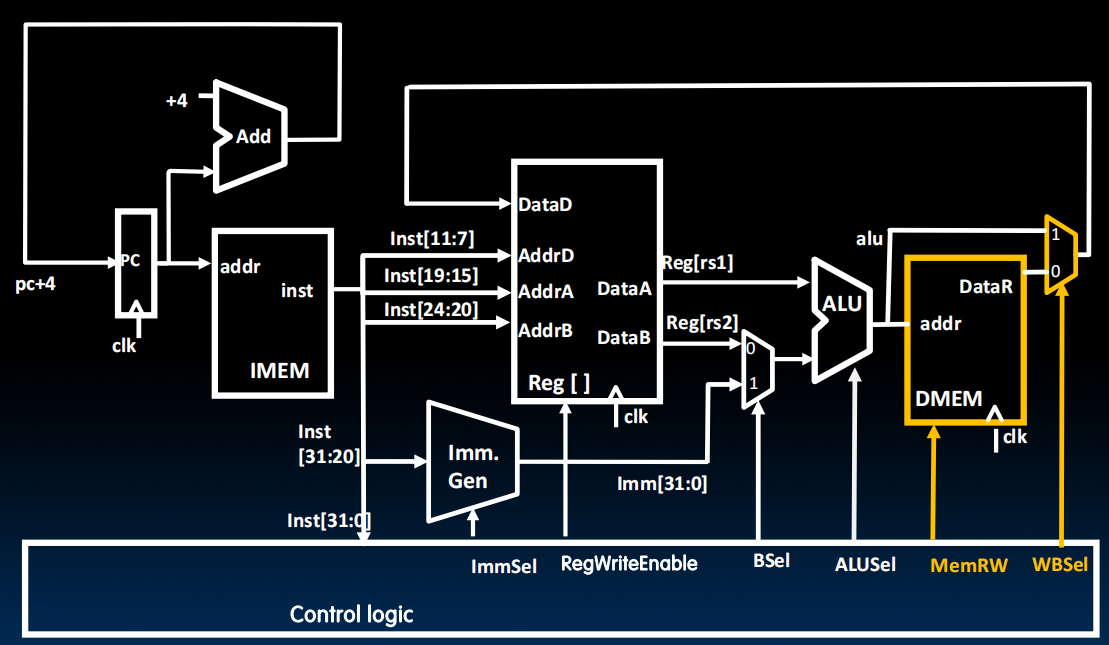
其他输入方式可以类似构建。
Datapath for Stores
1 | sw a0, 8(a1) |
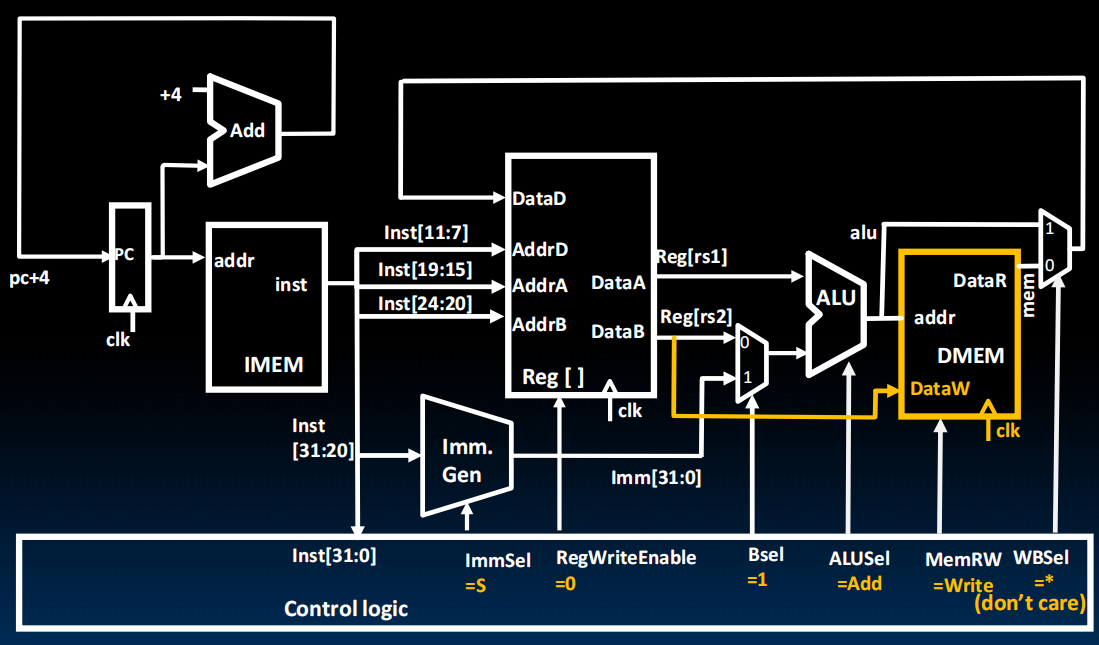
由于我们的此时的Immediate的存储的地方时拆开的,所以我们要修改Imm. Gen来把它合起来

Datapath for Branches
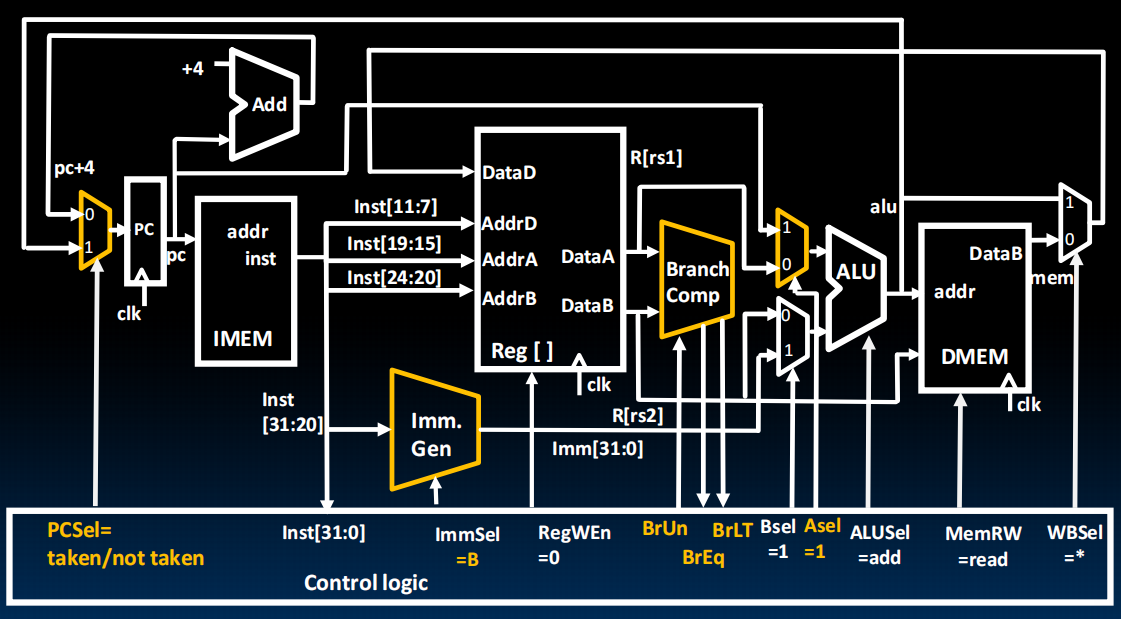

注意我们的立即数最后其实要加一个0:


那么现在的Immediate计算就是这样了:

Datapath for JALR(Jump and Link Register)

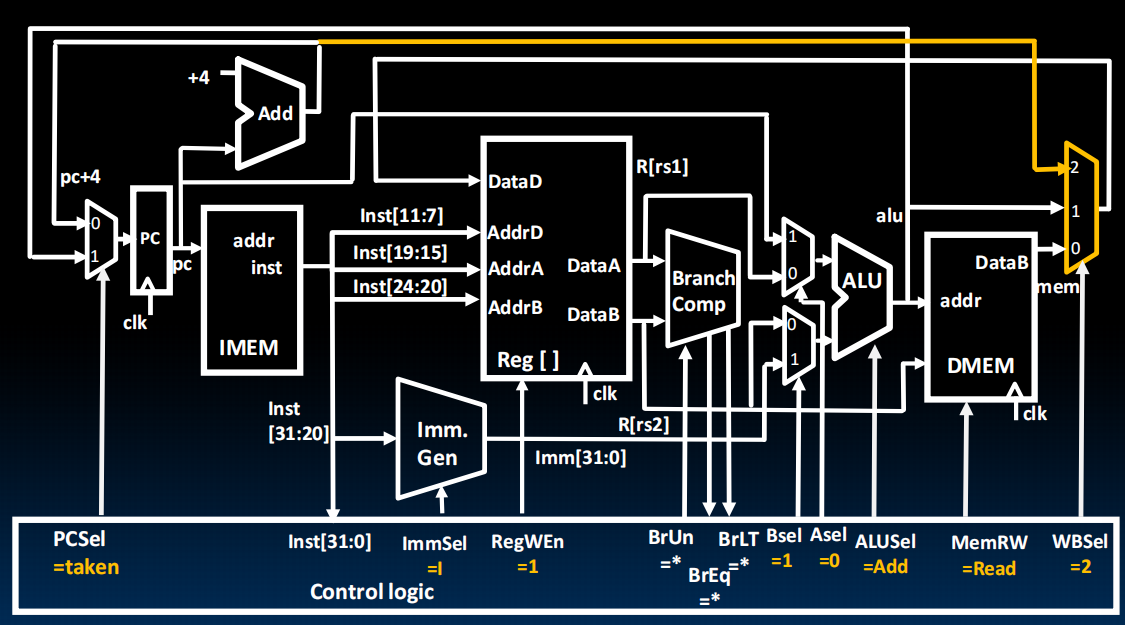
Datapath for JAL(Jump and Link)

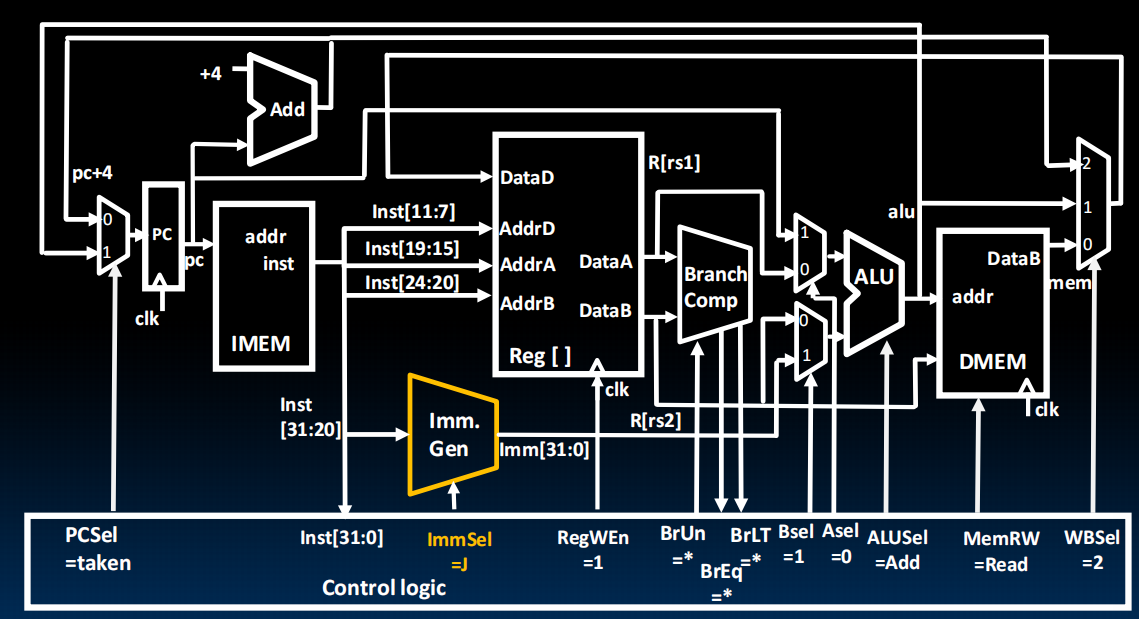
U-Type Datapath
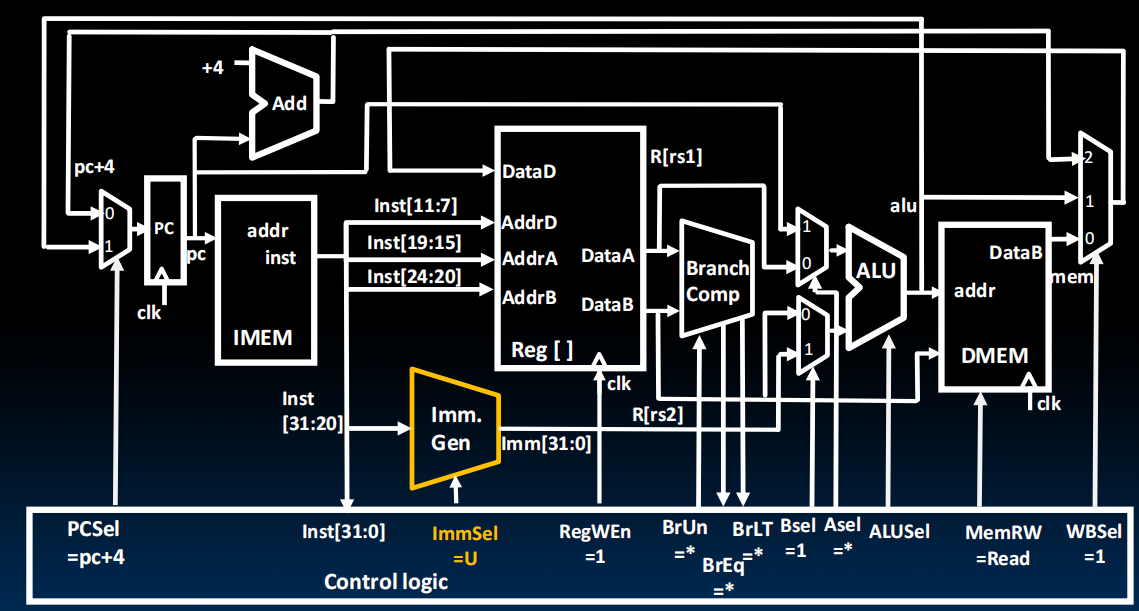
最终,我们得到了最后的设计图:
lec20-Single-Cycle CPU Control
Control and Status Registers(CSRs)
很多的CSR寄存器,没有我们核心的那32个那么快。
不属于ISA

csrrw:write csr中的到rd,read rs中的到csr中

rs存的不是register地址,而是立即数

ecall 和 ebreak

Instruction Timing

Control Logic Design
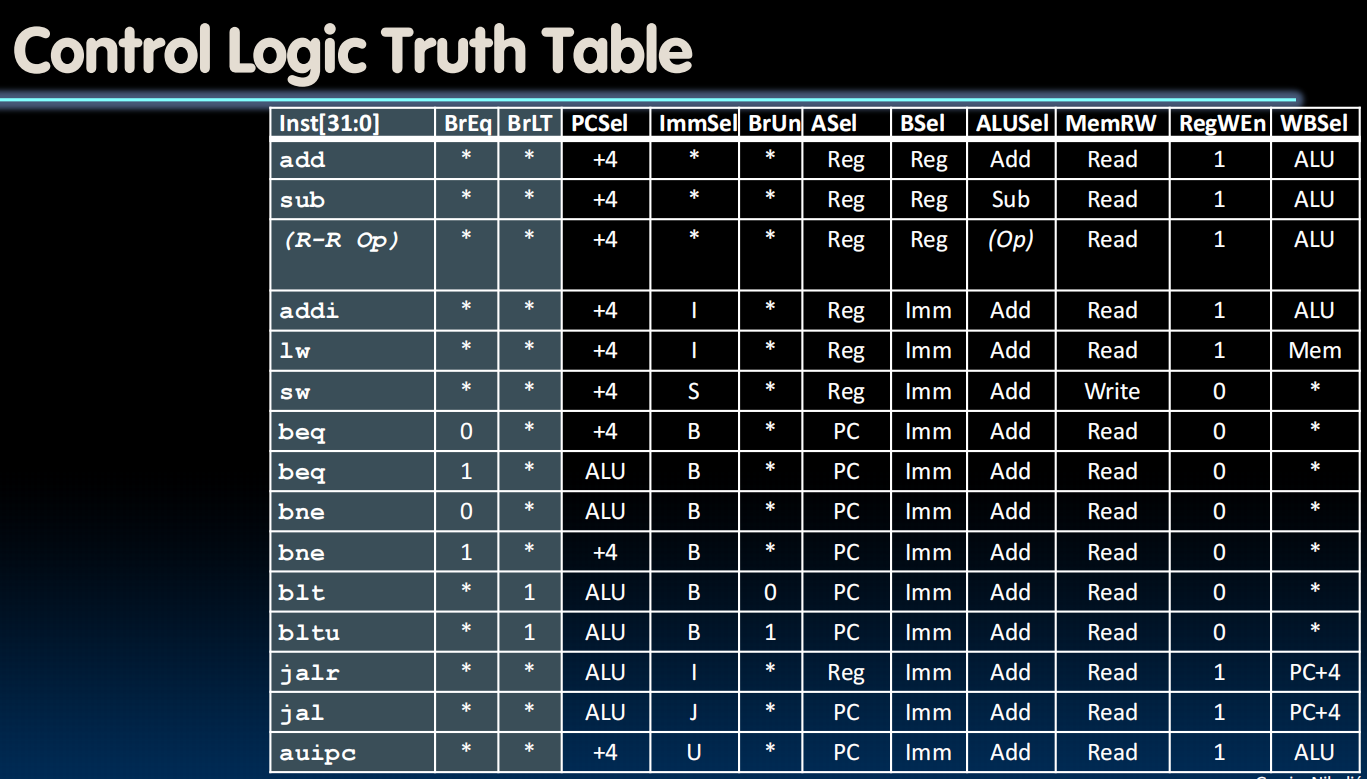

第二种更快:理解为一个小型的ISA:只用看9位(加上BrEq,BrLT,11位)
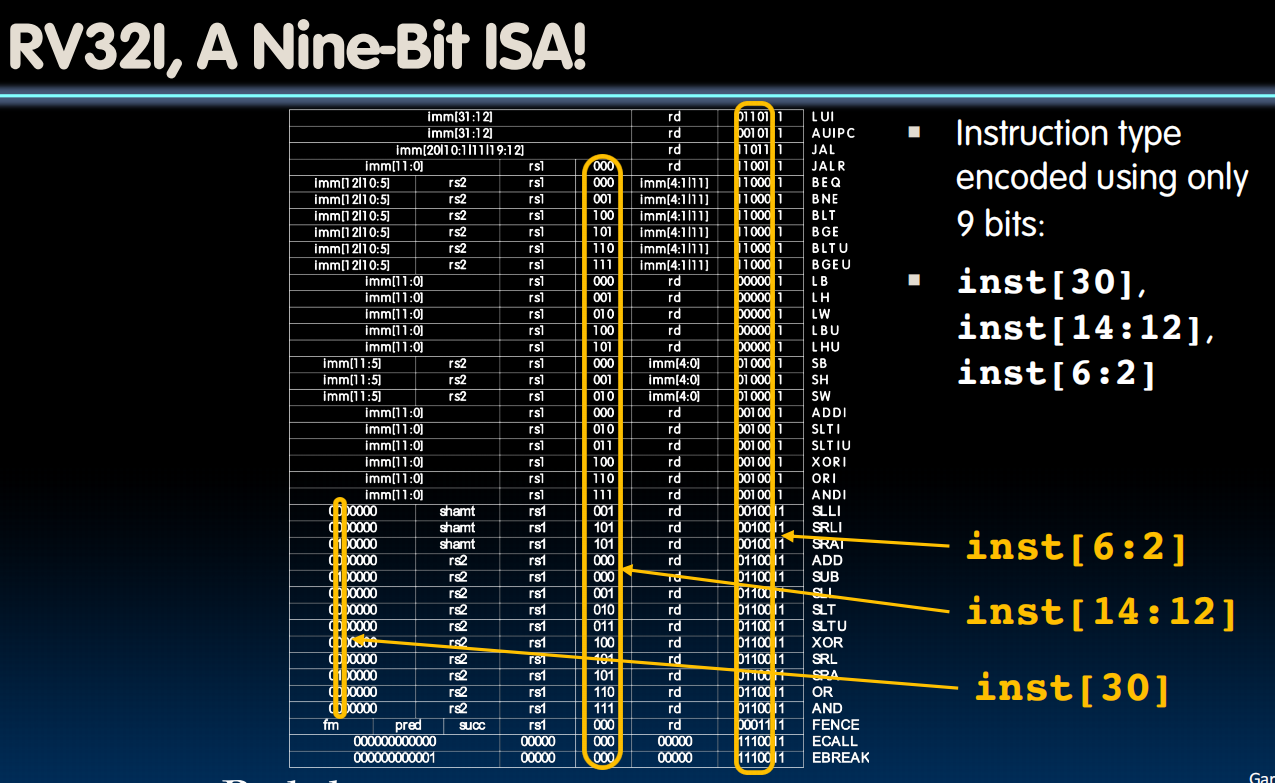
第一种容易:
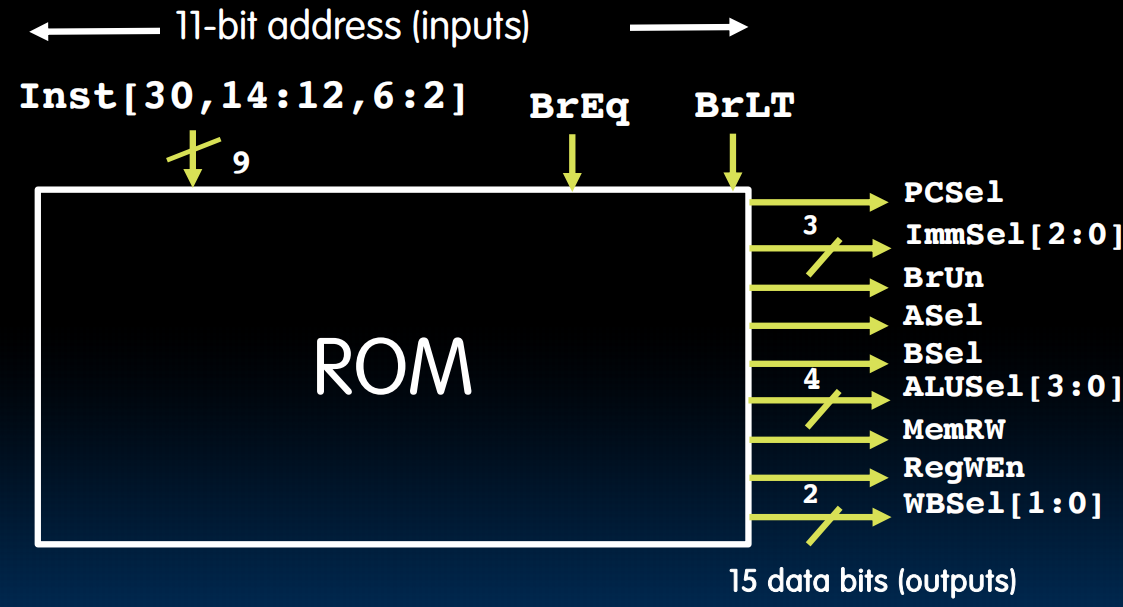
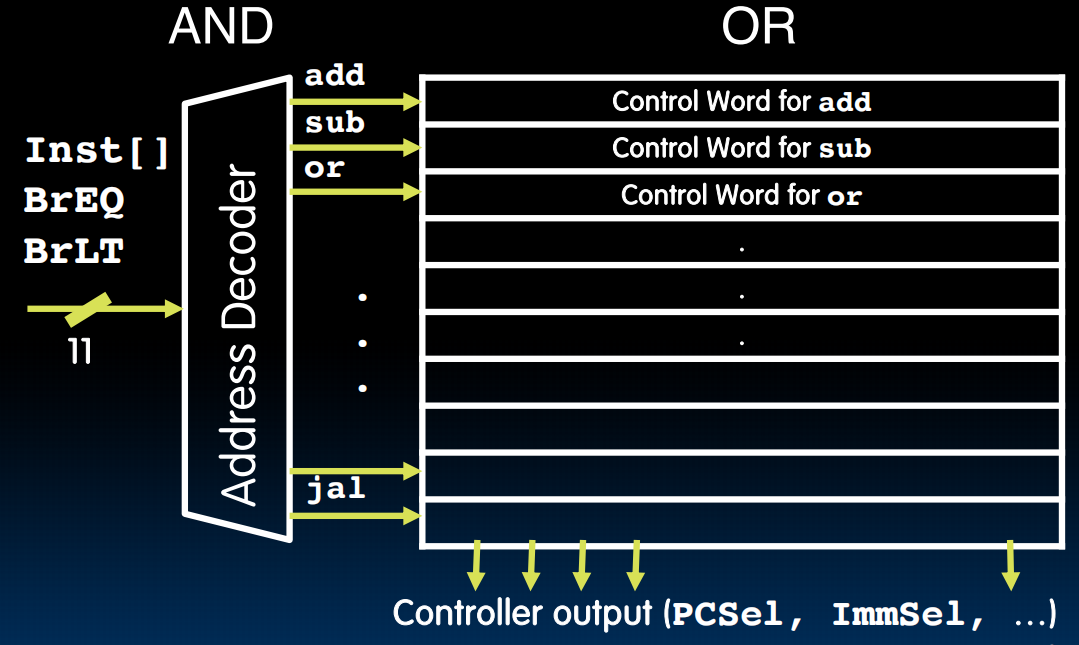
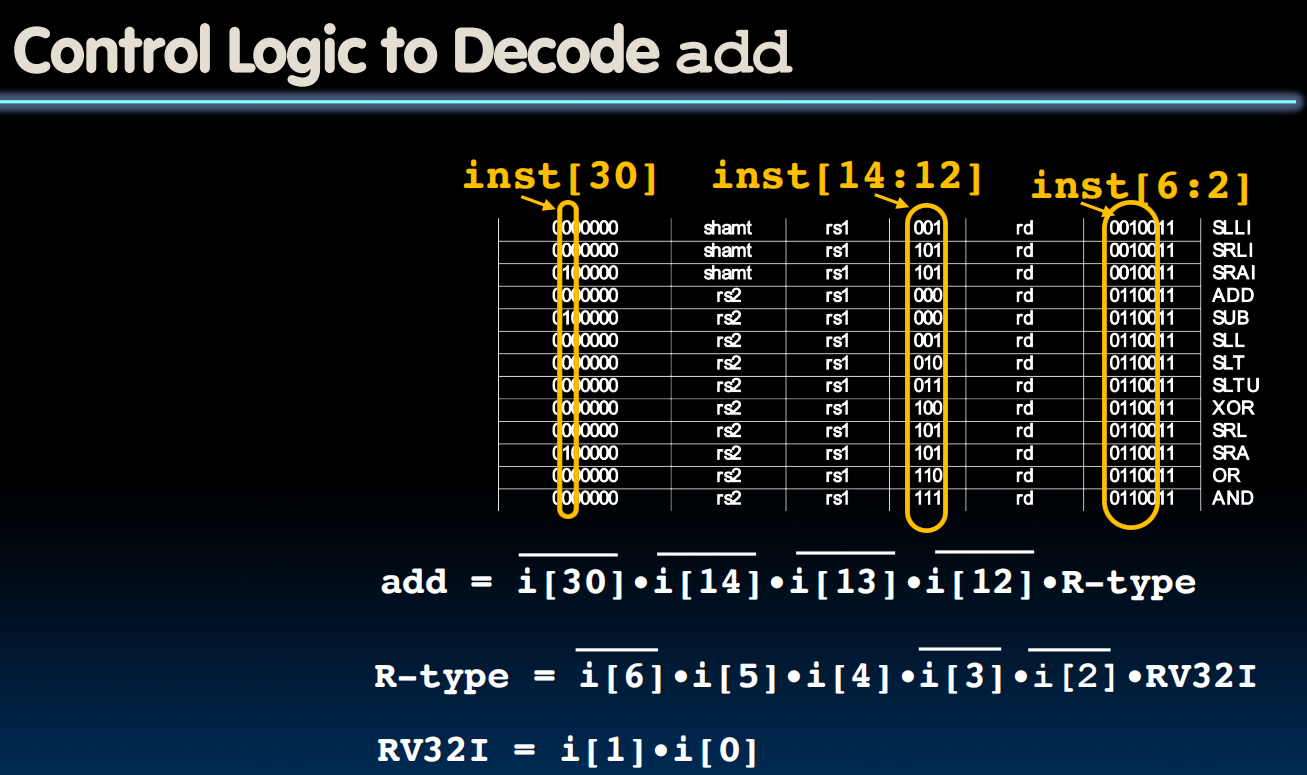
eg.
到目前为止,我们贯通了软件与硬件:这张图从上到下的所有内容我们都已学习!
现在开始到课程结束,我们将优化这个设计并添加一些功能。
lec21-Pipelining I
How to measure performance?

“Iron Law” of Processor Performance
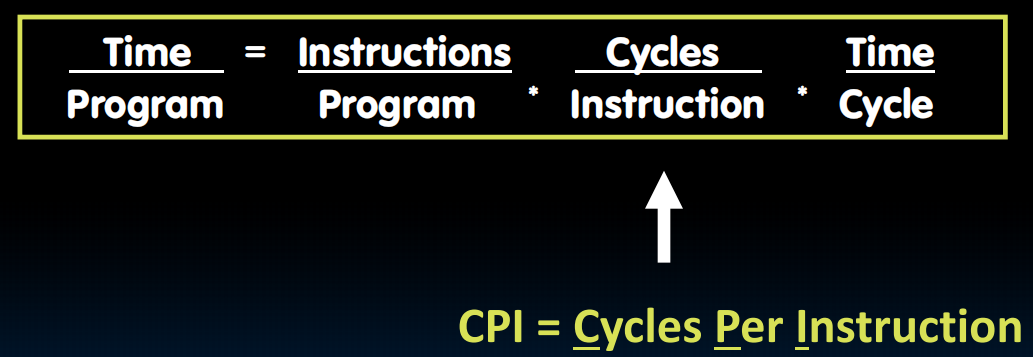
Energy Efficiency
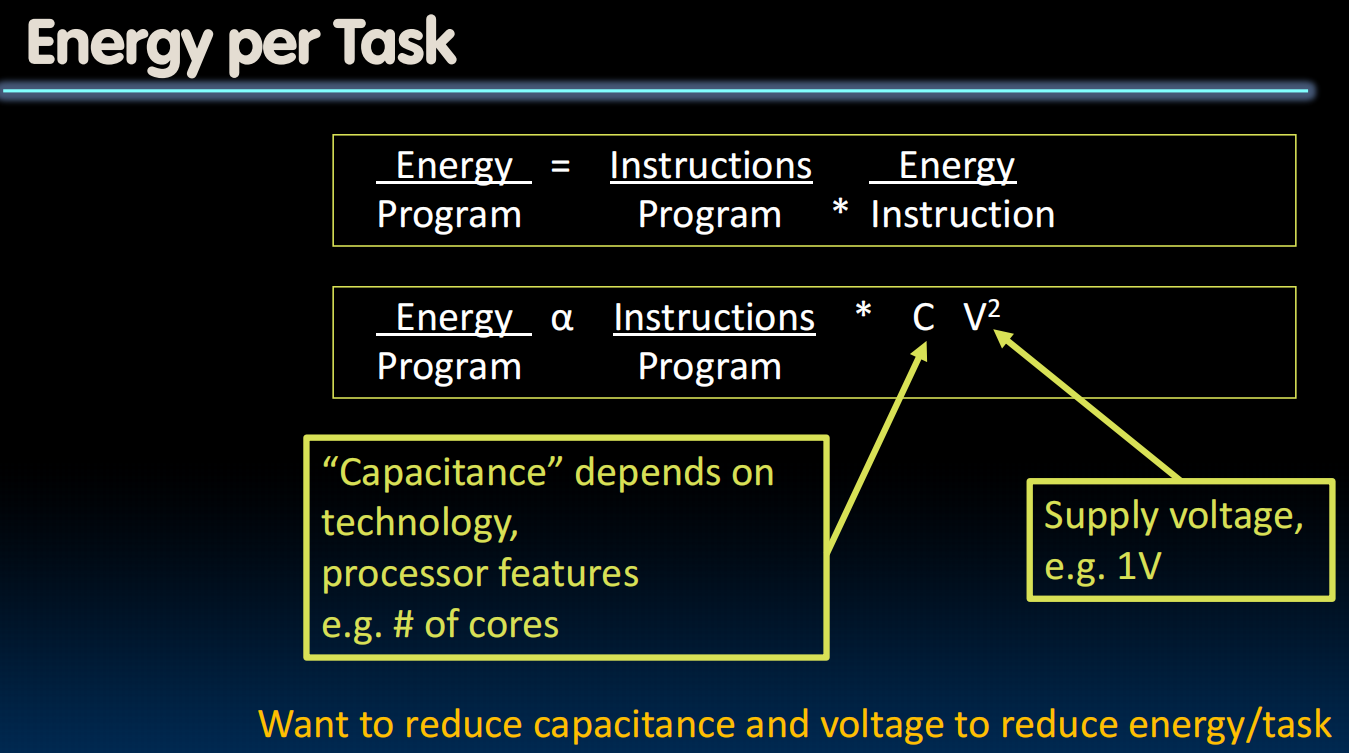

Introduction to Pipelining
提高throughput(吞吐量)
lec22-Pipelining II
Pipelining RISC-V
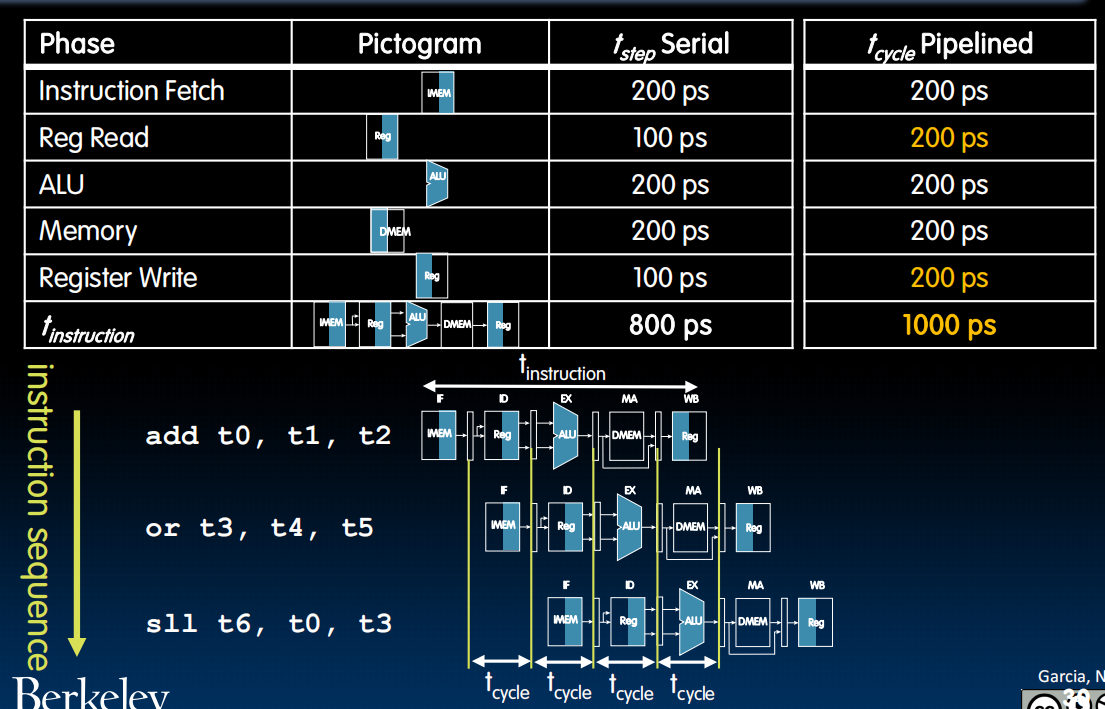
单个指令总时长(周期)变长,但是可以多线程了。
顺序与同时
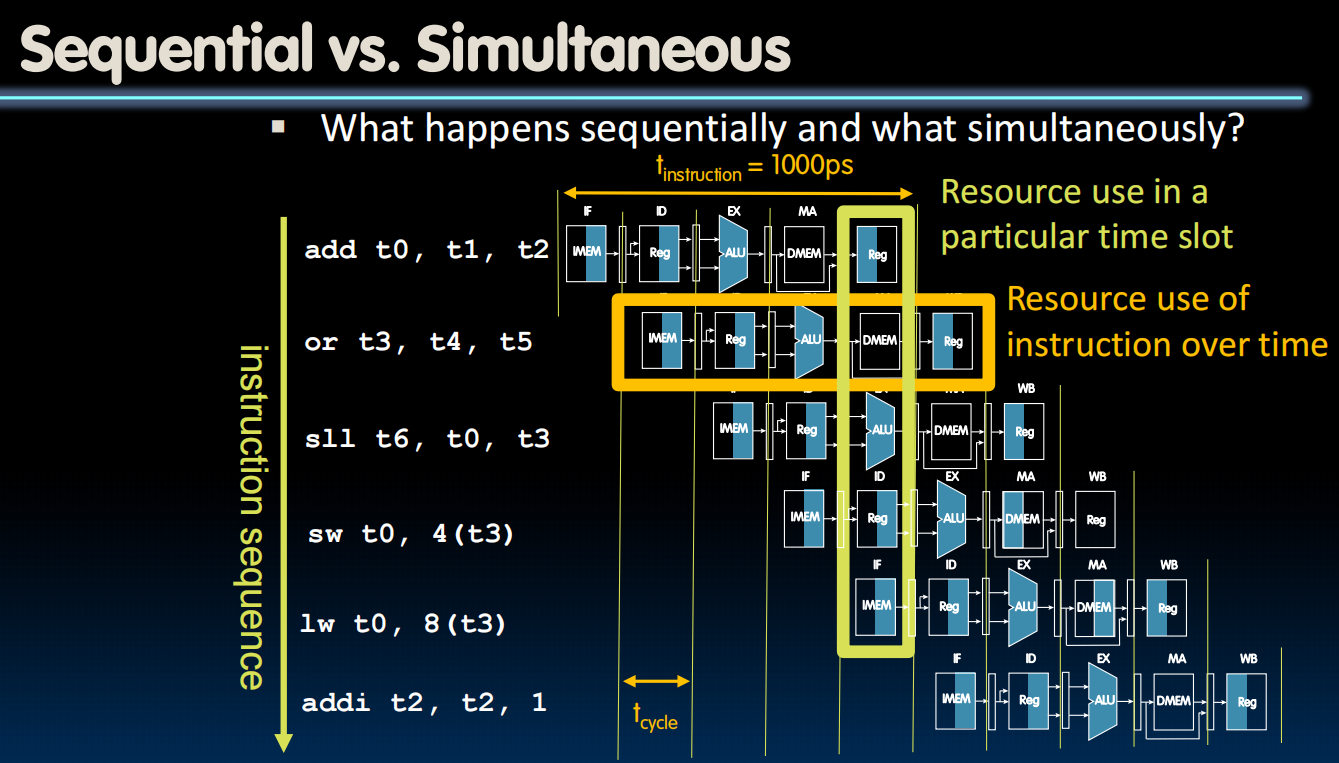
Pipelining Datapath
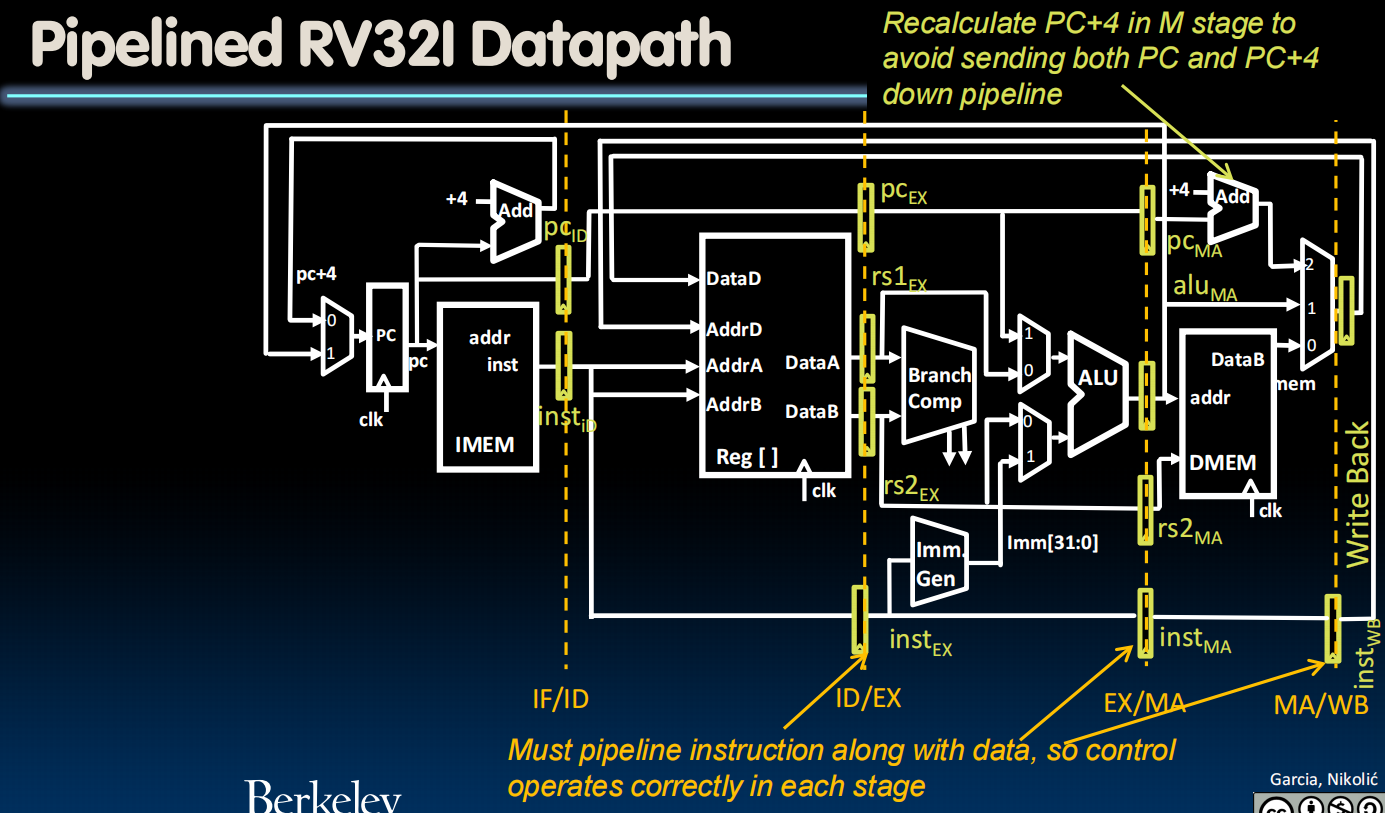
黄色的是 pipeline register ,用于把当前阶段产生的所有结果“锁存”到流水线寄存器中,实现pipeline效果。inst(指令)本身也通过一系列register流传下去。
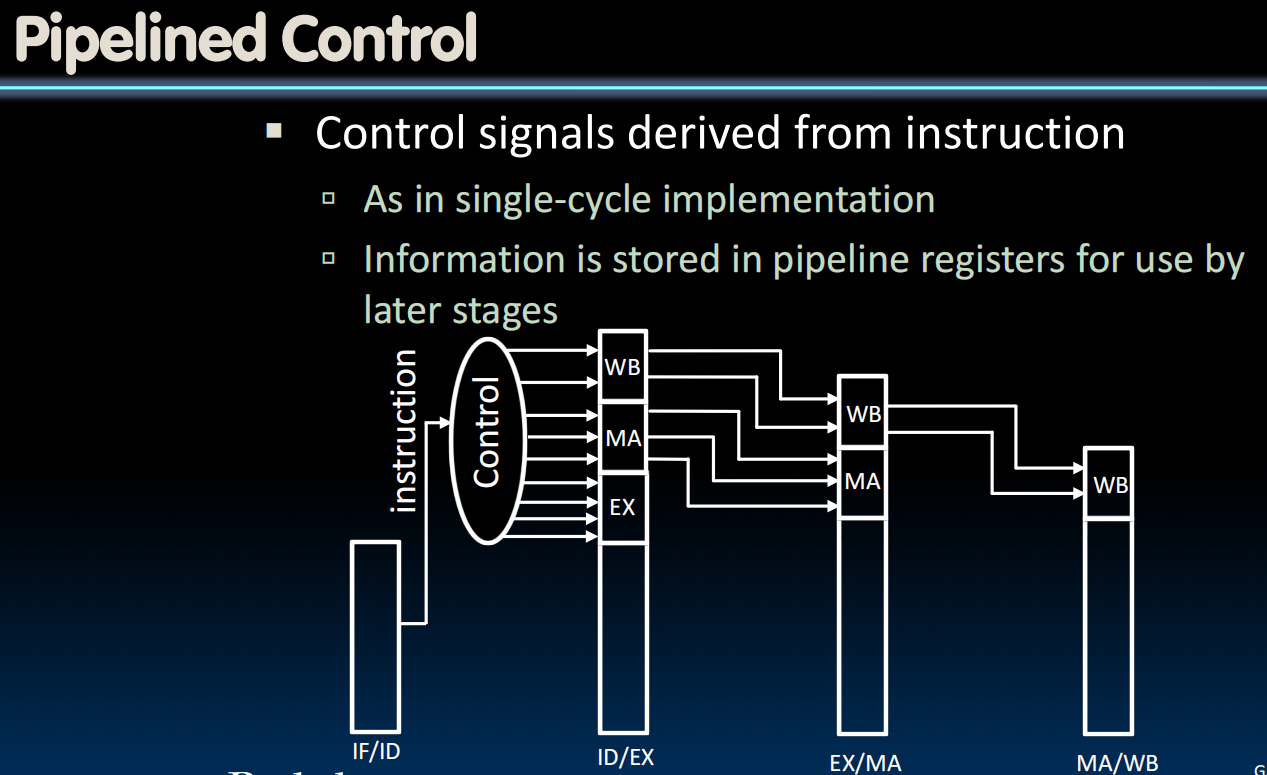
同时,control模块也要pipeline化。
Pipelining Hazards(冒险)

Structural hazard
解决:轮流使用/增加硬件
增加硬件:例如,对于RF有两个读端口和一个写端口
同时访问内存(DMEM和IMEM属于同一个,只有一个)怎么办->用缓存
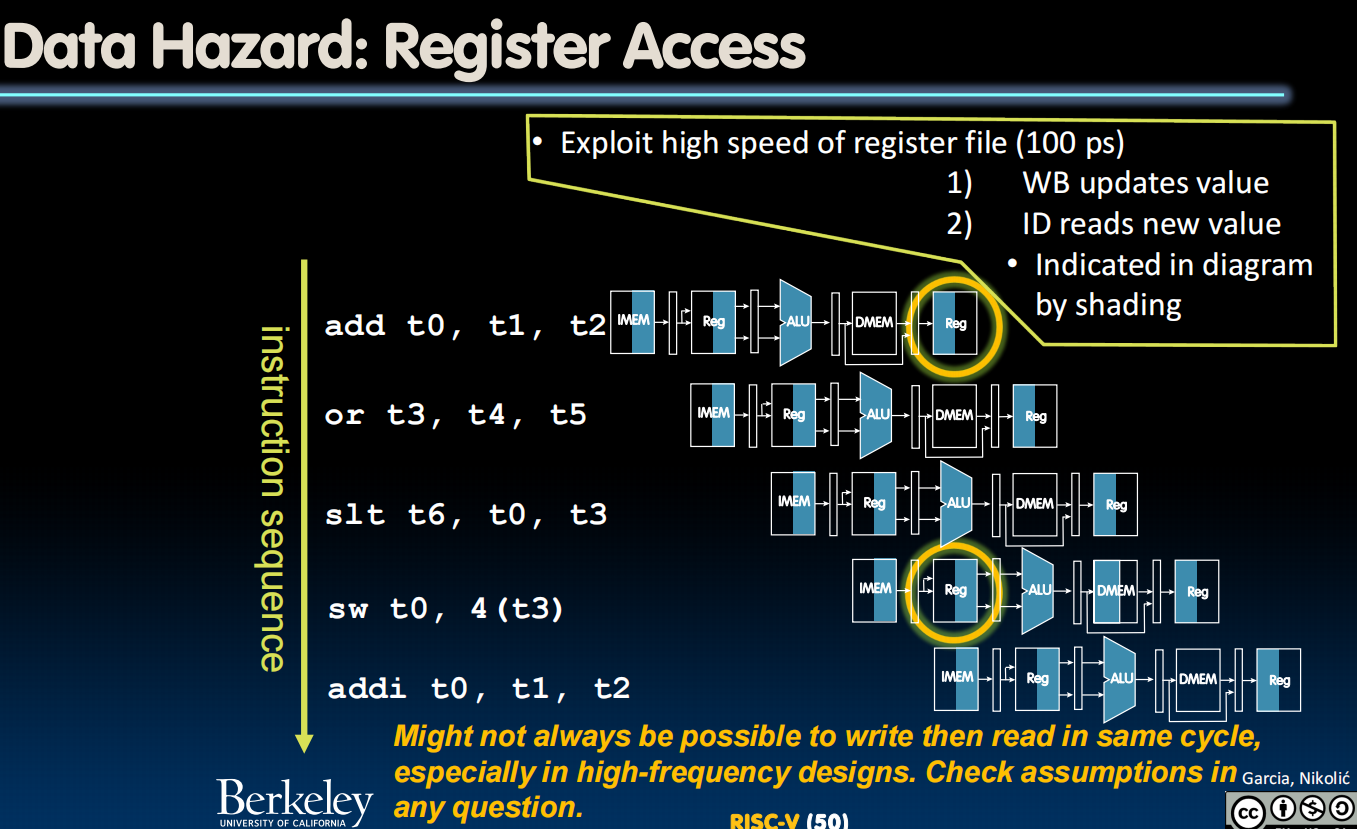
Data hazard
第一个问题:写后读。
多个指令,第一个写东西进s0,同时,第四个读s0。
解决:为了让第四个能够读到第一个指令写进去的东西,应该错峰,在这一个clock内先写后读。
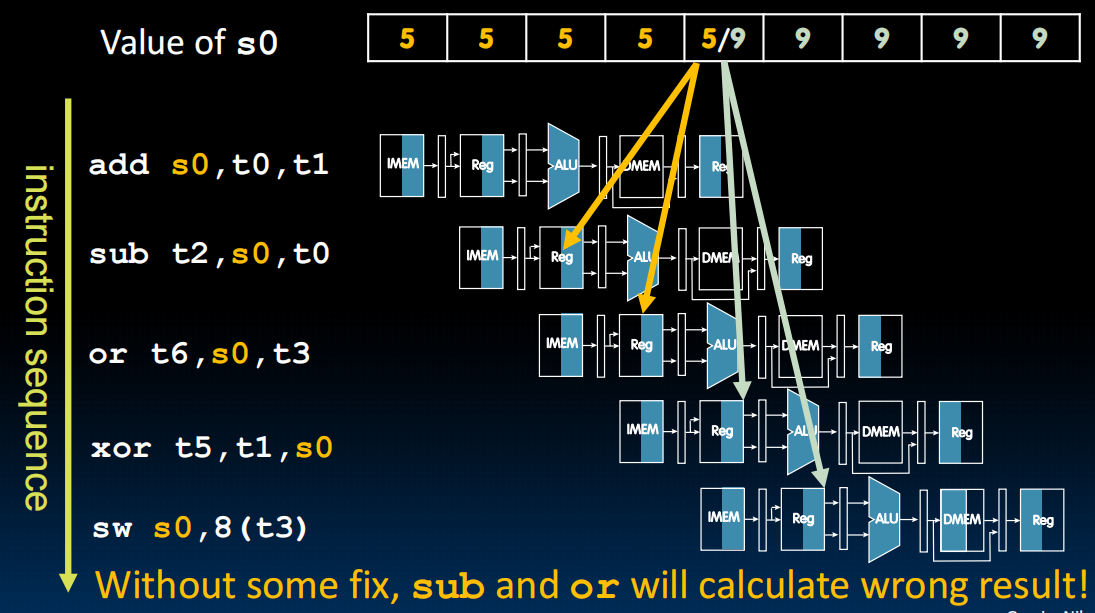
第二个问题:ALU Result
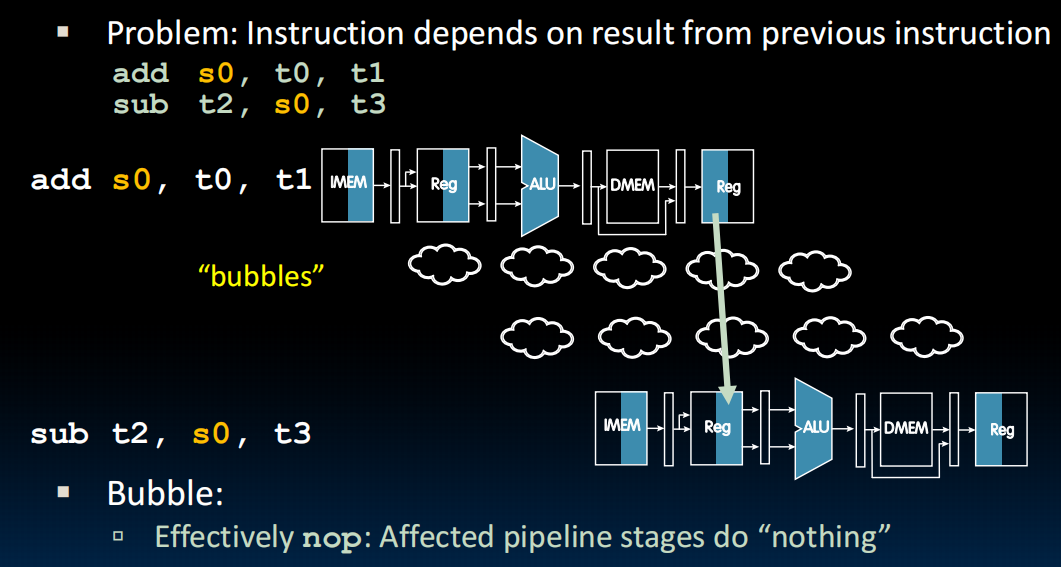
两个指令,第一个把s0中的数+1,第二个把s0中的数copy到s1中。流水线->第二个指令读取s0的时候第一个指令还没写!读到的是没有+1的版本。
解决:法1:“停机”。首先用一些bubbles填充中间的时间,然后我们会尝试找到一些与这个register无关的指令挪到这儿来填充。如果可以那就没事,但是如果没找到的话,只好用 addi x0, x0, 0 填充(nop)

法2:想法:既然数据s0还没被写进去,那一定是在pipeline的某个位置->从旁路拿过来,以便后续的指令立即得到想要的输入而不是等着想要的东西写进register再读出。
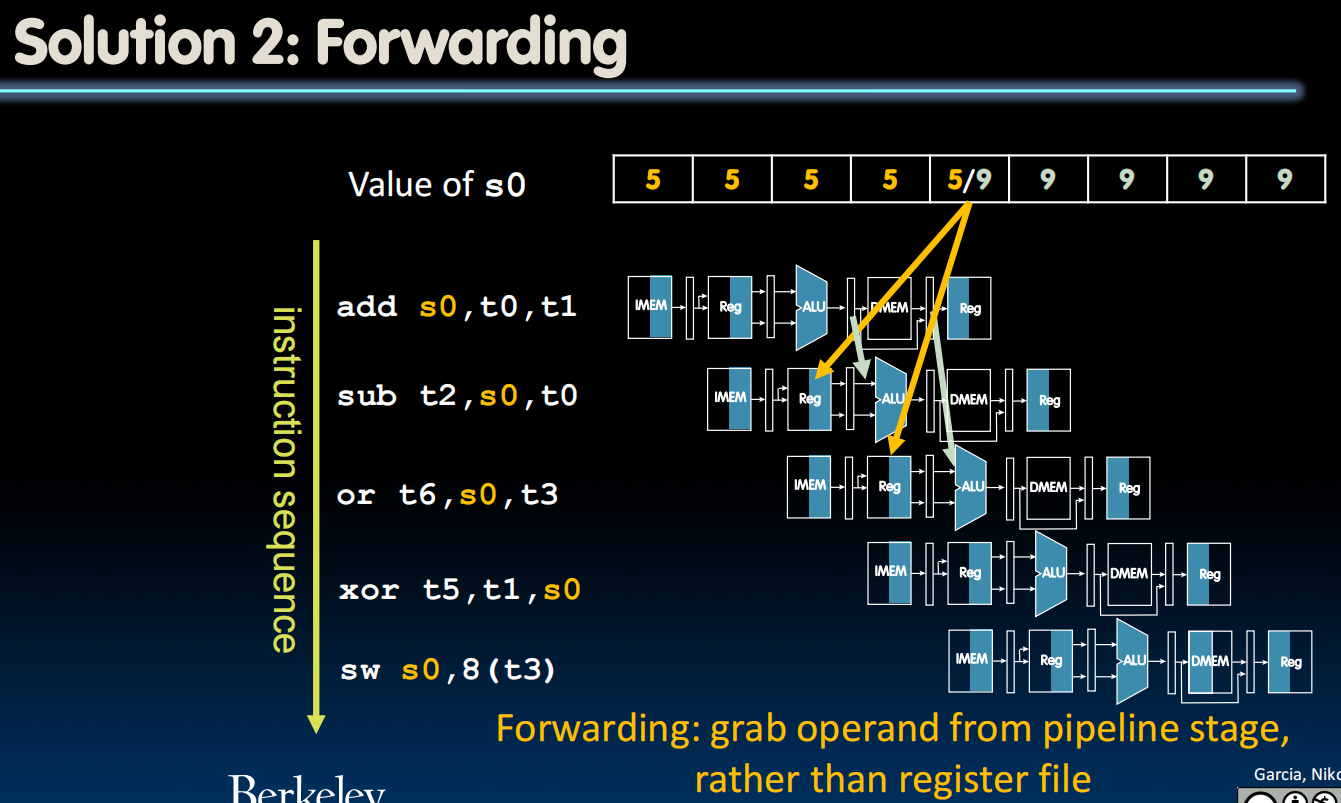
实现较容易,只需要判断前后两个是不是一样的register,会不会发生hazard,会的话就通过转发来拿数据。

在电路中,加几条线路并用一个control的logic来判断:
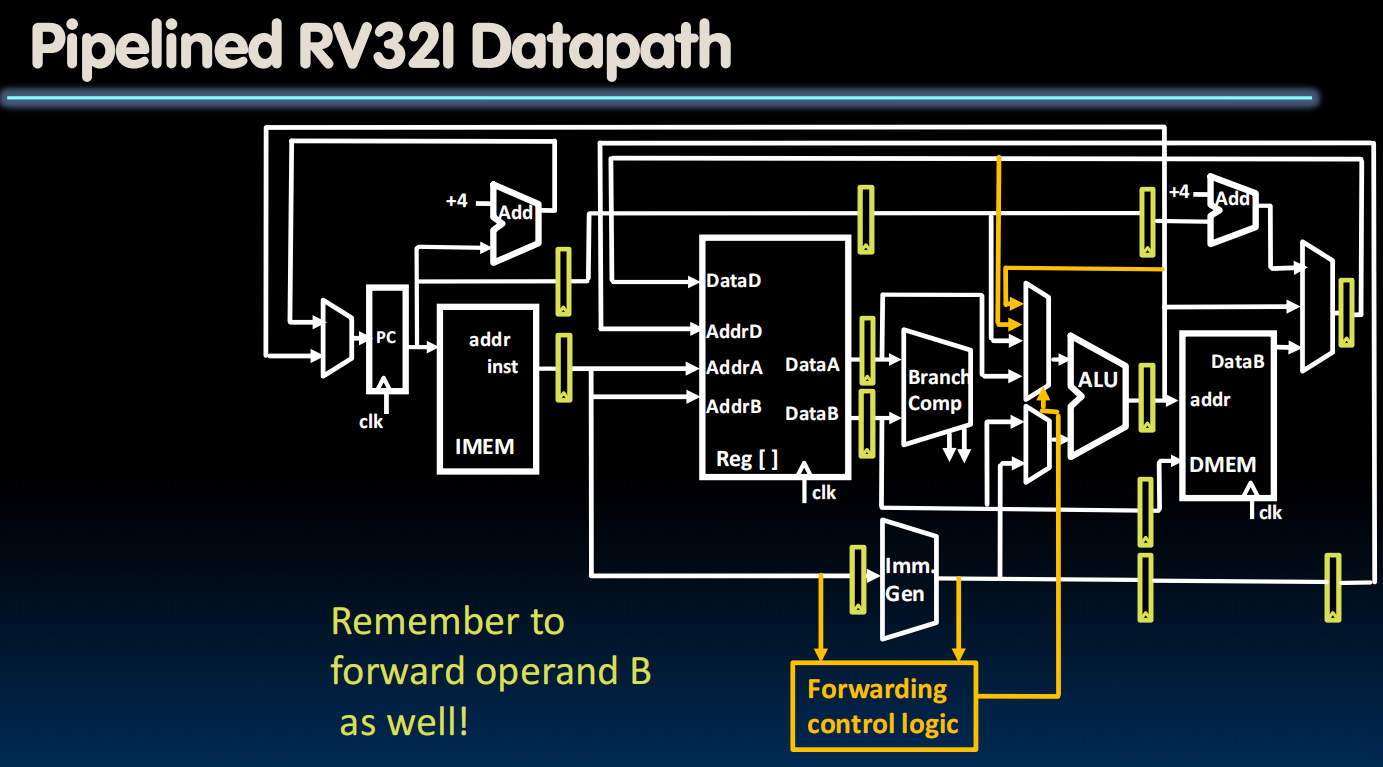
lec23-Pipelining III
Load Data hazard
要读的数据还没有产生!要在下一个时间点才生成,没办法,只好stall了!
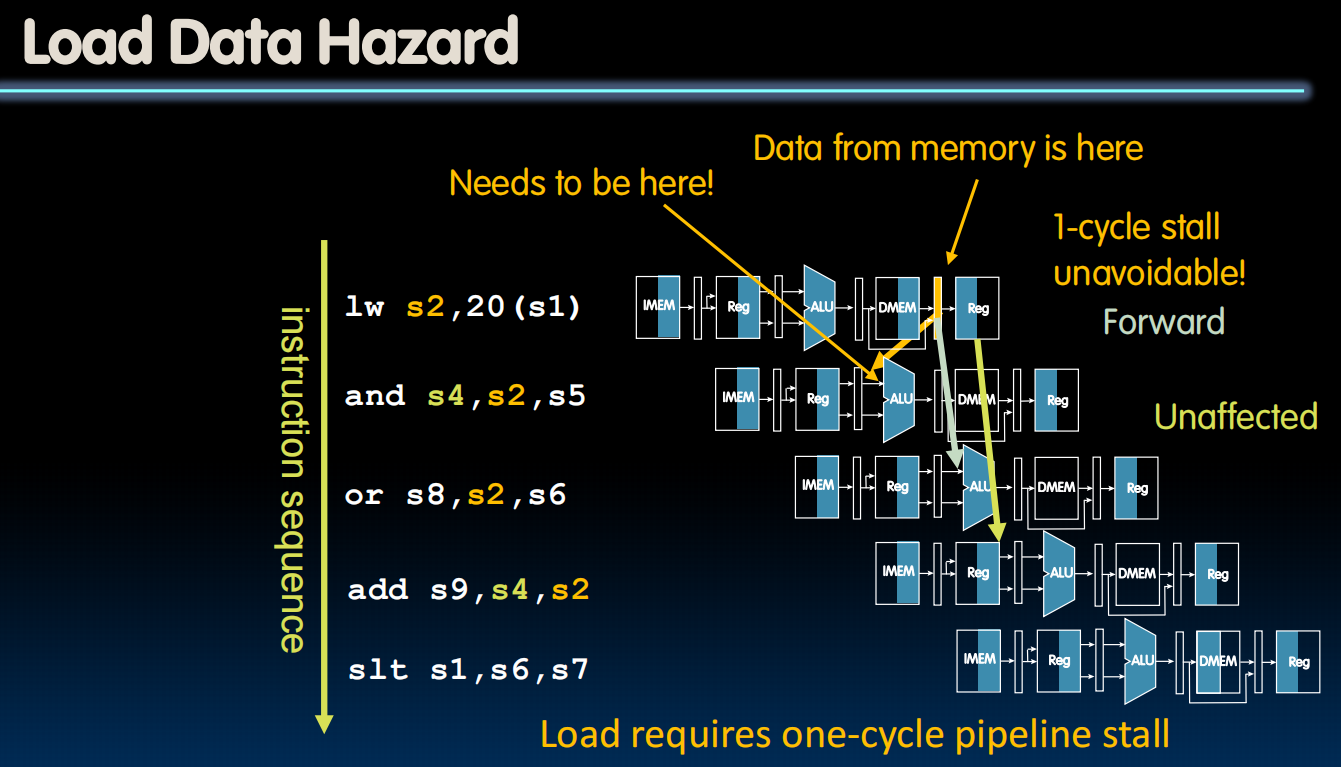
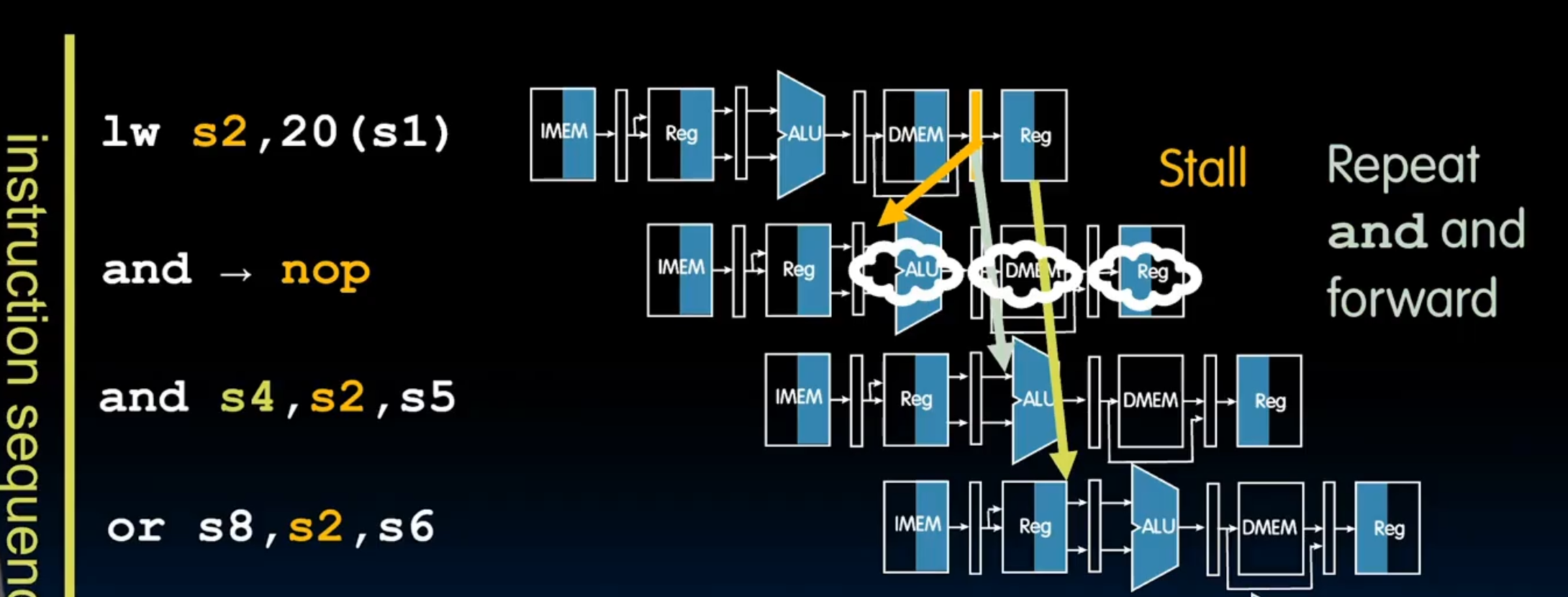
怎么实现stall?创建一个暂停的硬件,然后当发现这个的时候,我们关闭所有控制写入任何地方的写入权限,这样在下一个clock的时候,pc存的指令还是上一个,就好像没发生过一样,有运行一遍,这个时候运行就不会有问题了,可以通过forward正常的修理hazard
同样的,nopaddi x0, x0, 0 填充会增加代码长度,所以我们还是试图用其他无关指令填充。

Control Hazards
最早我们能在ALU之后知道会不会跳转,所以ALU之前不应该运行之后的指令。
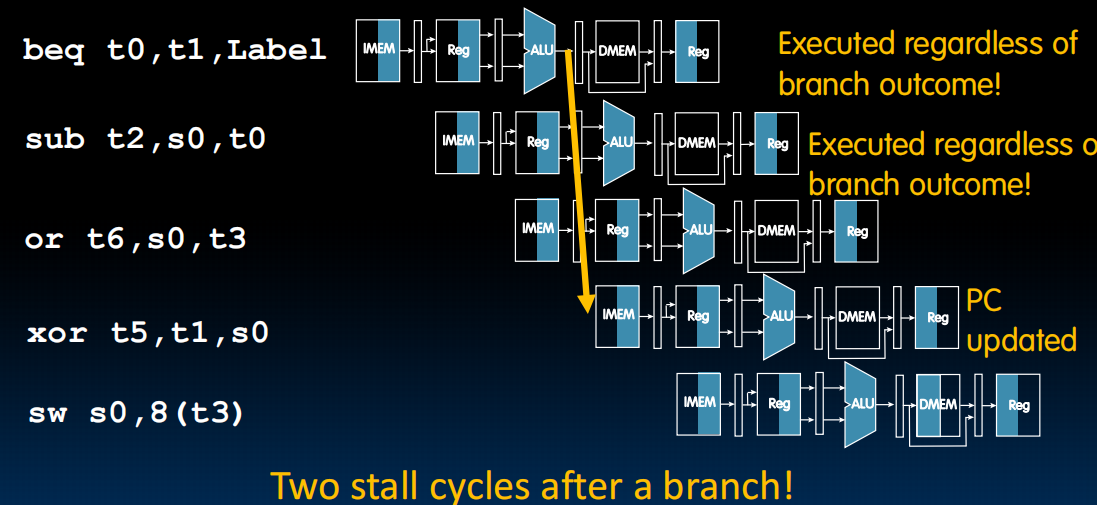
改进:假如我有很大概率不会跳转,那我就可以运行后两个指令,如果跳转了再把后两个改为nop就行。
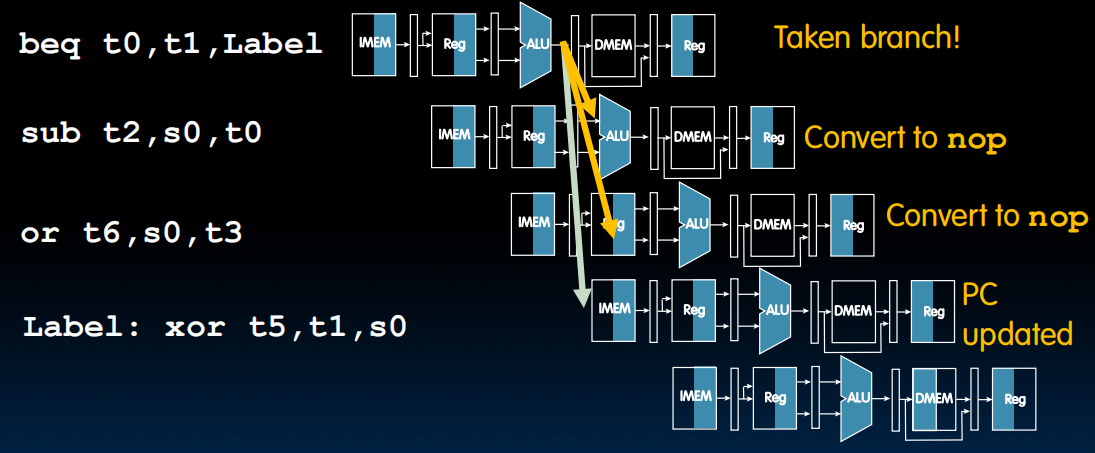
怎么知道跳转概率呢?预测下一次会不会跳转。一个简单的实现是,记录上一次跳转没有。如果上一次跳转了,我就不执行这个优化(不运行后两个),如果没有,我就运行。
这样我们就处理了五级流水中的所有可能的风险情况,这已经是一个性能比较好的CPU了。
Superscalar Processors(超标量处理器)


lec24-Caches I
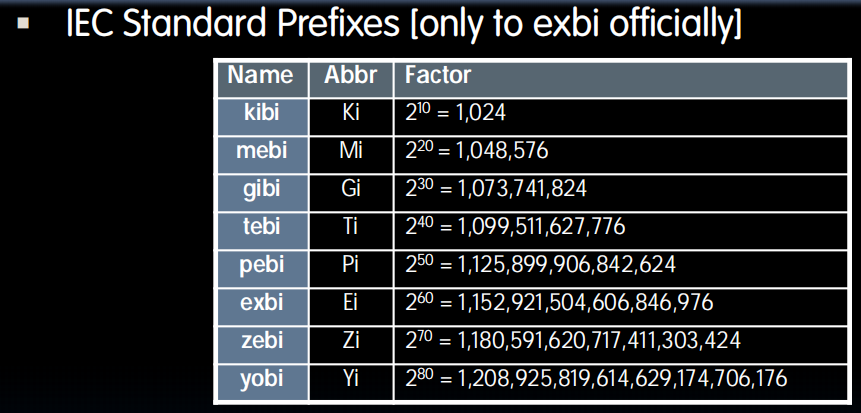
Binary Prefix
Memory Hierarchy
访问内存相当于在图书馆取书,如果我我要不停的用四五本书,我手上只能拿一本,那可能会很慢(不停地取图书馆找书,换书)。但是我现在有一张桌子,离我比较近,上面可以容纳五本书,那我基本上就不用去取书了,偶尔要用到第六本、第七本的时候再取就行,在桌子上放上我最常用的五本,每次取书只需要走两步路走到桌子取,不用费很大力气去图书馆了。

cache始终存的是副本
Locality, Design, Management
Caches work on the principles of temporal and spatial locality(时间和空间上的局部性).

在设计cache的时候要考虑:我们只存副本?地址呢?我们怎么知道它来自哪儿?要是要写入的话怎么写回去?暂略,之后讲。
层级内存之间的交互:

lec25-Caches II
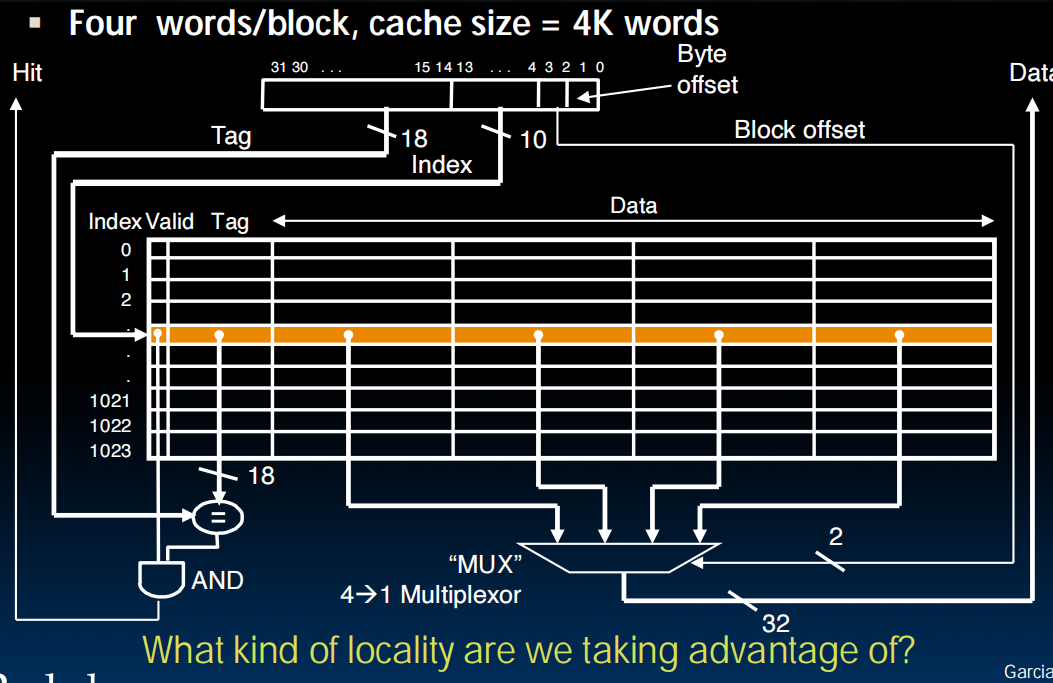
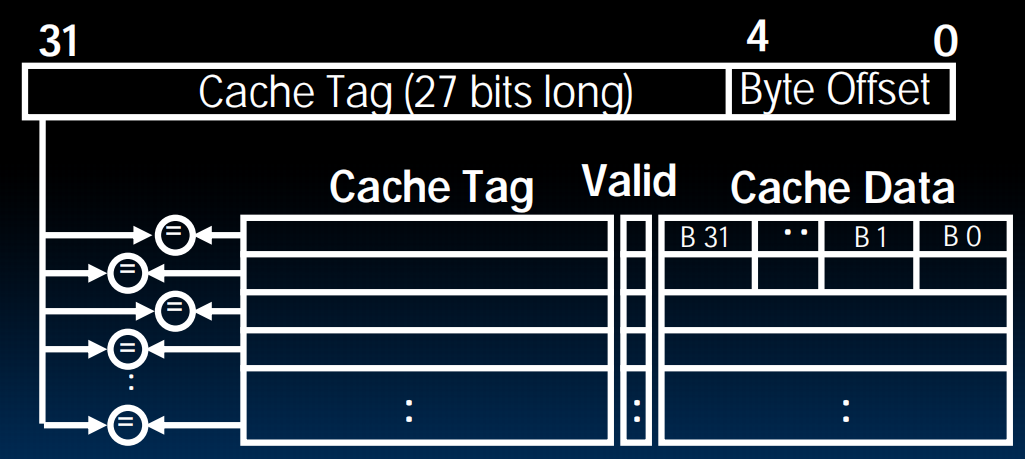
Direct Mapped Caches(直接映射缓存)
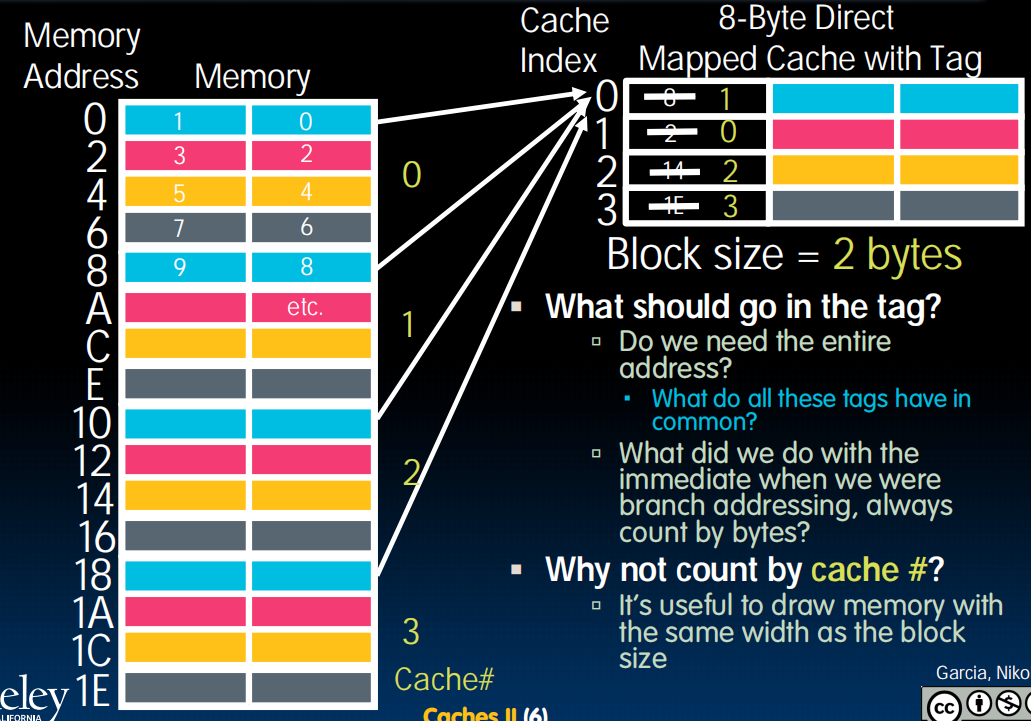
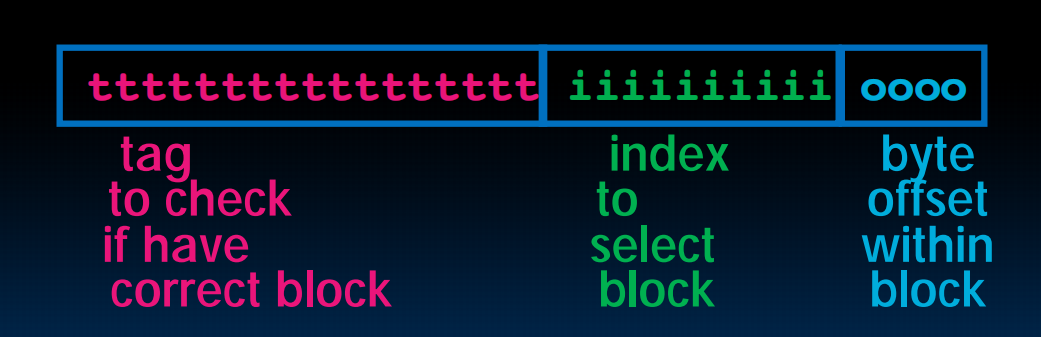
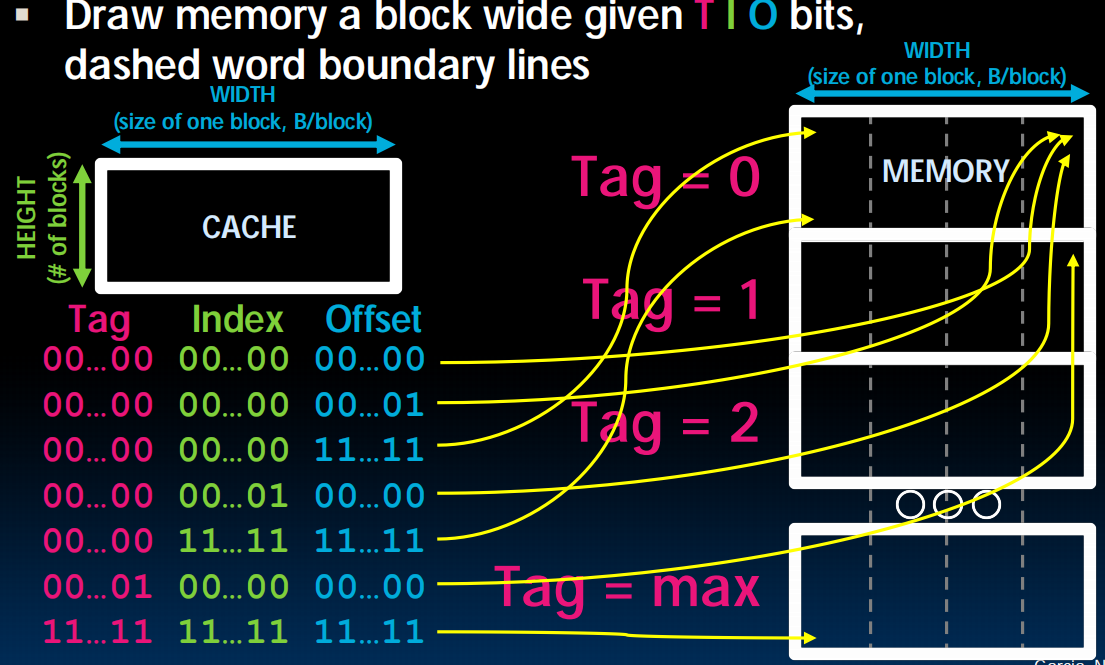
TIO
左边是memory,右边是cache,一行是一个block(这里是一行举例),memory分为4个4个的block,用颜色标识,蓝色的block一定会放到蓝色的cache里。而cache里面的每个数据存了相应的tag,index,offset。index对应于在哪一种block(图中是不同颜色,比如蓝色),offset对应一个block中的哪一列(具体位置,比如01可能就是一个block内的第二个byte),tag对应在是哪个蓝色block,也即,cache的行号。
举例:一个block 2byte,cache 8byte,则需要一位bit确定offset,需要2位bit确定index,剩下的29位都可以用来存tag
CPU访问一个内存地址的全过程是这样的:
- CPU 发出一个完整的内存地址。
- 硬件立刻将地址拆分为
[ Tag | Index | Offset ]三部分。 - 使用 Index:硬件电路根据
Index的值,直接定位到Cache中的唯一一行(比如第8行)。 - 使用 Tag:硬件将地址中的
Tag部分,与第8行中存储的Tag进行比较,看是否匹配。 - 使用 Offset:如果Tag匹配(缓存命中),硬件就从第8行中读出整个Data Block,然后根据
Offset的值,从这个Data Block中精确选择出CPU真正需要的那个字节。
所以cache里面只存tag和数据,不存index和offset
Cache Terminology
名词:



增加一个细节:valid bit
这个地方的信息是有效的吗还是垃圾?比如程序一开始cache里什么都没有,则全是垃圾。每次读取内存的时候用index定位之后先看看是不是valid的,不是的话就不会信任cache里存的东西。

lec26-Caches III
Direct Mapped Example

在读取内存的时候,首先通过index找到对应的行,然后看valid bit,如果不是valid,那么cache miss!那我们就看看tag,到内存里去读取对应的放的东西,读到了这一行的所有内容(不只读一个!这是cache的空间局部性)一起copy到cache中来,然后根据offset确定我们想要的,这里是b,那我们就拿着b回去,cache中就存下了一些neighbors。
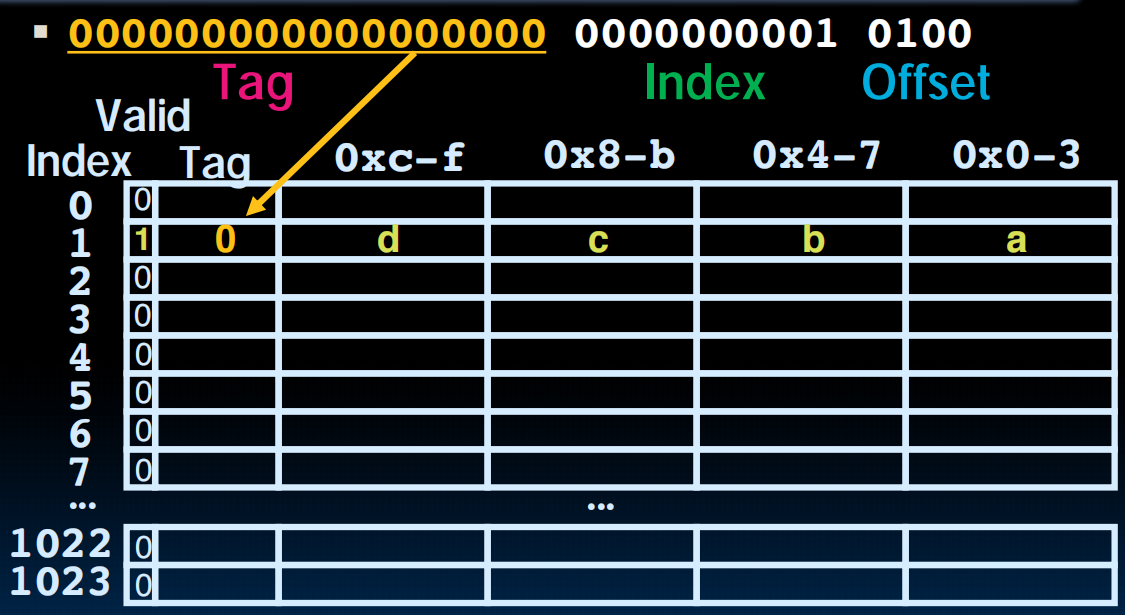
下一次读的时候index valid,tag matches,那就cache hit了,取回d
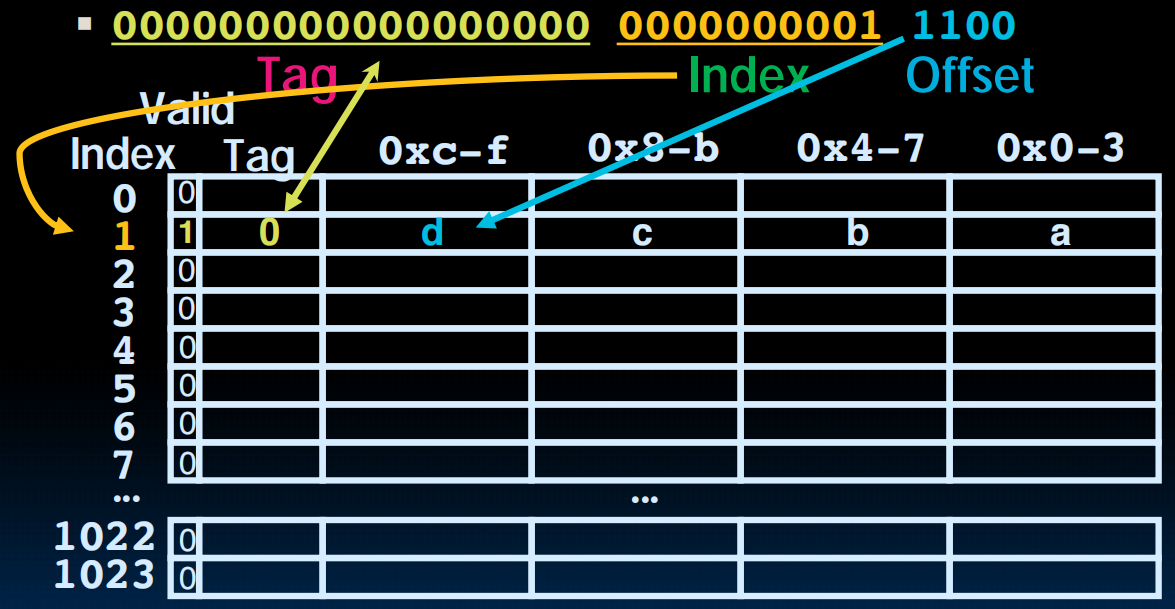
如果index valid,但是tag 没有 match,那我们就把这一行的tag和数据换掉,换成最近这次访问的数据行。
Writes,Block Sizes,Misses
Write
与其每次写入的时候同时写入cache和memory(write-through),有时候不如只写入cache(write-back),然后用一个dirty bit标识:memory里面的东西是旧的!最新版在cache里。当cache的这个block要被replace或者IO(输入输出会刷新缓存)的时候才把所有dirty的写进去。实际上,我们最后的做法是二者结合。

Block Sizes

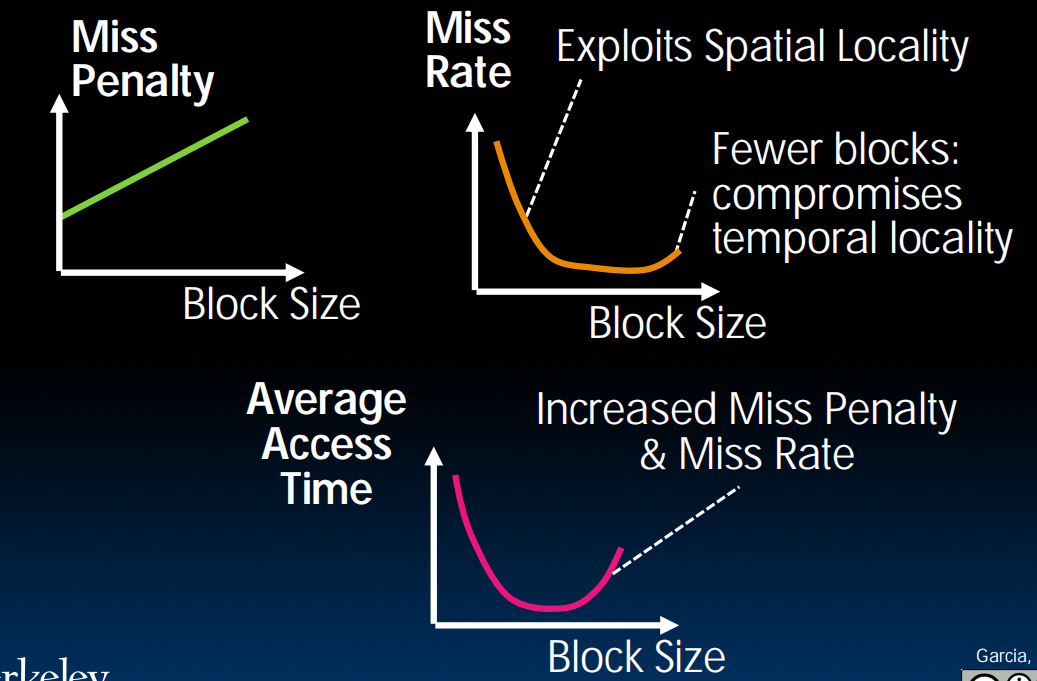
Misses
第一种miss:程序开始时cache里面没东西,不得不miss一次
第二种miss:冲突,两个地址想存在同一个cache的地方。两个blocks互相覆写(可以解决?)
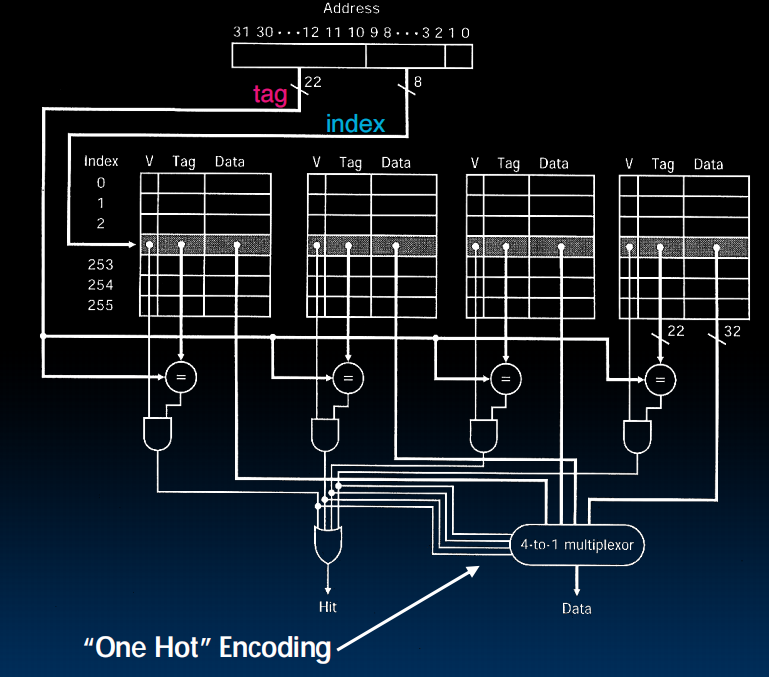
Fully Associative Caches(完全关联缓存)
与Direct Mapped Cache不同,不再有行号——随意放置。
back to miss:第三种miss :capacity misses,缓存大小限制,出现在完全关联缓存中
怎么分类:

lec27-Caches IV
Set-Associative Caches(组相联缓存)
介于Direct Mapped和Fully Associative 之间
N-Way Set-Associative Caches :N blocks in a set (假设cache m blocks, direct mapped = 1-way,fully Associative = m-way)


Block Replacement

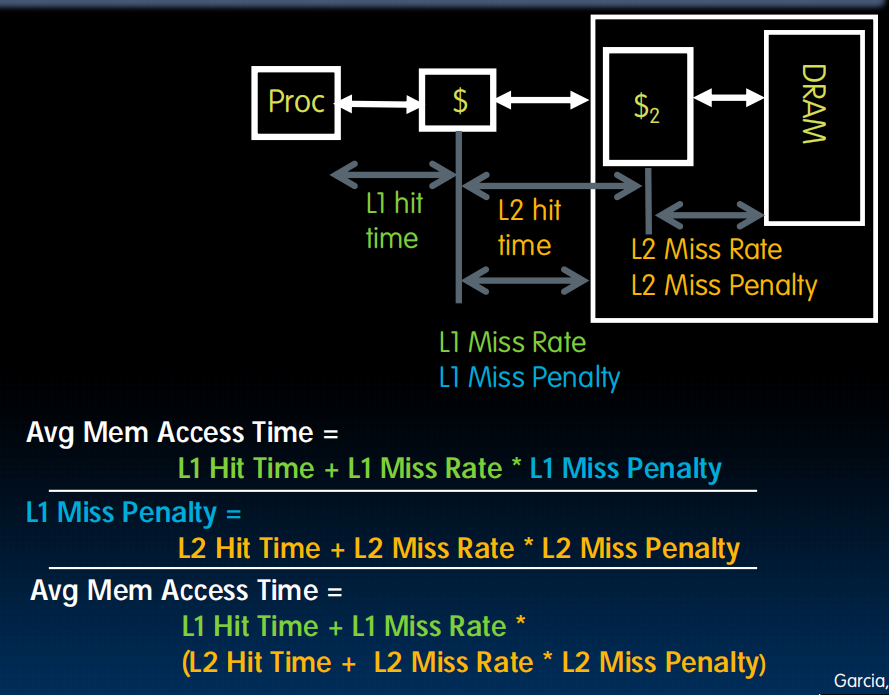
Average Memory Access Time(AMAT)
衡量不同设计的缓存性能怎么样。

miss了的话要取出来然后再hit一遍,所以hit time不需要乘hit rate
增加多层cache:
Actual CPUs

i7:L2每个·core各一个,L3共享

(lec28~31) OS and Virtual Memory
lec28-OS & Virtual Memory Intro
接下来将讨论的部分:
Operating System Basics

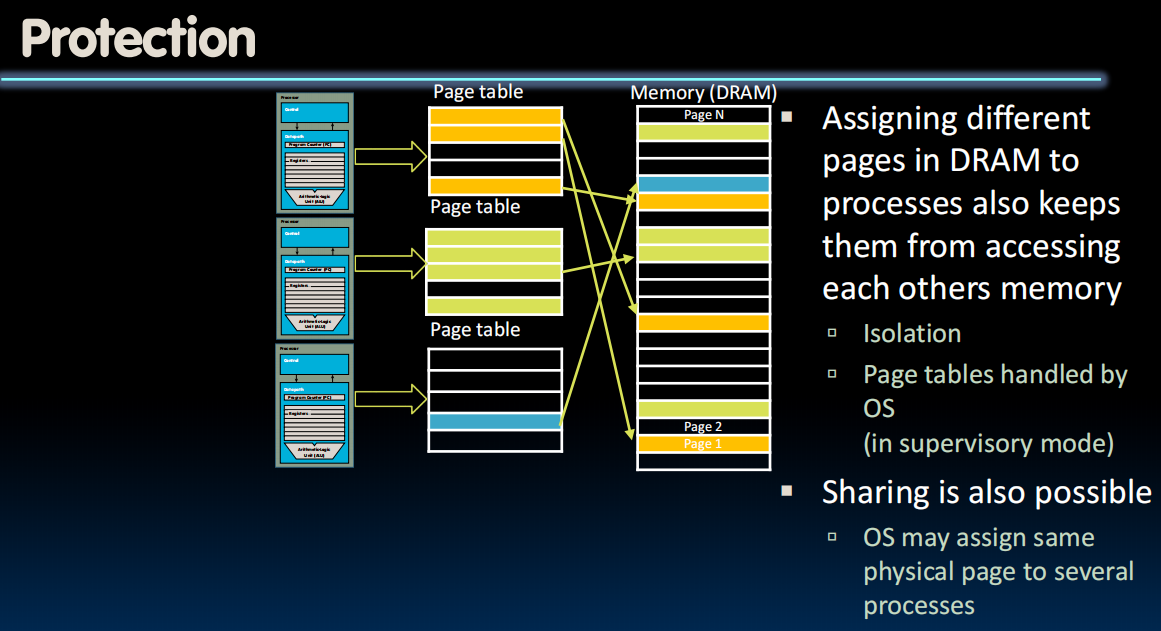
当有很多不同的程序想要访问同一个地址的时候,会出错,所以我们访问的实际上是虚拟内存,操作系统会把这个虚拟内存转换为不同的物理内存防止冲突
保护与权限(用户模式、机器模式、管理模式)

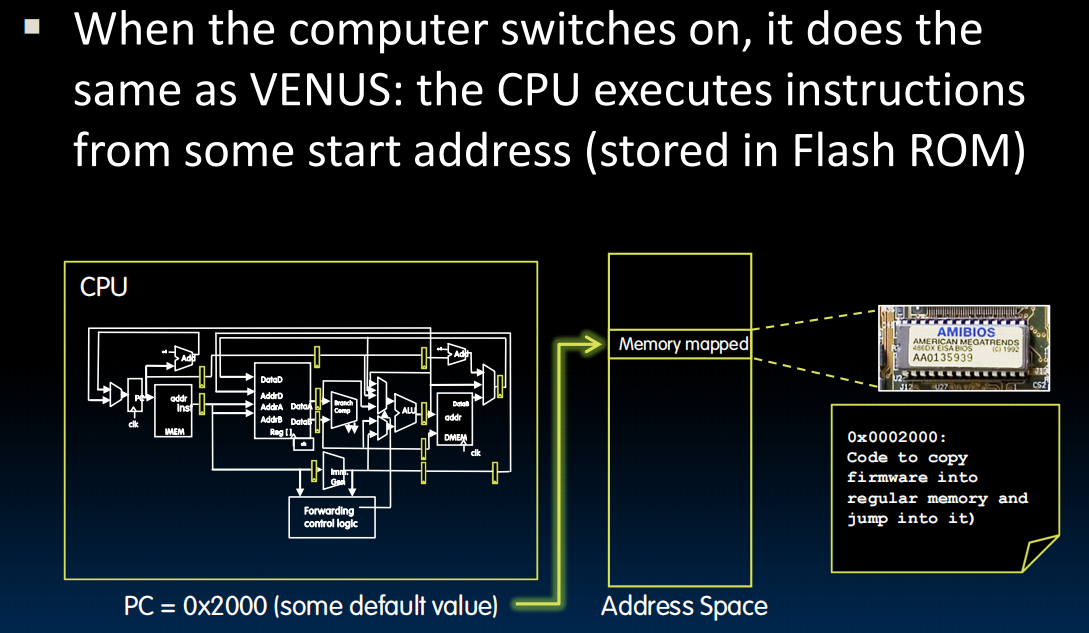
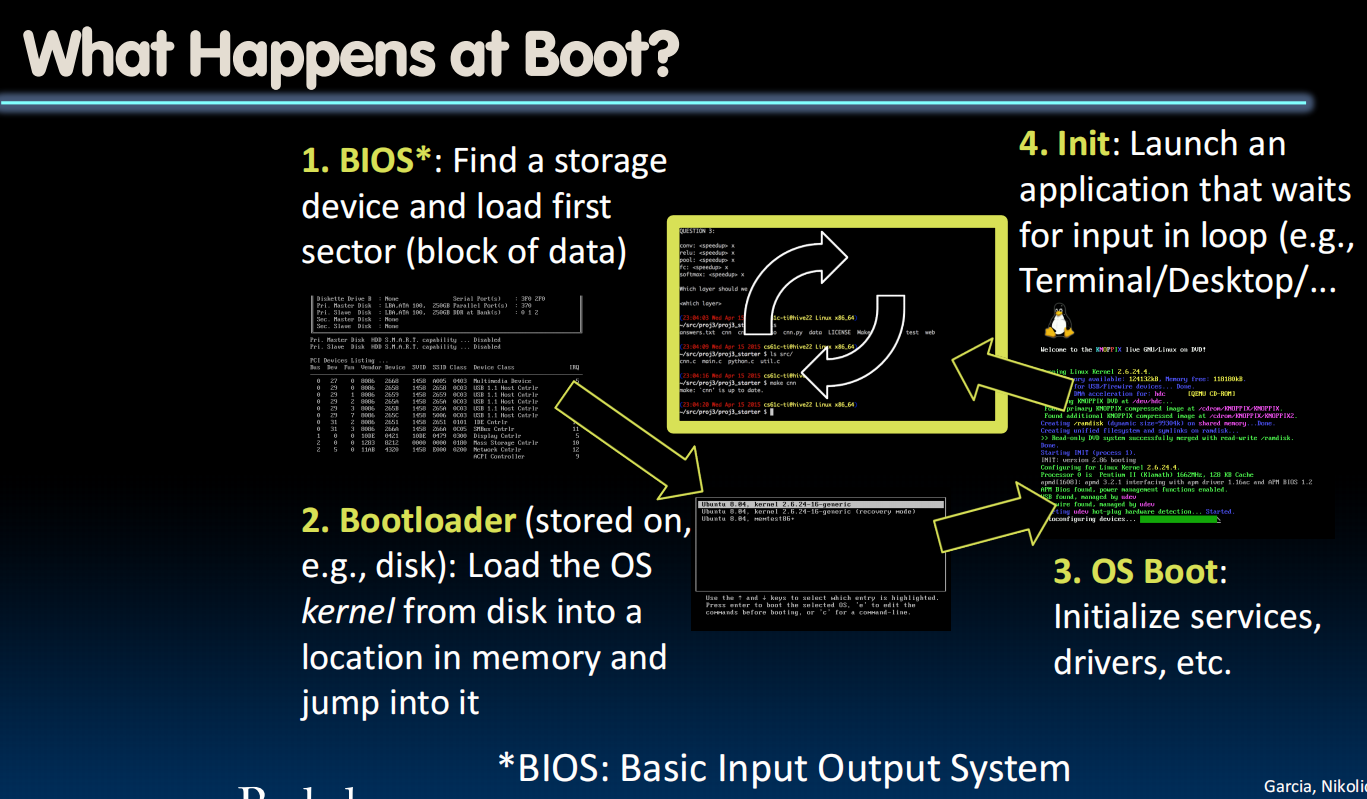
boot(引导/启动)过程:
Operating System Functions
(综述性质)具体每个内容要在之后细讲。




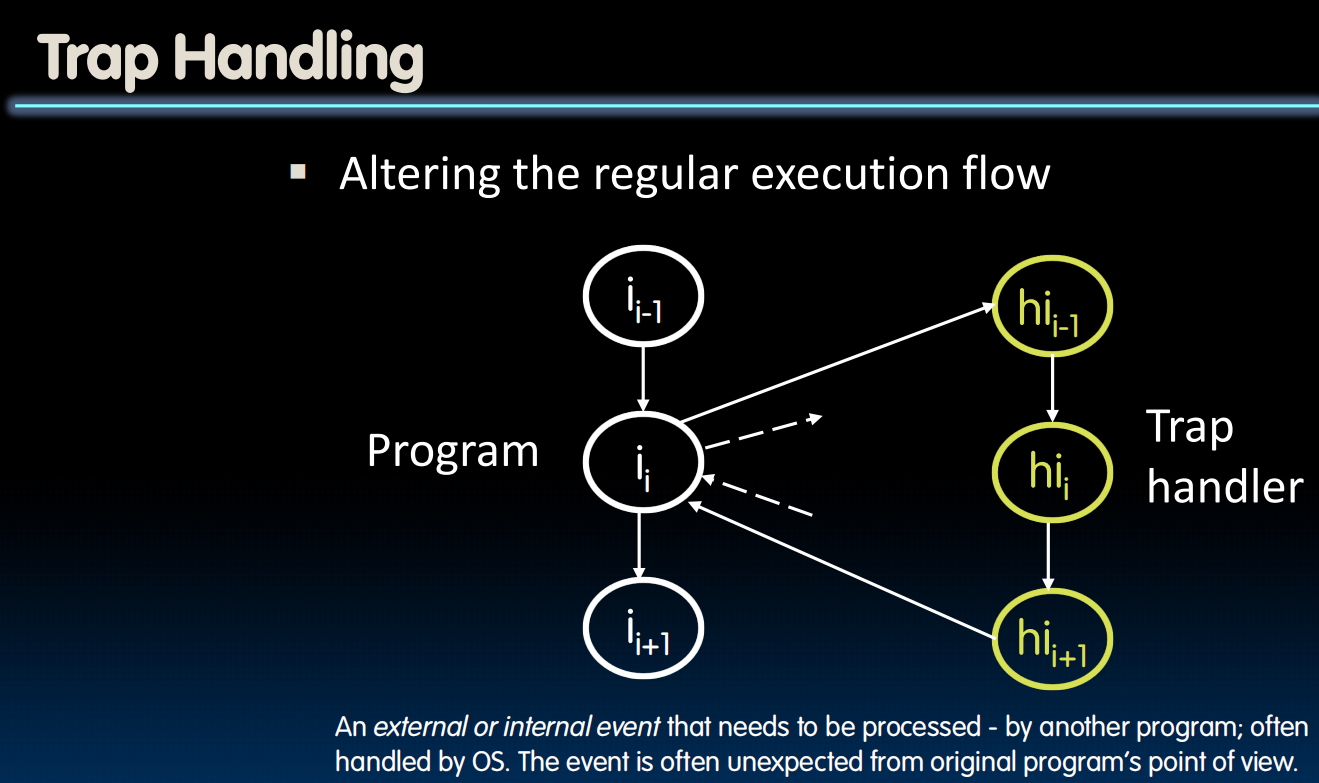
先存储所有register的状态,然后跳转到trap handling,handle之后再恢复所有的状态,假装什么都没有发生(换成nop等方式)
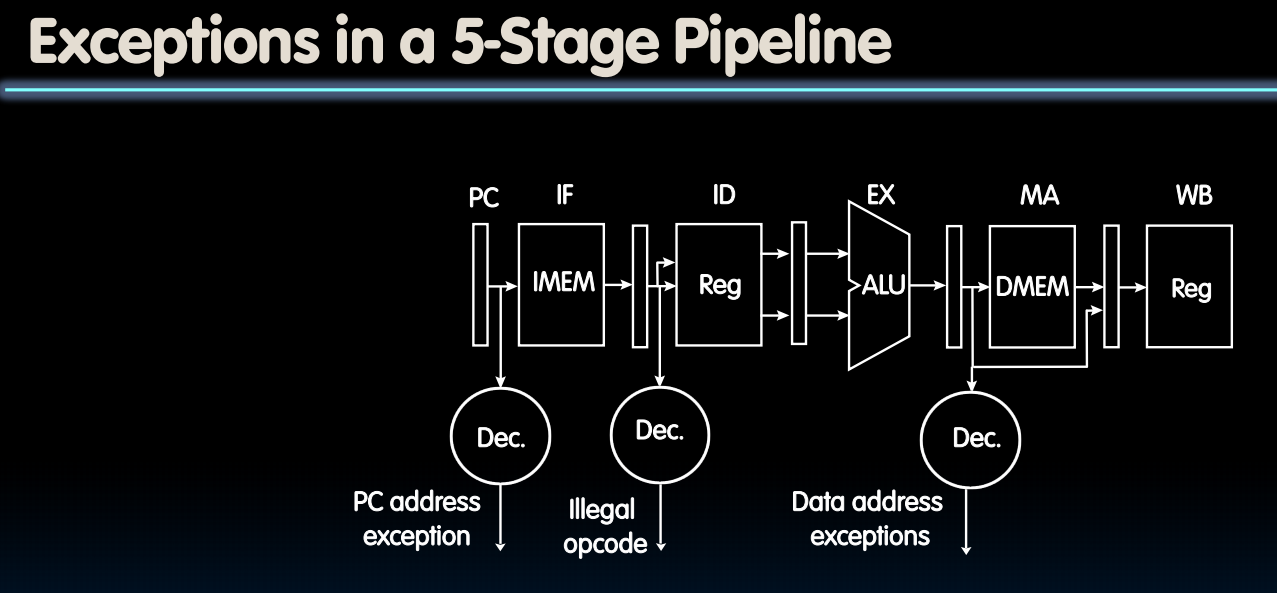
与处理pipeline hazards很像
多程序:看似是多,实则是不断的仔不同的程序之间跳转。“scheduling"调度


lec29-Virtual Memory I
Virtual Memory Concepts
目的:使每一个程序都觉得自己拥有所有的内存,由OS调度,这样不同程序之间不会打架
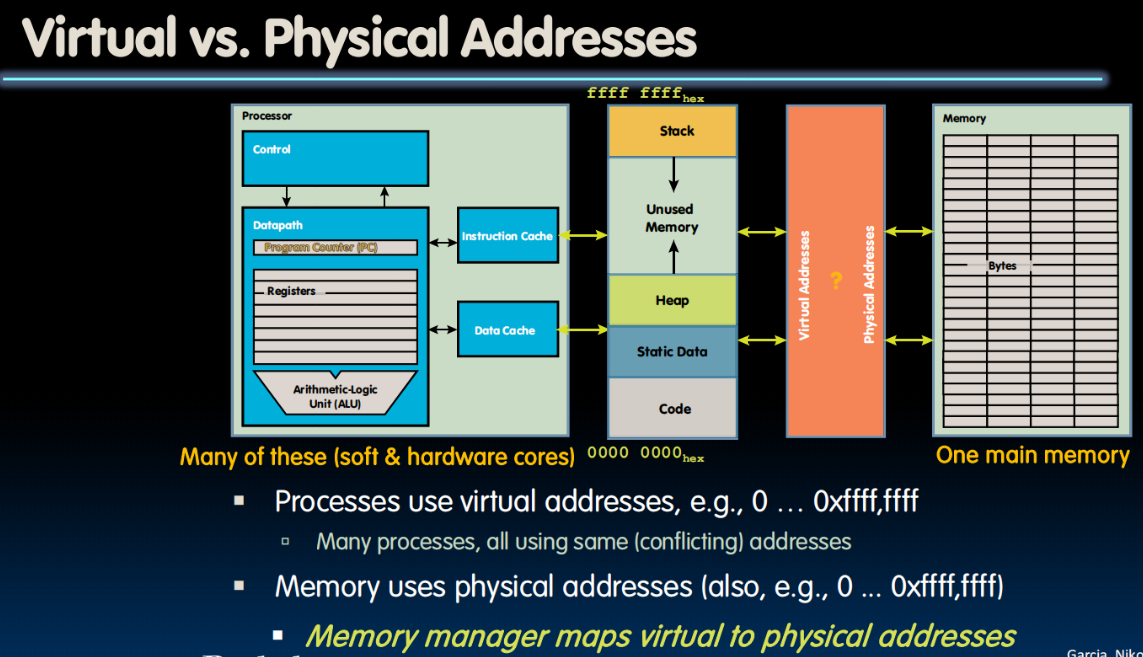

Physical Memory and Storage
Dynamic Random Access Memory,DRAM —volatile,需要电源才能存储数据

Disk:比memory(DRAM慢)SSD: solid-state disk(固态硬盘), HDD: hard disk drives(机械硬盘)(not volatile)
SSD类似于DRAM,比HDD(纯机电)快。flash drives
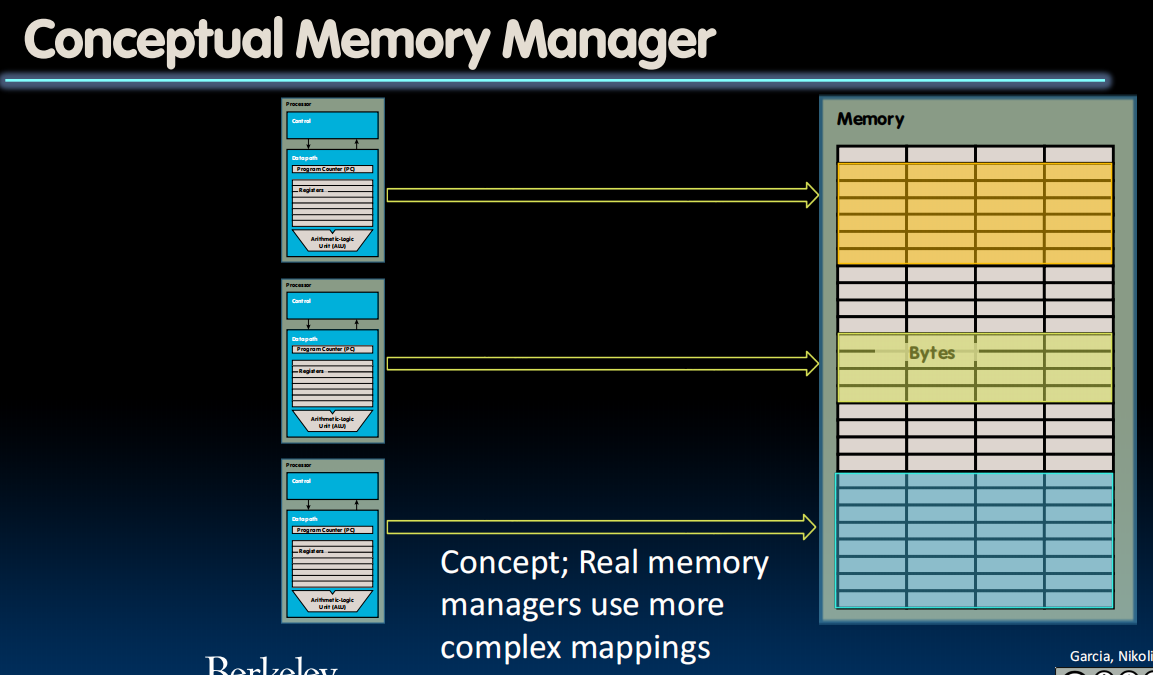
Memory Manager

Paged Memory


作用:
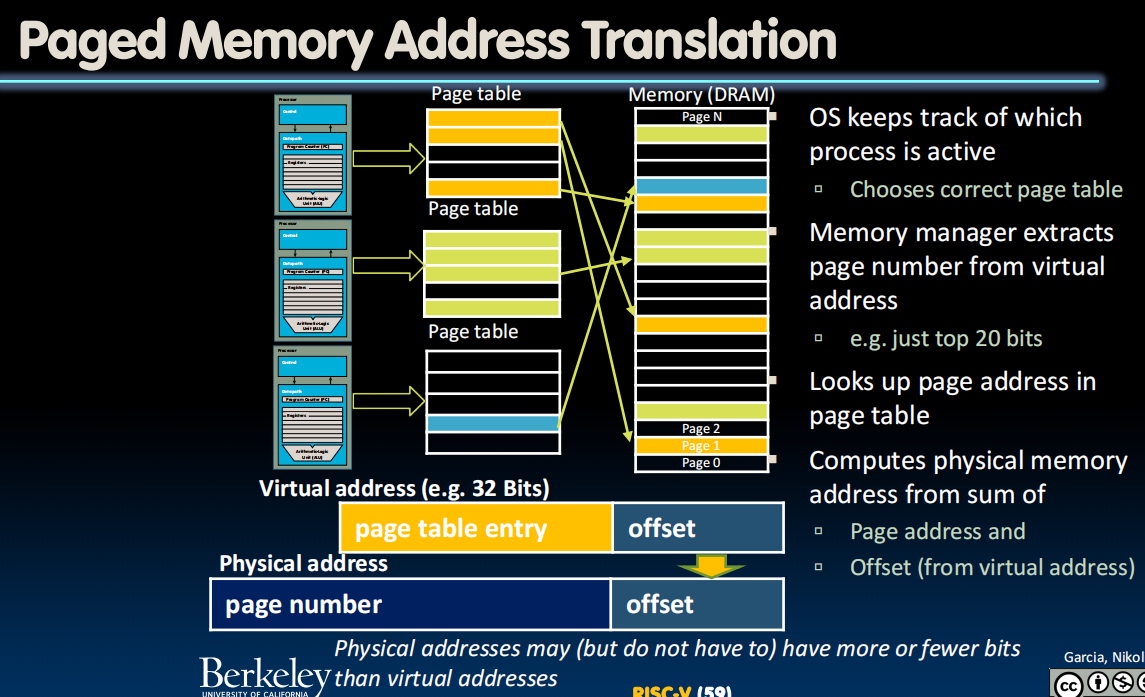
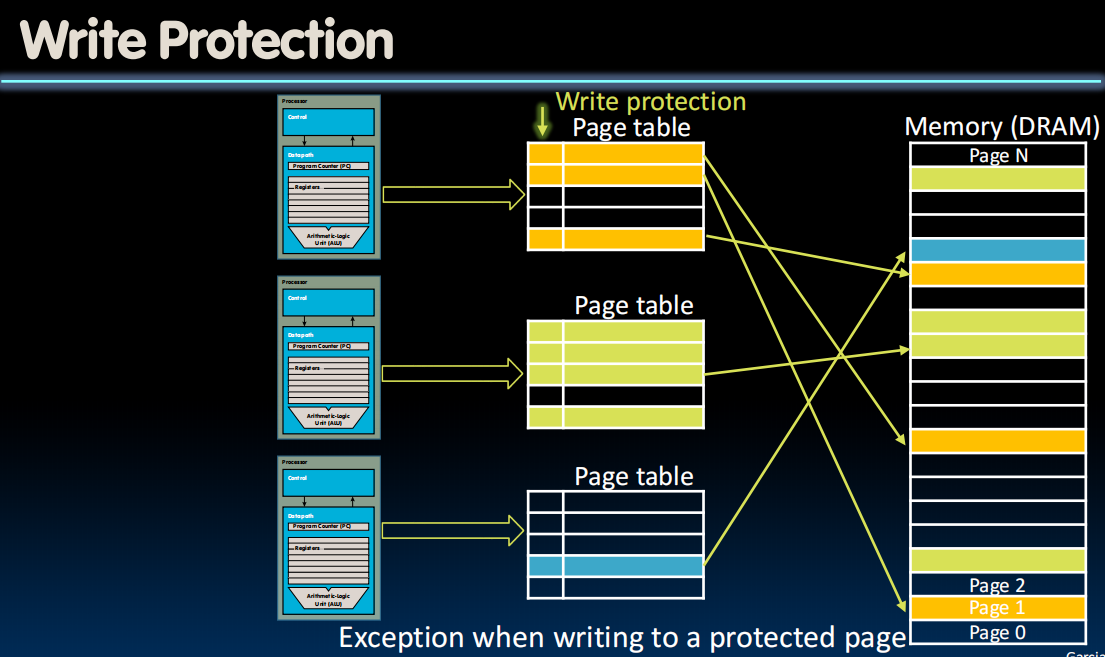
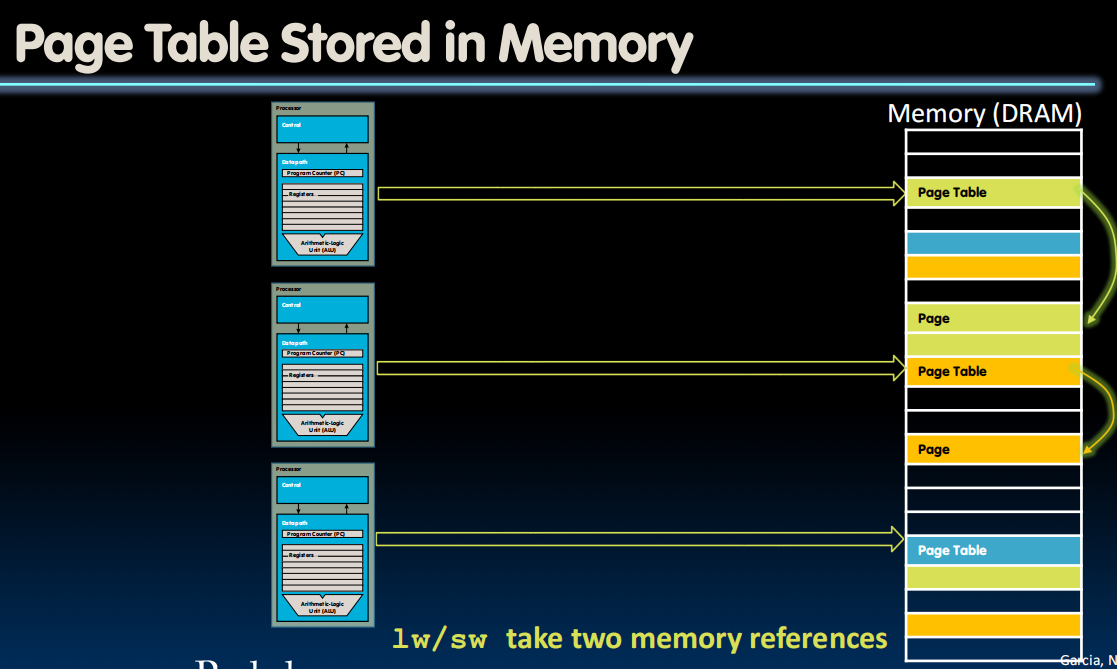
Page Tables不算小,所以只能存在DRAMs里,然后把部分常用的存在caches里。

Page Faults

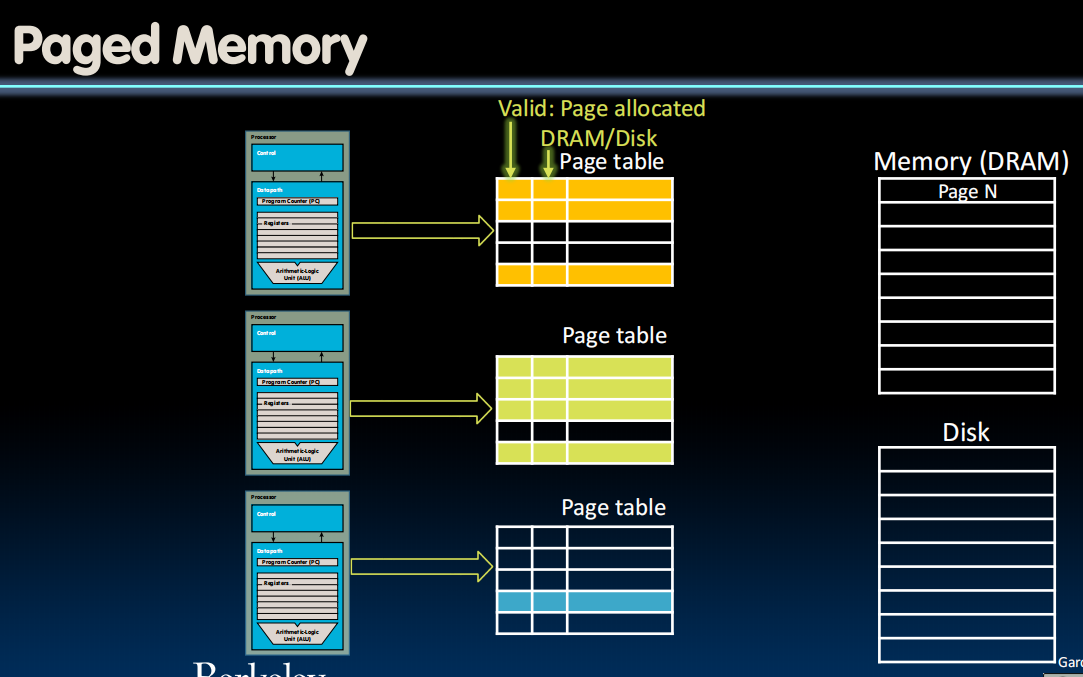

page fault:如果要从disk取东西,会有一段时间回不来,视为一个exception

当面临DRAM的时候,我们选择write back而非write through
lec30-Virtual Memory II
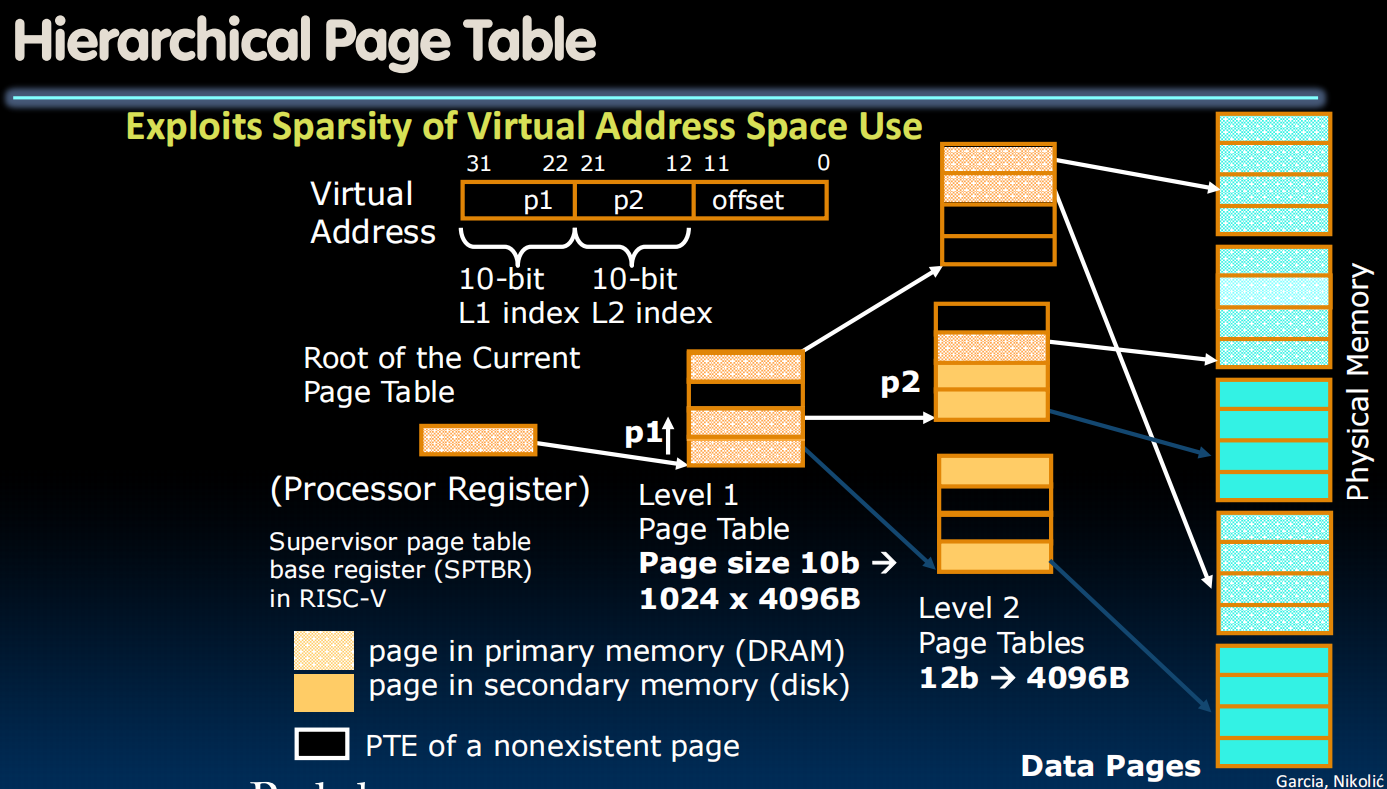
Hierarchical Page Tables
page table不能太大

分层页表
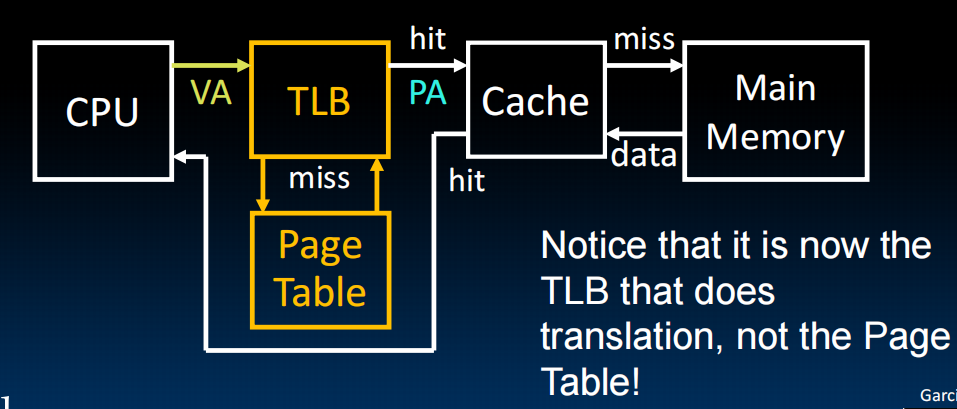
Translation Lookaside Buffers(TLB)
4层page table让我们需要5次访问内存->类似cache,我们存一些经常用的到TLB里,如果命中成为TLB hit
同样有valid和dirty bit
fully associated
VPN: virtual page number PPN: physical page number
VA: virtual address PA: physical address 先访问TLB后Cache
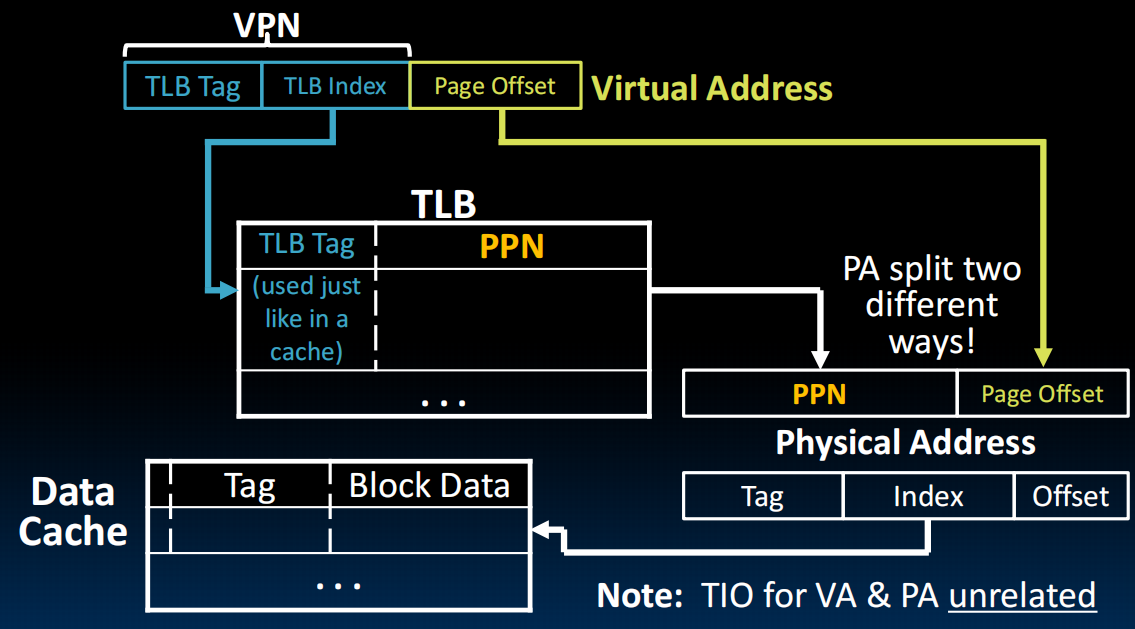
TLBs in Datapath
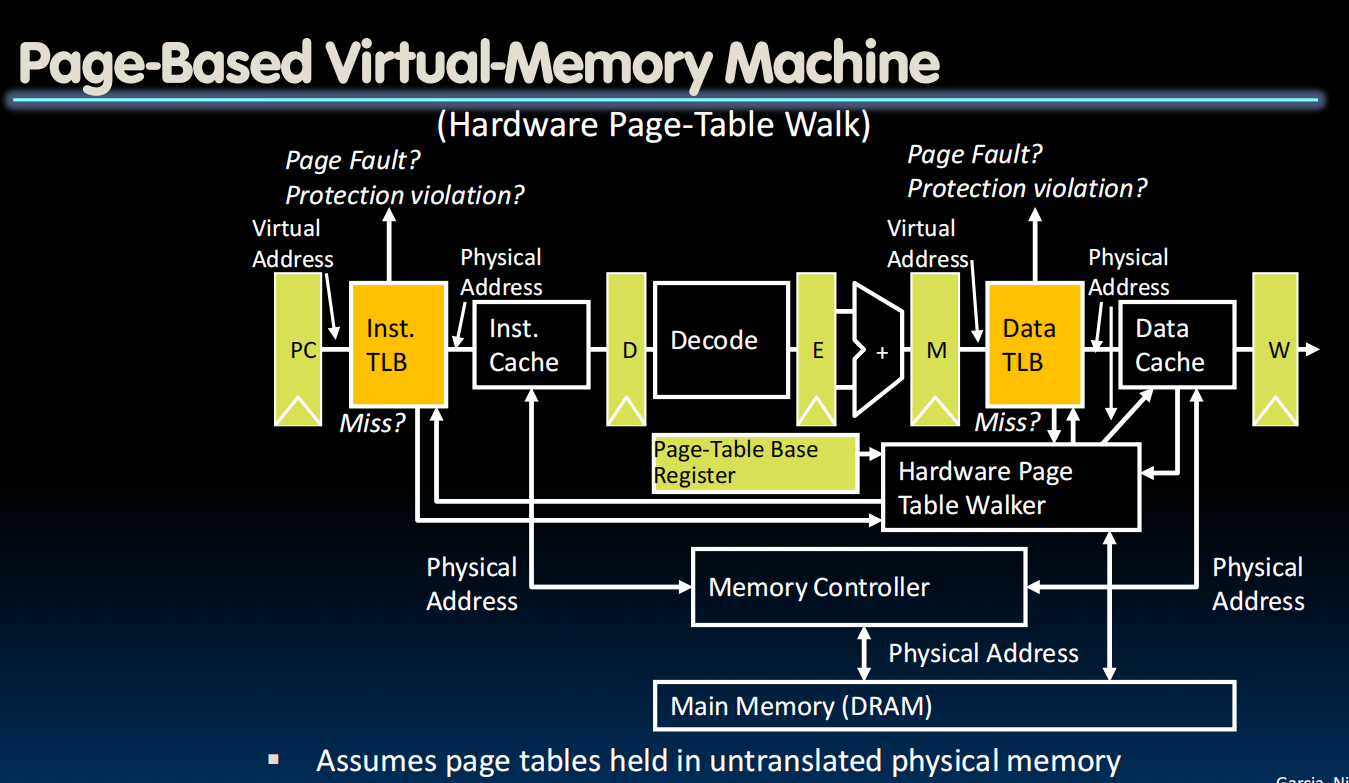
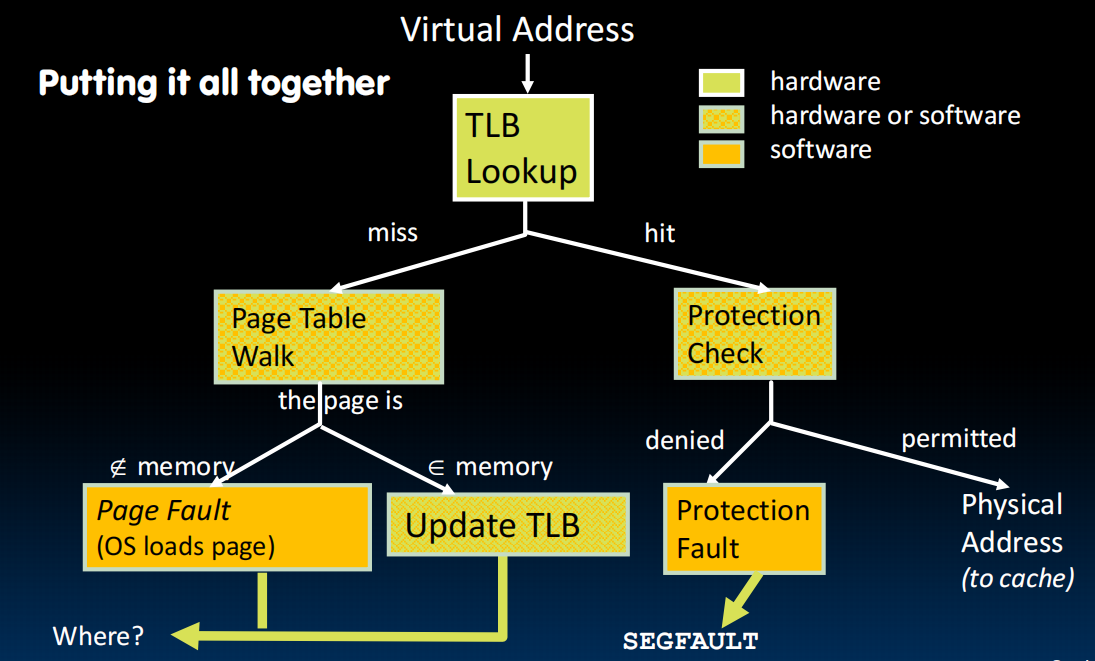

怎么同时处理多个程序?context switching
What happens to the TLB?
Current entries are for different process
Set all entries to invalid on context switch
VM Performance
用和cache类似的方法
对比:


使用AMAT衡量。
lec31-IO
I/O Devices
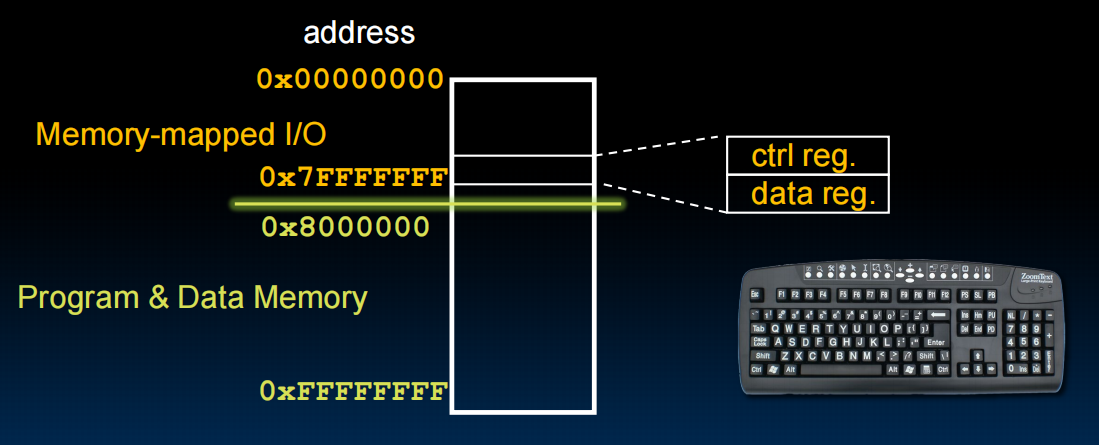
Memory mapped I/O
- Portion of address space dedicated to I/O
- I/O device registers there (no memory)
- Use normal load/store instructions, e.g. lw/sw
- Very common, used by RISC-V
I/O Polling(轮询)

ready bit:表示准备好写/读了,操作结束复位为0
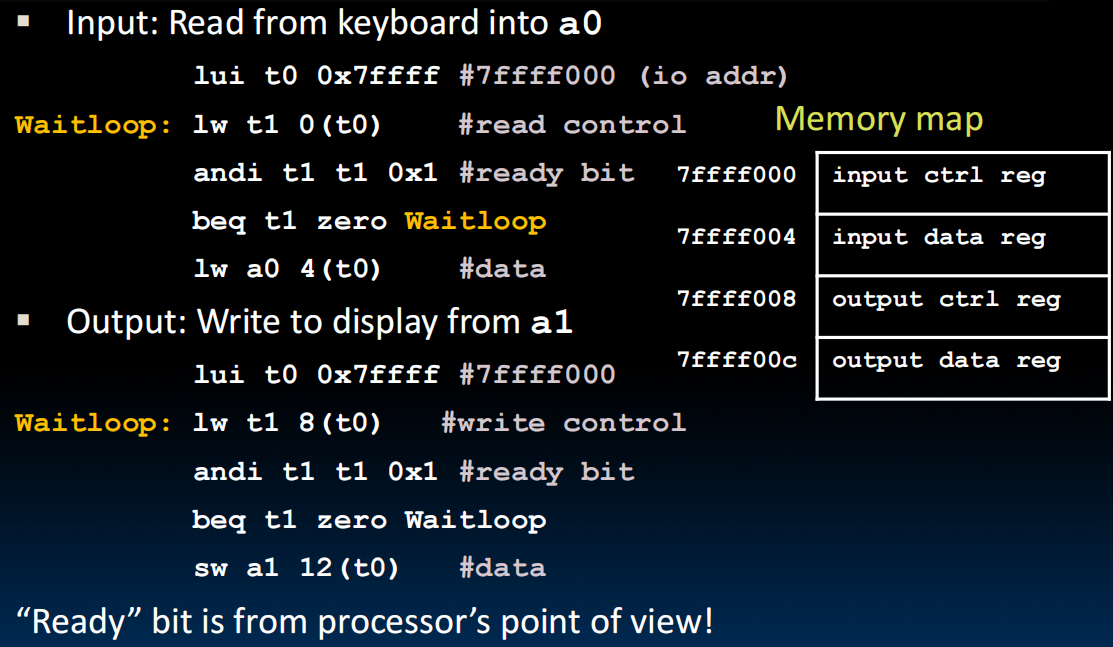
有些设备能产生大量数据,一直轮询会占用大量时间,所以轮询是有缺陷的。
I/O Interrupts
Interrupt:门铃。I/O要使用的时候就按一下。但是Interrupt中断程序,保存状态,移交给trapped,然后再回来,在Interrupt较多的时候也不好。

DMA
移动大量数据的时候我们使用Direct Memory Access (DMA)而非前两种。

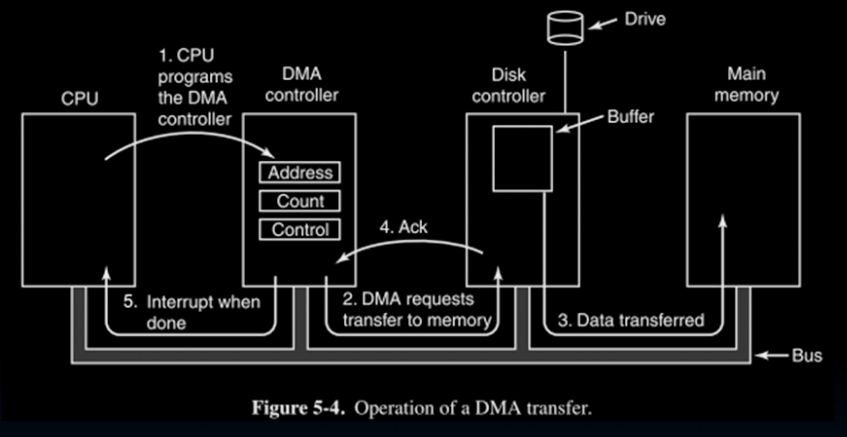
只需要中断两次。第一次中断向DMA发信息,发完继续做自己的。第二次受到DMA已完成的信息,收完继续。



Networking


(lec32~37) Parallelism
lec32-Flynn Taxonomy, SIMD Instructions
用矩阵乘法的吞吐量来衡量速度
Matrix Multiplication
C>>Python
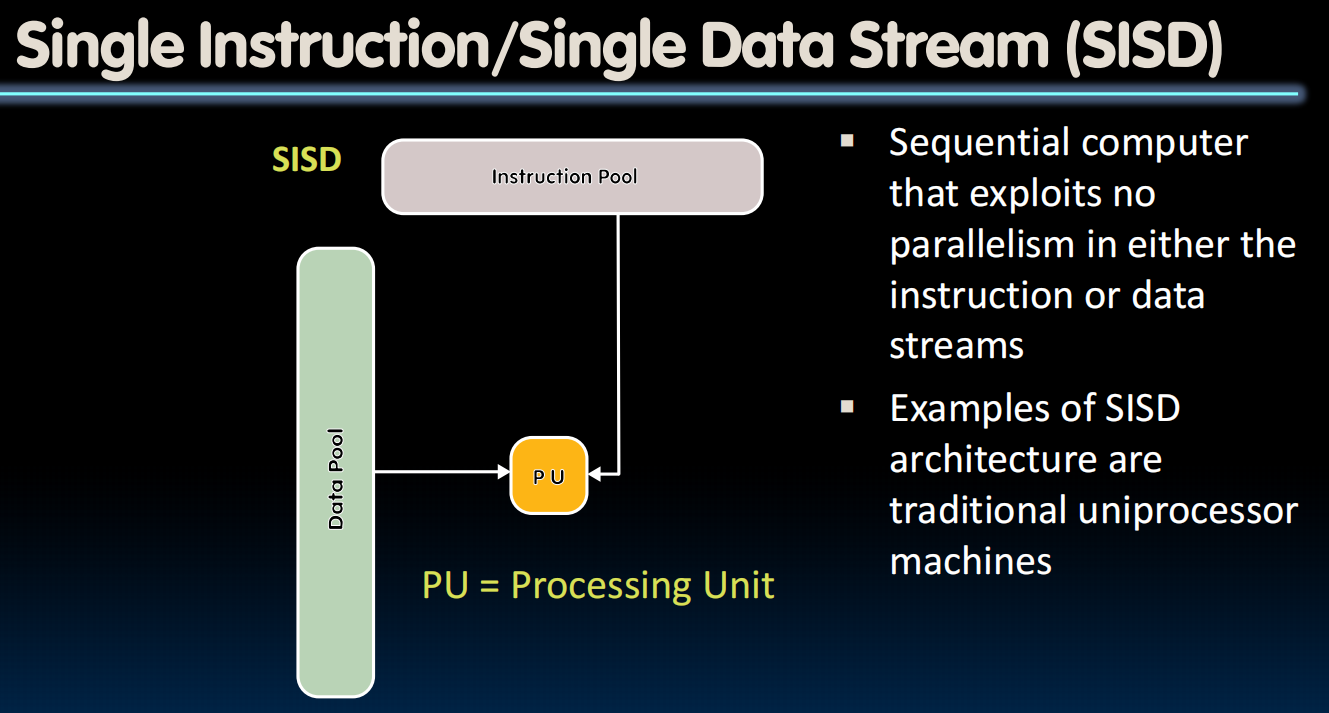
Flynn’s Taxonomy
硬件和软件并行性的选择是独立的:并发软件也可以在串行硬件上运行,顺序软件也可以在并行硬件上运行
Flynn分类法:对并行硬件的分类
SIMD: 单指令多数据

PU:Processing Unit
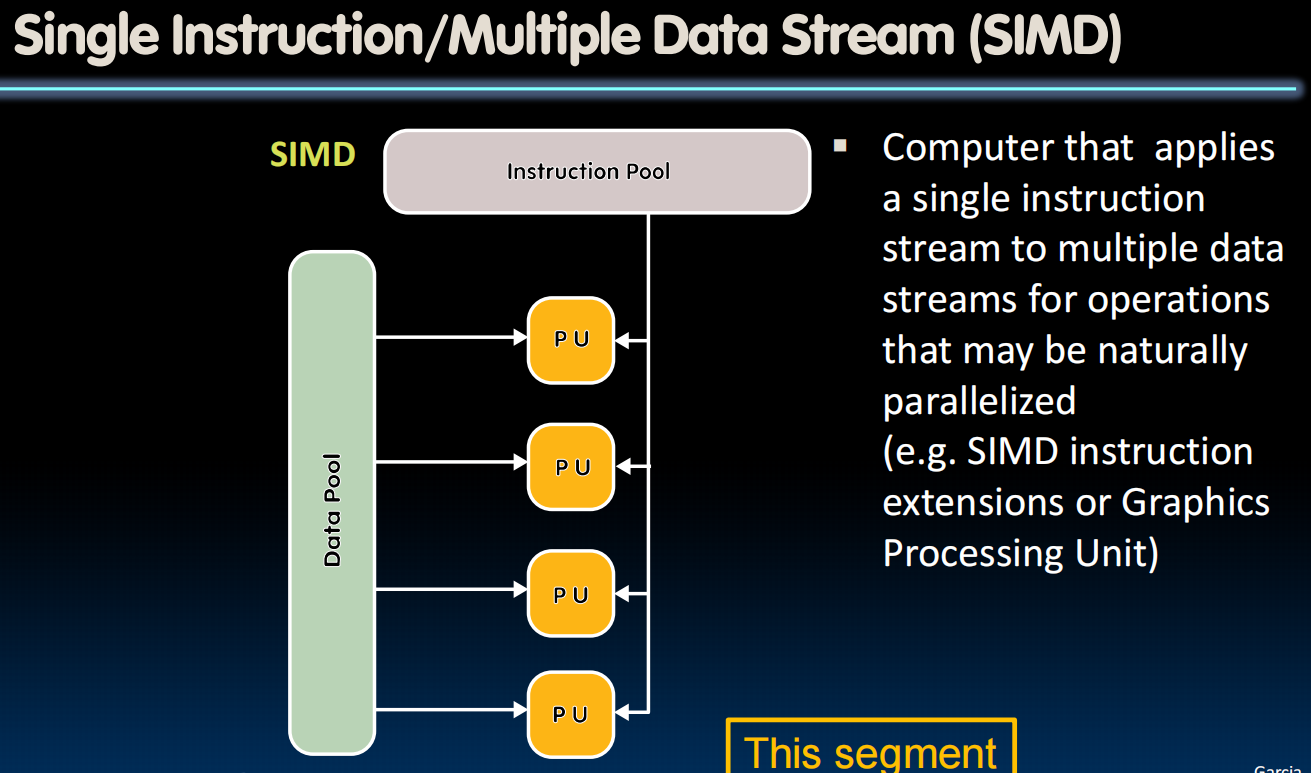
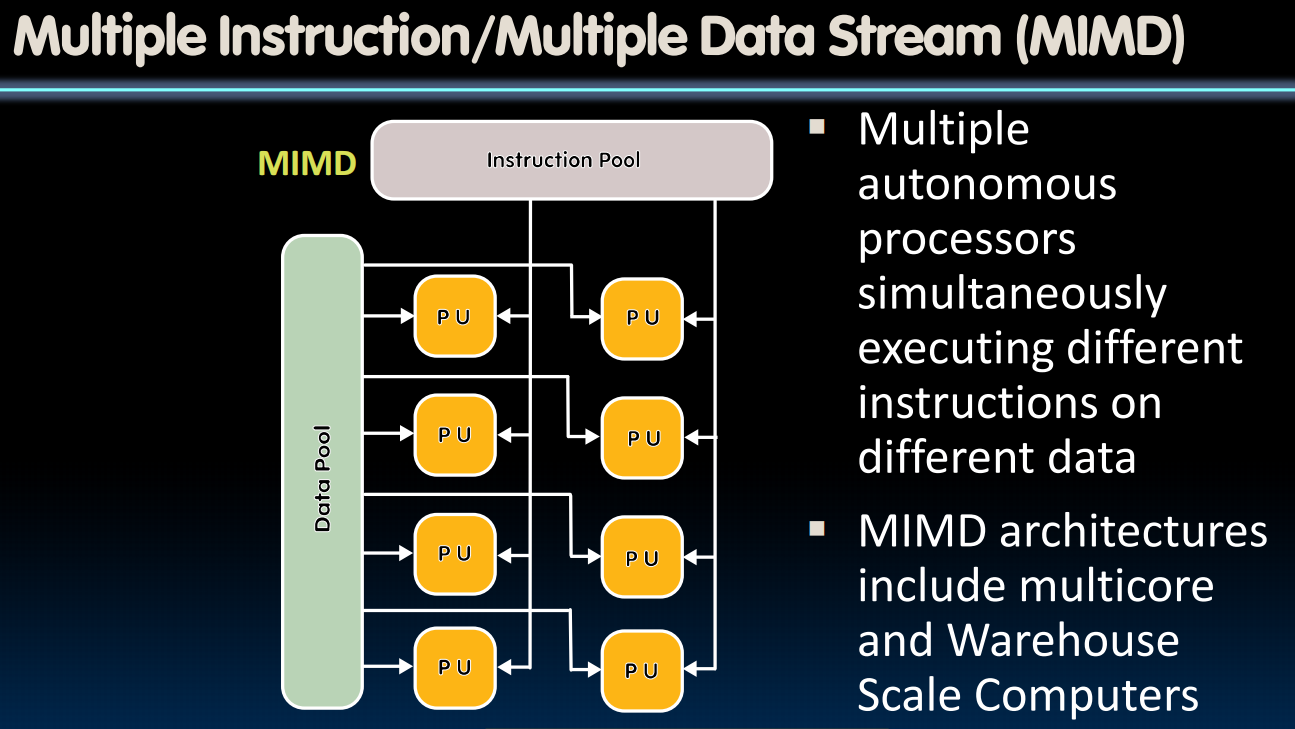
SIMD Architectures
eg.在一个时间内计算出点乘(ai x bi)


扩展寄存器,扩展指令
Intel x86:SSE : Streaming SIMD Extensions ,“流式单指令多数据扩展”。

SIMD Array Processing
举例:
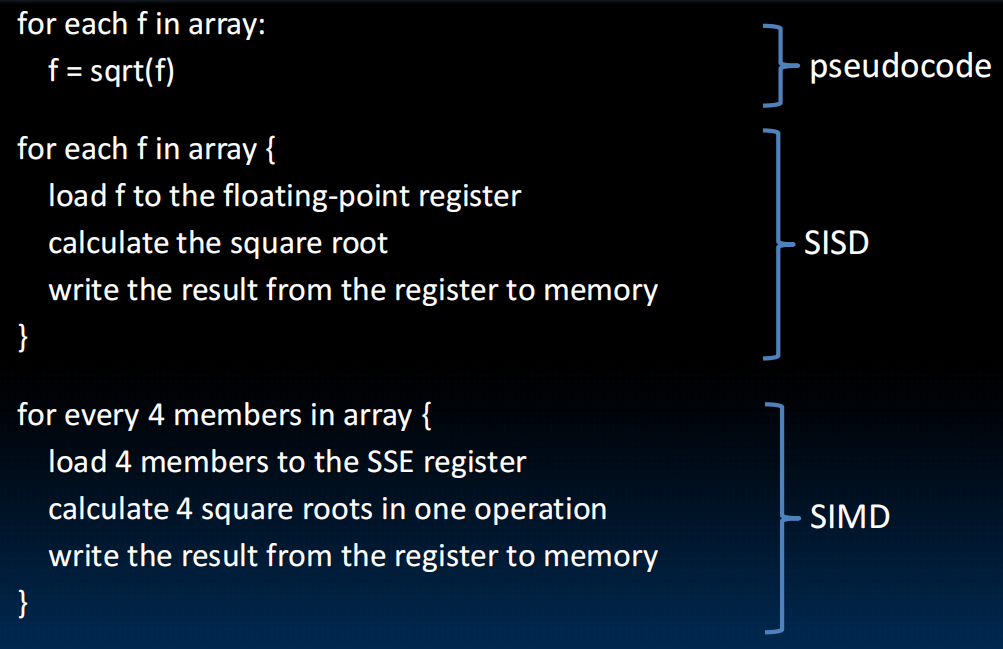


lec33-Thread-Level Parallelism I
Parallel Computer Architectures
CPU with two cores
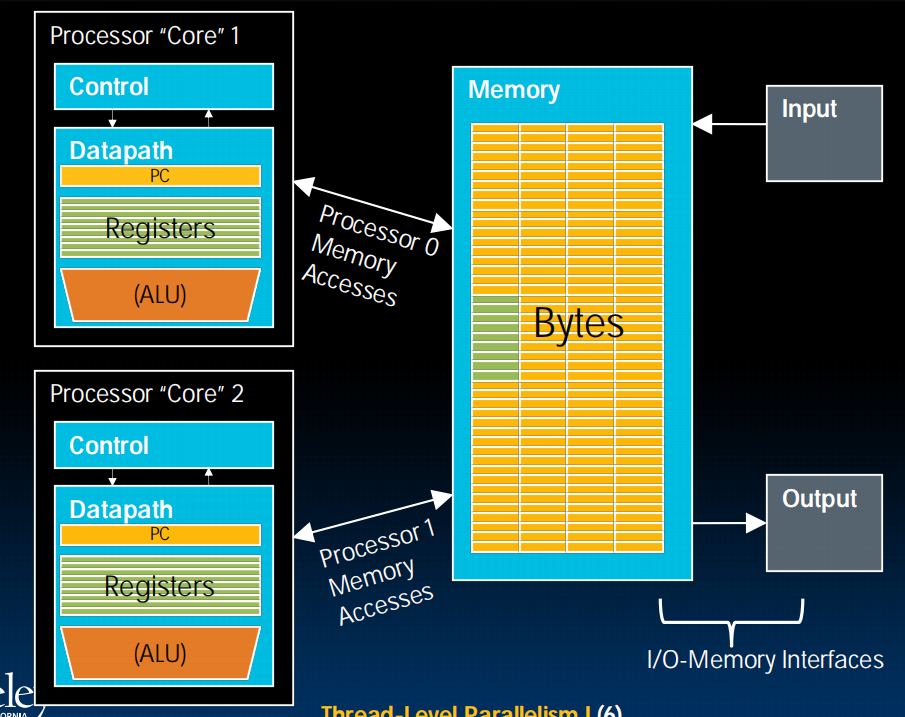

Multicore
2005年左右,能耗等限制开始显现,多核的思想开始产生,用多核来继续提升性能。

Threads(线程)
A Thread stands for “thread of execution”, is a single stream of instructions



Multithreading
一核多线程
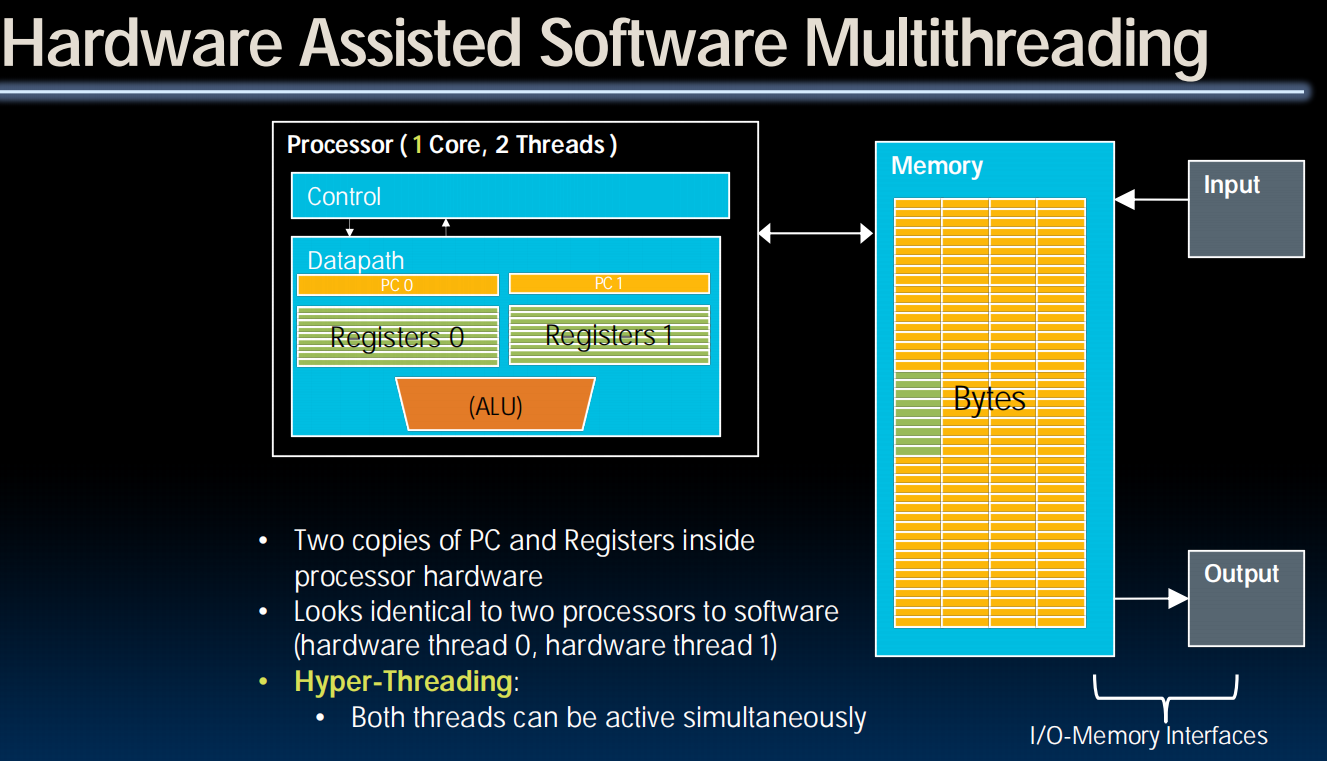

MIMD
lec34-Thread-Level Parallelism II
Parallel Programming Languages
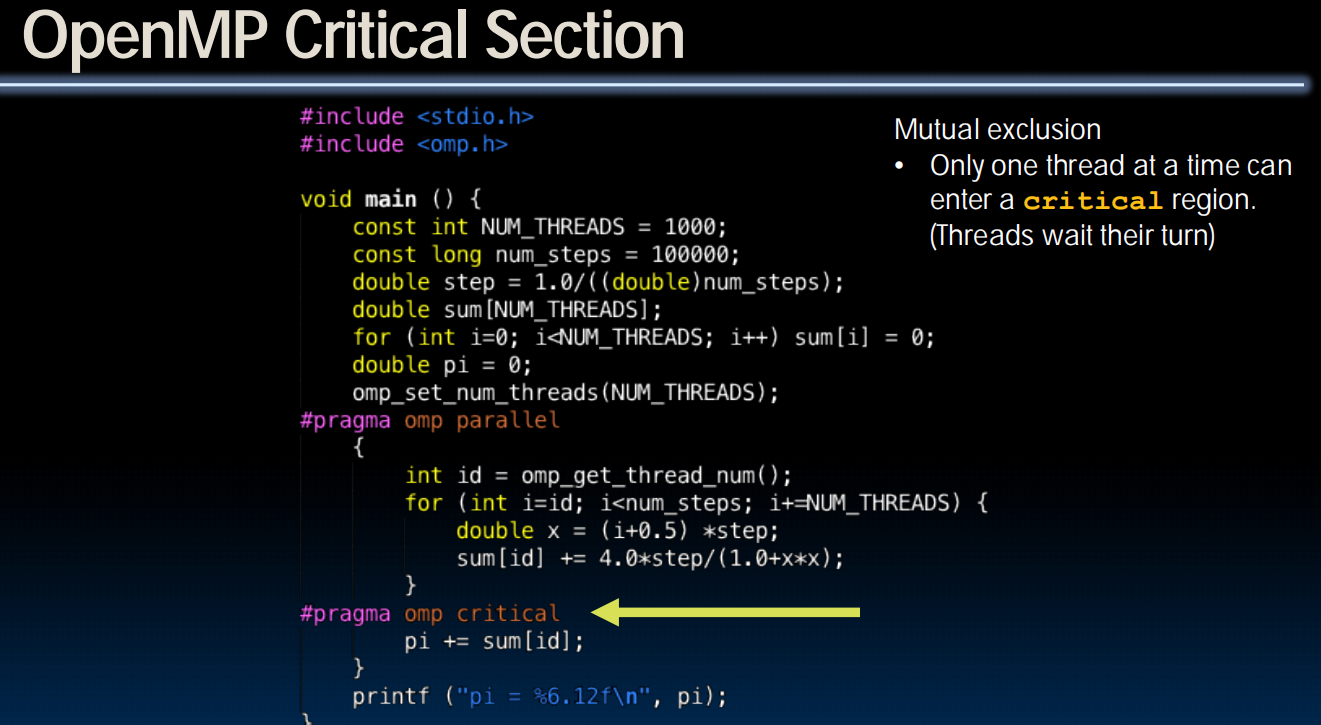
OpenMP
(C的头文件,支持多线程)
(Software Thread)
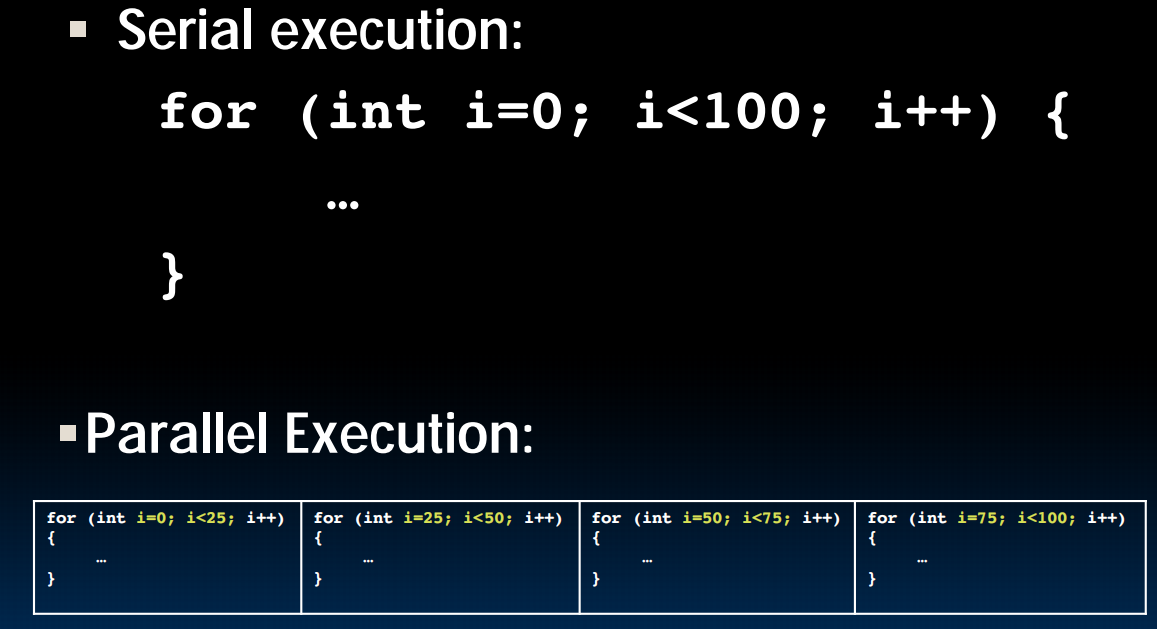
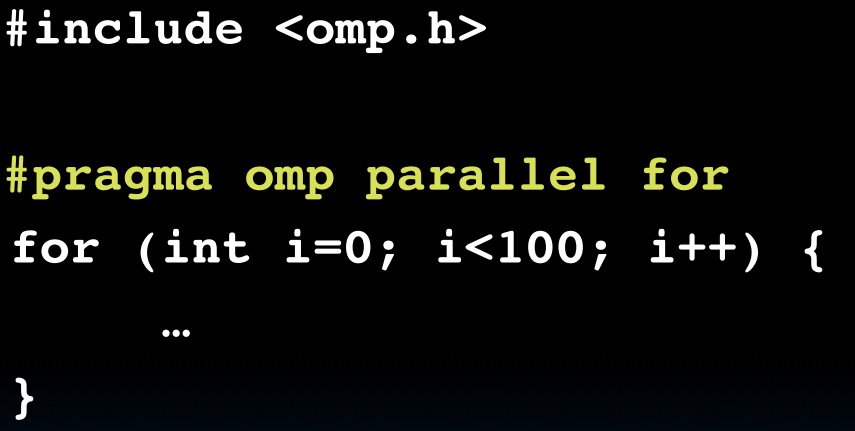
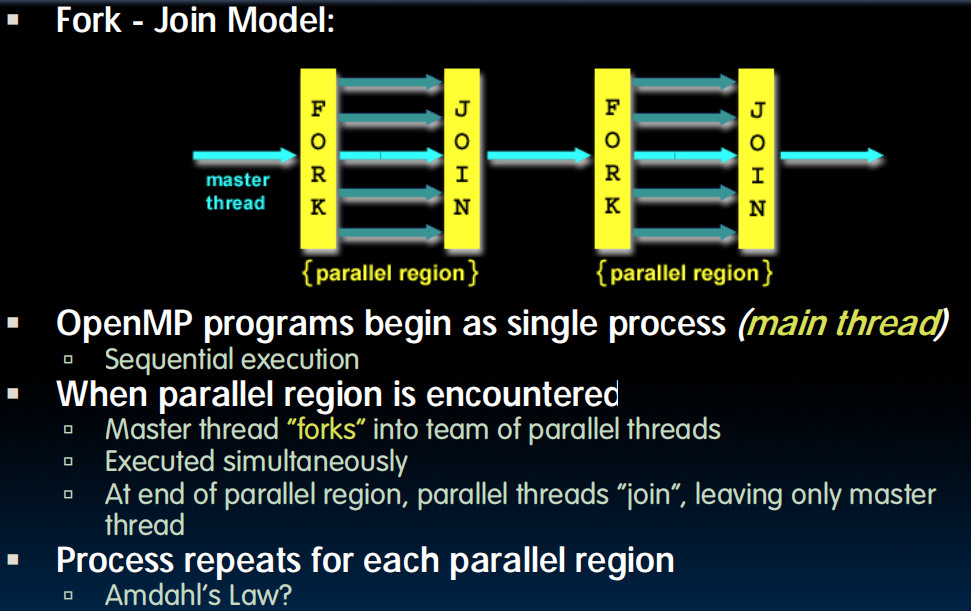
但是如果我的fork之后(eg.上面的for循环)共用了同一个变量(内存区域)呢?比如,
1 | int sum = 0; |
只好换为:
1 | int sum[10]; |
这样的委曲求全不是我们想要的。
如果不这样的话会成为“race condition”,产生垃圾值,比如覆写。
Synchronization(同步)
锁!
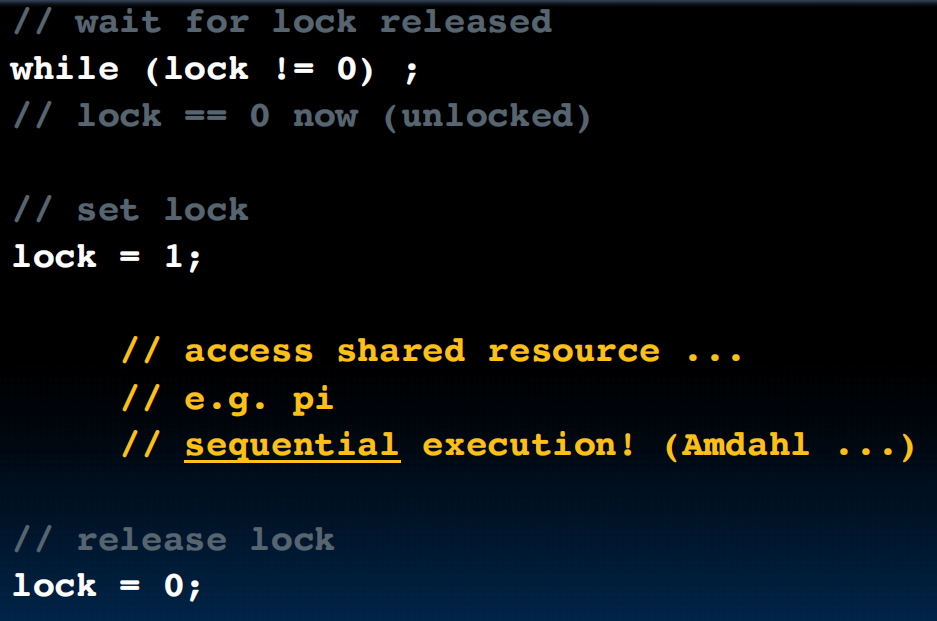
但是会不会两个线程同时拿到了锁呢?next lesson
lec35-Thread-Level Parallelism III
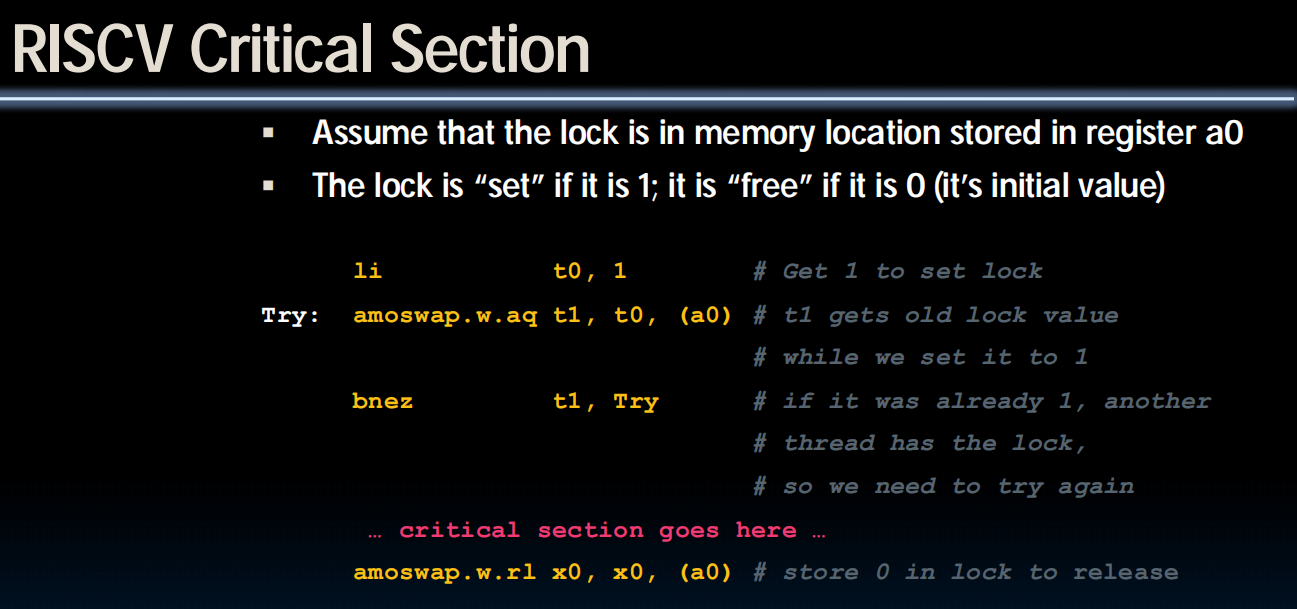
Hardware Synchronization
Atomoc Memory Operations(AMOs)
读取旧值,并对旧值做加法作为新值放回去。

实现的锁:这是在硬件层面实现的,所以不会有问题了。
OpenMP:
Deadlock
时间:

Shared Memory and Caches


但是这就出现了问题:memory[1000]在第一个cache中写了,写成了40,他是最新的。但是其他cache没有更新,也没有设置其为dirty,这意味着其他cache中可能会有一些旧的memory[1000]!所以我们要让其他cache中的副本“无效”。
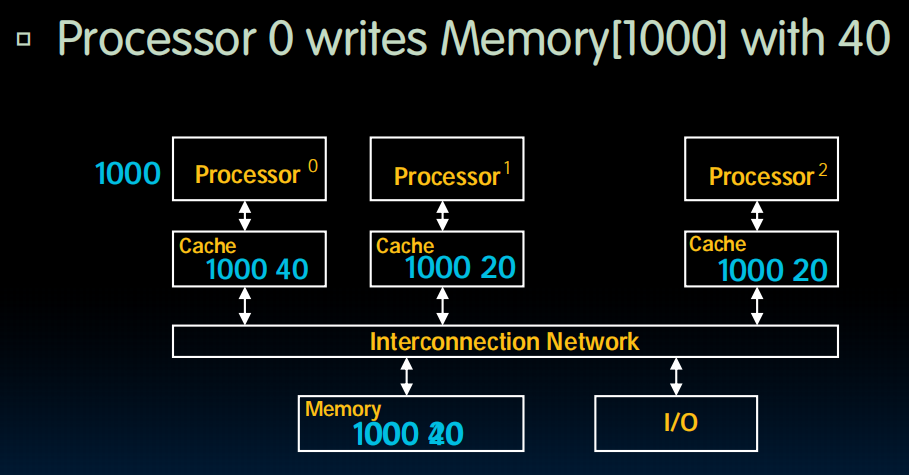
Cache Coherency
每个缓存跟踪缓存中每个块的状态:
-
Shared:最新数据,其他缓存可能有副本
-
Modified:最新数据,已更改(脏),没有其他缓存有副本,可以写入,内存已过期(即,写回)
-
exclusive:数据是最新的,没有其他缓存有副本,可以安全地写入,内存也是最新的。
- 如果块被替换,避免向内存写入。
- 读取时直接提供数据,而不是访问内存。
-
owner:数据是最新的,其他缓存可能有副本(这些副本必须处于共享状态)。
- 这个缓存是多个拥有该缓存行有效副本的缓存之一,但拥有独占权来修改它。它必须将这些更改广播给所有共享该缓存行的其他缓存。引入所有者状态允许脏数据共享,即修改后的缓存块可以在不更新主内存的情况下在各个缓存中移动。缓存行在使所有共享副本失效后可以被更改为“modified”状态,或者通过将更改写回主内存来更改为“shared”状态。所有者缓存行必须响应窥探请求并提供数据。(当有一个线程的cache没有这个数据的时候,他先问问别人有没有,owner必须回答)

行是我,列是其他人。

lec36-MapReduce, Spark
Amdahl’s Law
s是一个进程无法被加速的部分:“串行部分比例”(Sequential part)。这部分任务因为其内在逻辑,必须按顺序一步步执行,无法通过并行等手段来加速。P是加速倍数。

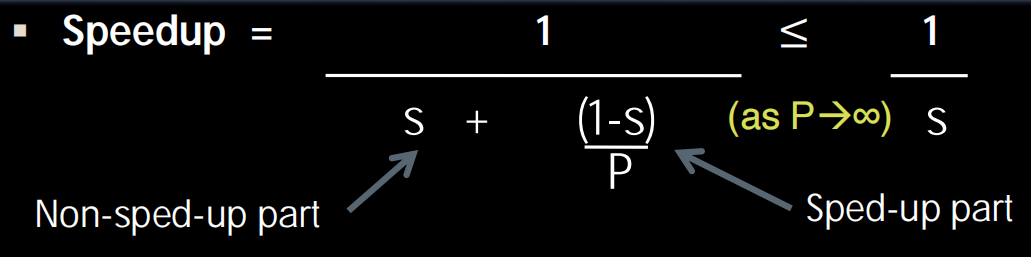
所以我们要做的是尽可能并行,减小s
Request·-Level and Data-Level Parallelism


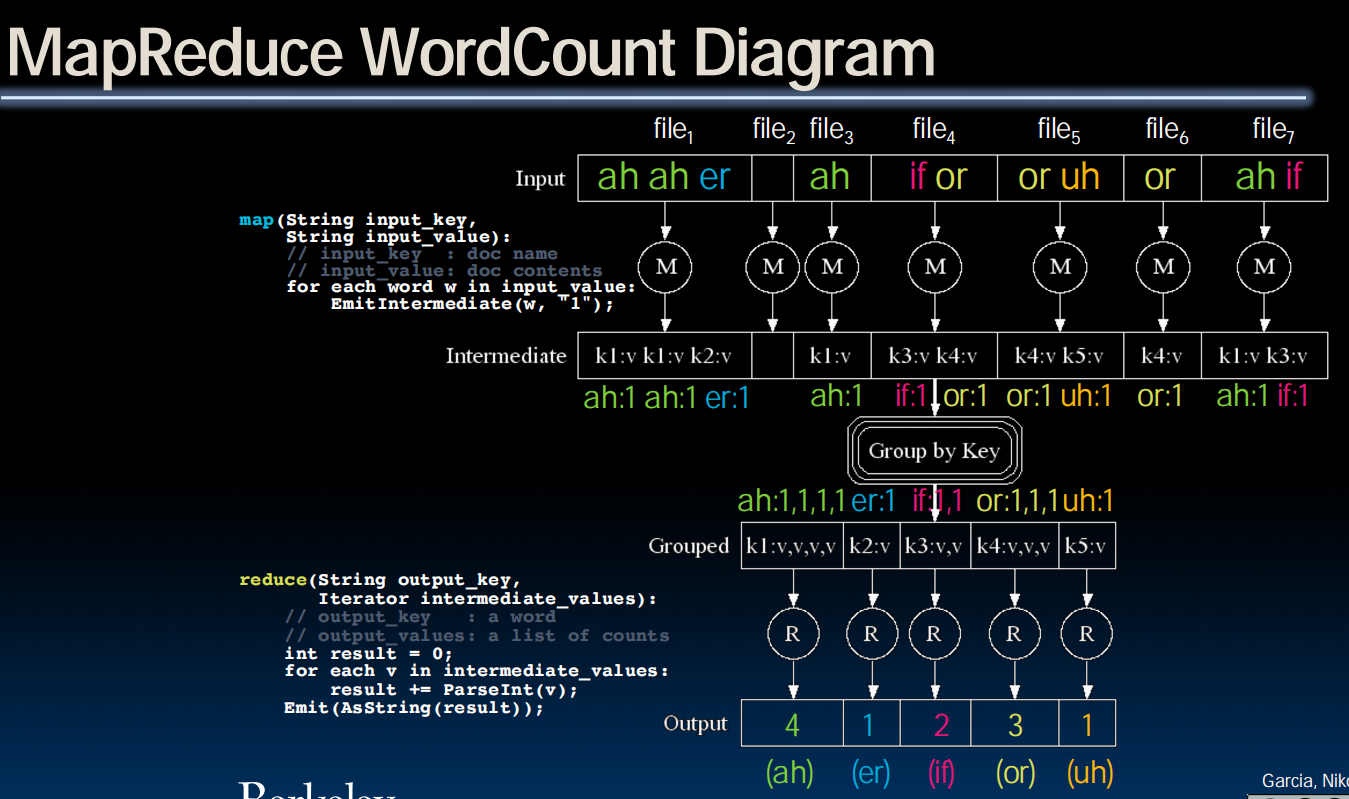
MapReduce
MapReduce 是一种用于处理和生成海量数据集的编程模型和其对应的计算框架。
Simple data-parallel programming model designed for scalability and fault-tolerance
把一个非常庞大、复杂的大任务,分解成两个简单、独立的阶段,即 Map(映射) 和 Reduce(化约),然后将这两个阶段的任务分发到成百上千台计算机上并行处理,最后再把结果汇总起来。
Hadoop
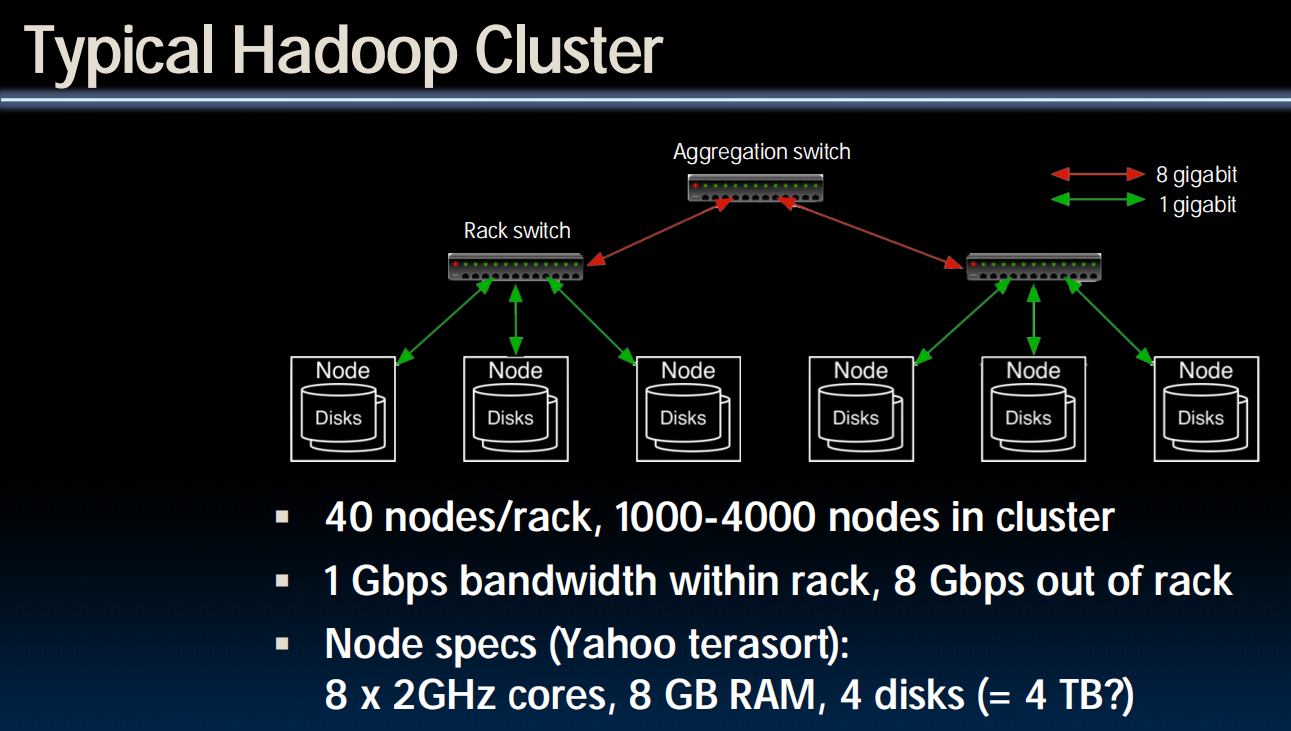


DFS:分布式文件系统
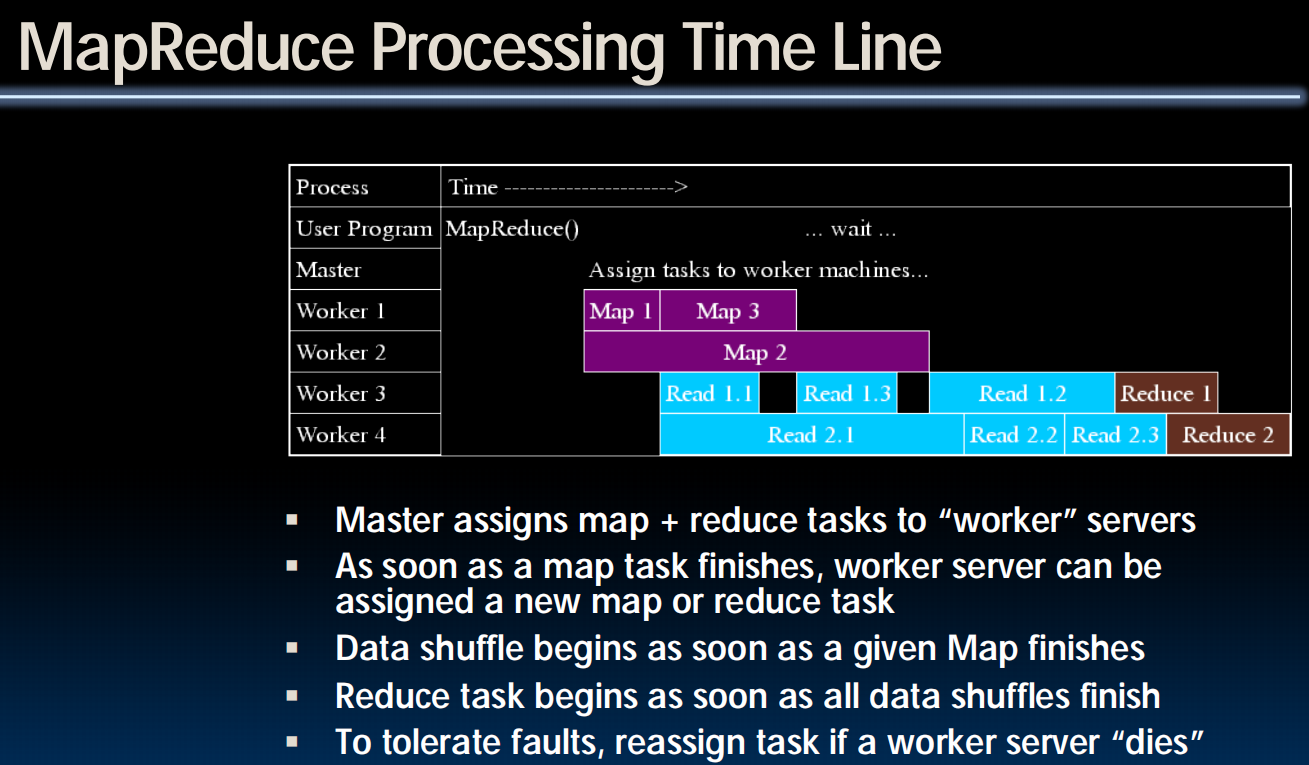
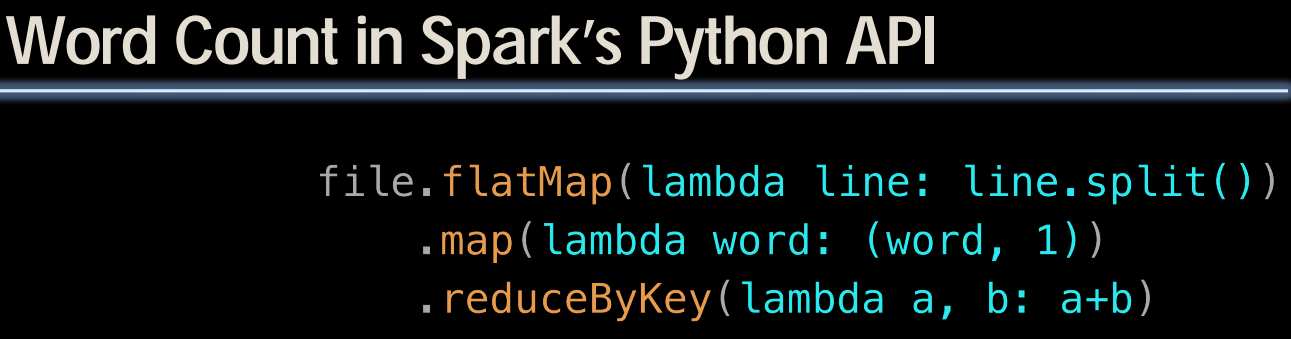
Spark
(另一种MapReduce的实现,但是代码上轻量级一些)
lec37-Data Centers, Cloud Computing (WSC)
Eras of Computer Hardware
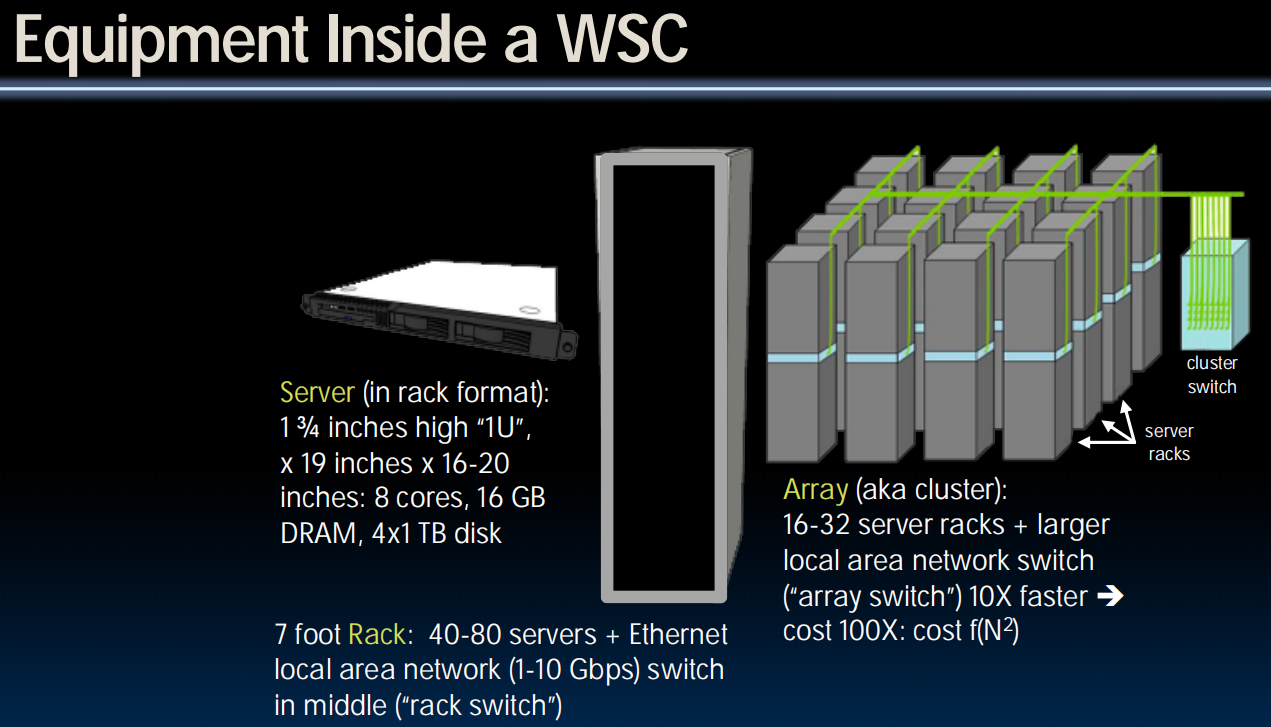
Warehouse Scale Computers(仓库规模的计算机)

Power Usage Effectiveness(PUE)


(lec38) Dependability
lec38-Dependability- Parity, ECC, RAID
Dependability
可靠性——减少硬件故障

Dependability Metrics


如何测量:
平均故障间隔时间+平均修复时间




Error Detection

ECC
奇偶值检验——只能检验奇数个错误,但由于我们的soft errors通常是一个bit有问题,所以没关系

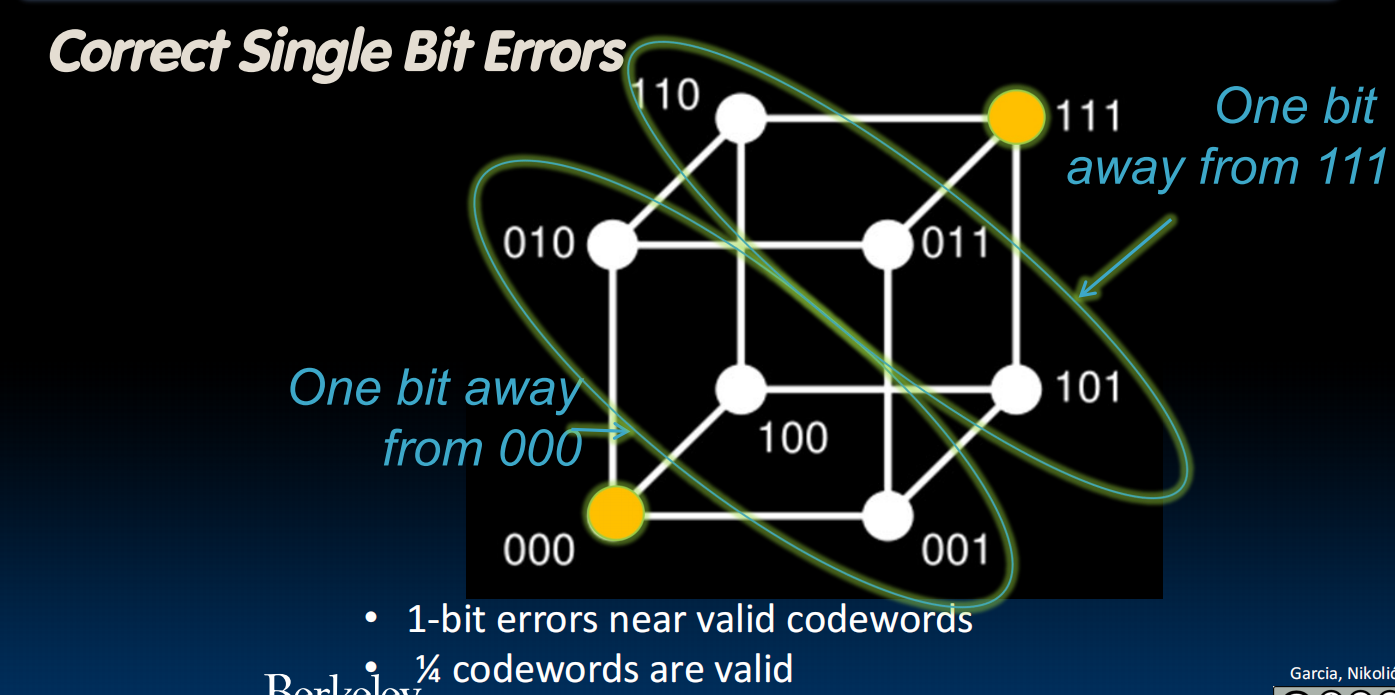
Error Detection and Correction
如何纠正呢?一般我们会选择临近的可能情况。比如:8bit的数据的奇偶值有问题->我们怀疑是一个bit错了

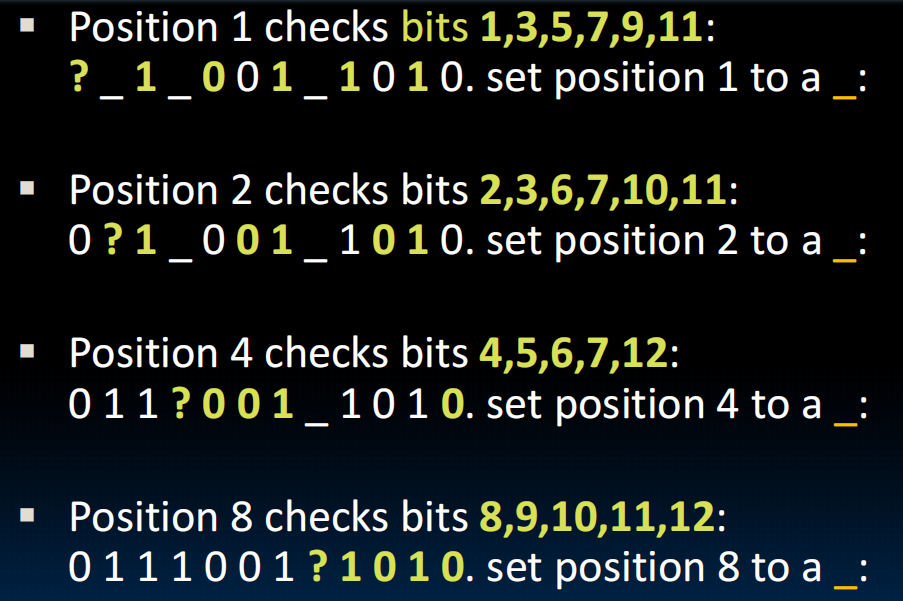
ECC Example
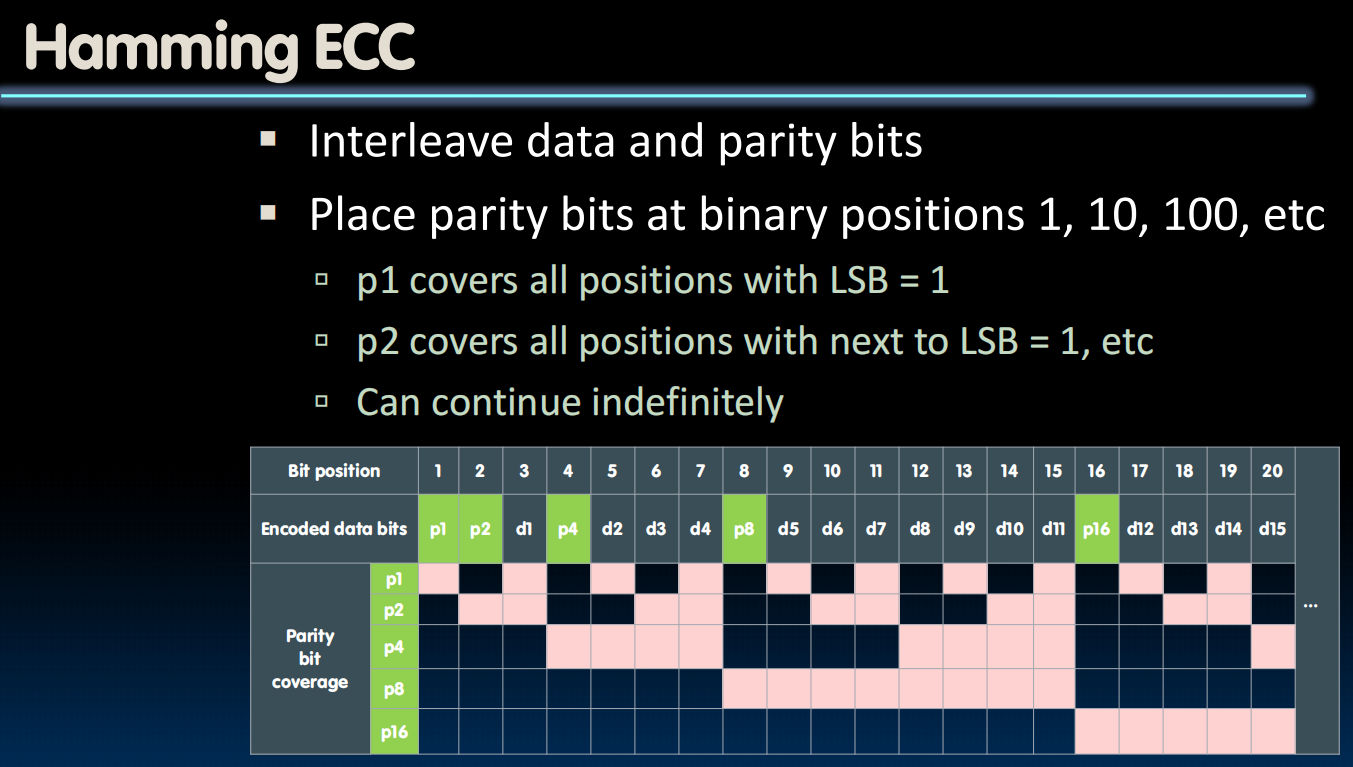
我们把奇偶值检验的bit嵌入到1,2,4,8…位,每个值检验一些位数,如表所示,这样的话,当我们发现,比如,第二位和第八位的奇偶值有问题->2+8=10,把第十位数据翻转,就对了!非常巧妙

如果多于2-bits error呢?引入更复杂的检验机制。

Redundancy with RAID(Redundant Arrays of Inexpensive Disks)

RAID 1:Disk Mirroring/Shadowing 每个disk都存一个相应的副本

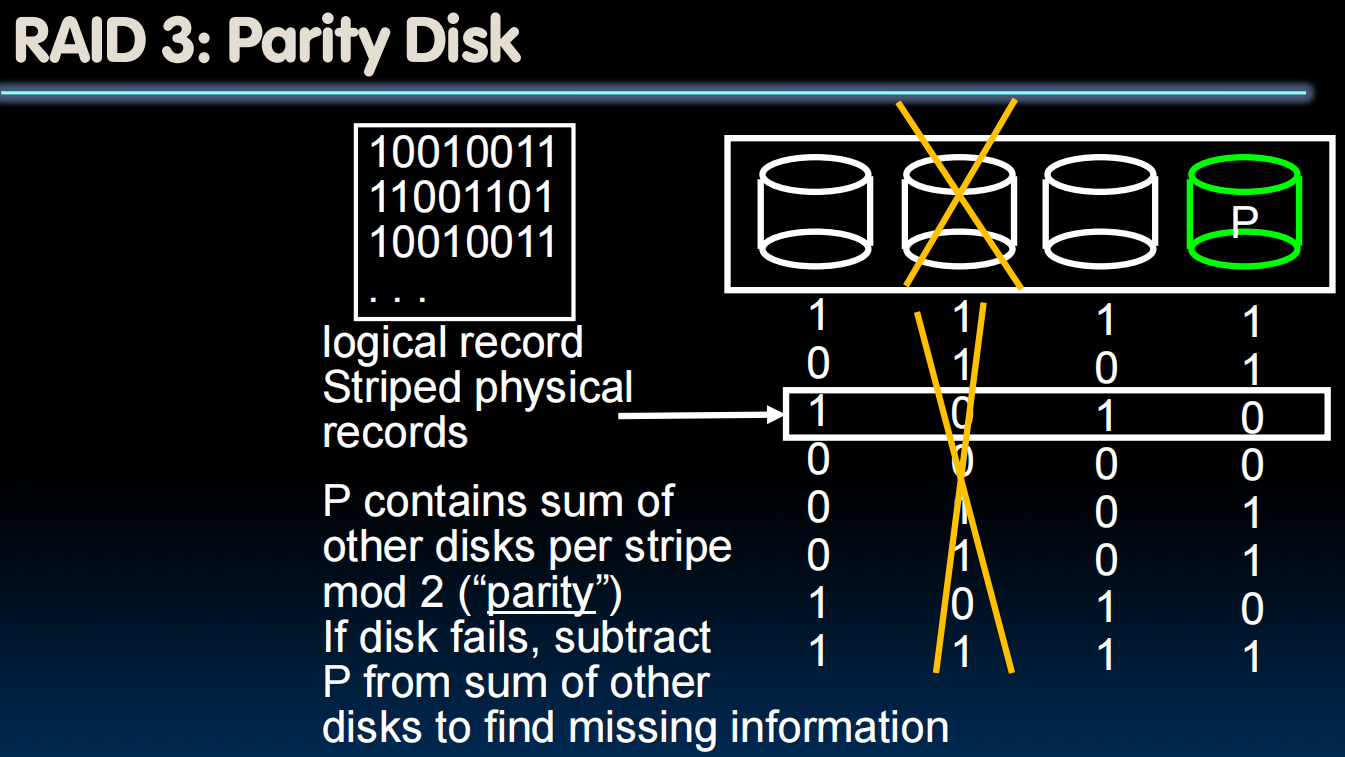
RAID 3:Parity Disk 三个disk存用一个disk存奇偶值
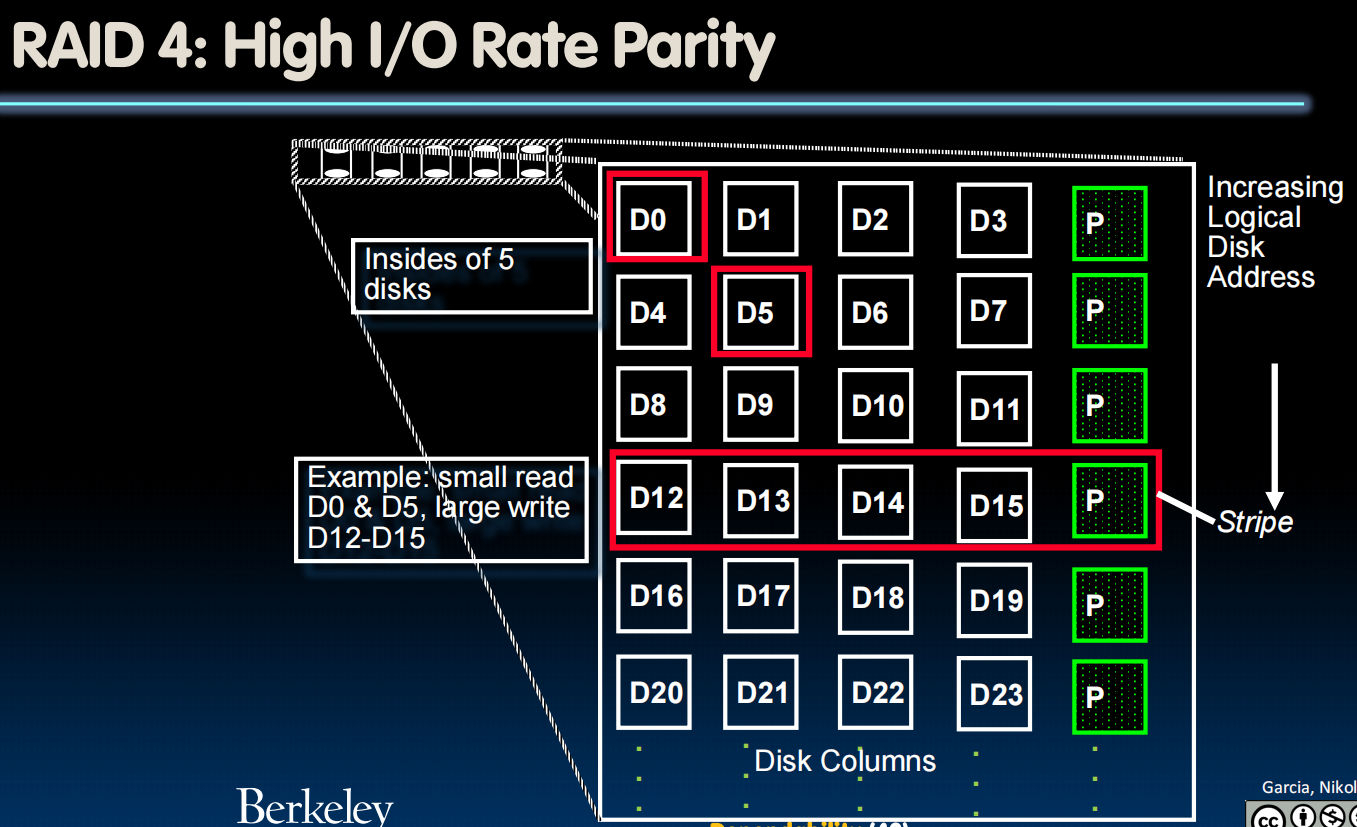
RAID 4: High I/O Rate Parity
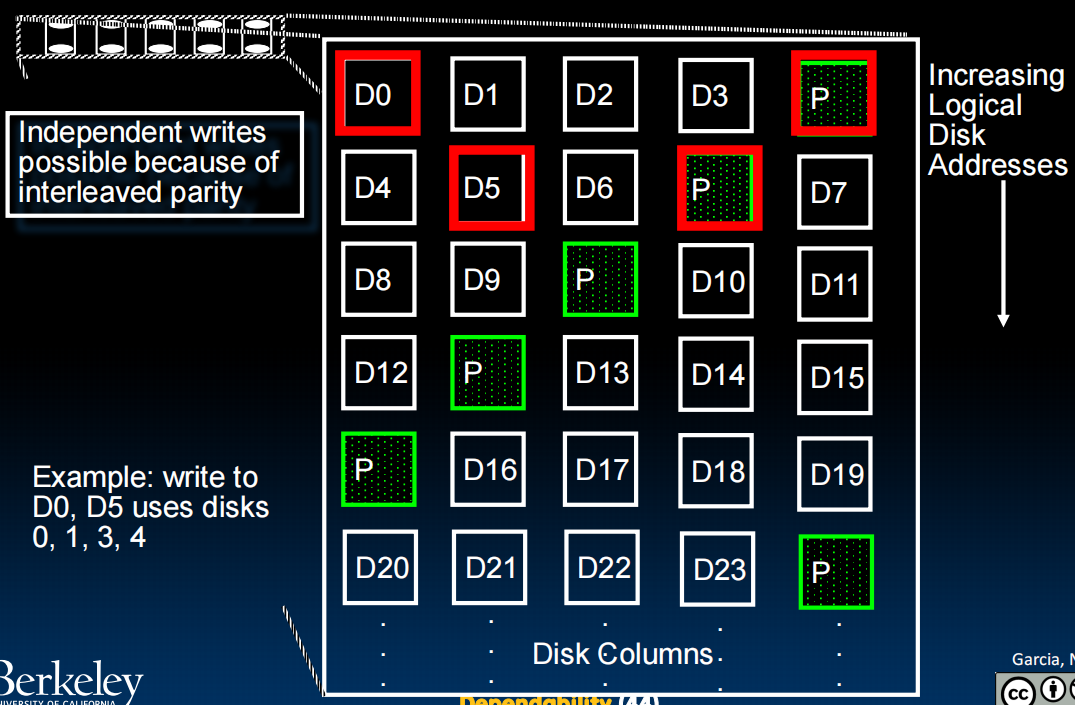
RAID 5:High I/O Rate Interleaved Parity

lec39-GPU Architecture
由Apple的人来讲的,好像要保密…但是视频都发在B站上了,应该没啥吧(

CPU:一个数学教授,GPU:一群小学生。为了解决巨量的简单问题,GPU显然是更优解。
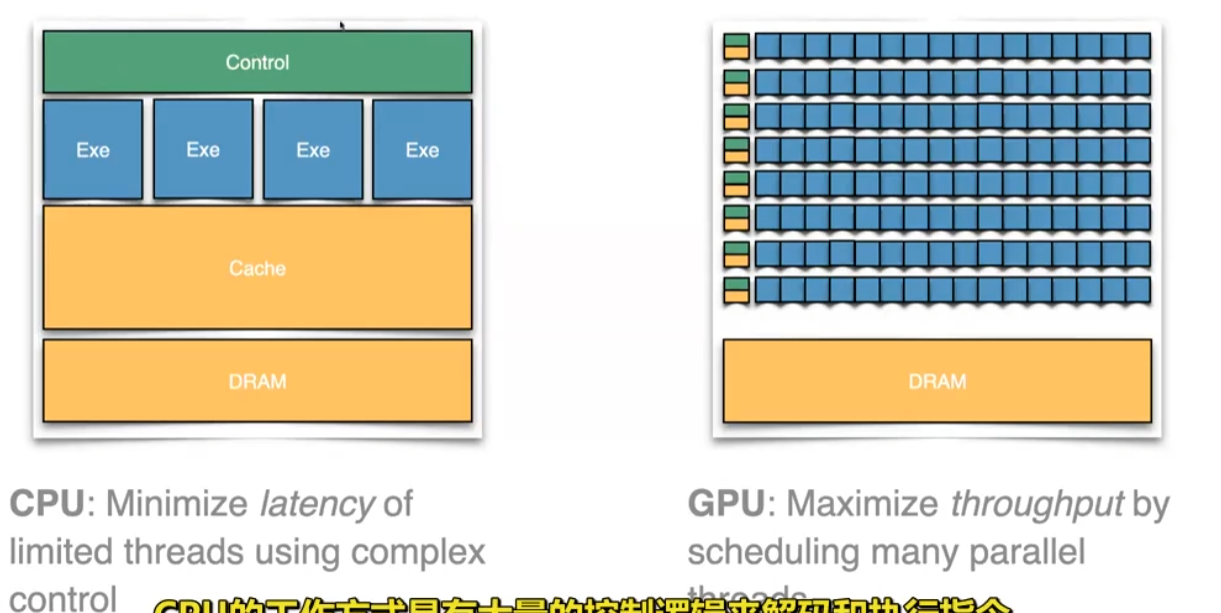
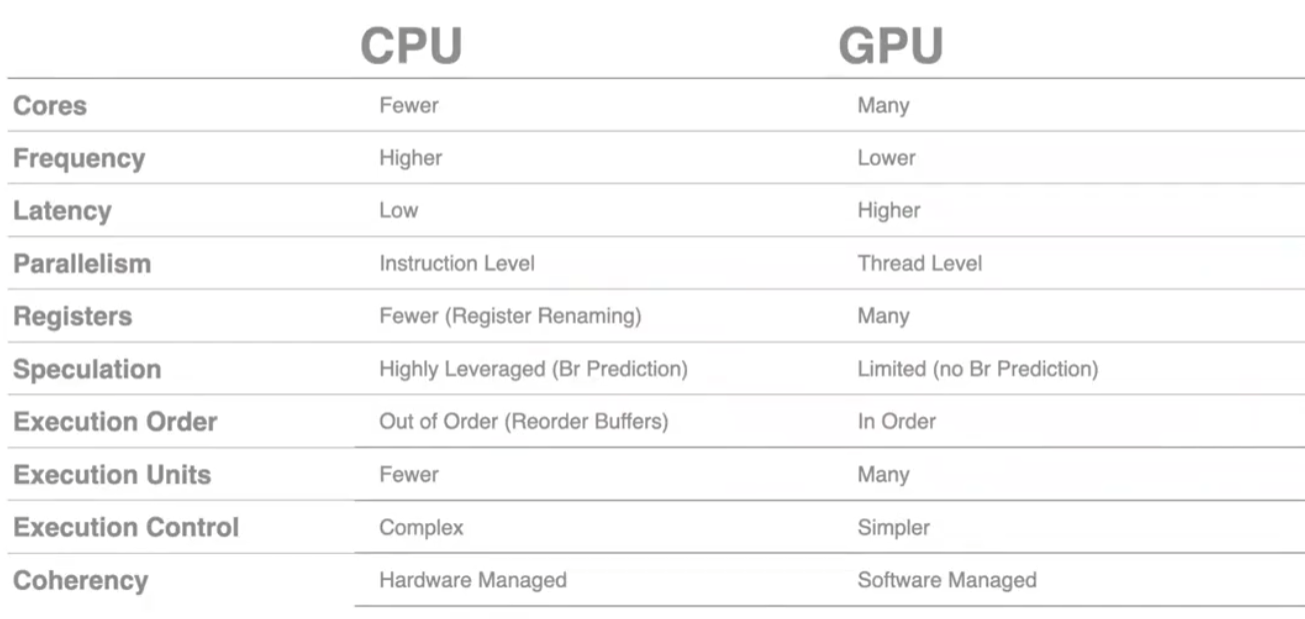
GPU的目标:最大化吞吐量。可以访问很大的Memory bandwidth(带宽)

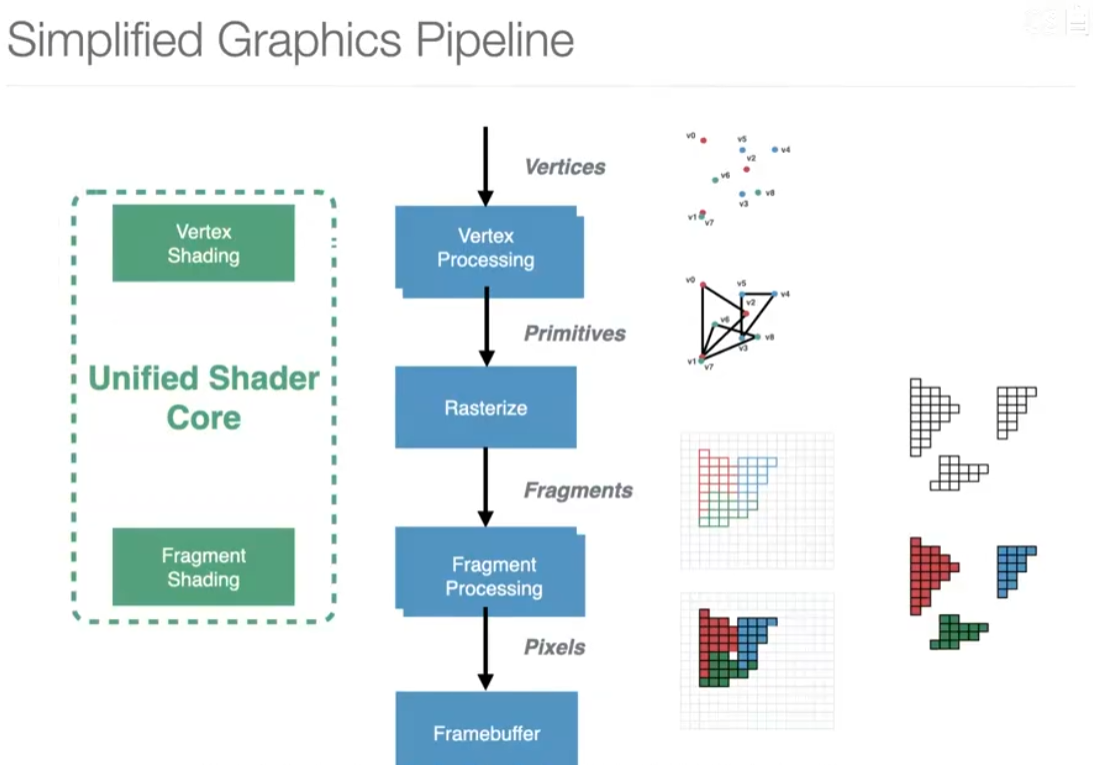
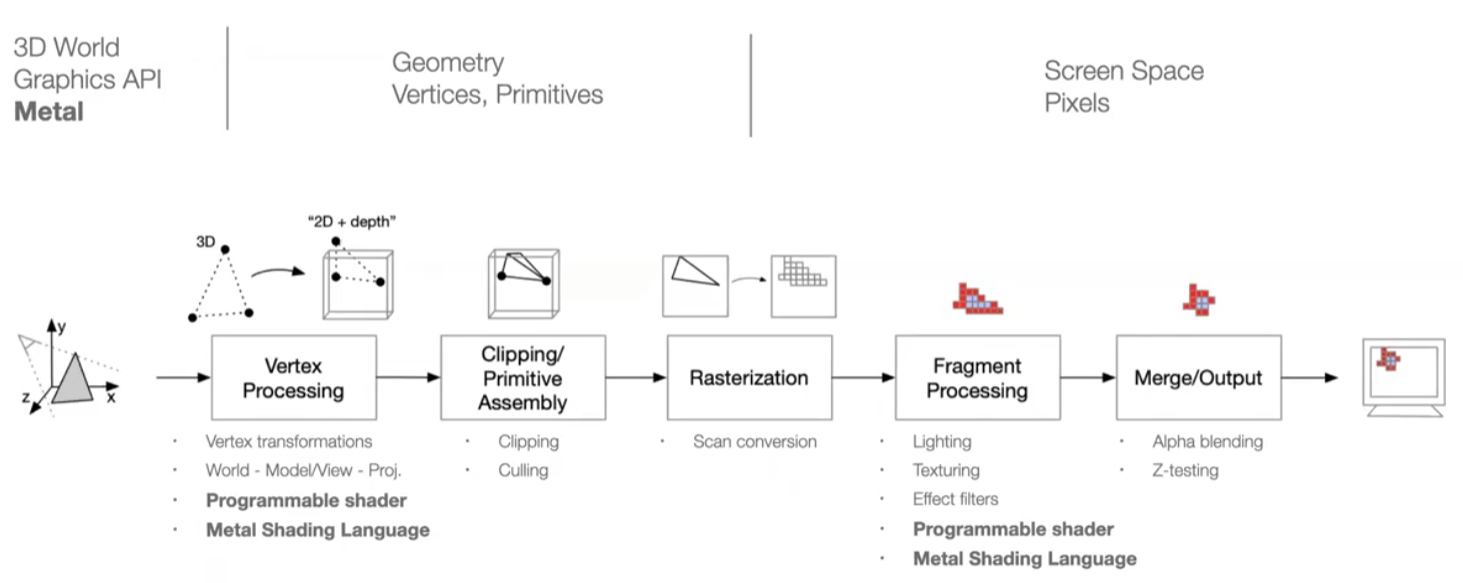
第一步:vertex processing
vertex shader 定点着色器。
这一步其实是在做非常大的矩阵乘法,变换矩阵4*4
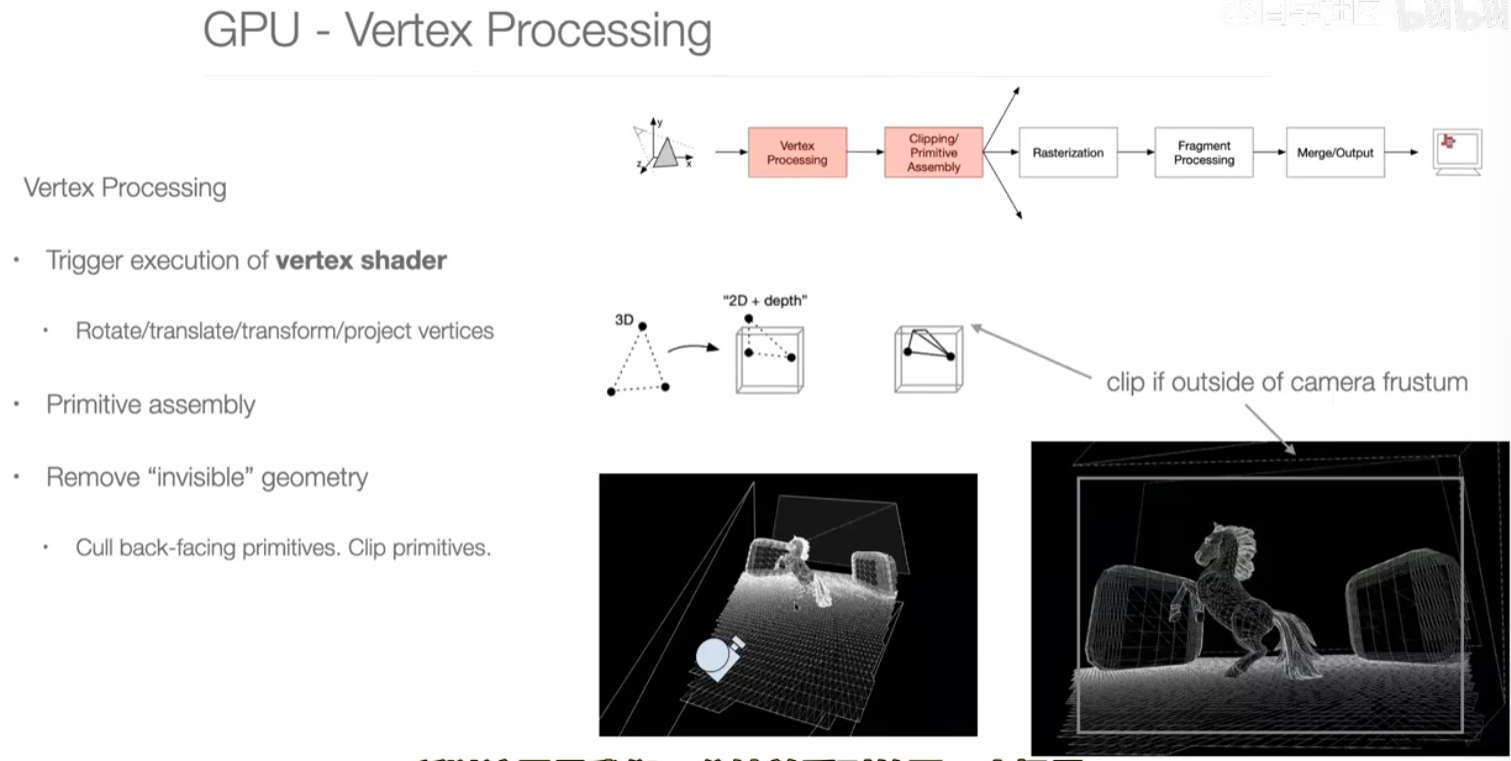
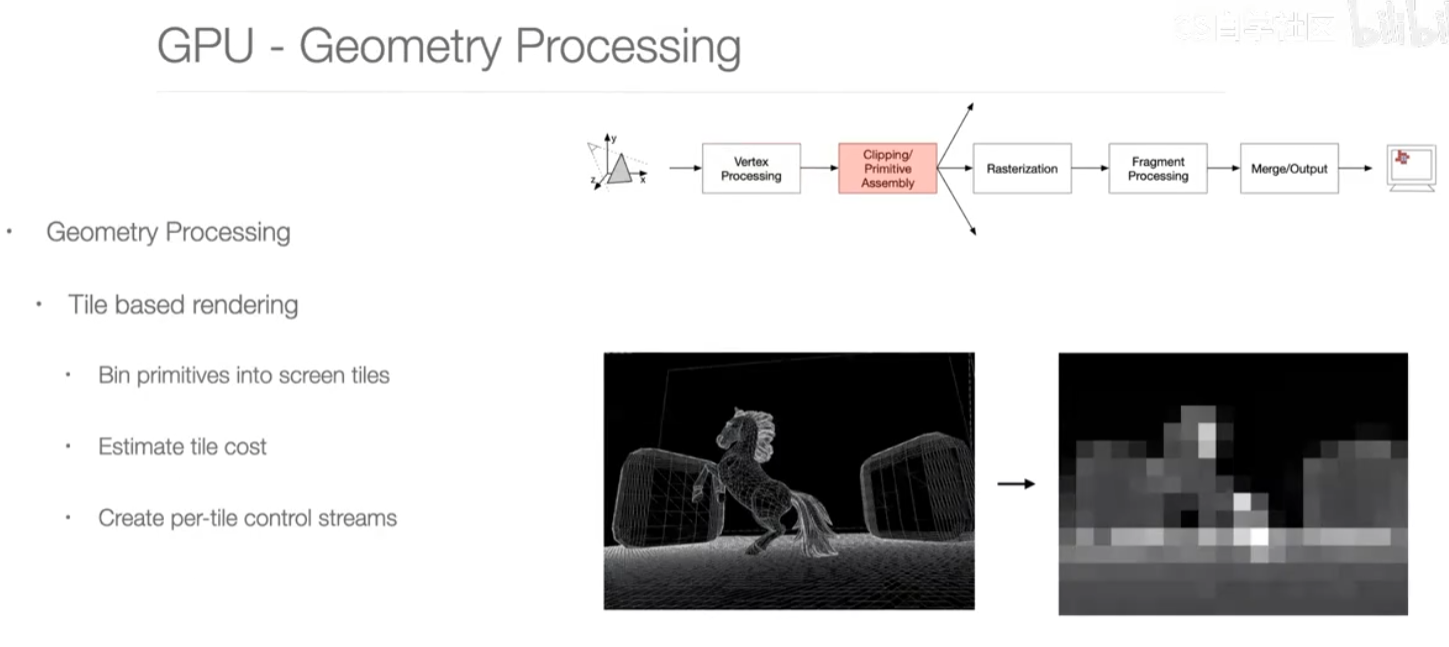
第二步:geometry processing
通过三角形组装起来,哪些地方难以渲染?
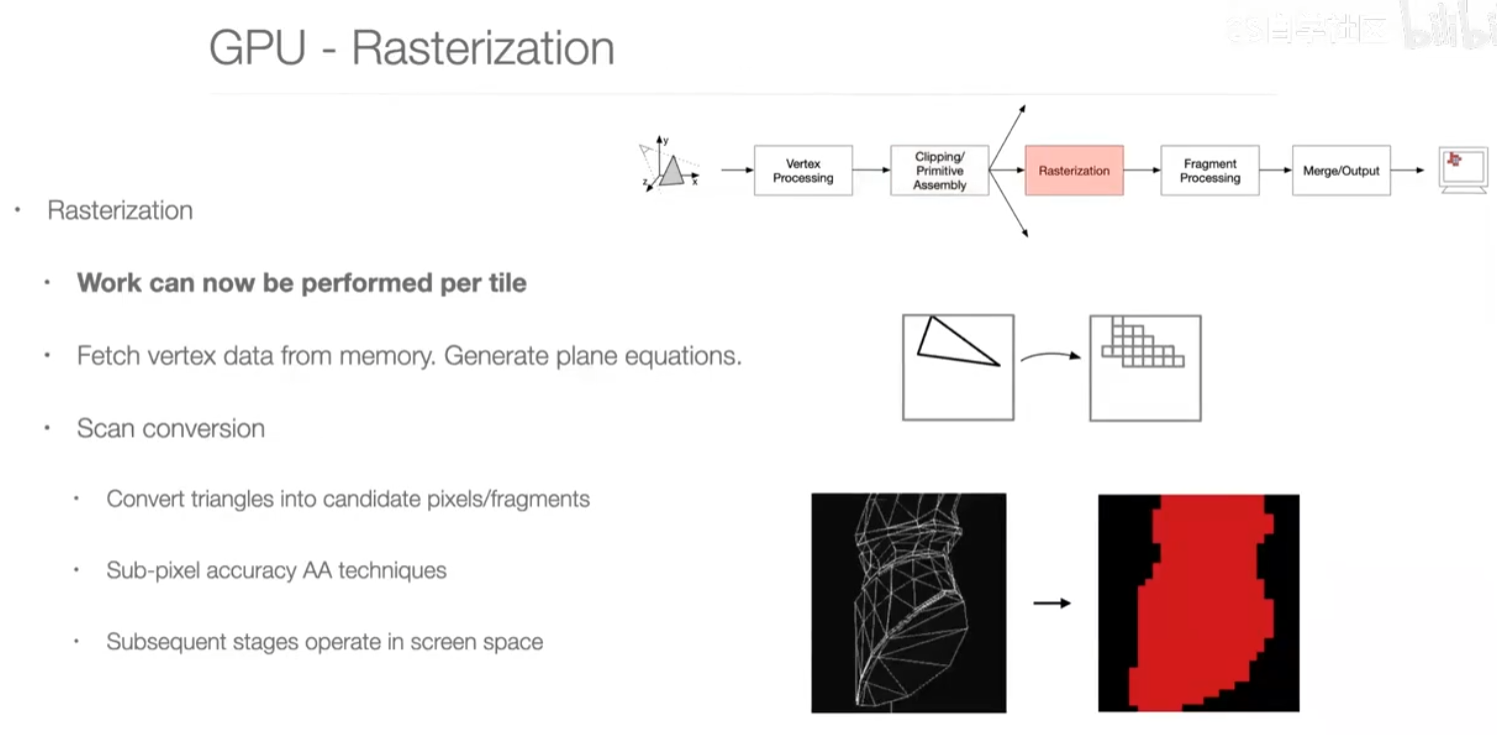
第三步:rasterization
光栅化,把三角形转换为像素
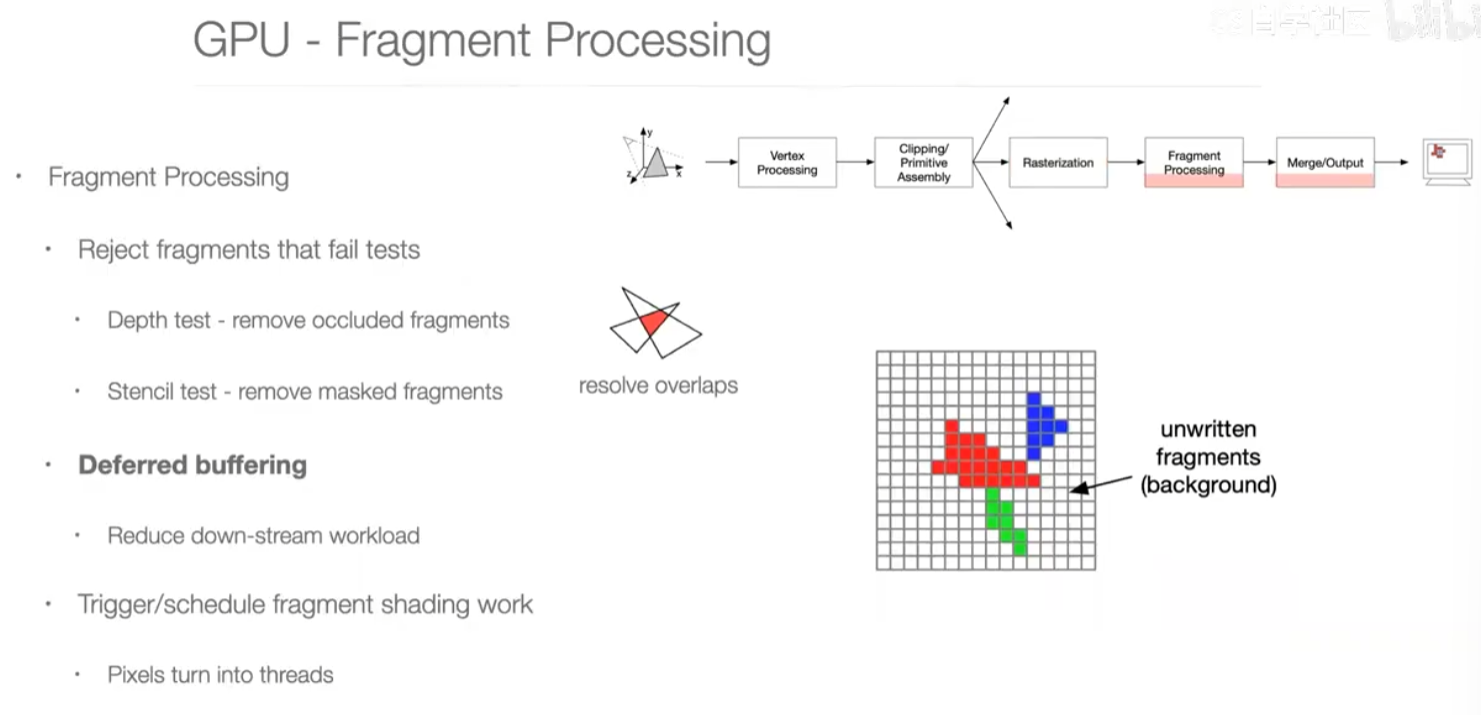
第四步:fragment processing
片段处理
depth test:被覆盖的部分不用上色
第五步:shading
着色
光照算法
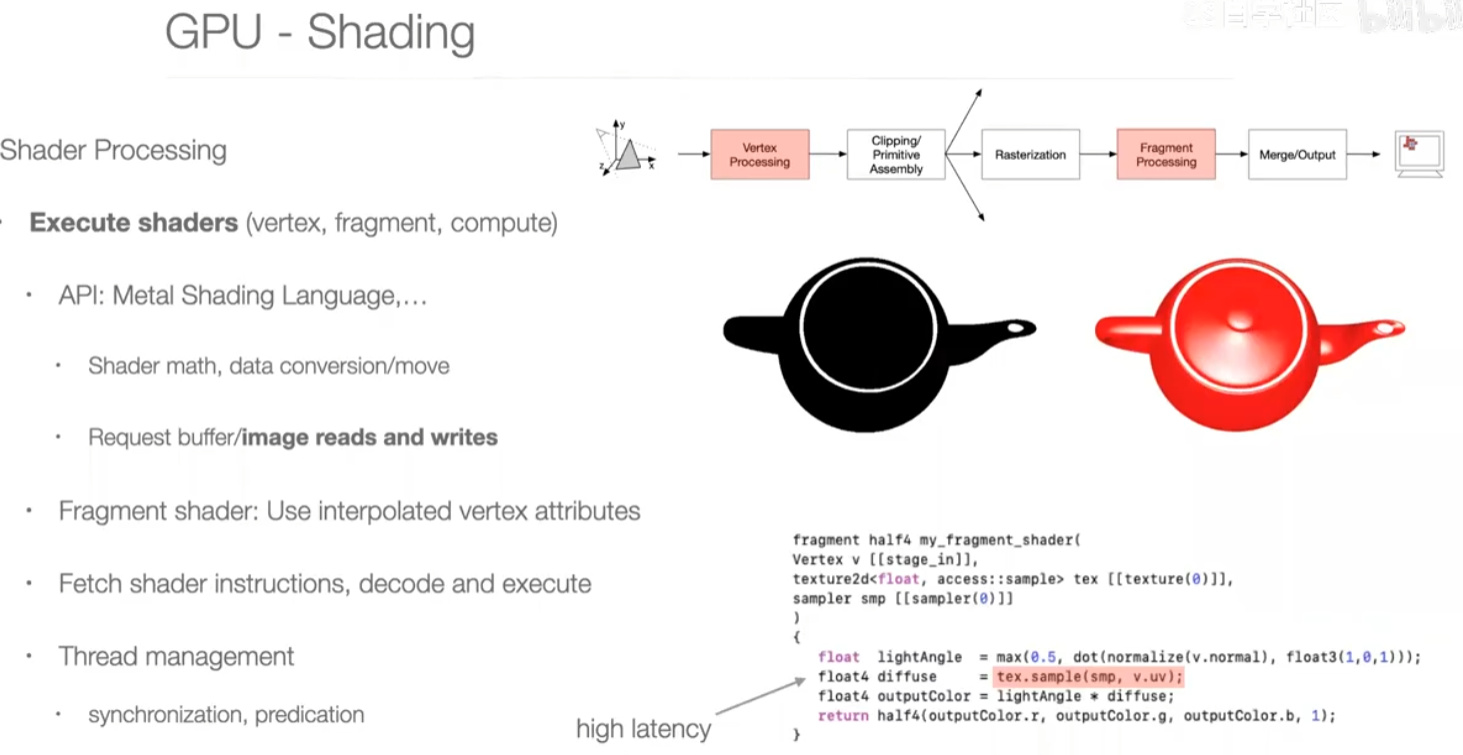
SIMD加速execute shaders
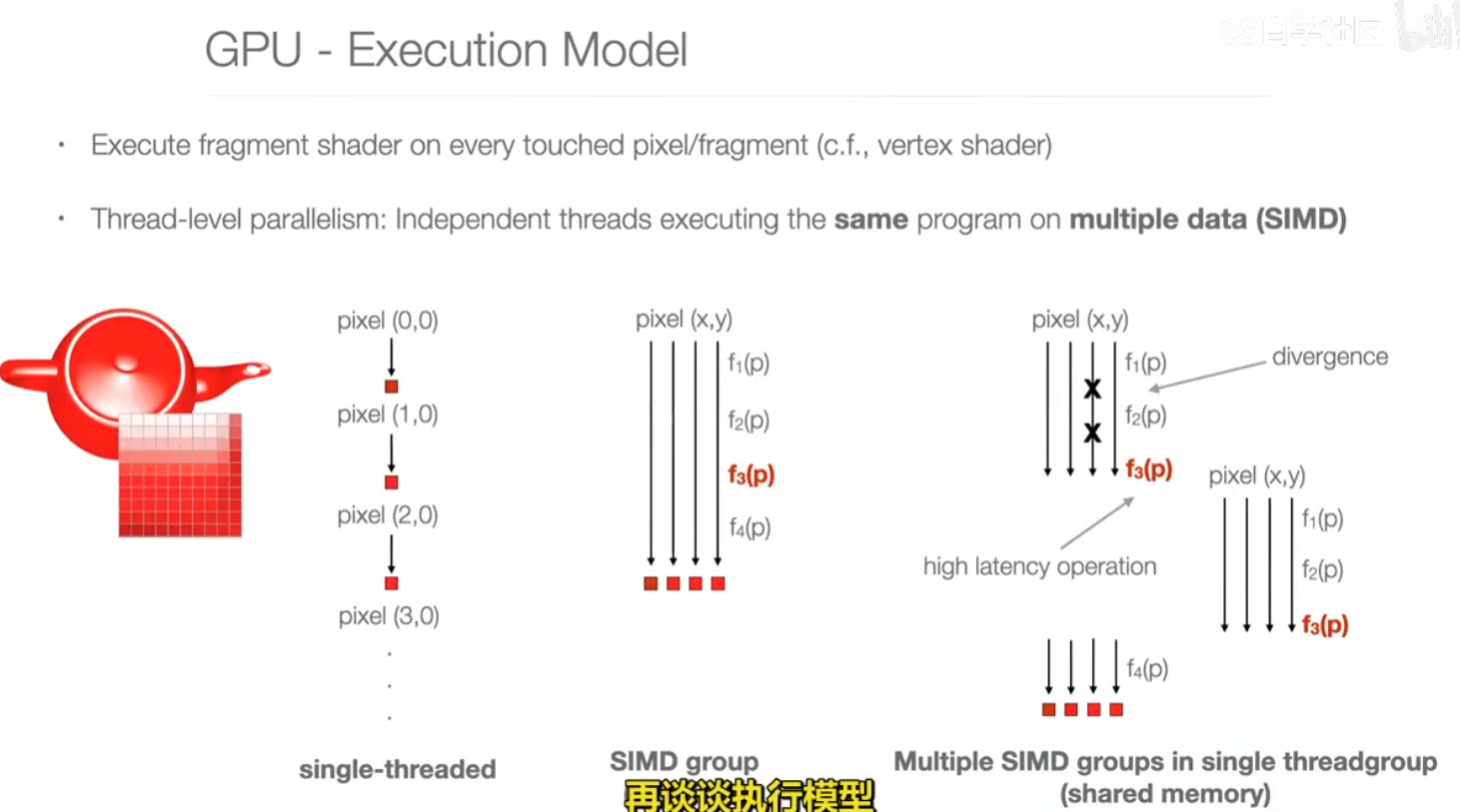
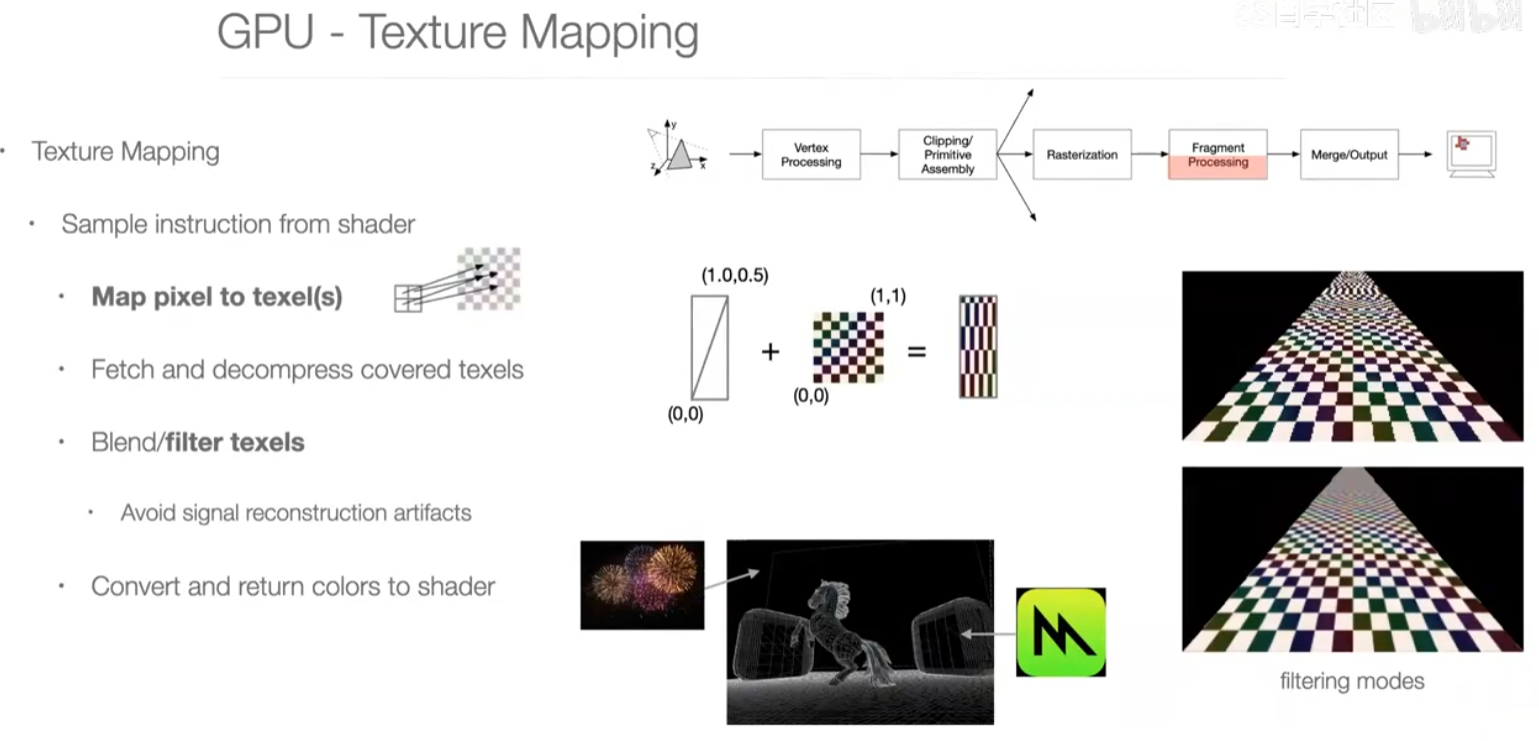
texture mapping 纹理。eg.把烟花放上来。
抗锯齿
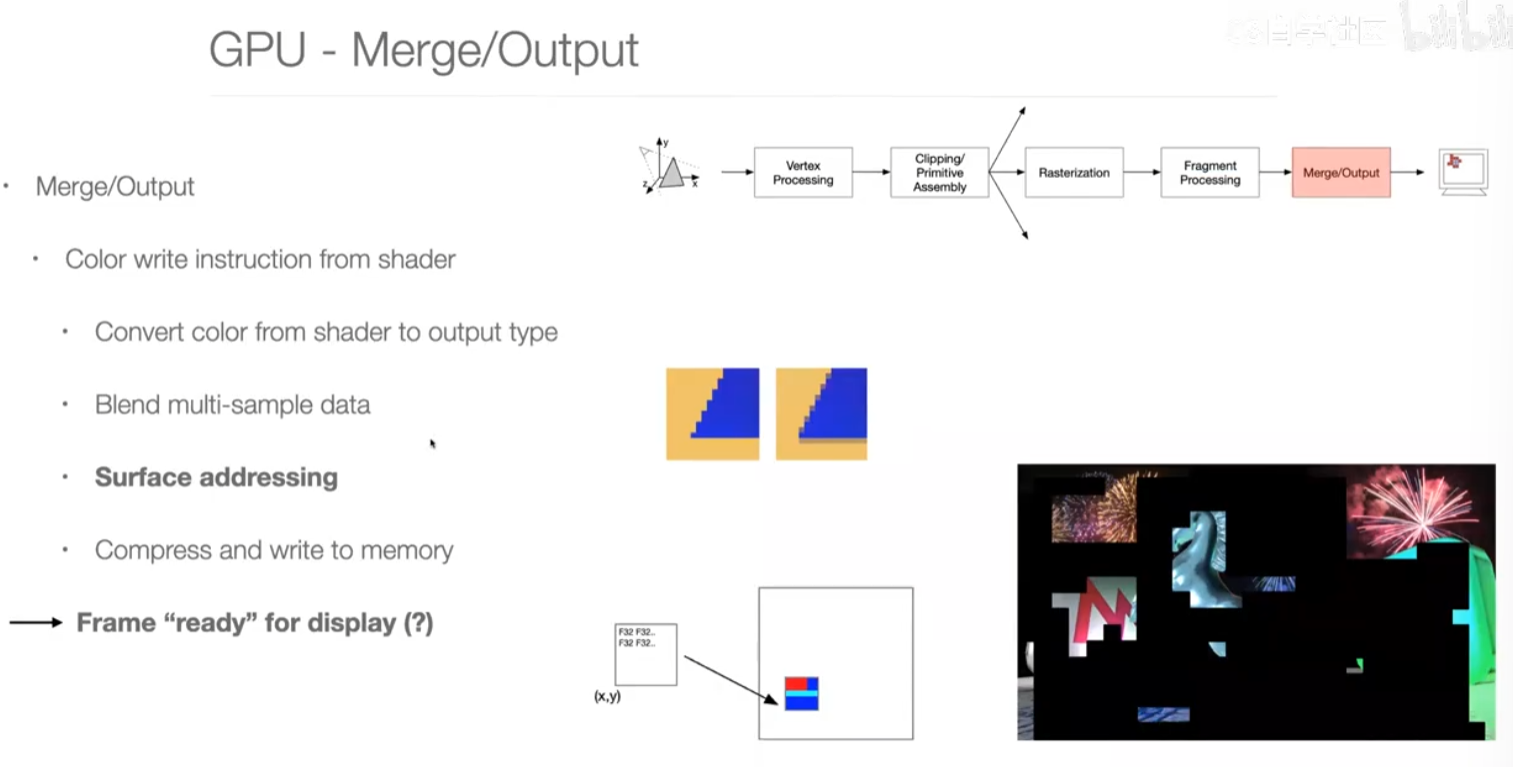
第六步:merge output
lec40-Summary & Farewell
6 Great Ideas

Old School “Machine Structure”
New School Machine Structures (Parallelism)
Hardware and Software Connection
后续课程:


两位讲师:Dan

Bora

CS61C作为伯克利的计算机体系结构的入门课,两位讲师用风格各异的教学讲授了很多很多对于一个系统领域新生很有意思的内容。于我而言,这也是非常非常有意思的一趟旅程。作为个人第二次的自学,我认为无论是一点点听完40*1h的讲座,还是上手做projects和labs都是非常有意思的事情。感谢两位老师带来的精彩旅途!