

This blog is used to note down all the knowledge I’ve learned in this lesson.
And here is the notes that provided by the teacher.
My implements for 2024 version: (or you can see there things in my github)
Assignment 1 : google drive
Assignment 2 : google_drive
Assignment 3 : google_drive
The lecture I watched is 2017 version on bilibili
Lec1
Lec2 Image Classification pipeline
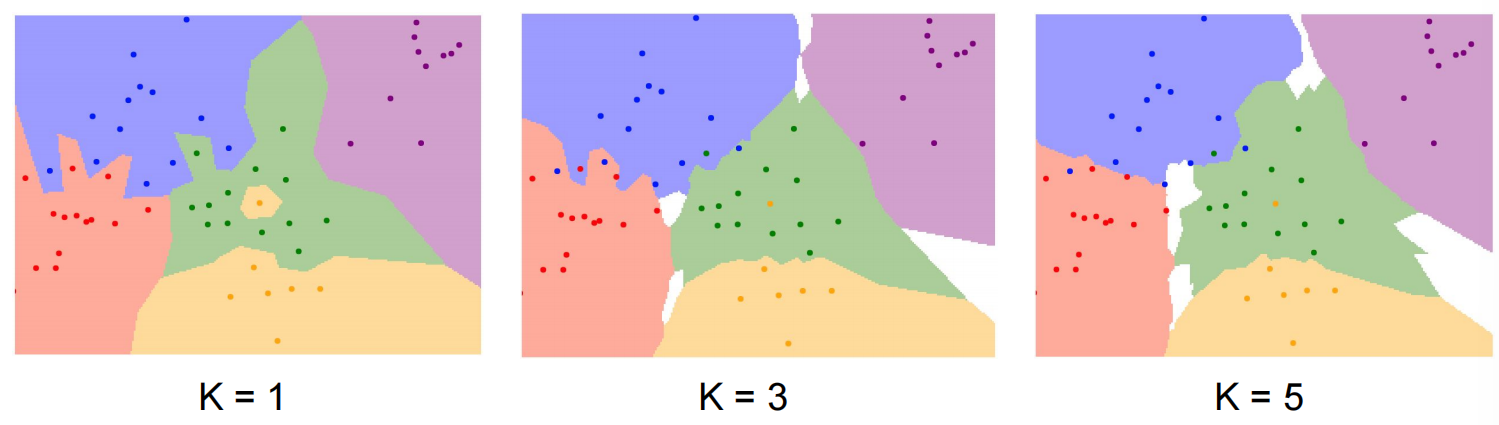
K-Nearest Neighbors k-最近邻算法
但实际上这个算法从未在图像上用过,因为如果图像向下移一点,或者换个色调,就完全不一样了。而且,二维,甚至三维的图像太大了,我们几乎不可能拿到那么多的数据点来覆盖。

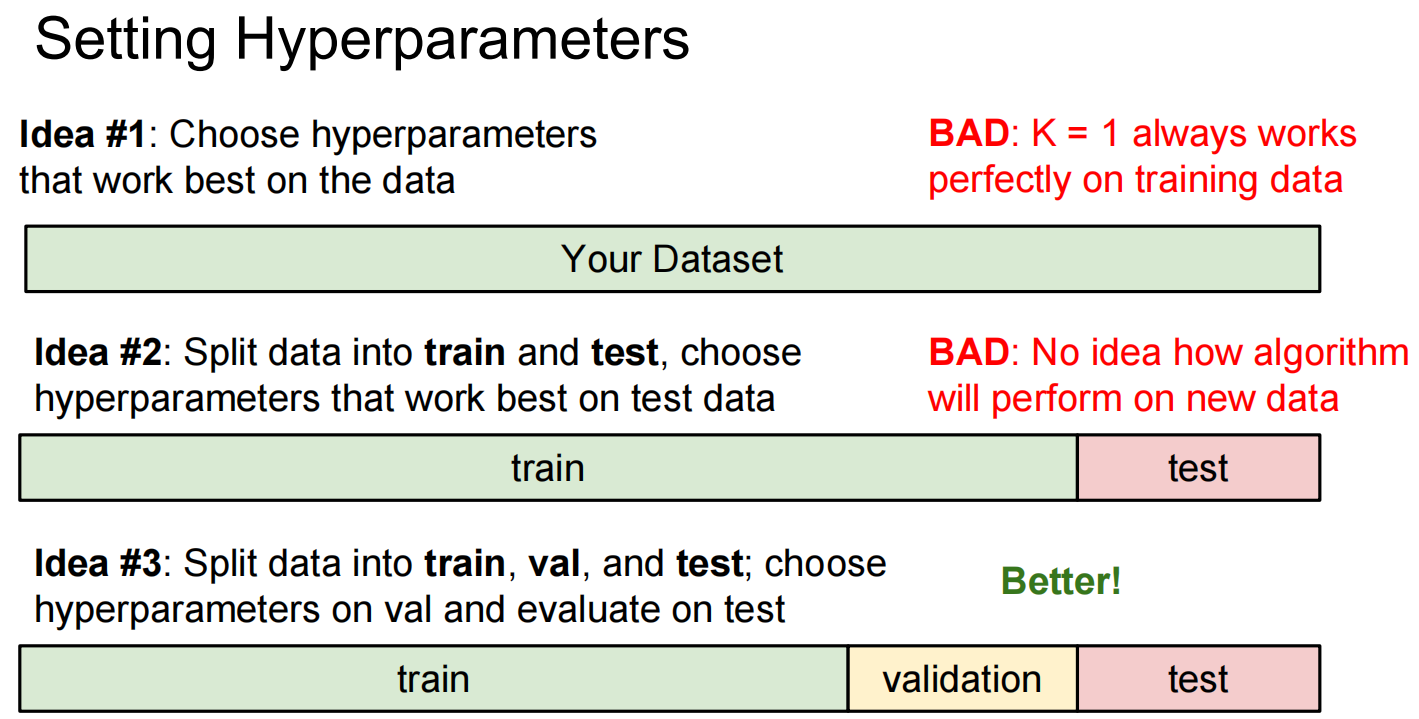
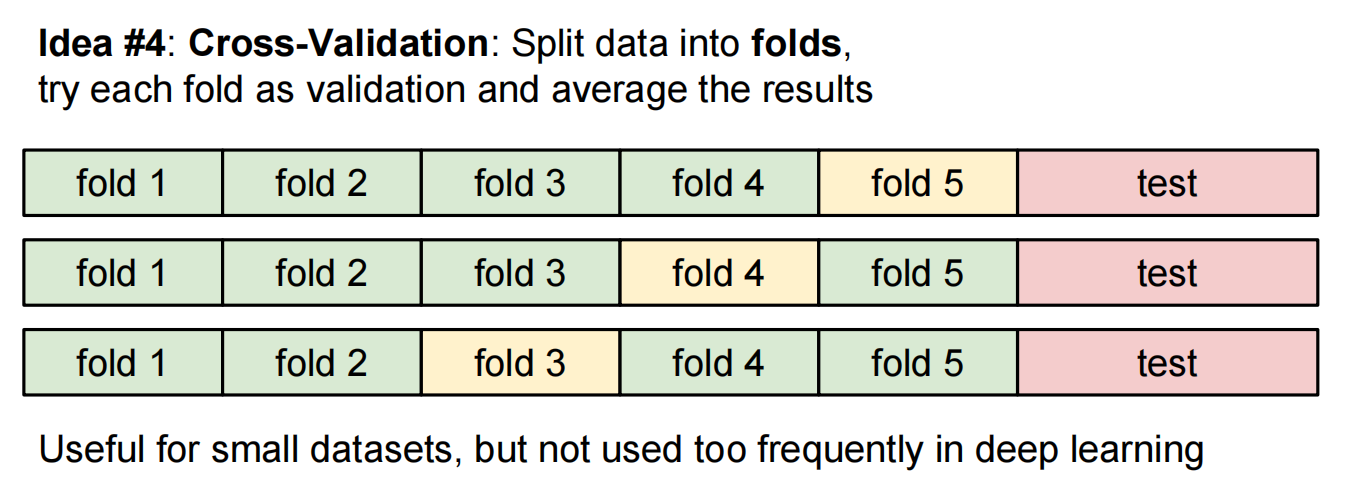
关于数据集与训练:
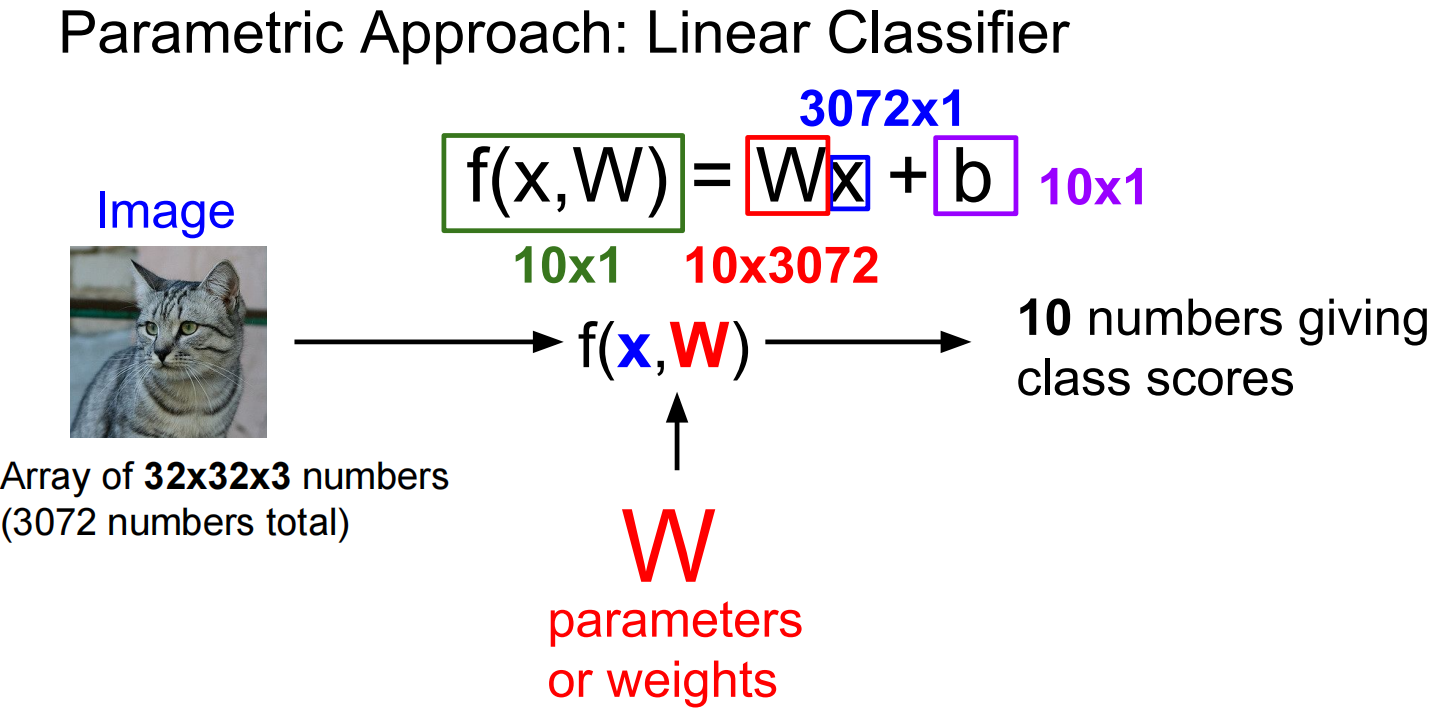
Linear Classification 线性分类
Lec03 Loss Functions and Optimization
loss functions

第一种:SVM loss:

如果loss function = 0,我们得到的W也不是唯一的
正则化:
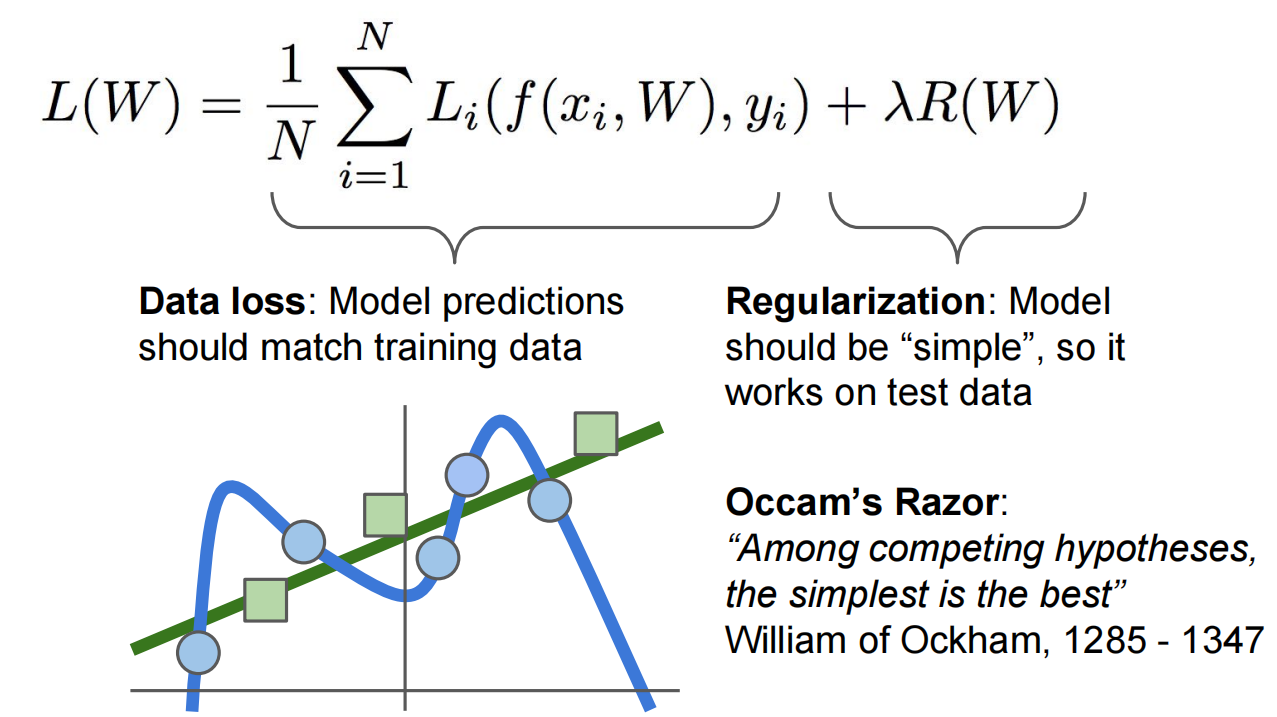

第二种:Softmax

Optimization
梯度下降
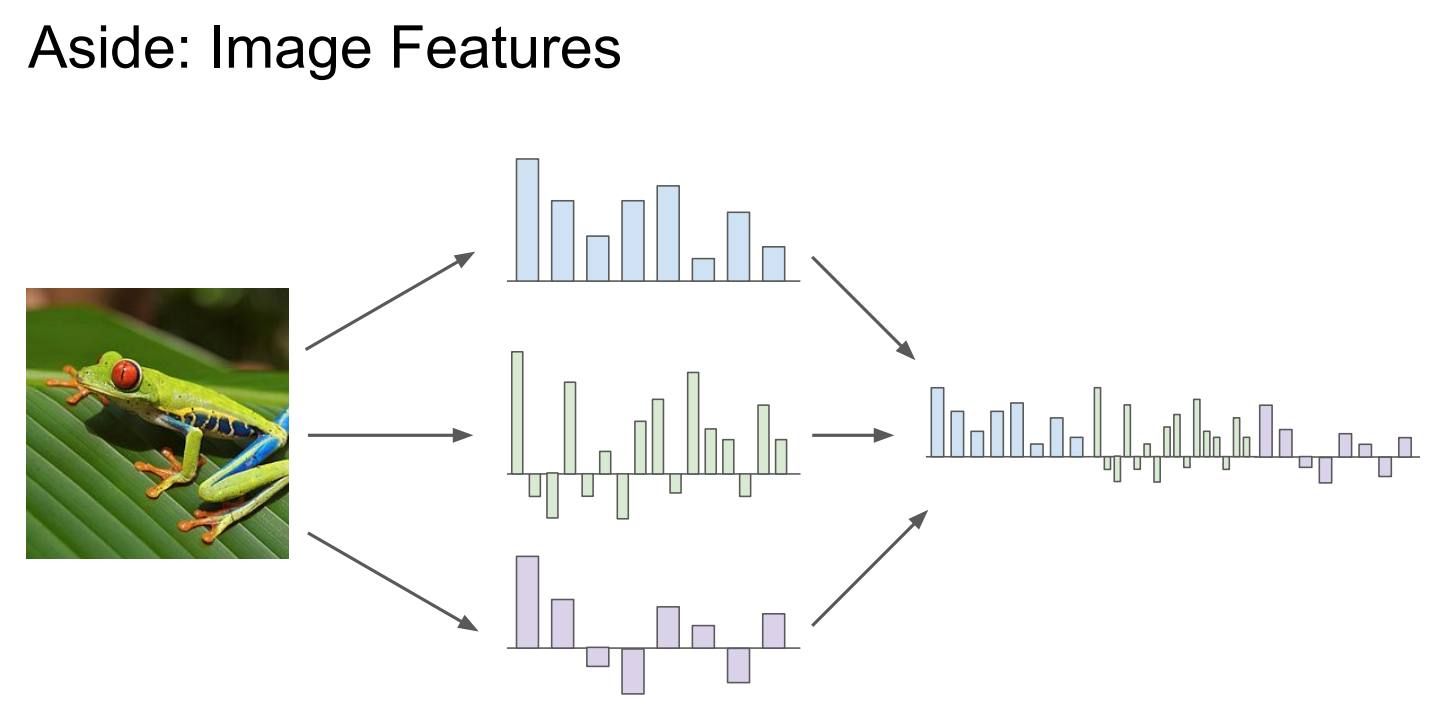
提取特征:
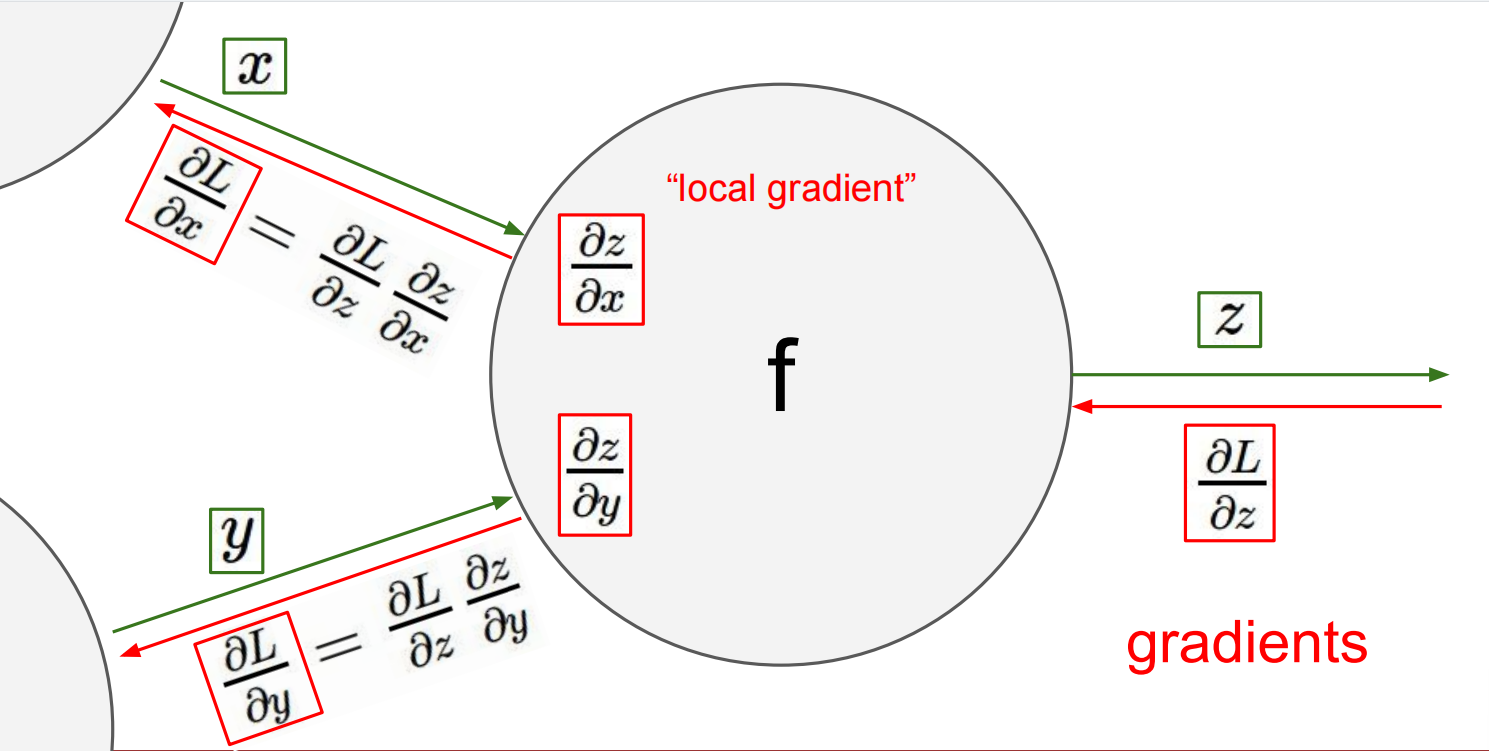
Lec04 Backpropagation and Neural Networks
反向梯度传播算法:
max gate:大的那个数梯度取1,小的取0
mul gate:同样
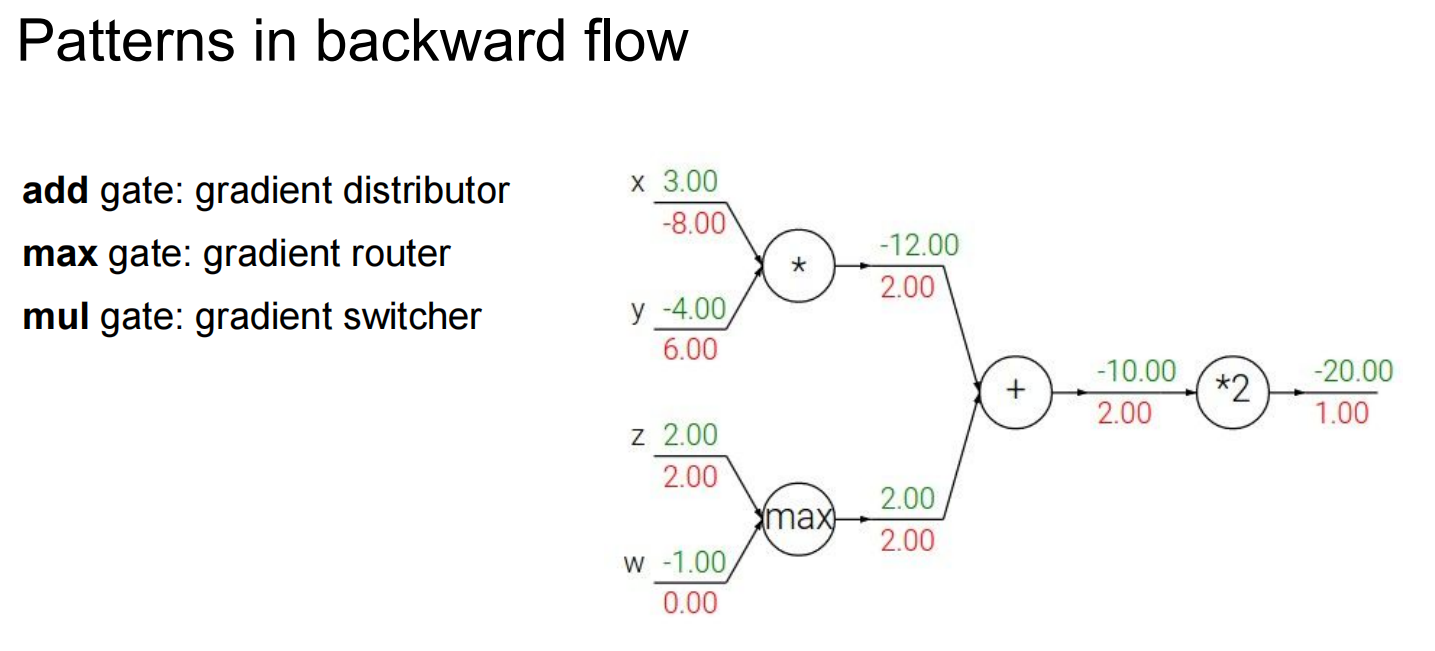
分支的话,两个分支传回来的梯度会相加作为梯度
对于向量而言:jacobian matrix
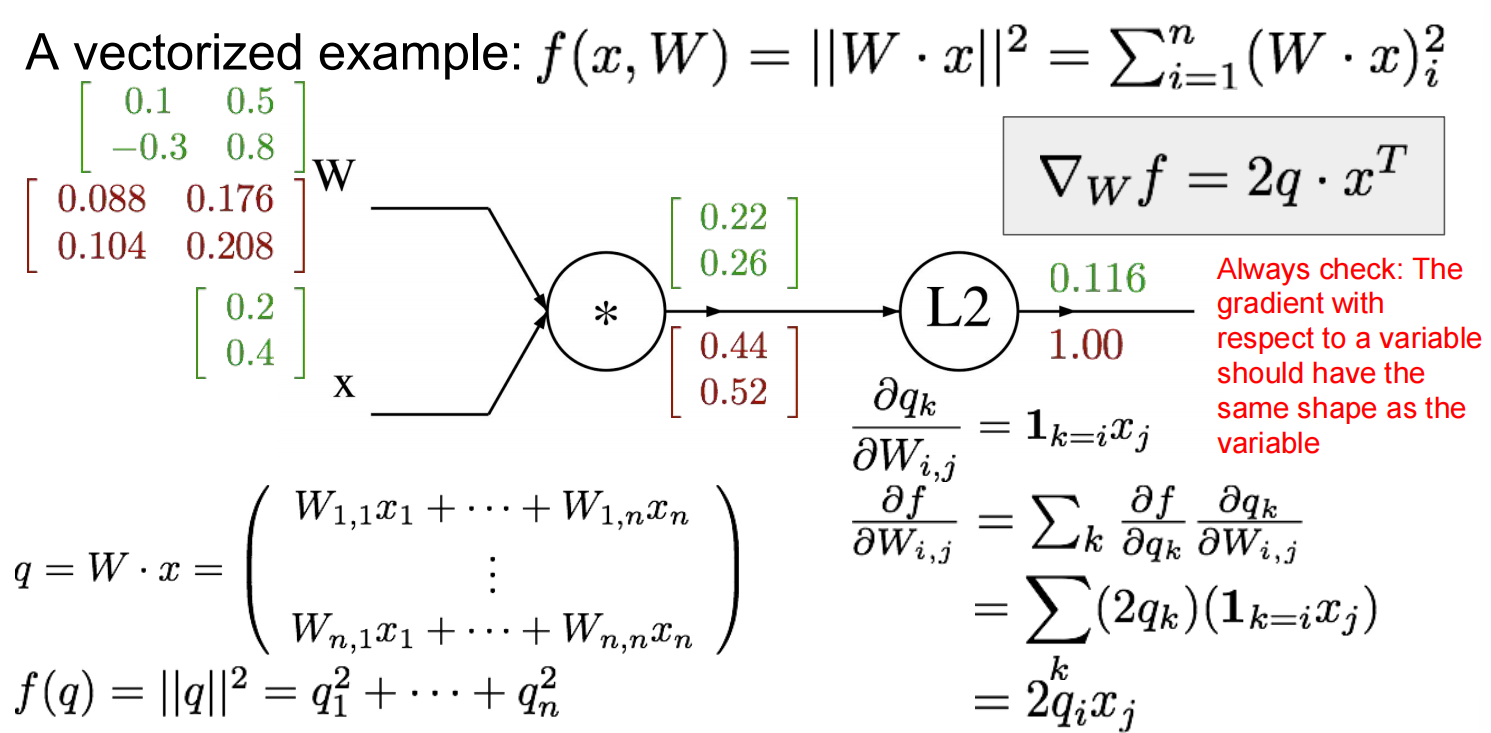
Neural Network

Lec05 Convolutional Neural Networks
卷积层:
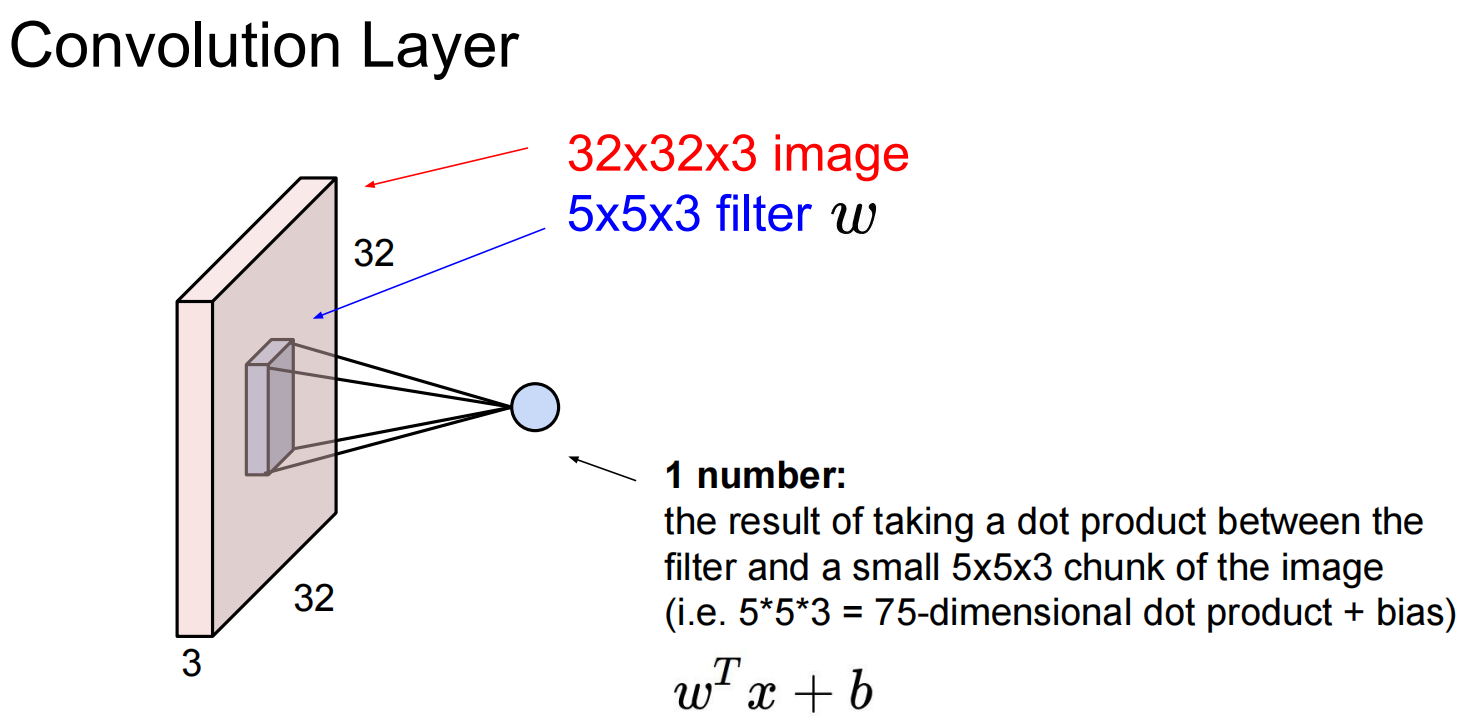
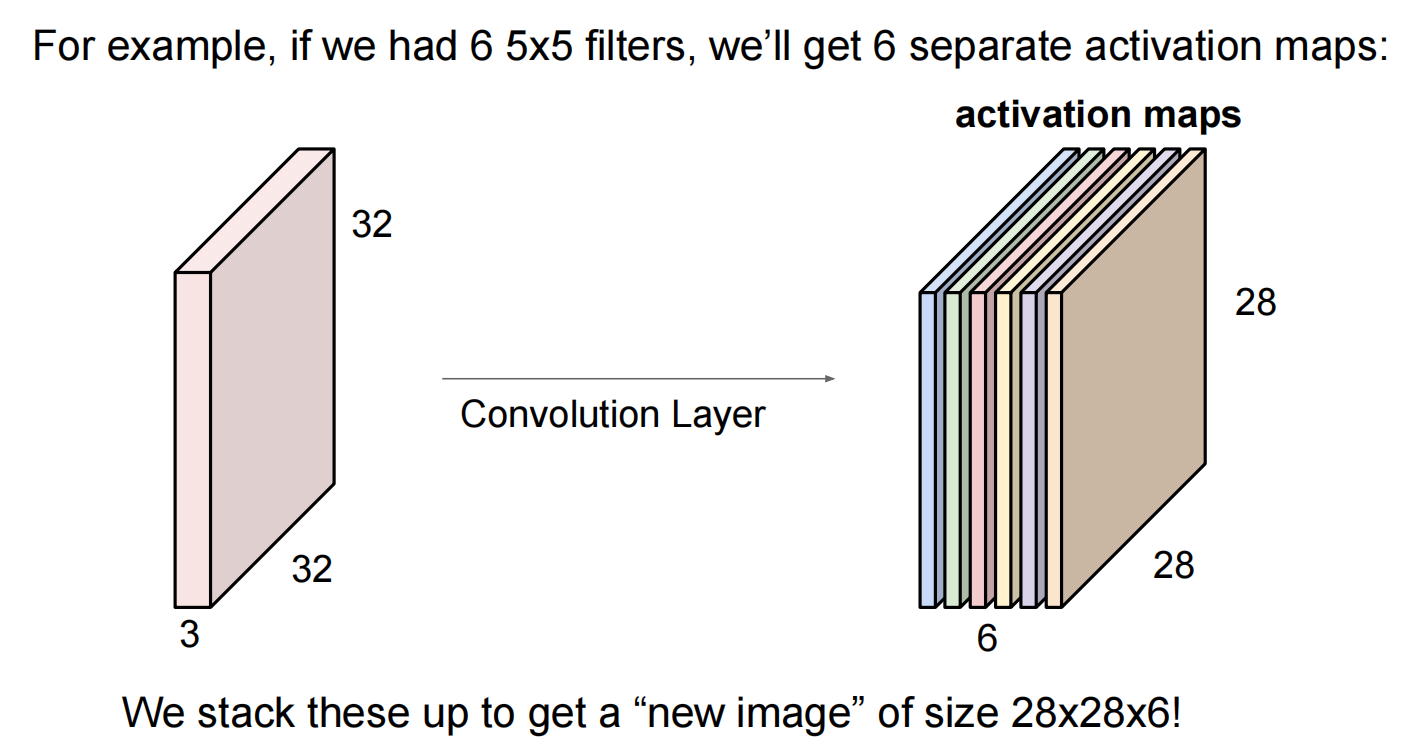
filter的补偿stride可多可少,但是要和图像吻合
补0:


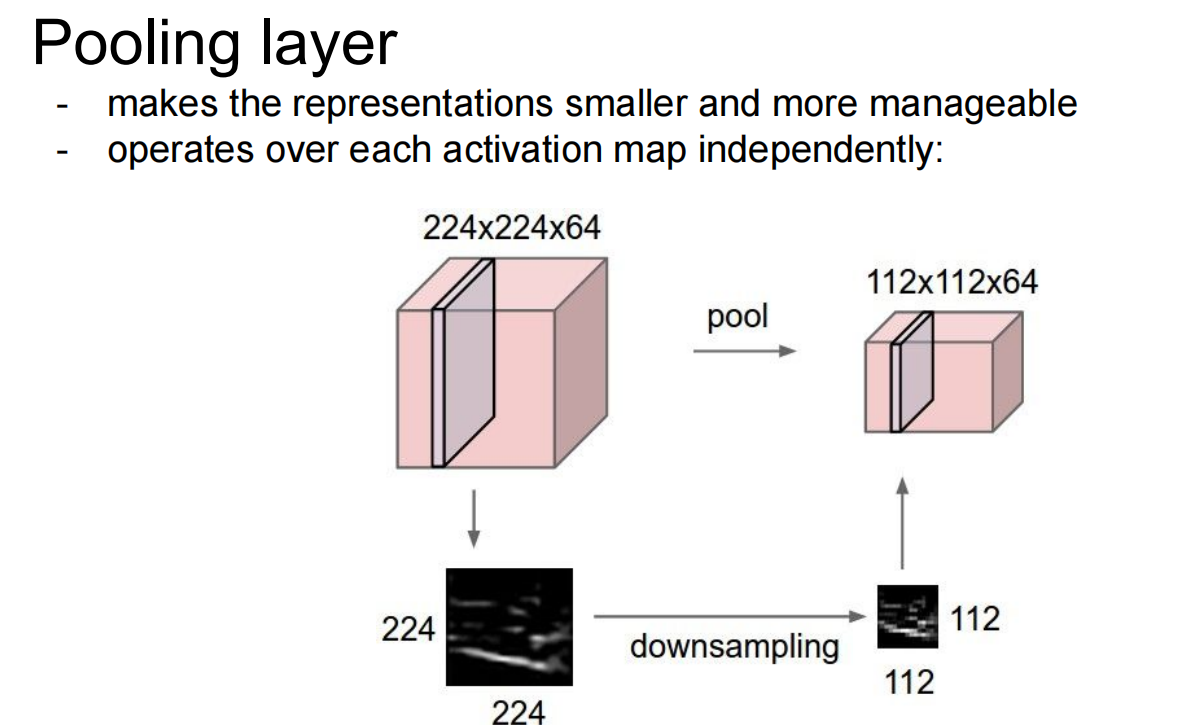
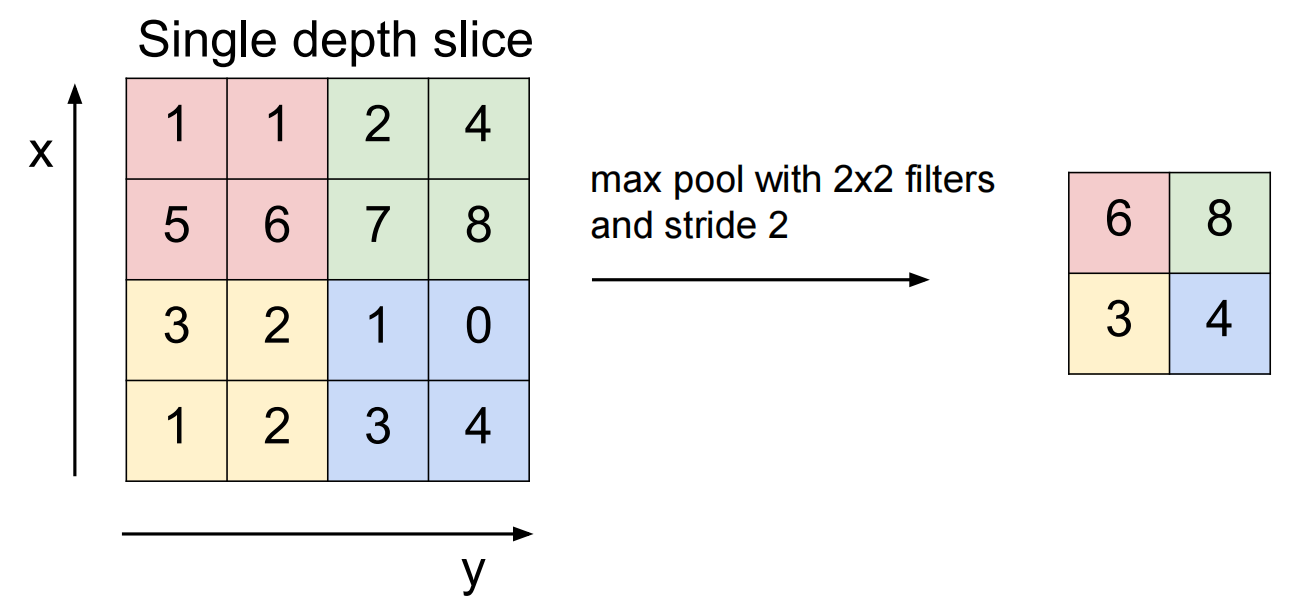
max pooling:

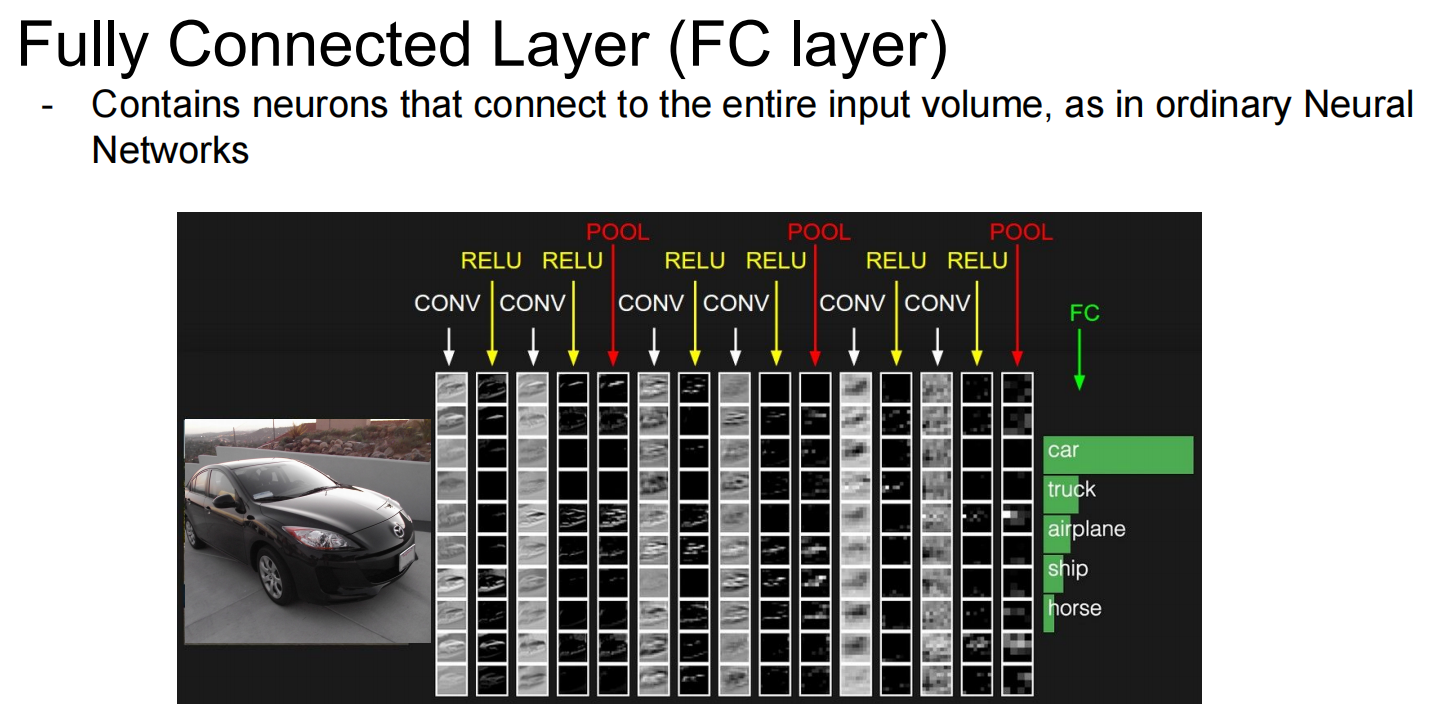
FC layer:
Lec06 Training Neural Networks Ⅰ
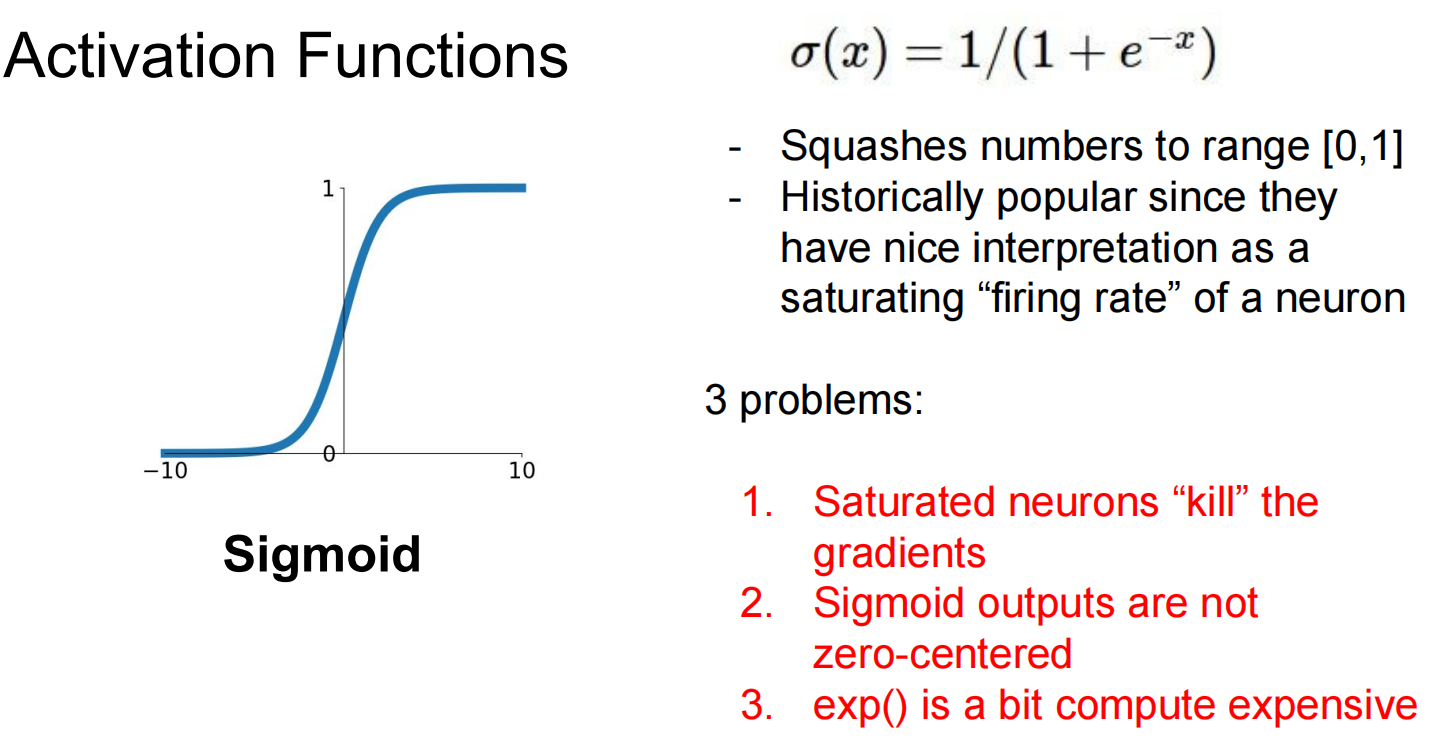
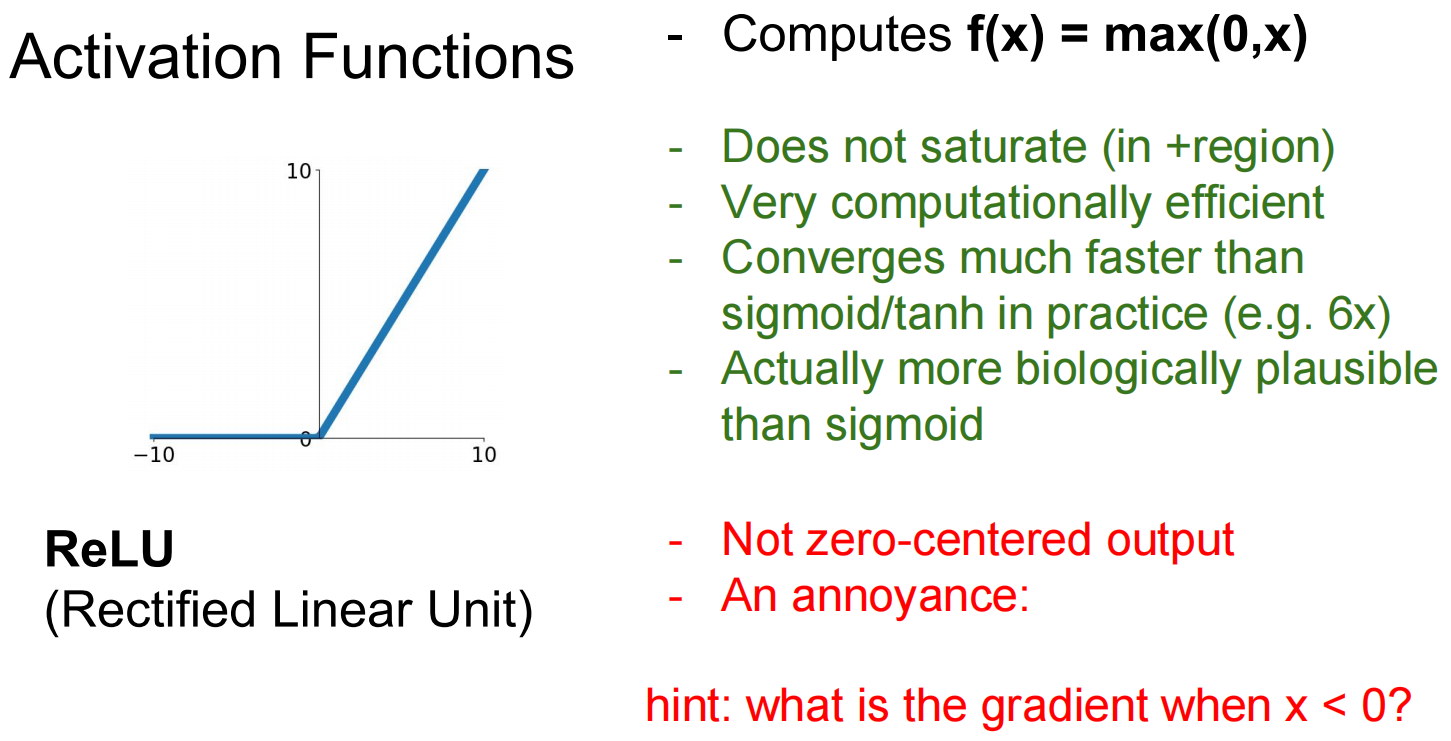
Activate functions



Data preprocessing

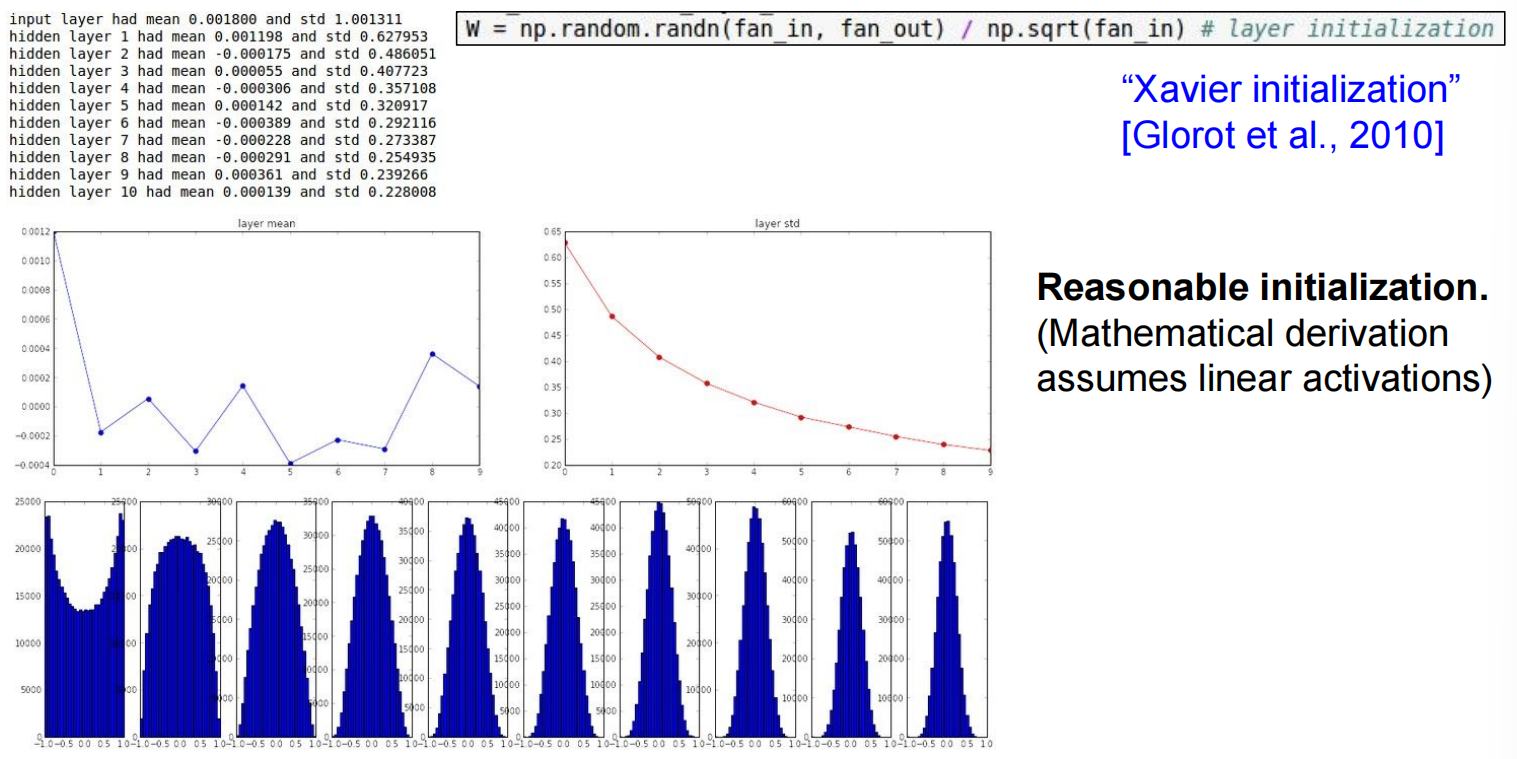
Weight Initialization
权重太小的话,所有的激活函数基本都是0,太大的话,基本都是+1,-1
Xavier Initialization: W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in)。这种方法旨在使每一层的输出方差和输入方差保持一致,在tanh等线性激活函数下表现良好 。但在ReLU下会失效 。
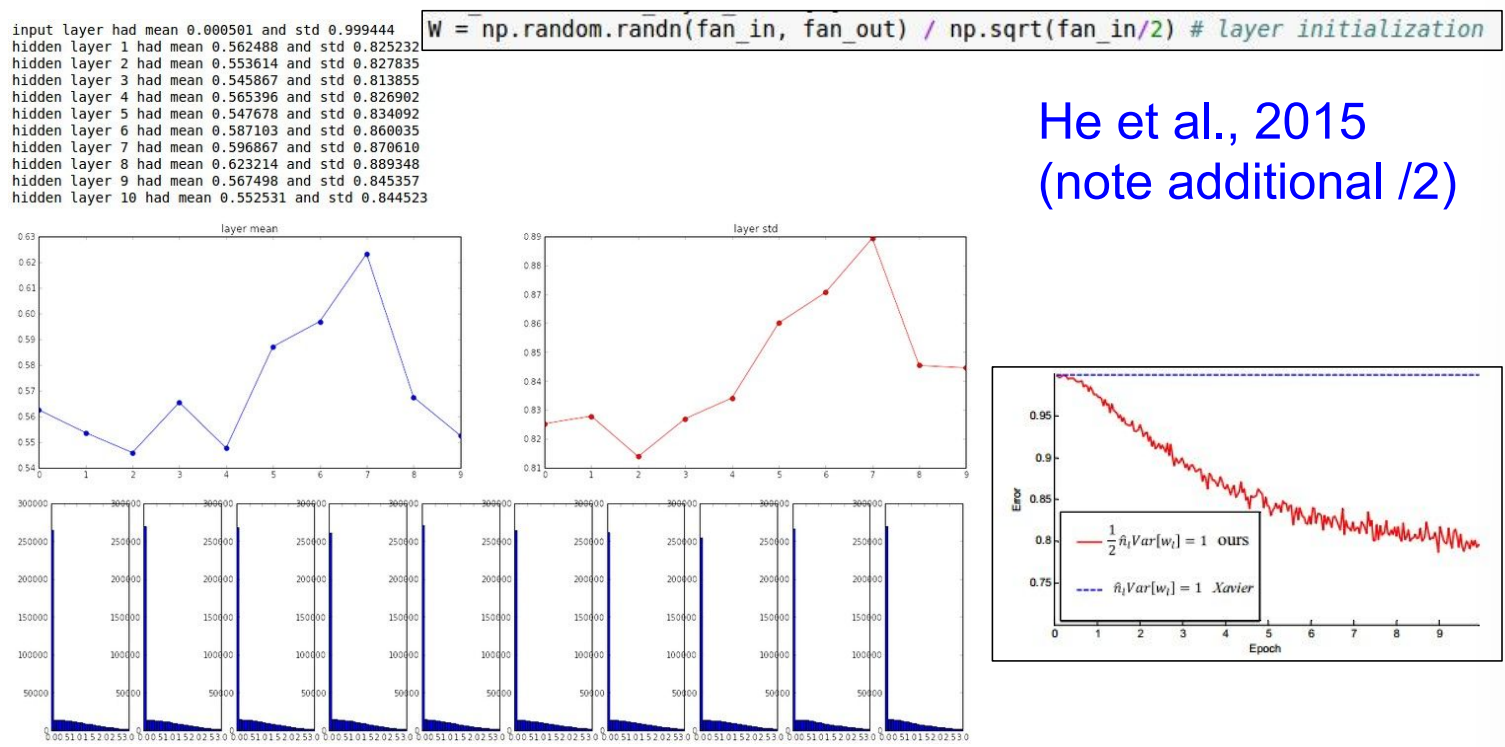
He Initialization: W = np.random.randn(fan_in, fan_out) / np.sqrt(fan_in / 2)。这是专门为ReLU设计的初始化方法,在实践中效果很好 。
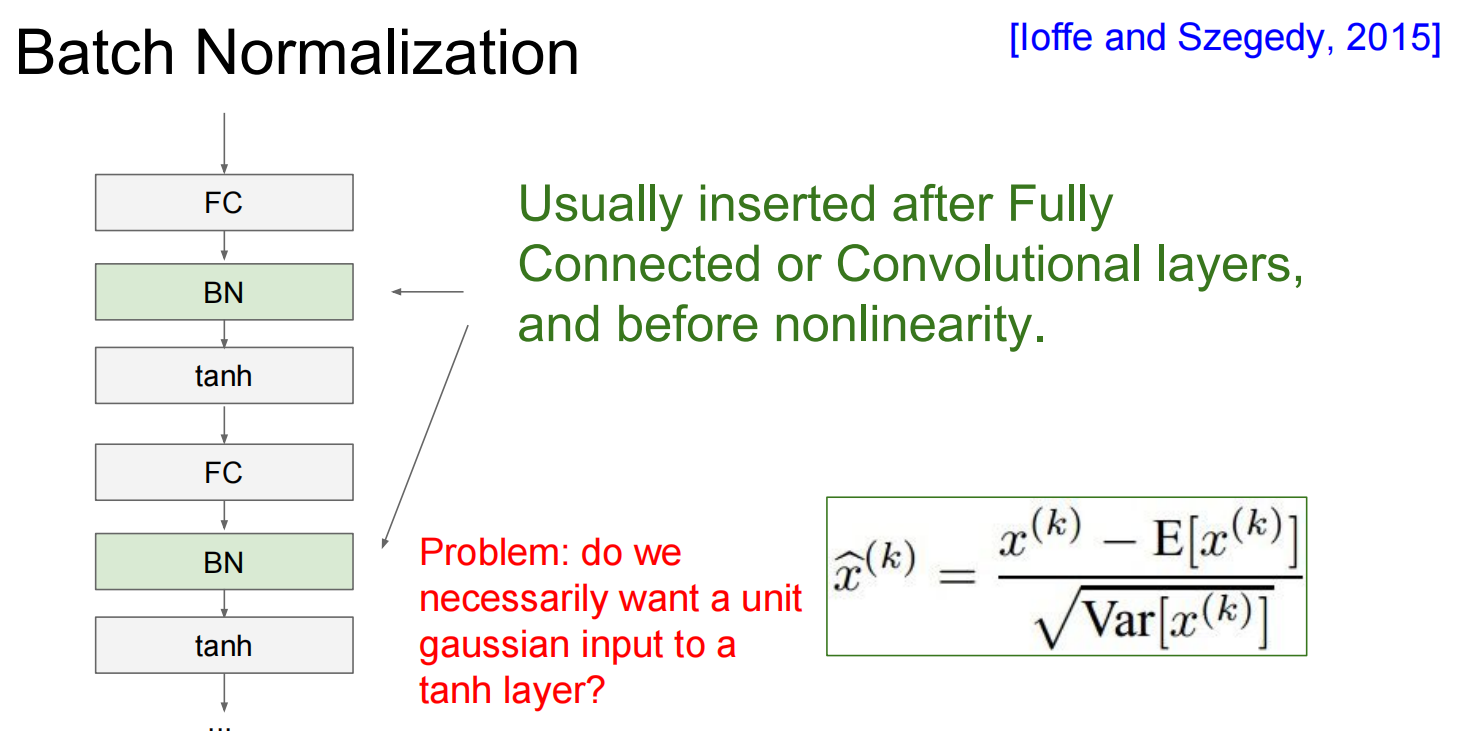
Batch Normalization
思想: 在网络的每一层、激活函数之前,强行让该层的输入(激活值)变回单元高斯分布(均值为0,方差为1) 。
做法:
对一个mini-batch的数据,计算每个特征维度的均值和方差 。
使用该均值和方差对数据进行归一化 。
引入两个可学习的参数
γ 和 β,对归一化后的数据进行缩放和偏移 (y=γx^+β),以恢复网络的表达能力。网络甚至可以学习到 γ 和 β 的原始值,从而抵消归一化的效果 。


Babysitting the Learning Process
步骤1:数据预处理 。
步骤2:选择网络架构,例如先从一个简单的单隐藏层网络开始 。
步骤3:执行“理智检查” (Sanity Checks)
- 关闭正则化,用小的权重初始化,检查初始损失值是否符合预期(例如,对于10分类问题,初始损失应约为
-ln(1/10) ≈ 2.3) 。 - 增加正则化强度,观察损失值是否相应增加 。
- 过拟合小数据集:选取一小部分训练数据(如20个样本),关闭正则化,看模型能否在这些数据上达到100%的训练准确率(损失降到接近0) 。这是确保模型有能力学习的重要一步。
步骤4:开始训练
Hyperparameter Optimization

每次迭代的时候计算梯度的数据随机:
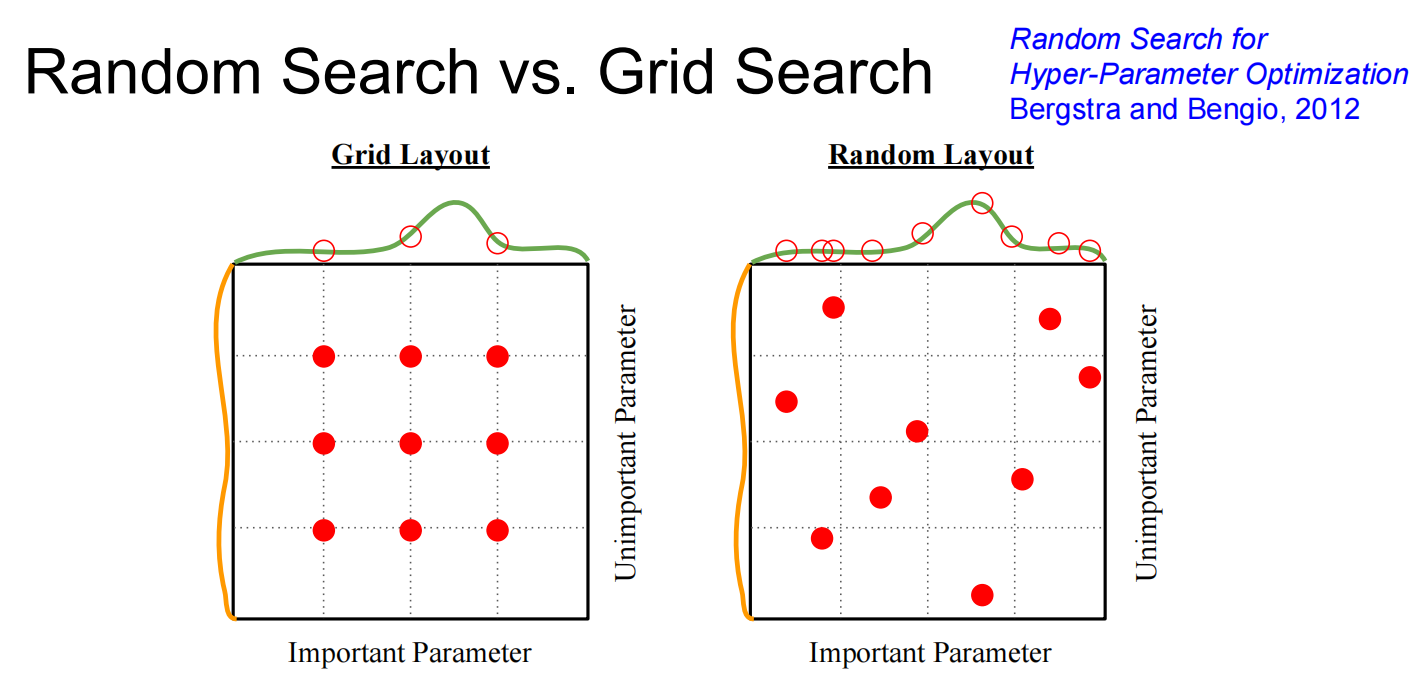
交叉验证策略:
- 随机搜索优于网格搜索 (Random Search > Grid Search) 。因为某些超参数比其他参数更重要,随机搜索能更高效地探索参数空间 。
- 在对数空间中搜索:对于学习率和正则化强度这类超参数,在对数尺度上进行随机取样更有效(例如,
lr = 10**uniform(-3, -6)) 。 - 分阶段搜索: 先进行粗略的大范围搜索(只训练几个epoch),找到表现较好的超参数区域,然后再进行更长时间、更精细的搜索 。
监控与可视化:
- 损失曲线 (Loss curve): 观察损失随时间的变化,可以判断学习率是否合适 。如果曲线太平,说明学习率太低;如果曲线抖动剧烈或上升,说明学习率太高 。
- 训练/验证准确率曲线 (Train/Val accuracy): 两条曲线之间的差距可以反映过拟合程度。差距大说明过拟合,应增强正则化或获取更多数据 。差距小说明模型容量可能不足,可以尝试增加模型复杂度 。
- 权重更新量/权重值比例: 监控每次更新的权重大小与权重本身大小的比率,这个比率应该在
1e-3左右 。
Lec07 Training Neural Networks Ⅱ
更多优化:
stochastic gradient descent,SGD:随机梯度下降

问题:1.之字形下降
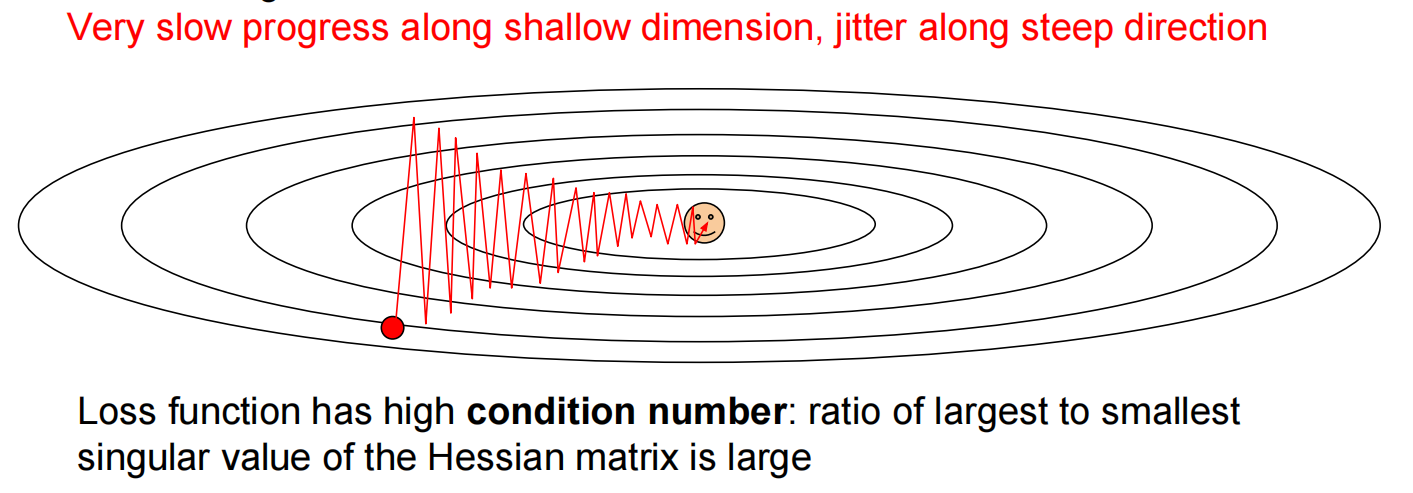
2.局部最优或下降较慢
改进:SGD+Momentum
加动量

同时改变速度:

基于历史梯度来影响当前的速度,这样可以减小之字形,因为它会让敏感的那一维度除以一个很大的数:

但这样会导致步长越来越短,改进:

得到完整的Adam算法:

拓展到二维、多维:牛顿法

太大了->拟牛顿法,少一维

用一个平均值,而非最新的->平滑

正则化:
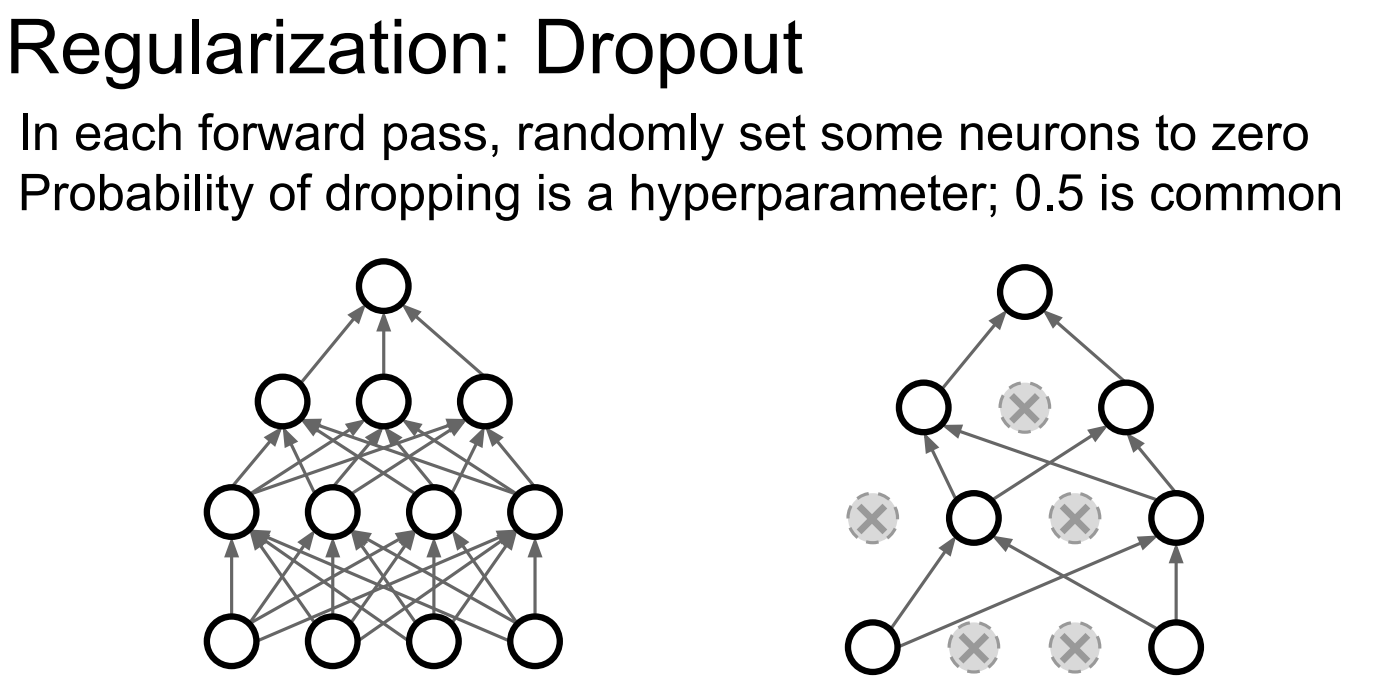

其他手段:

或者,将图像翻转,裁剪,色彩抖动等等来训练
另一种:dropconnect,不是取消神经元,而是把权重矩阵的某些地方置零
又或者,,随机化池化一部分,不全部池化:
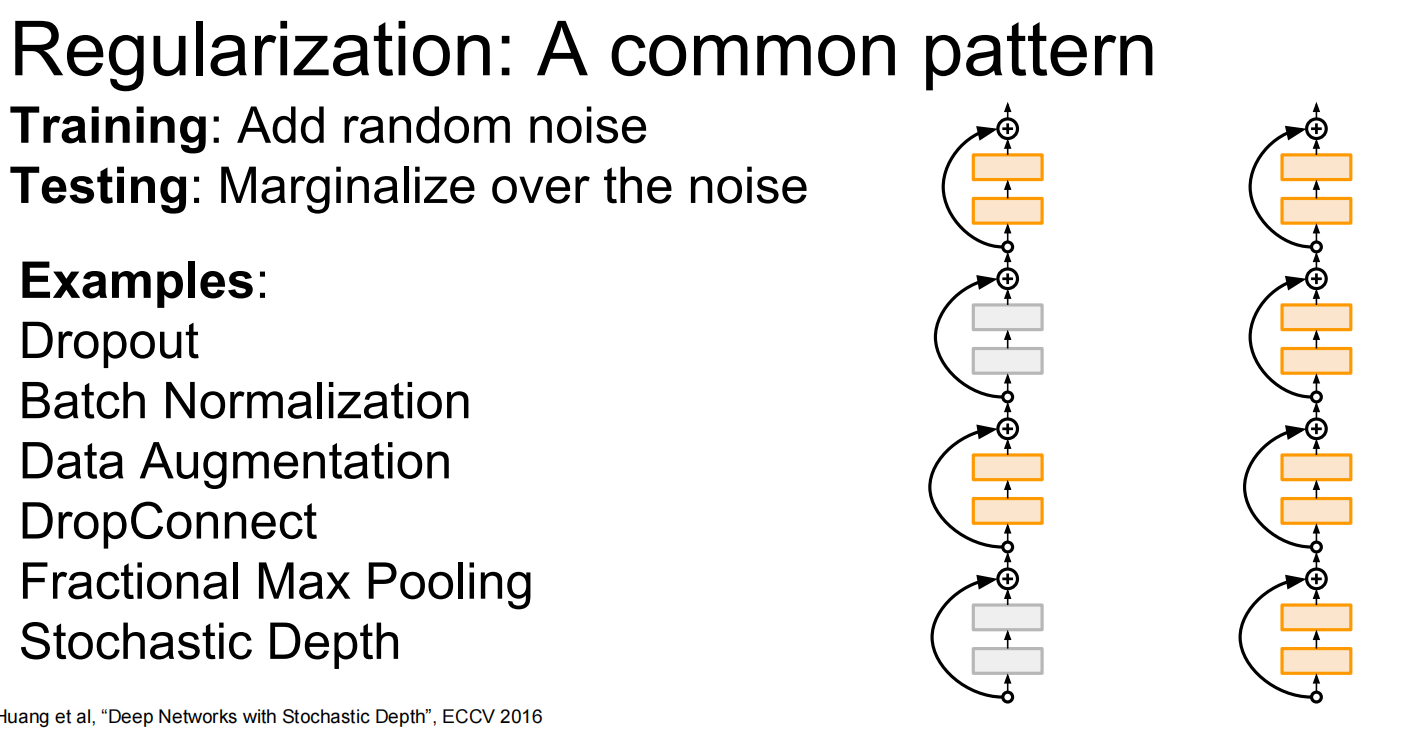
抑或,取消一些层
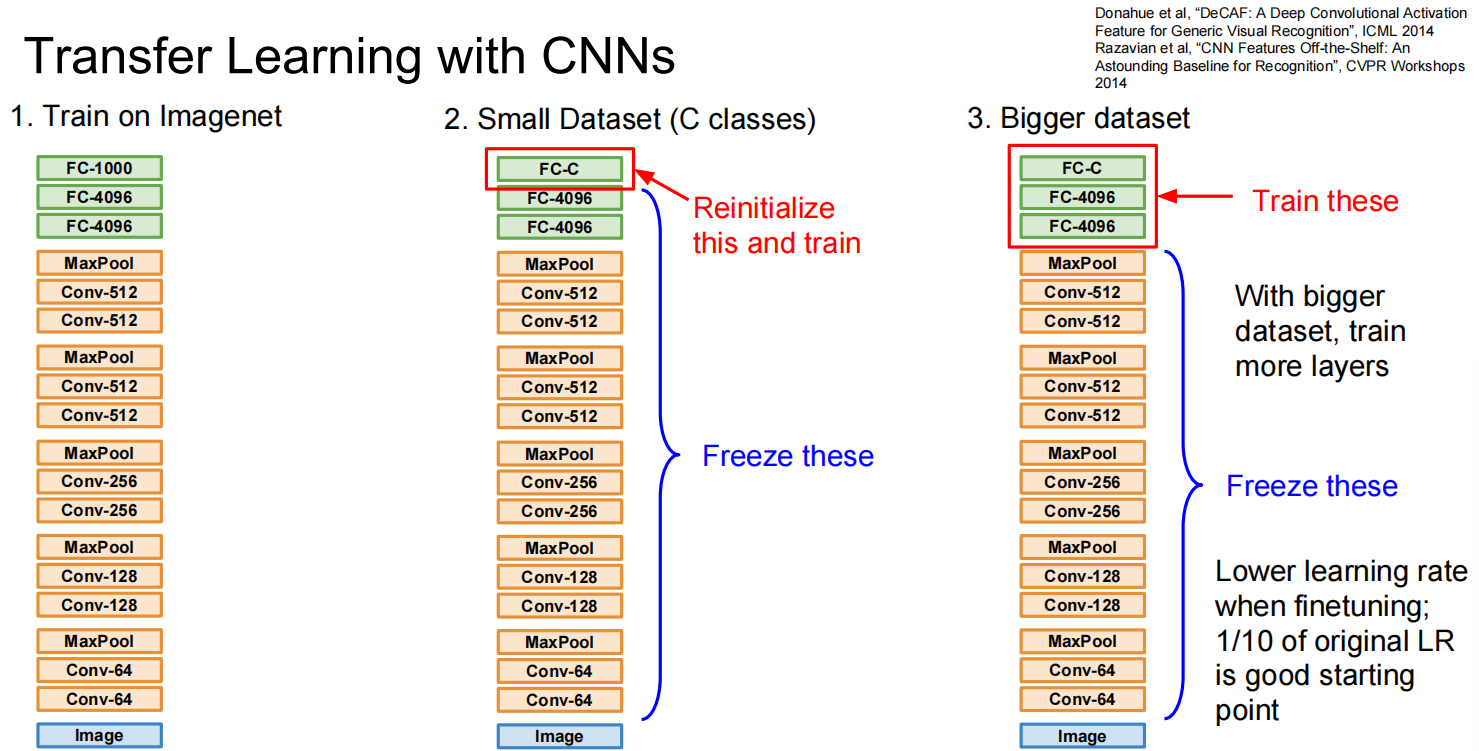
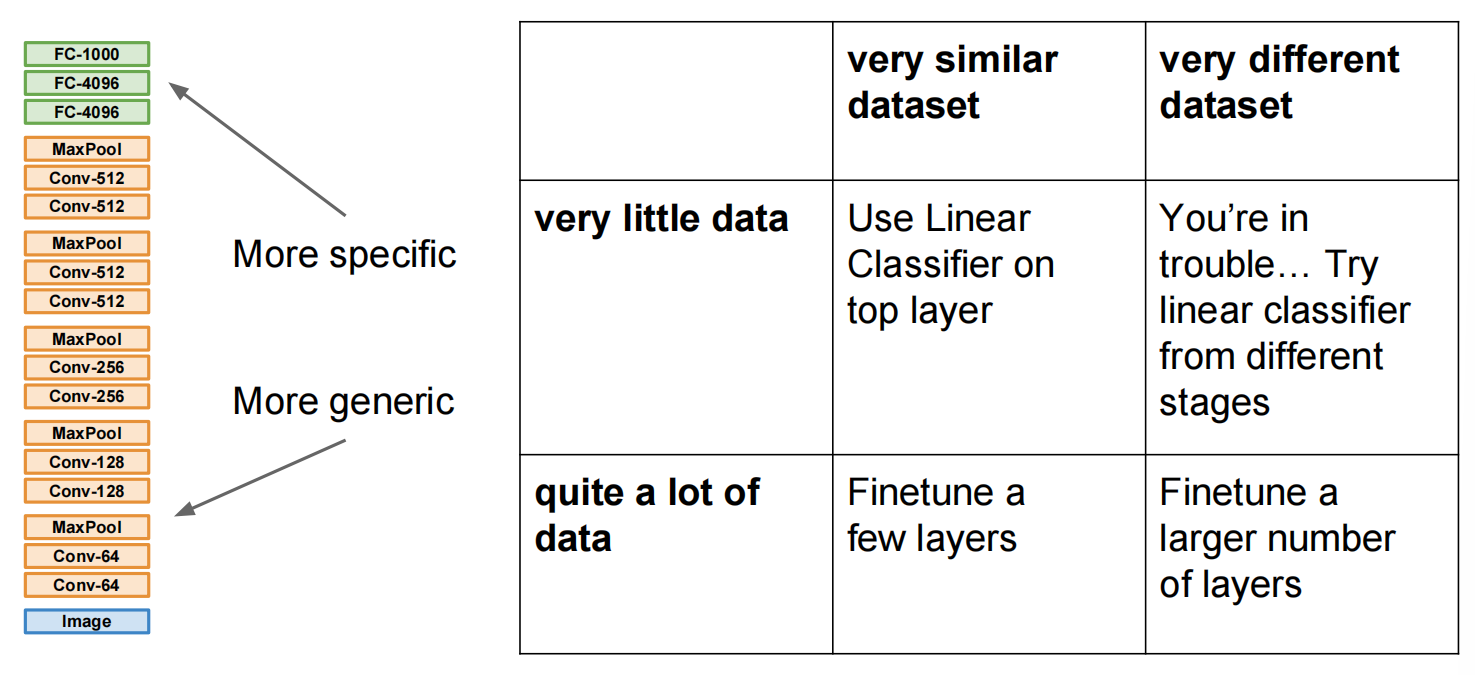
迁移学习:
Transfer Learning
Lec08 Deep Learning Software




各有优劣
第三个:caffe,caffe2

Lec09 CNN Architectures
Today: CNN Architectures
Case Studies
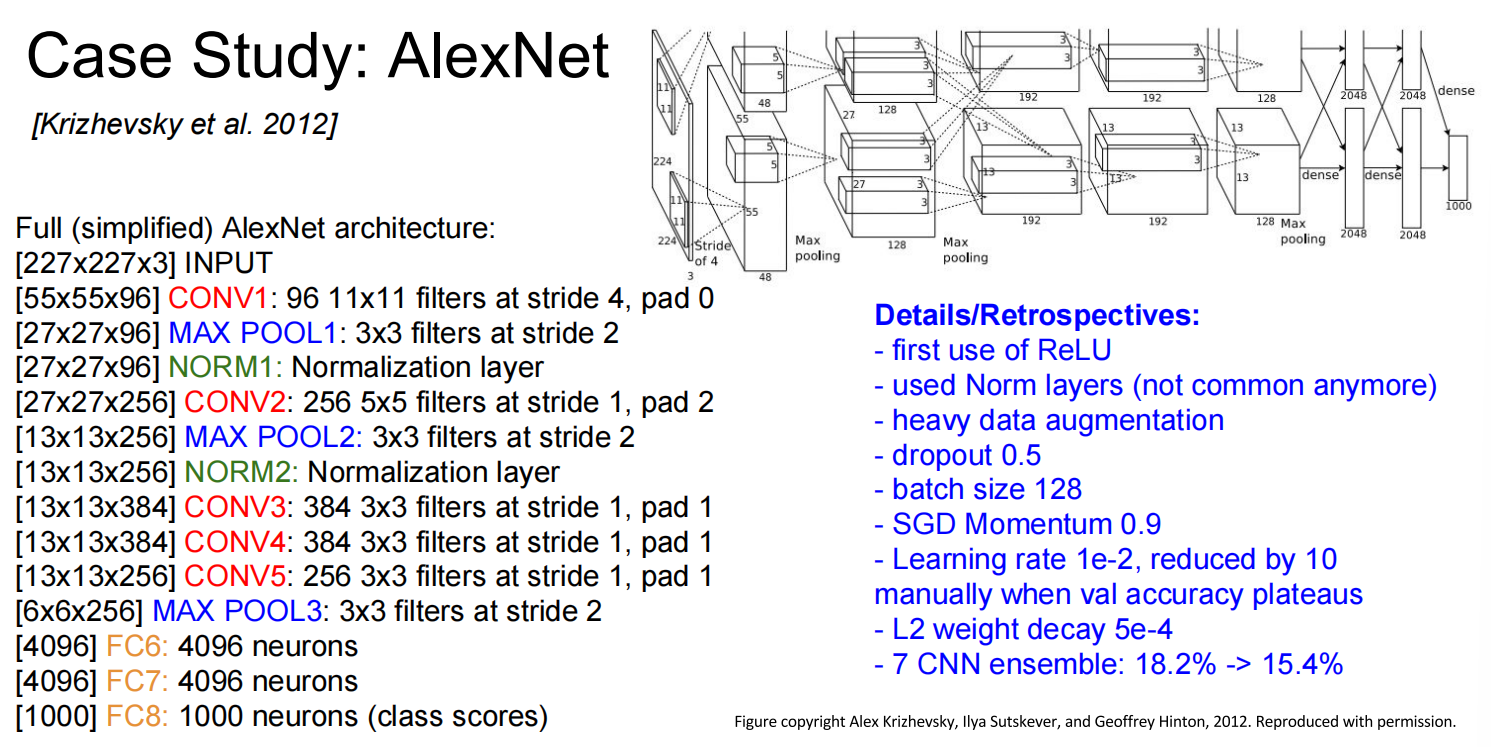
AlexNet
VGG
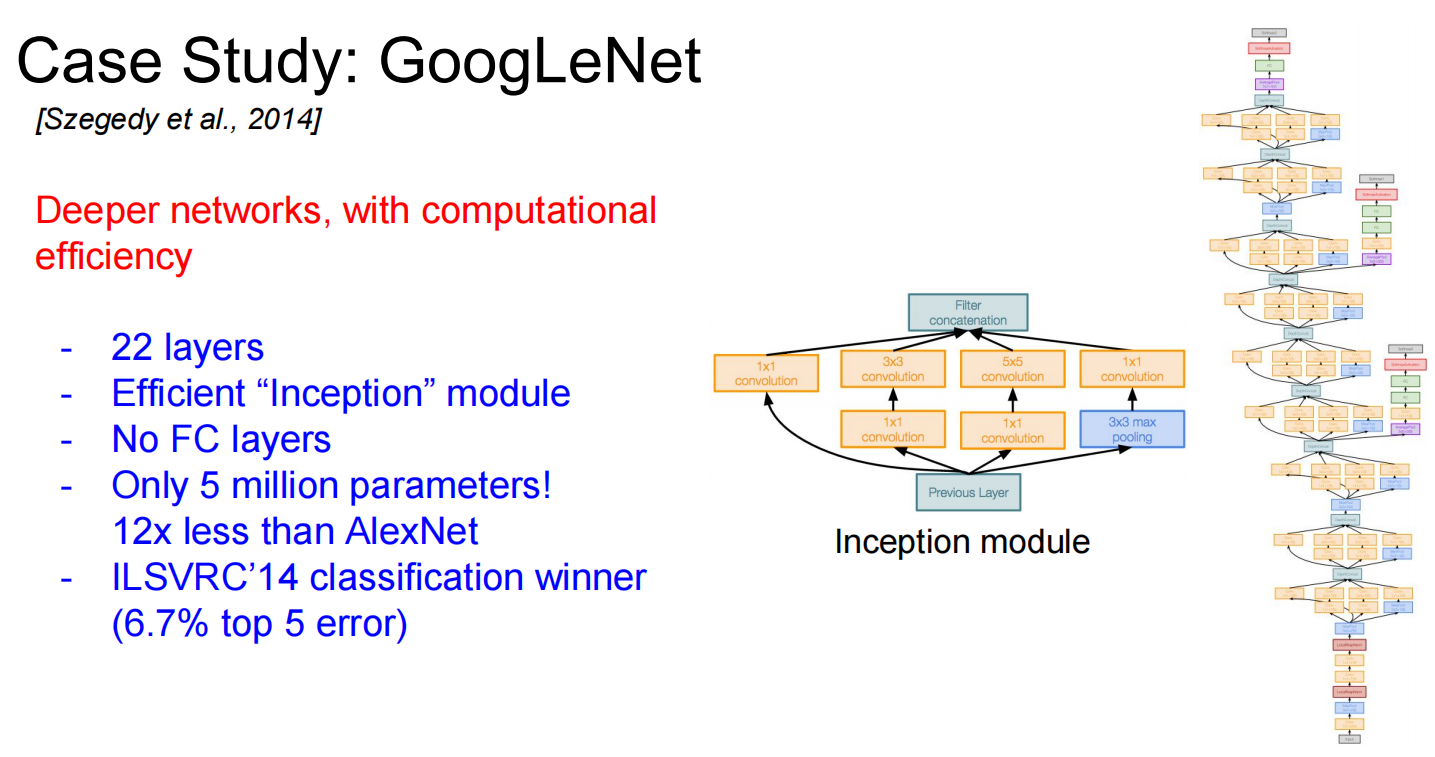
GoogLeNet
ResNet
Also….
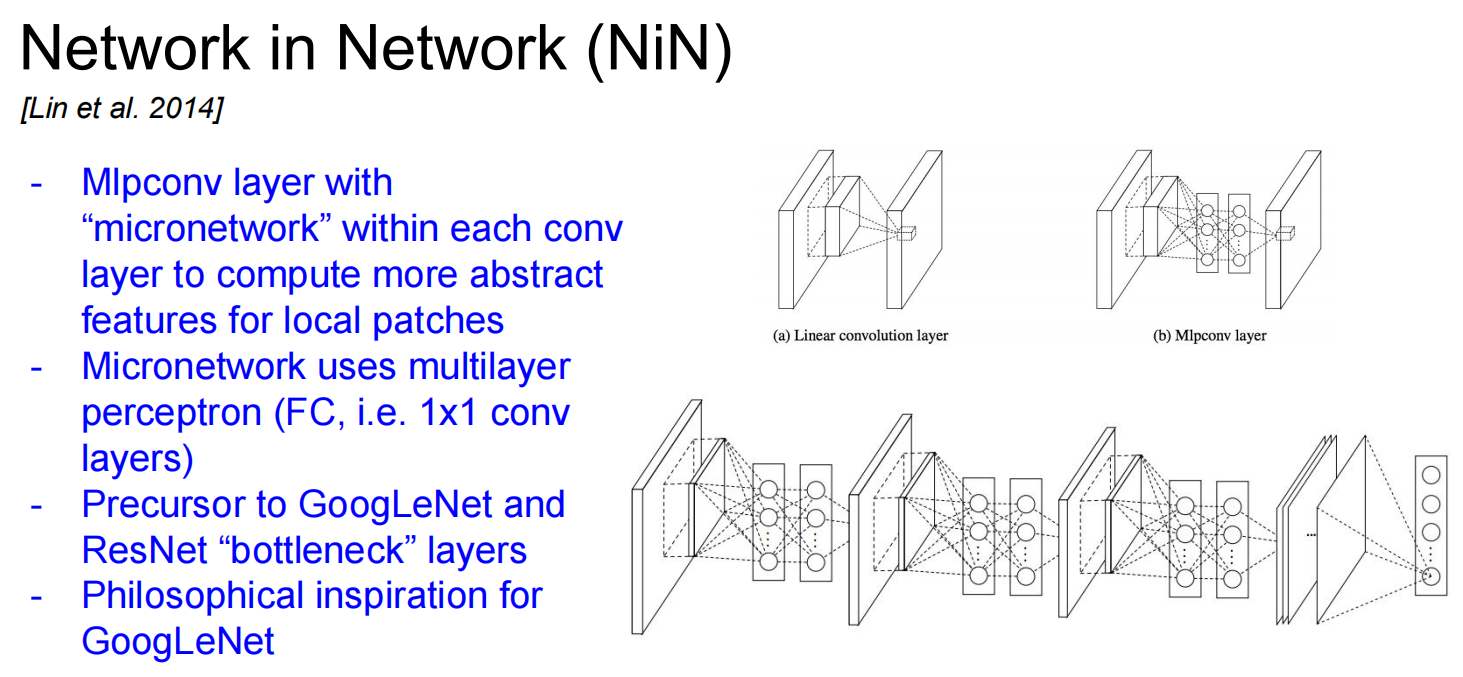
NiN (Network in Network)
Wide ResNet
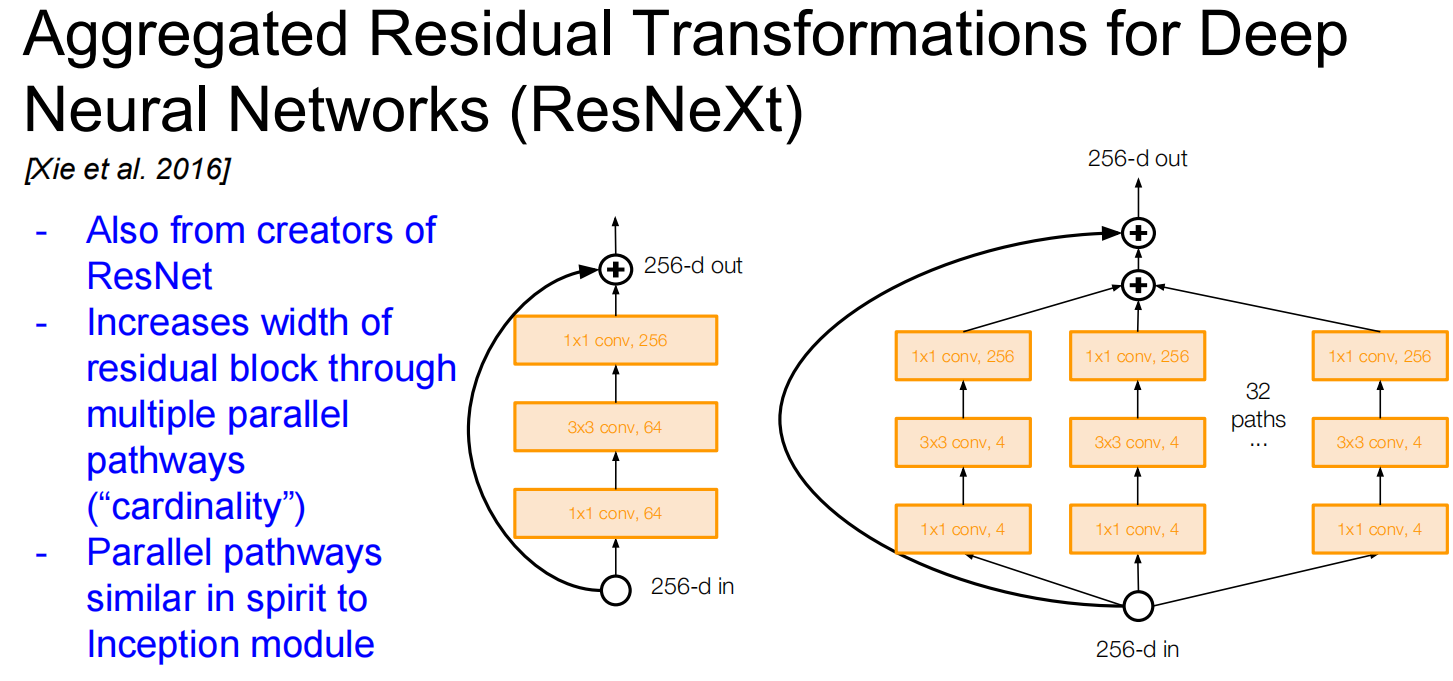
ResNeXT
Stochastic Depth
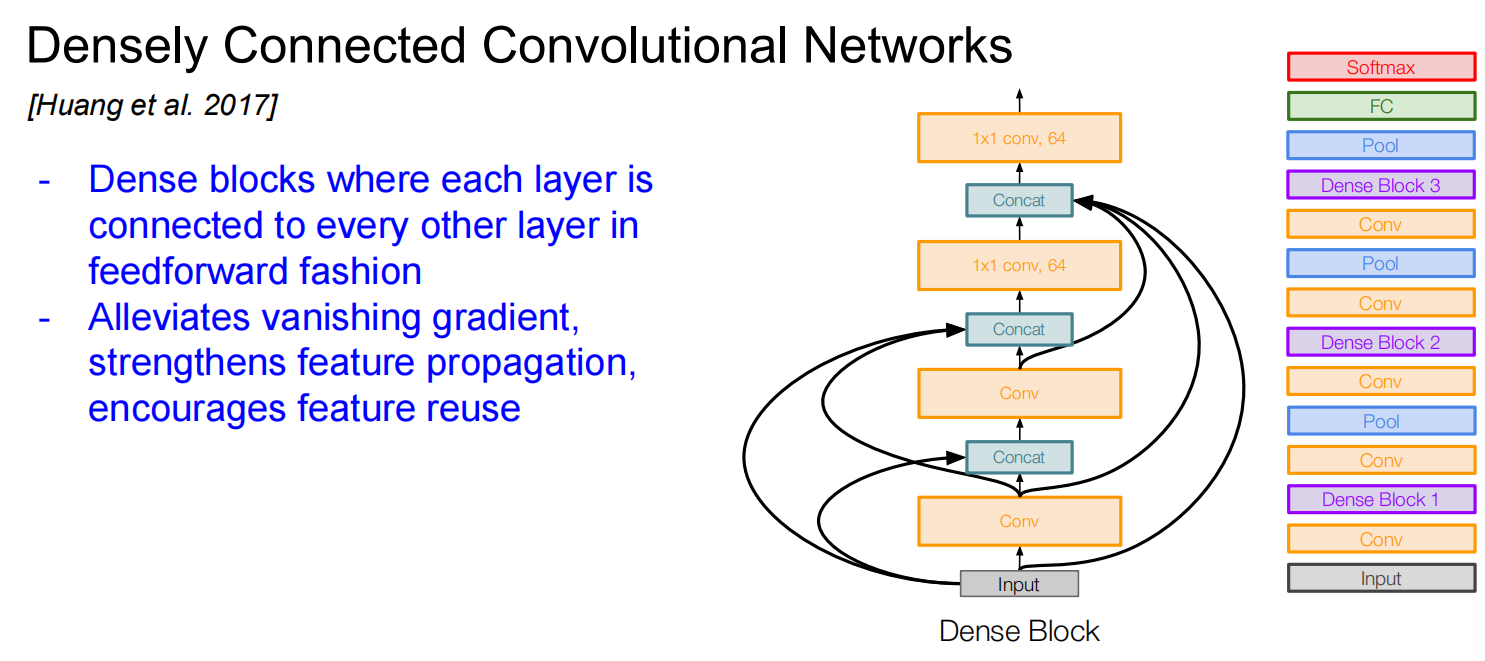
DenseNet
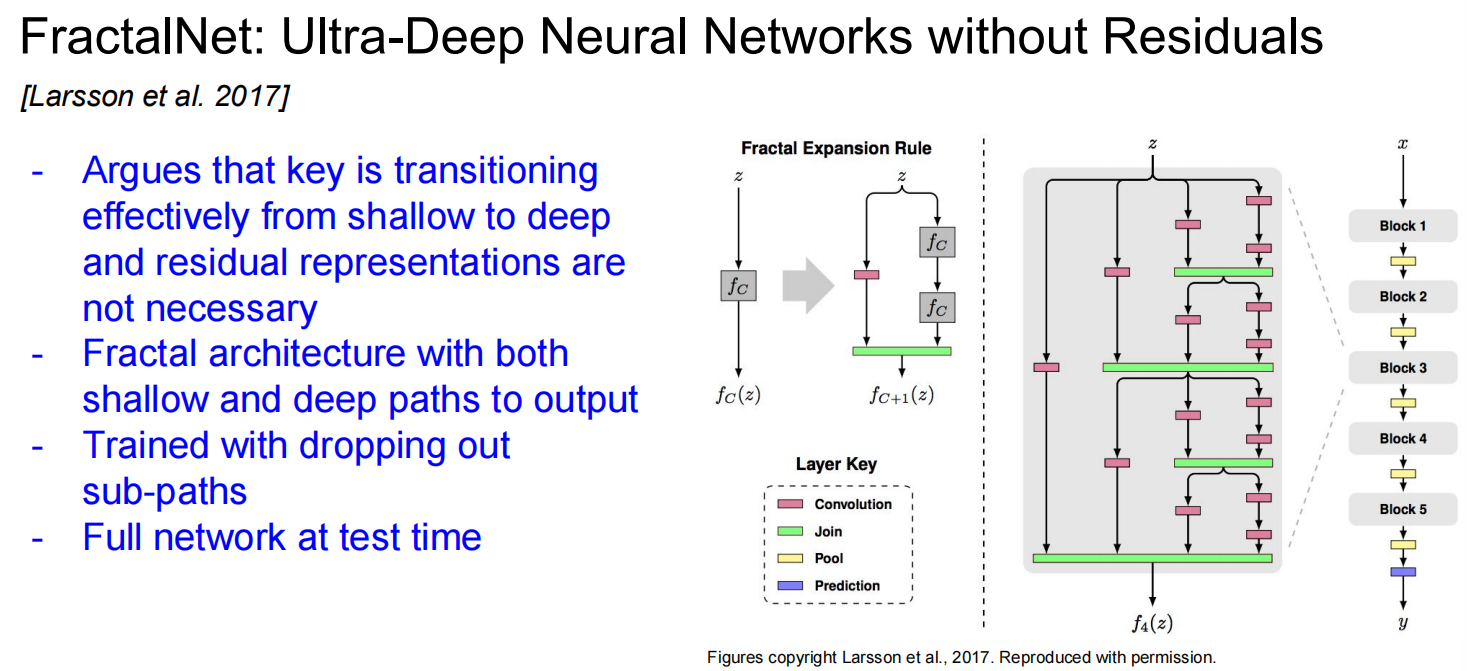
FractalNet
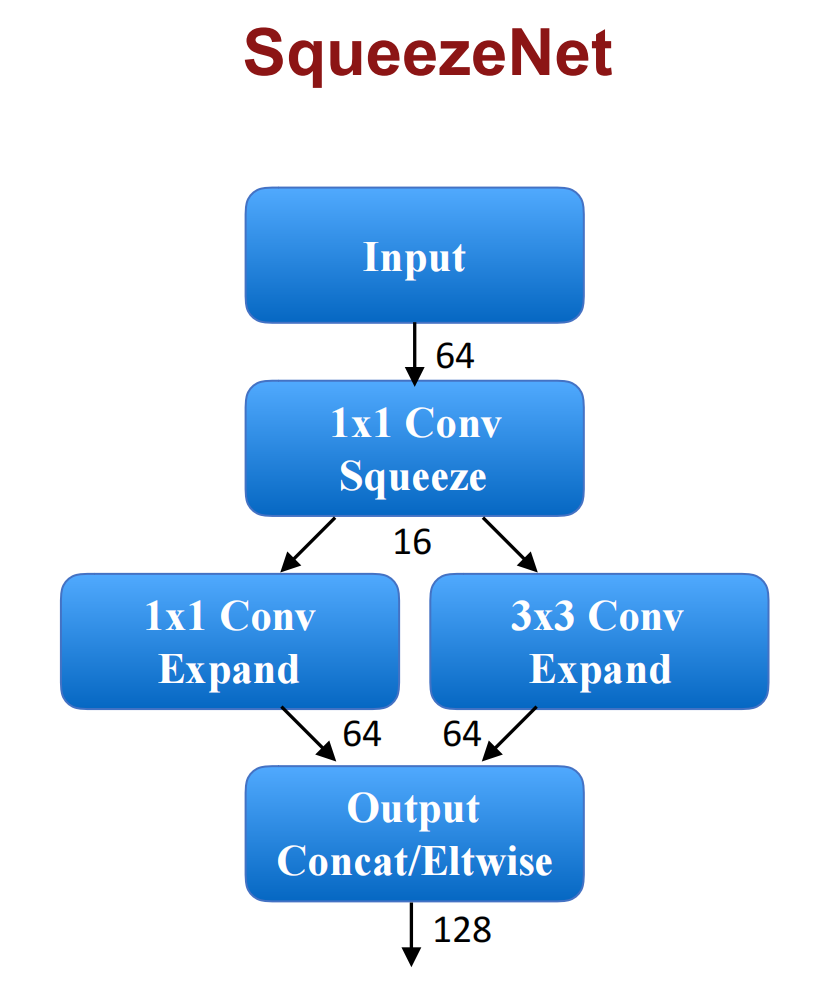
SqueezeNet

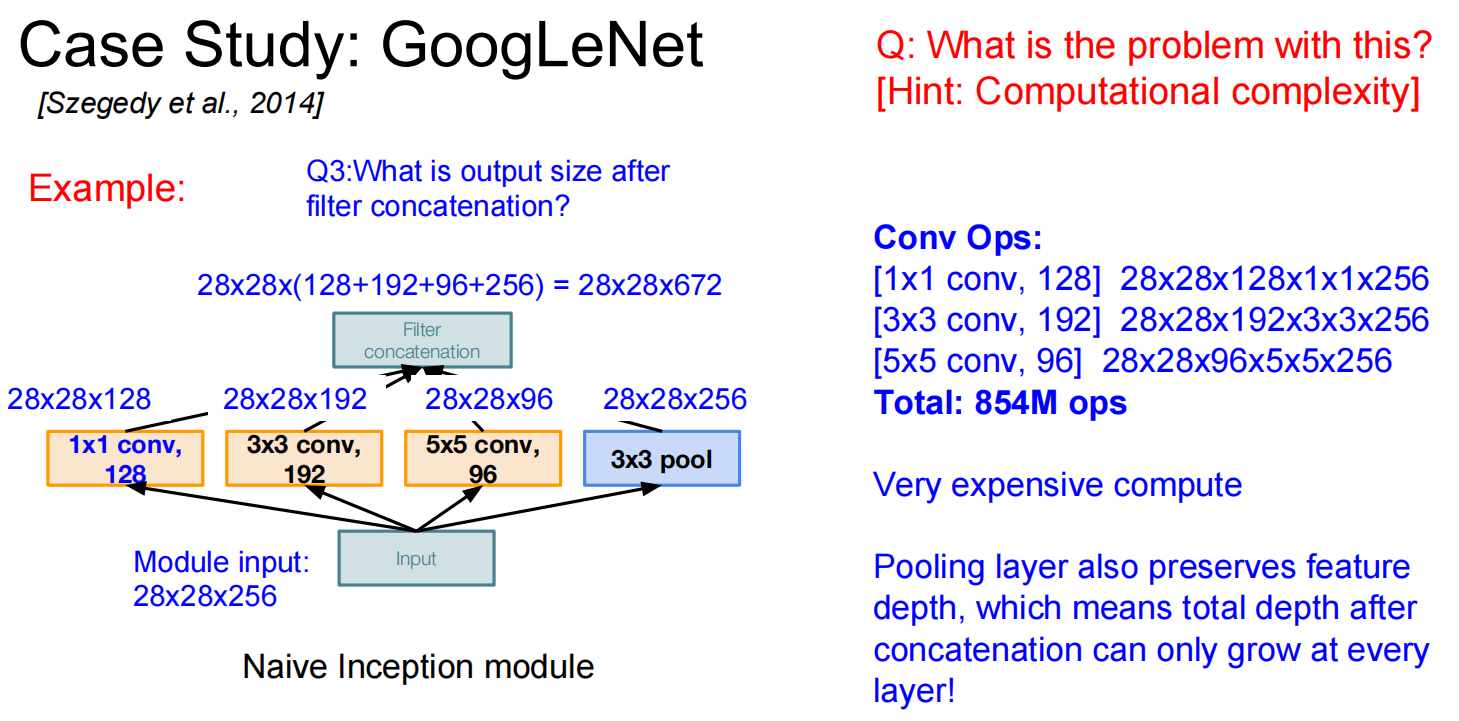
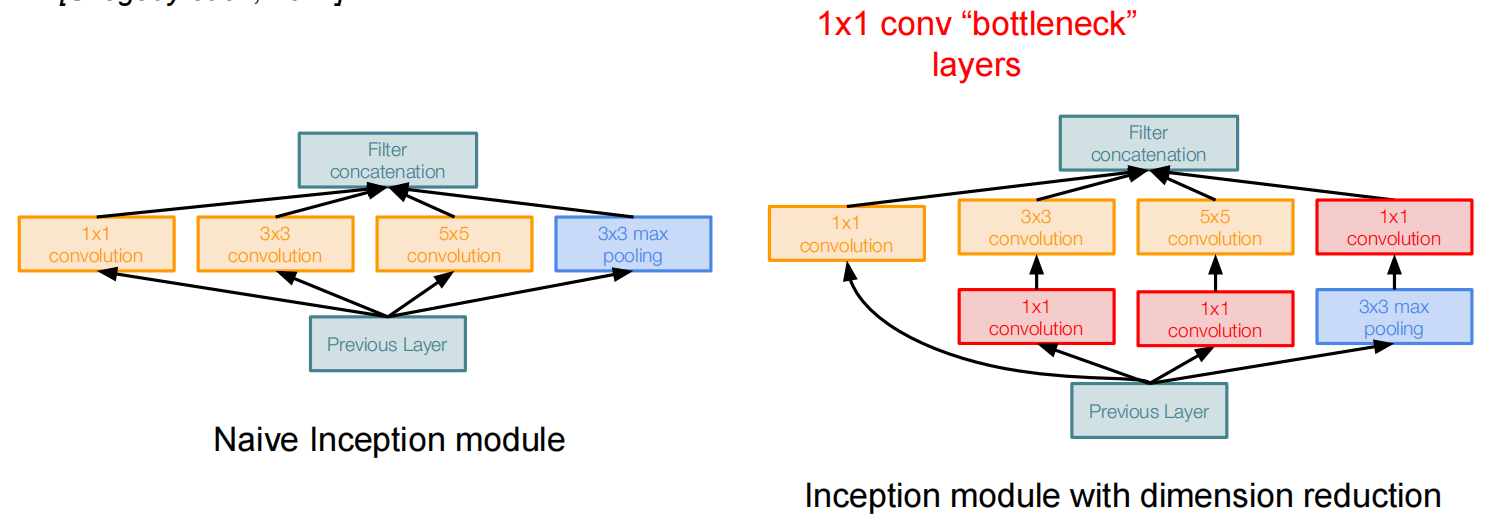
计算量太大了怎么办?添加一个瓶颈层,压缩深度:
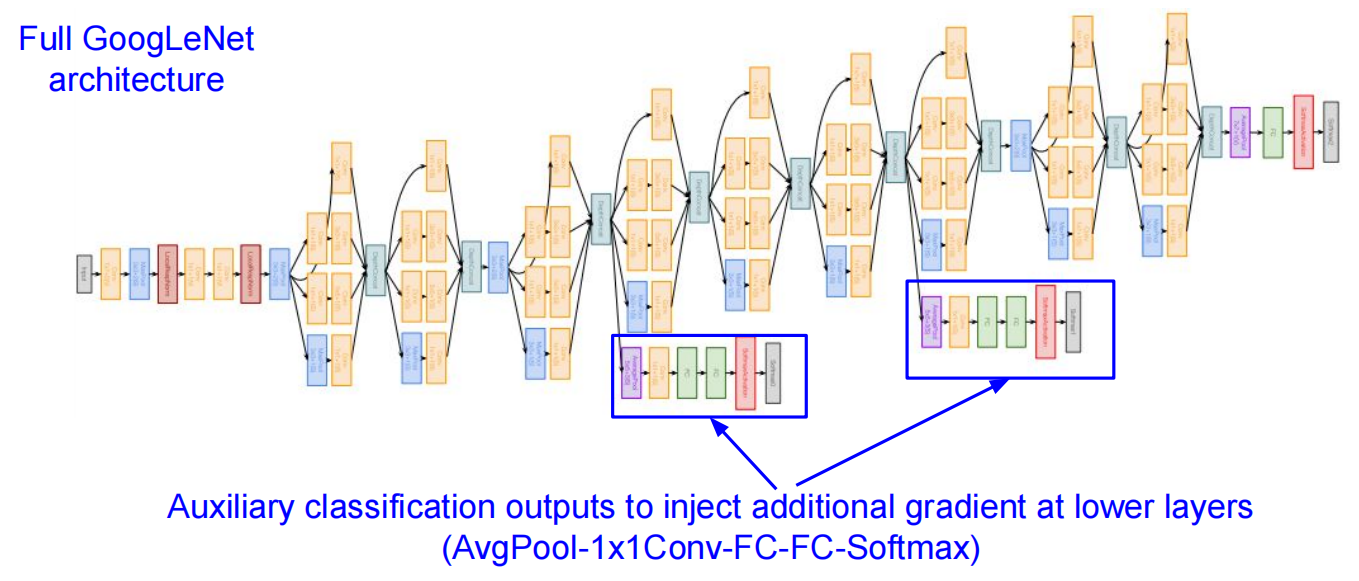
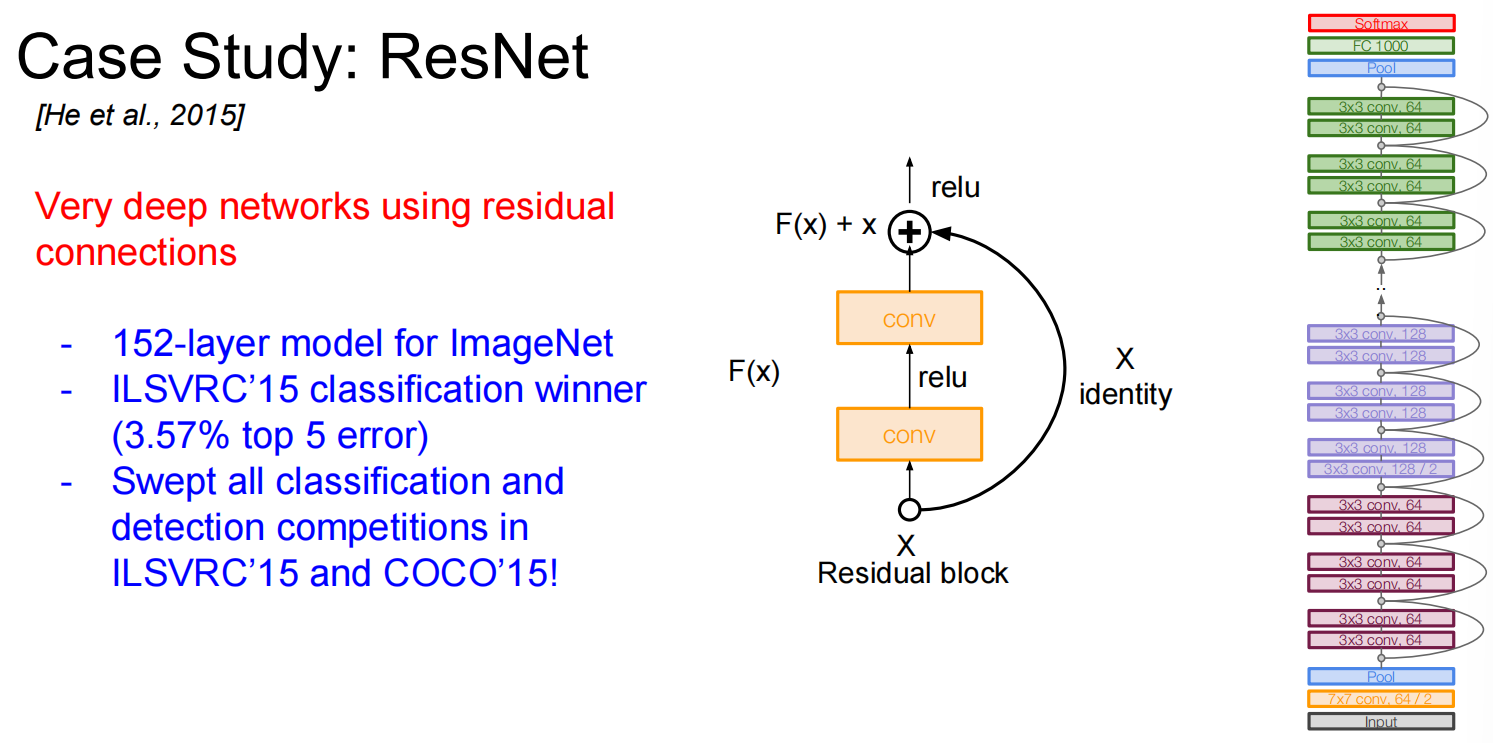
一些其他的:
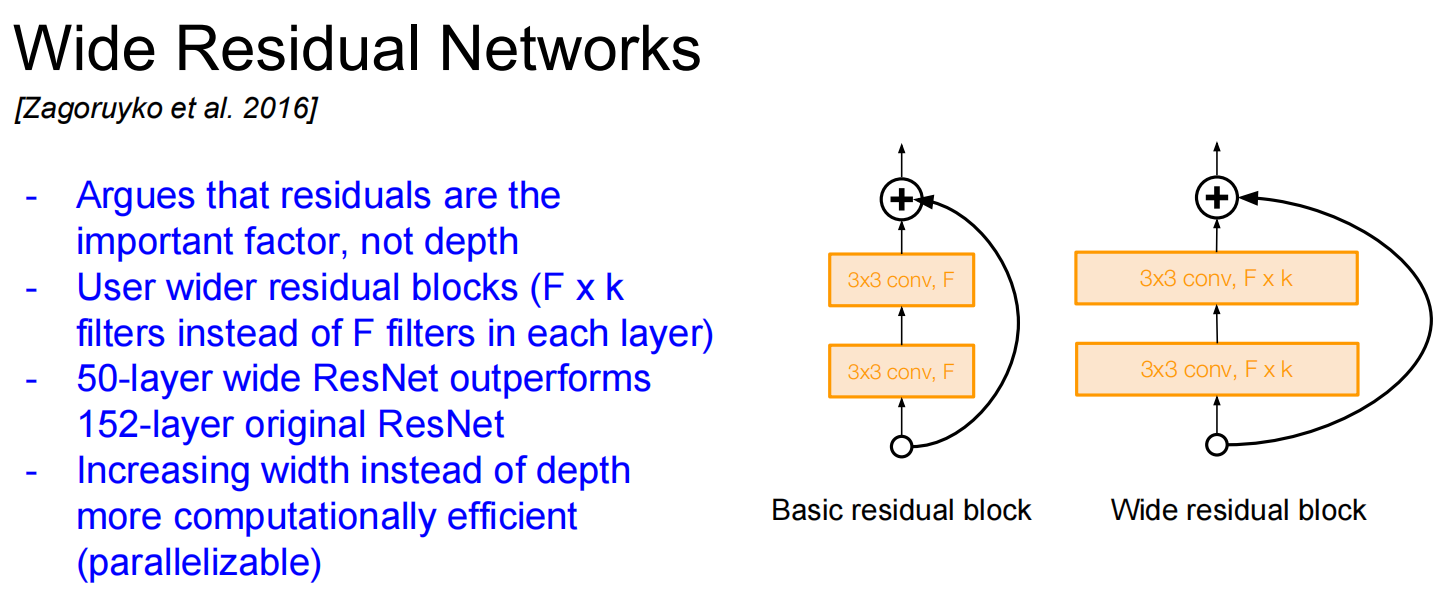


Lec10 Recurrent Neural Networks
循环神经网络
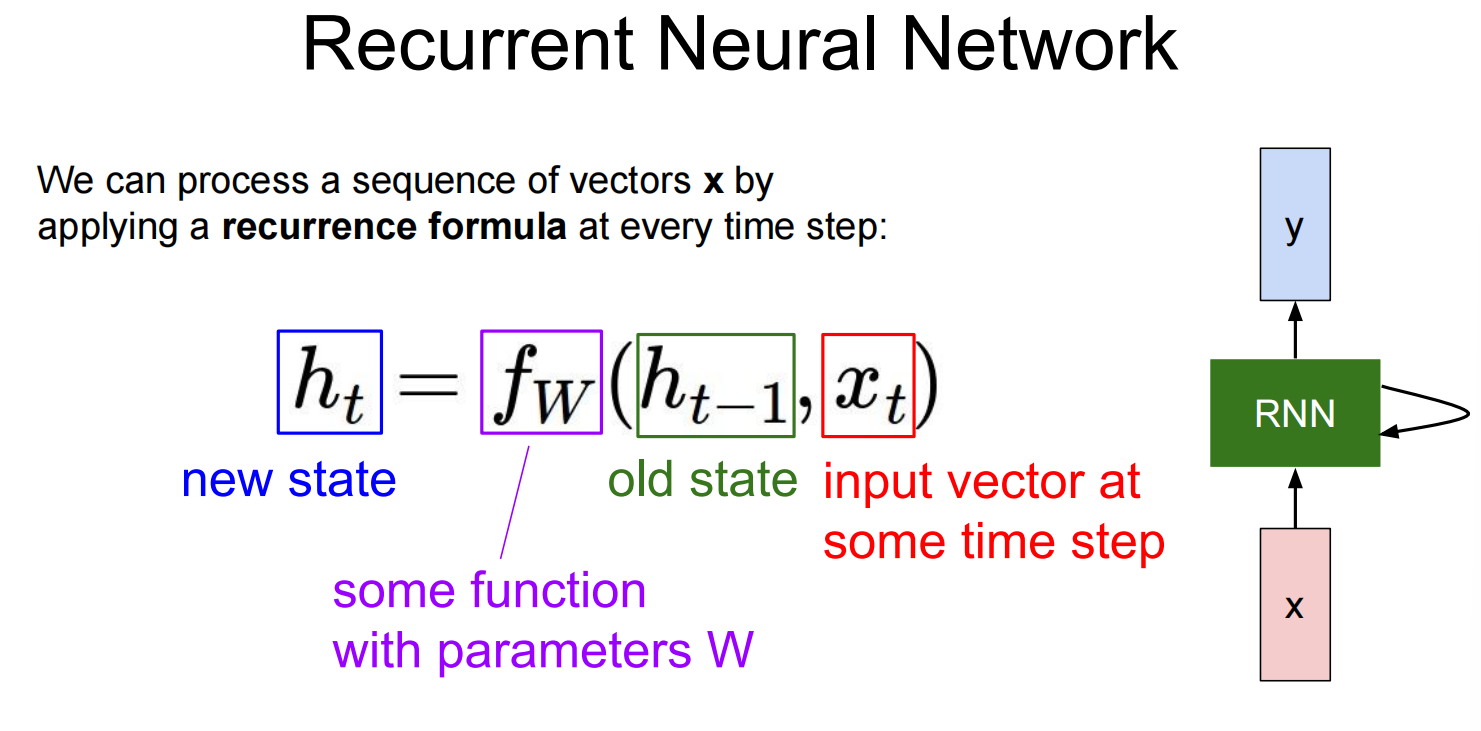

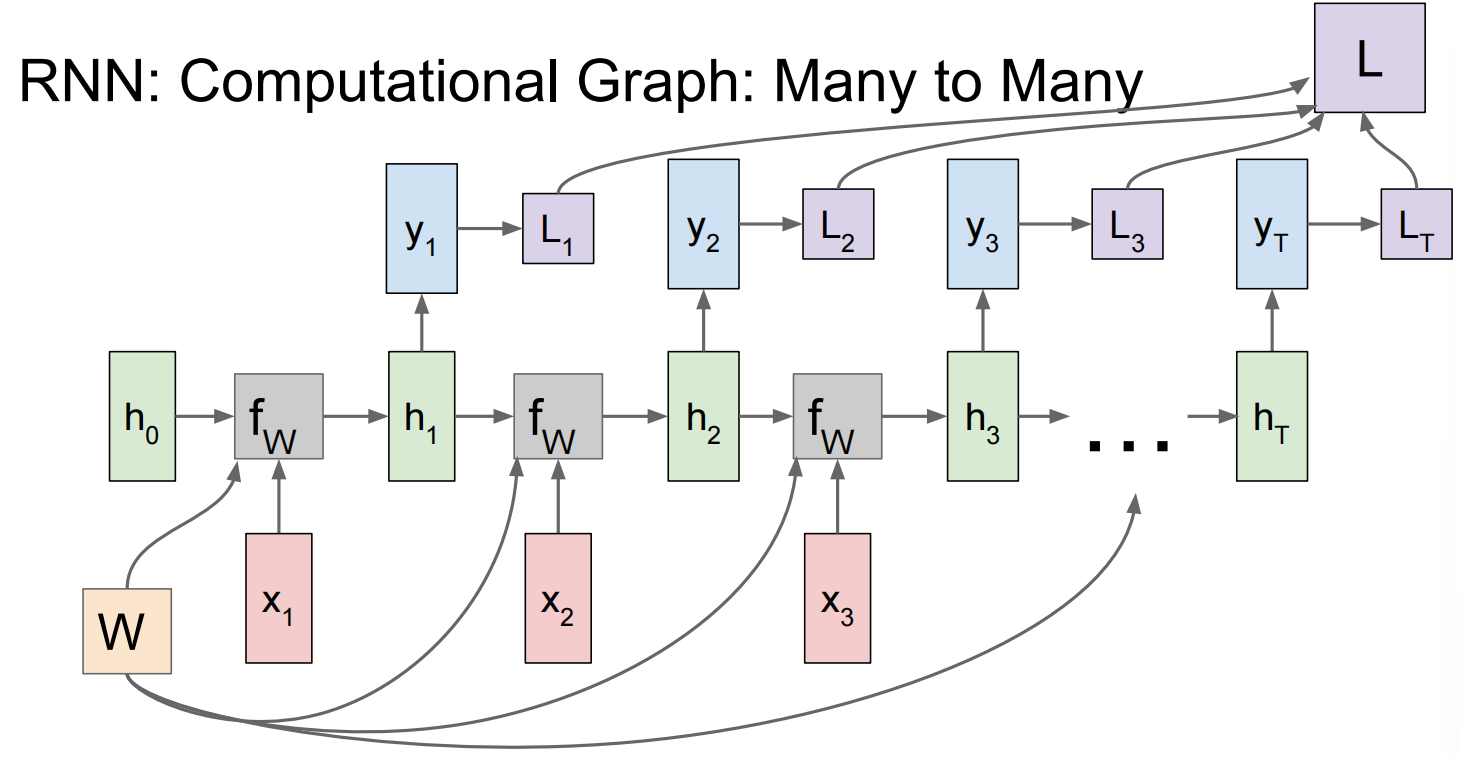
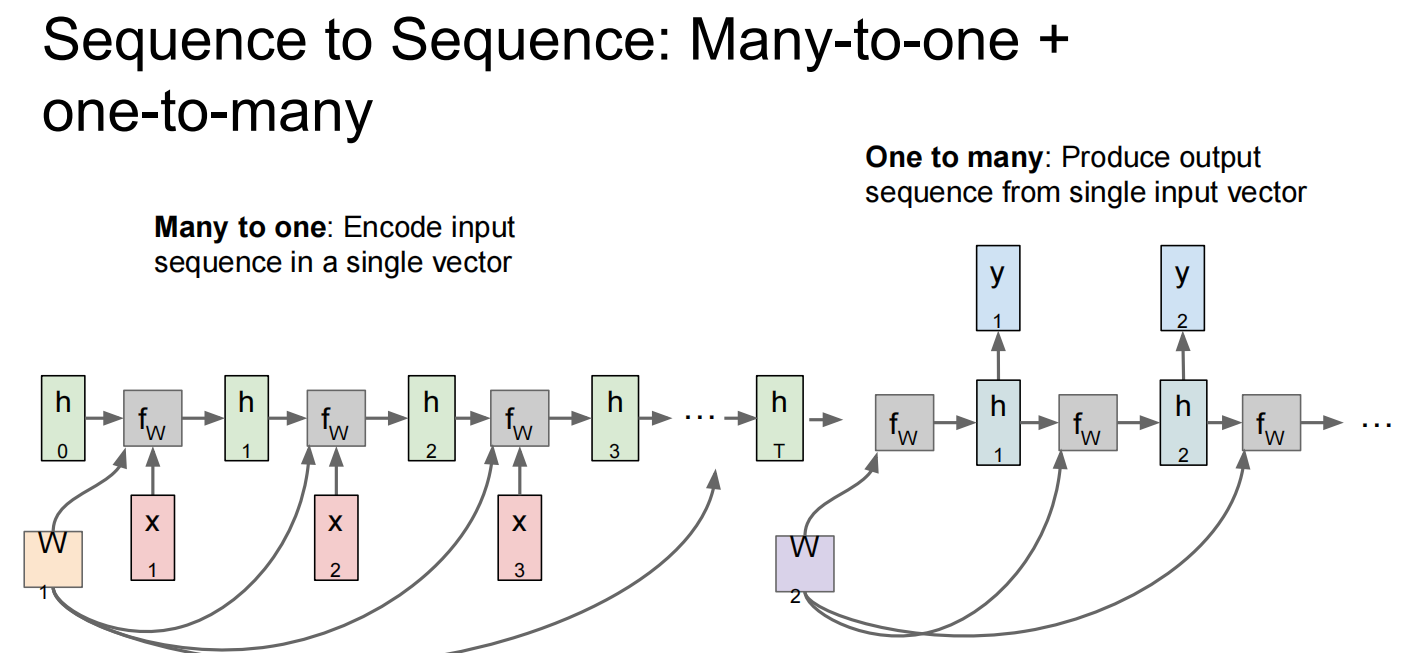
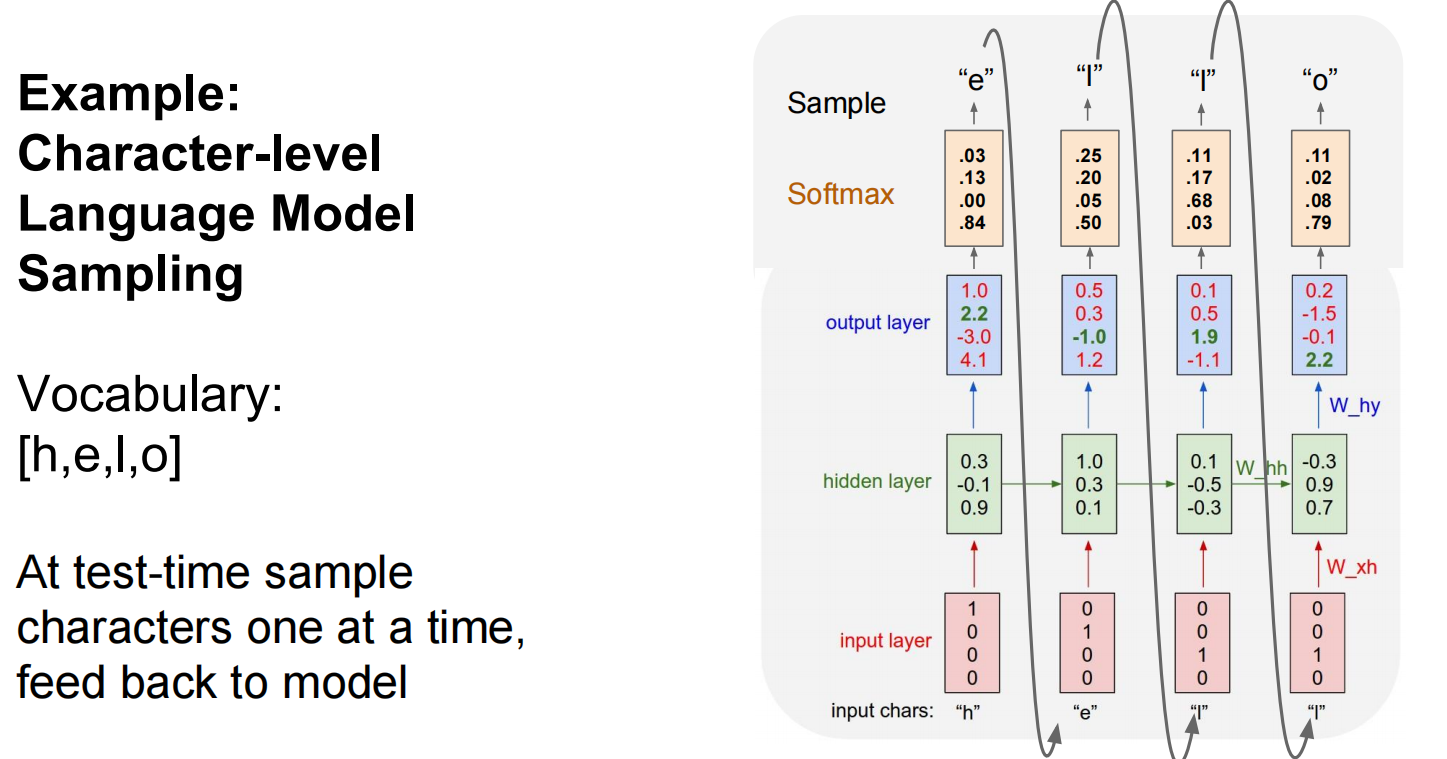
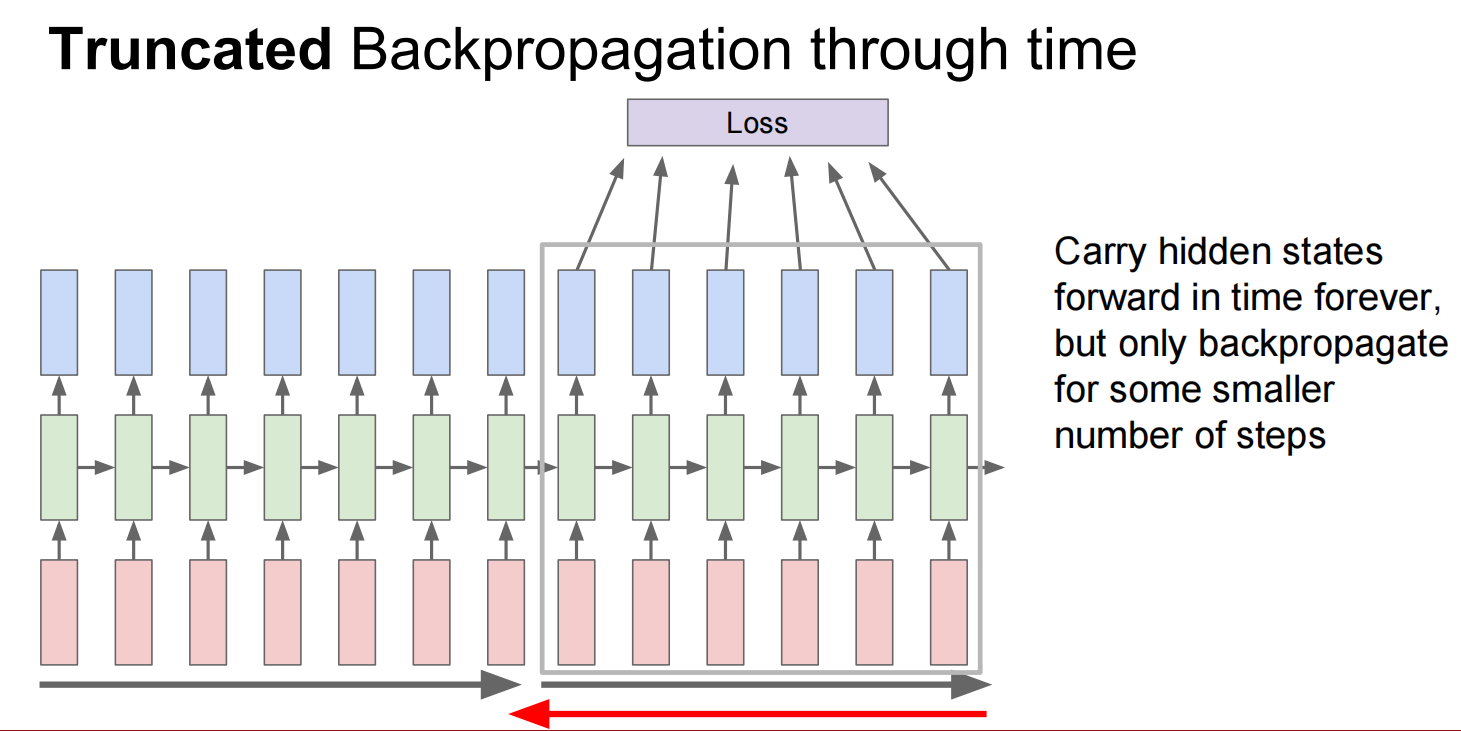
反向传播:
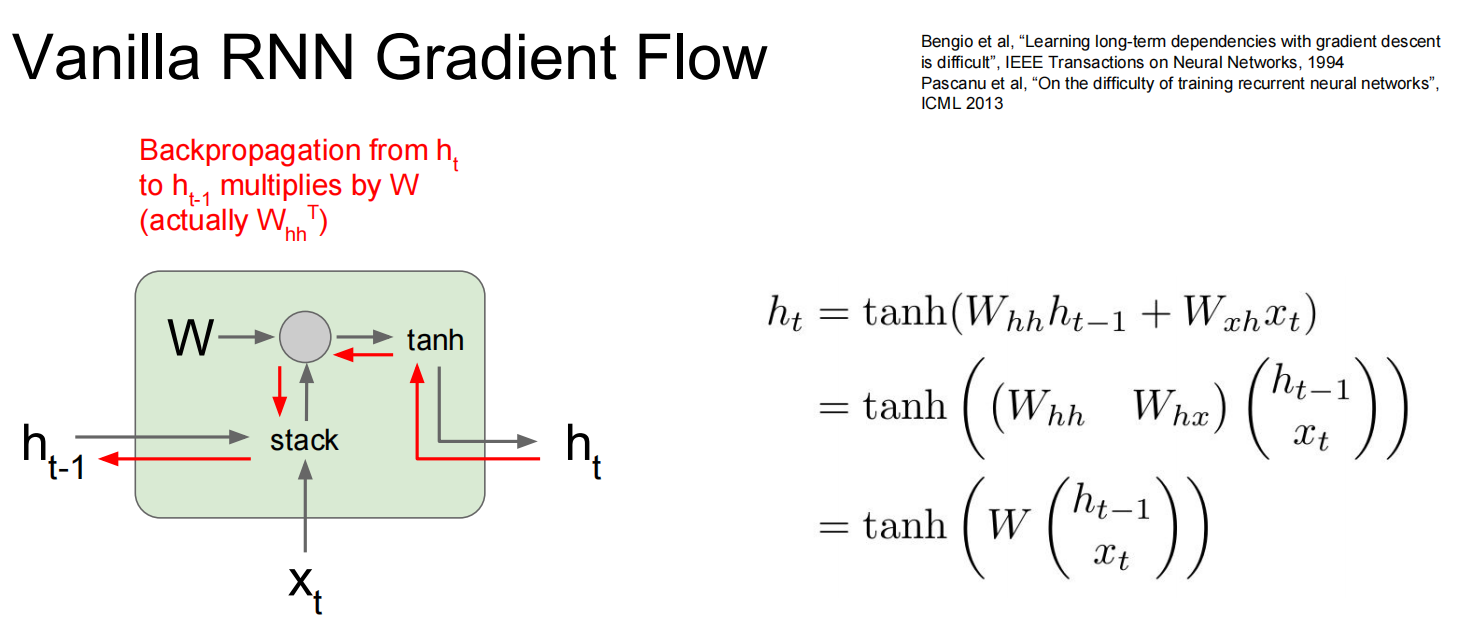
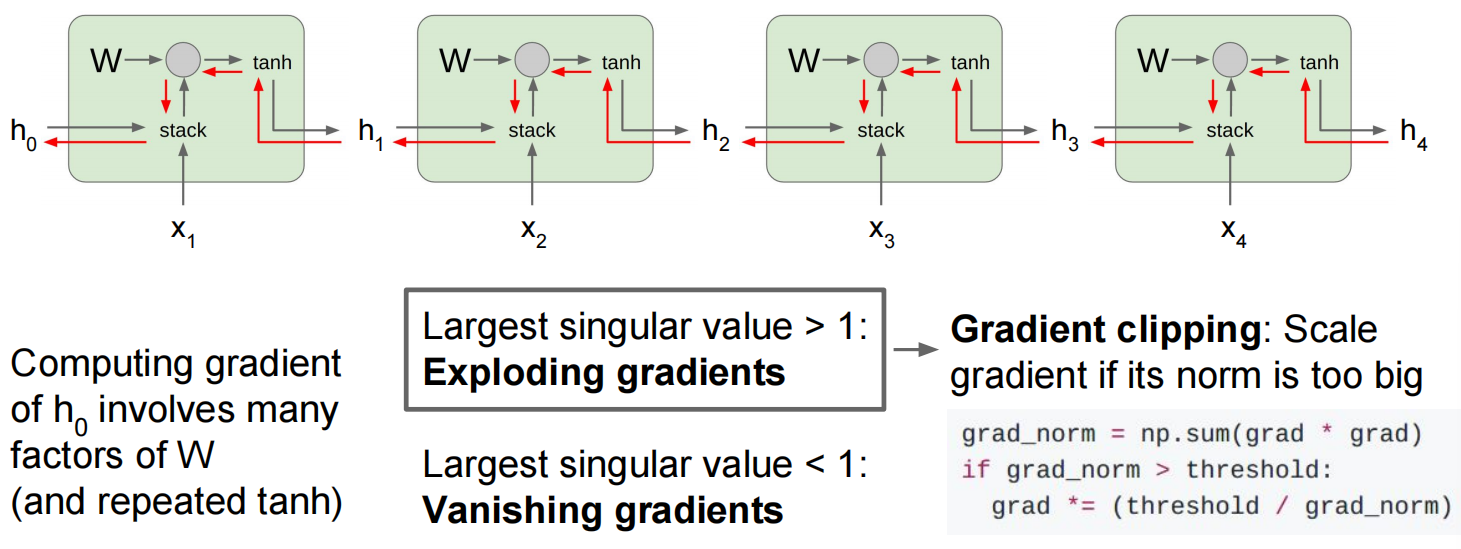
当层数较多时,会乘很多次同一个数——修改

改进为LSTM:
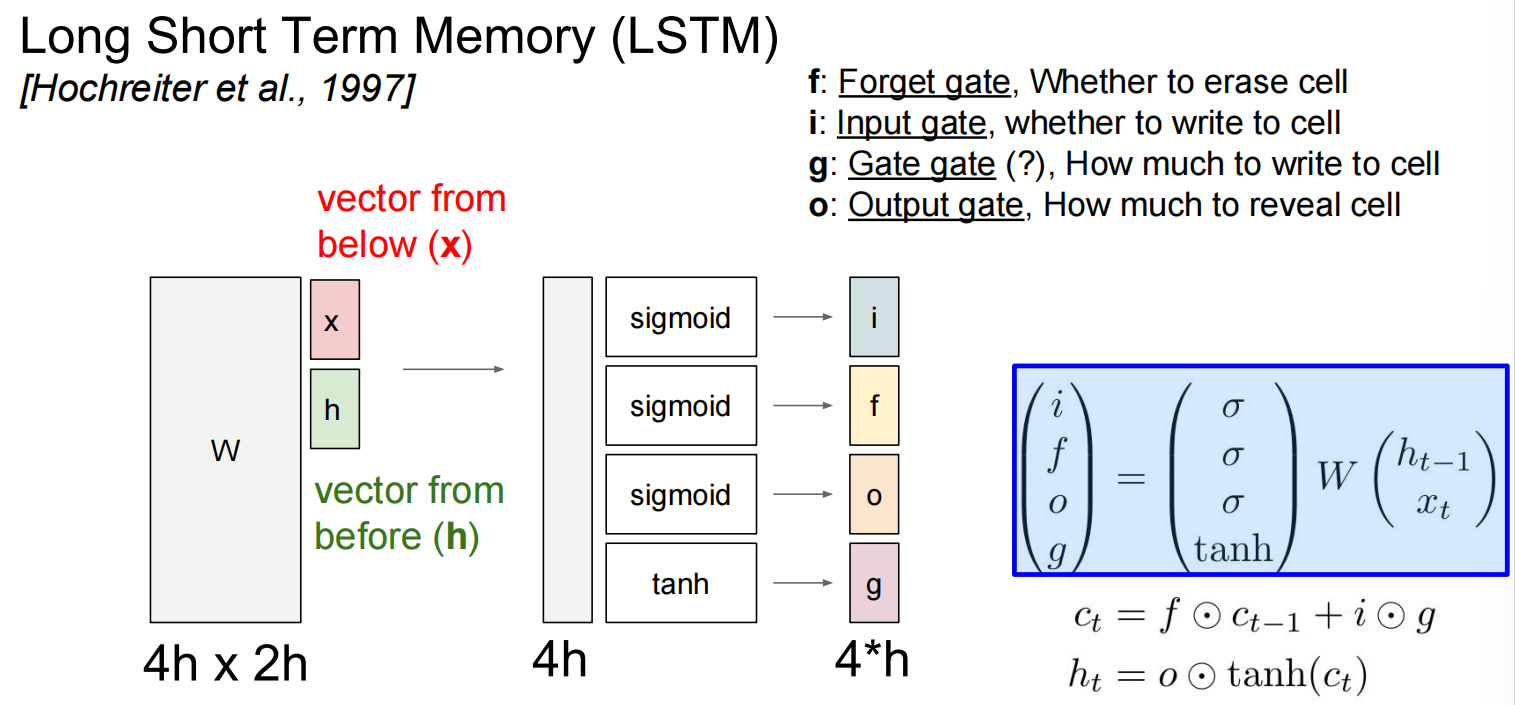
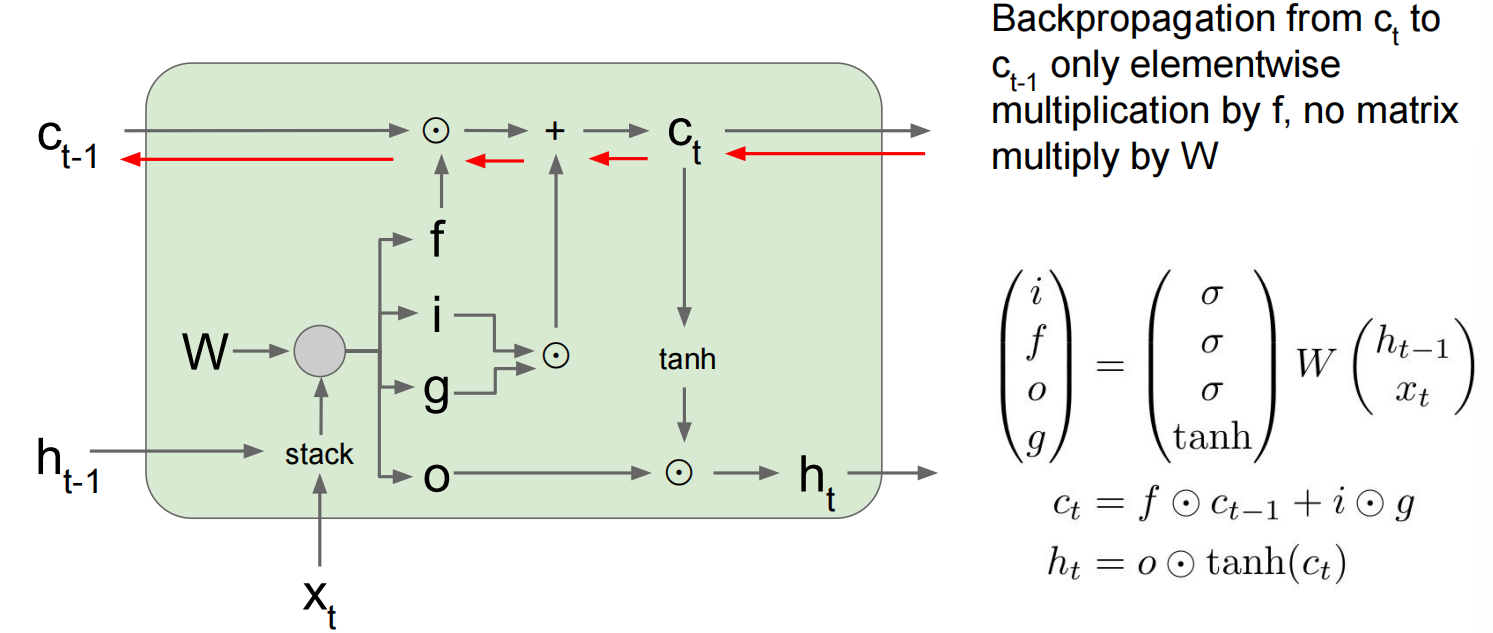
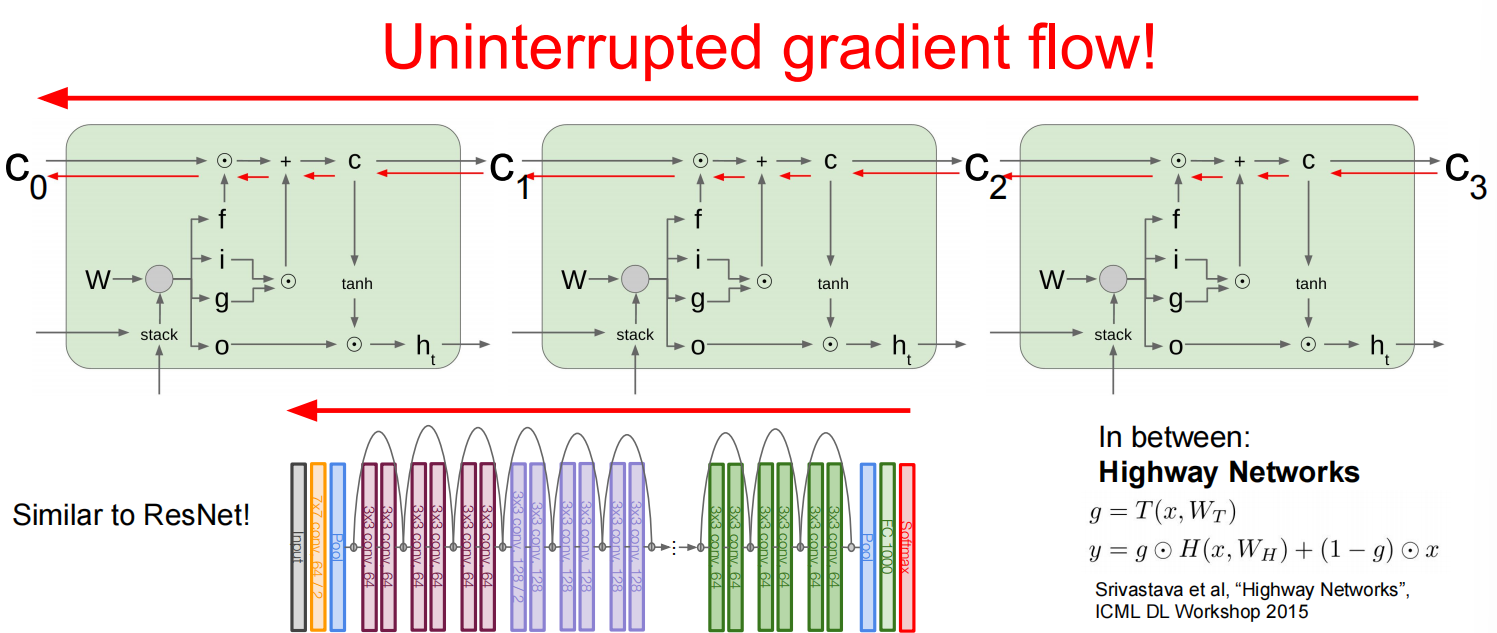
一些其他的循环神经网络:

Lec11 Detection and Segmentation
CV除了分类可以做的其他事:语义分割,定位,对象识别,物体切割…
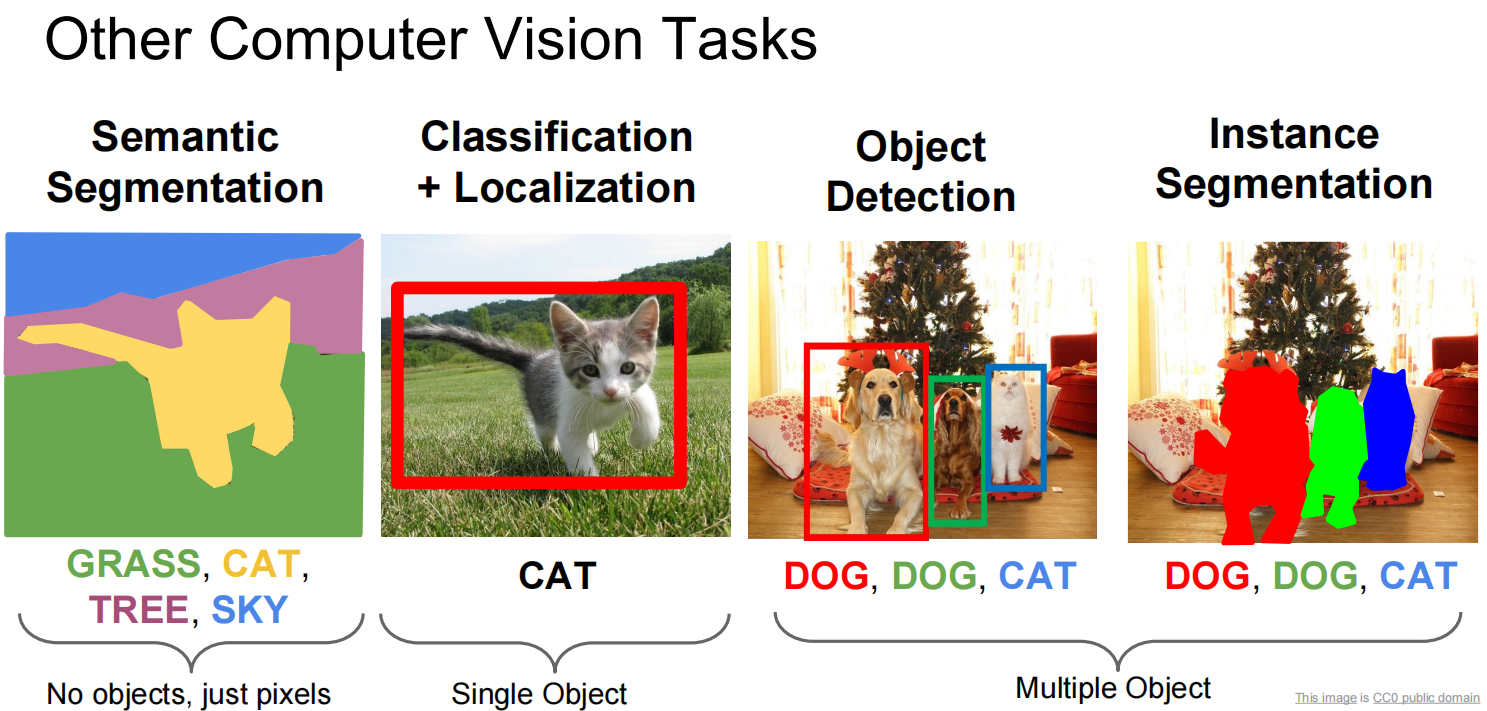
第一个,语义分割:
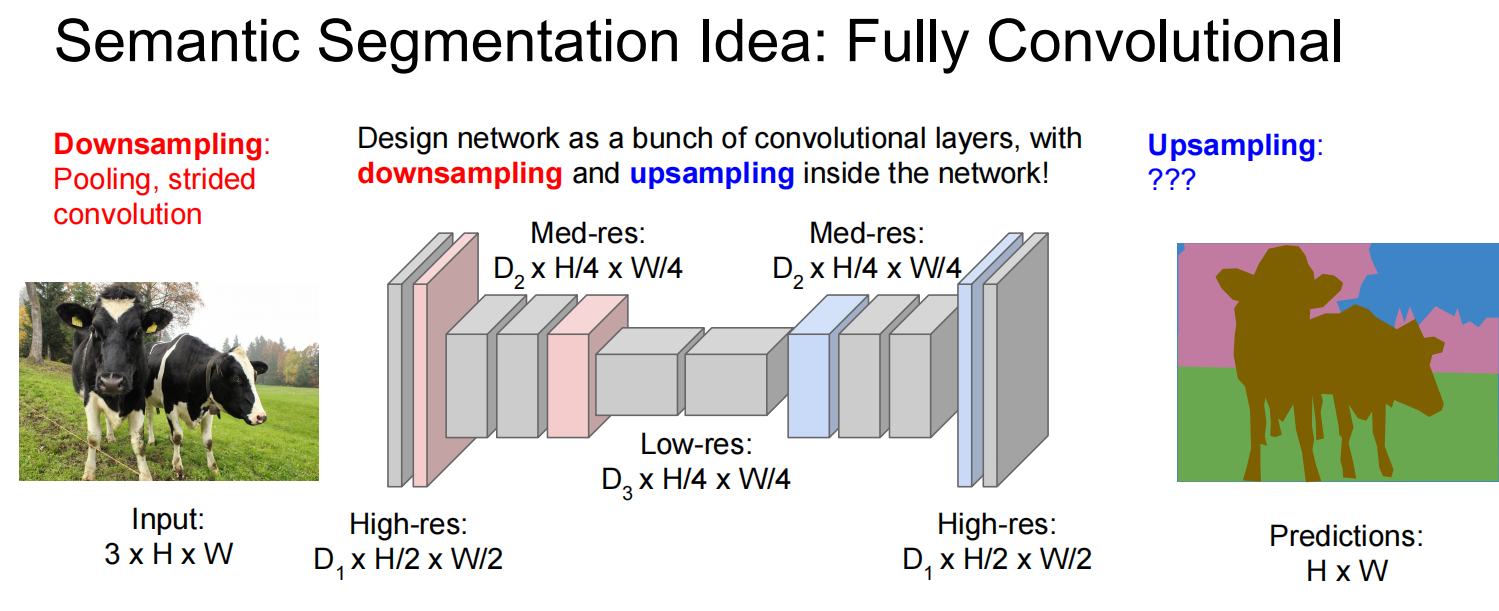
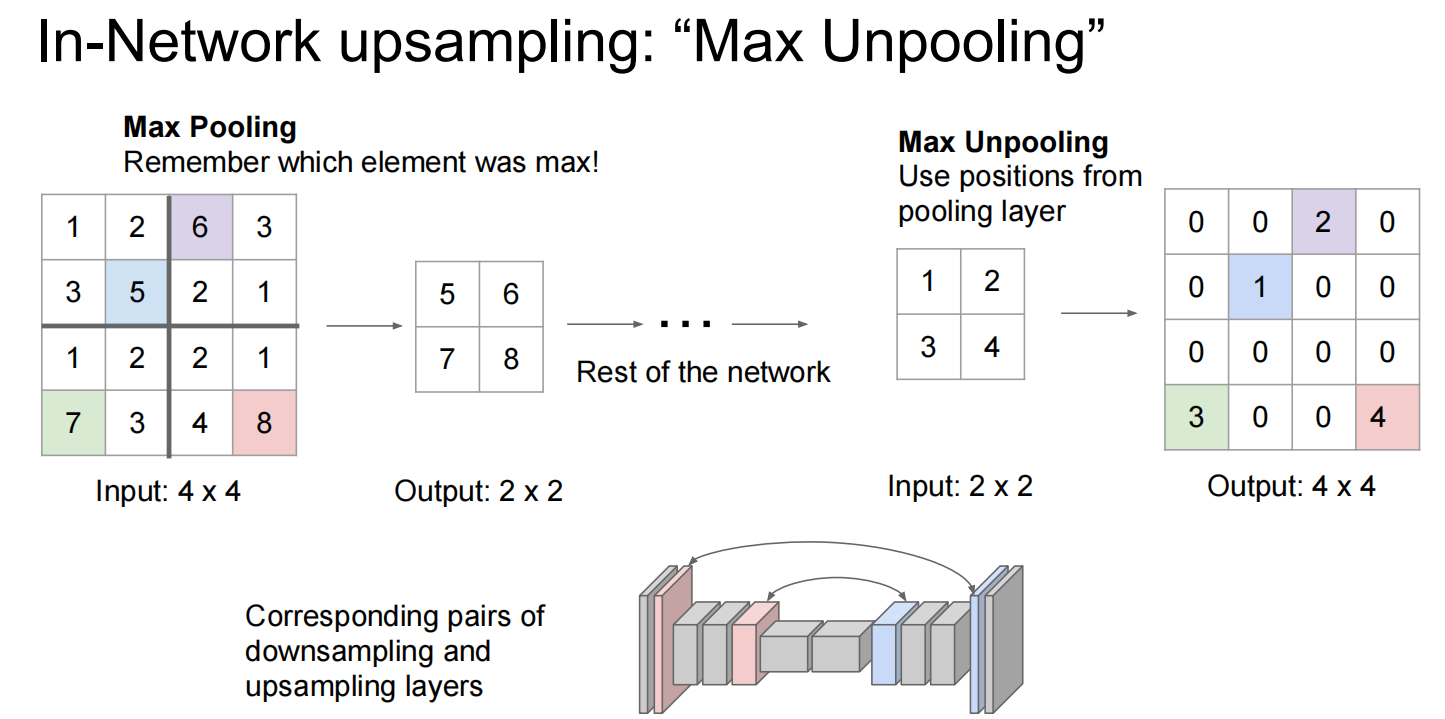
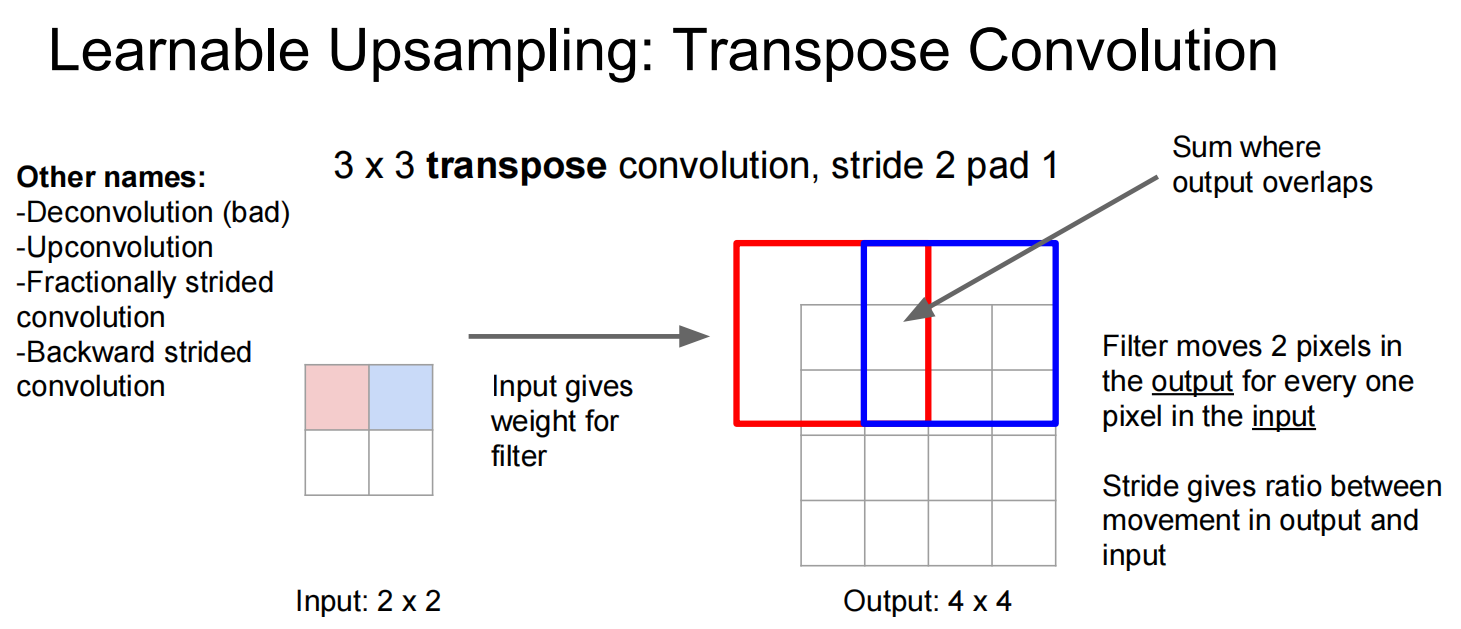
两种上采样:
第二个,定位:
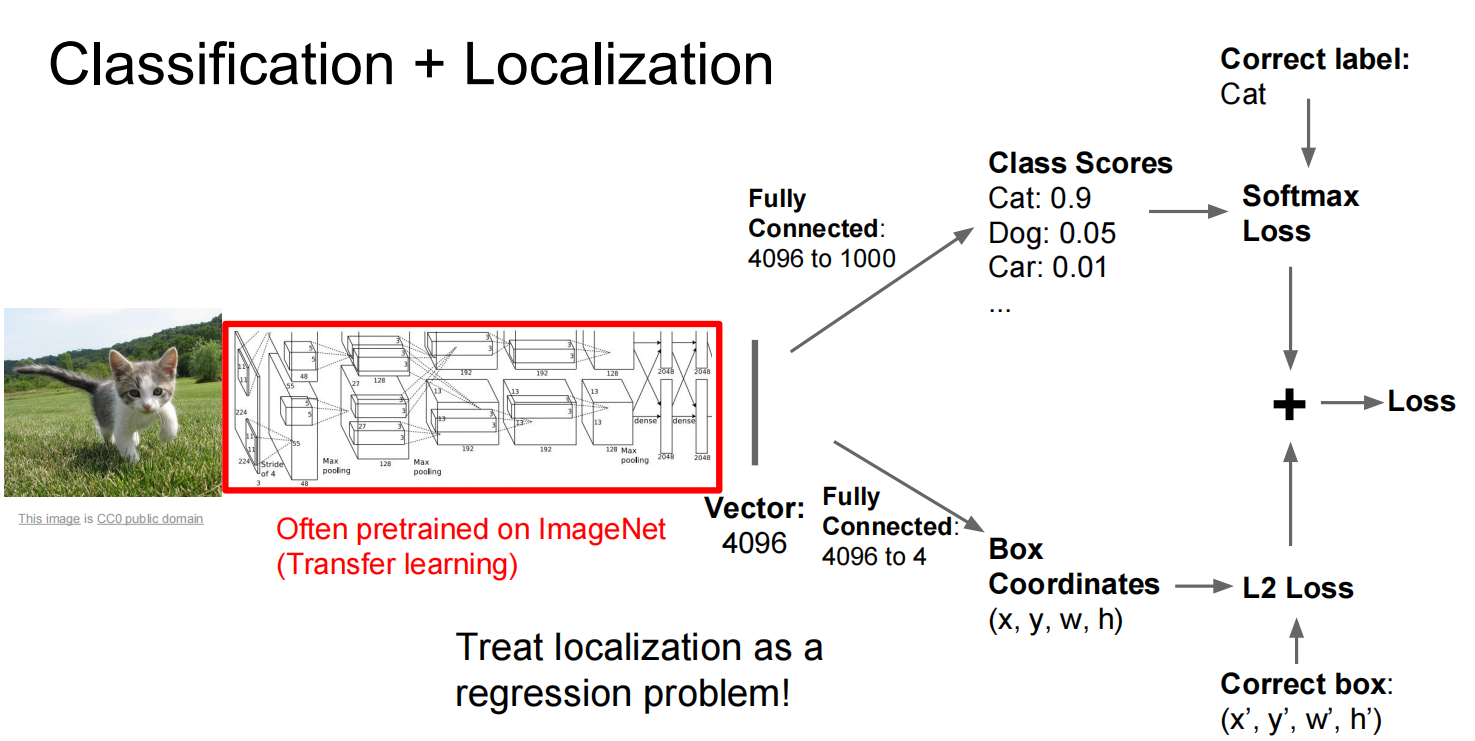
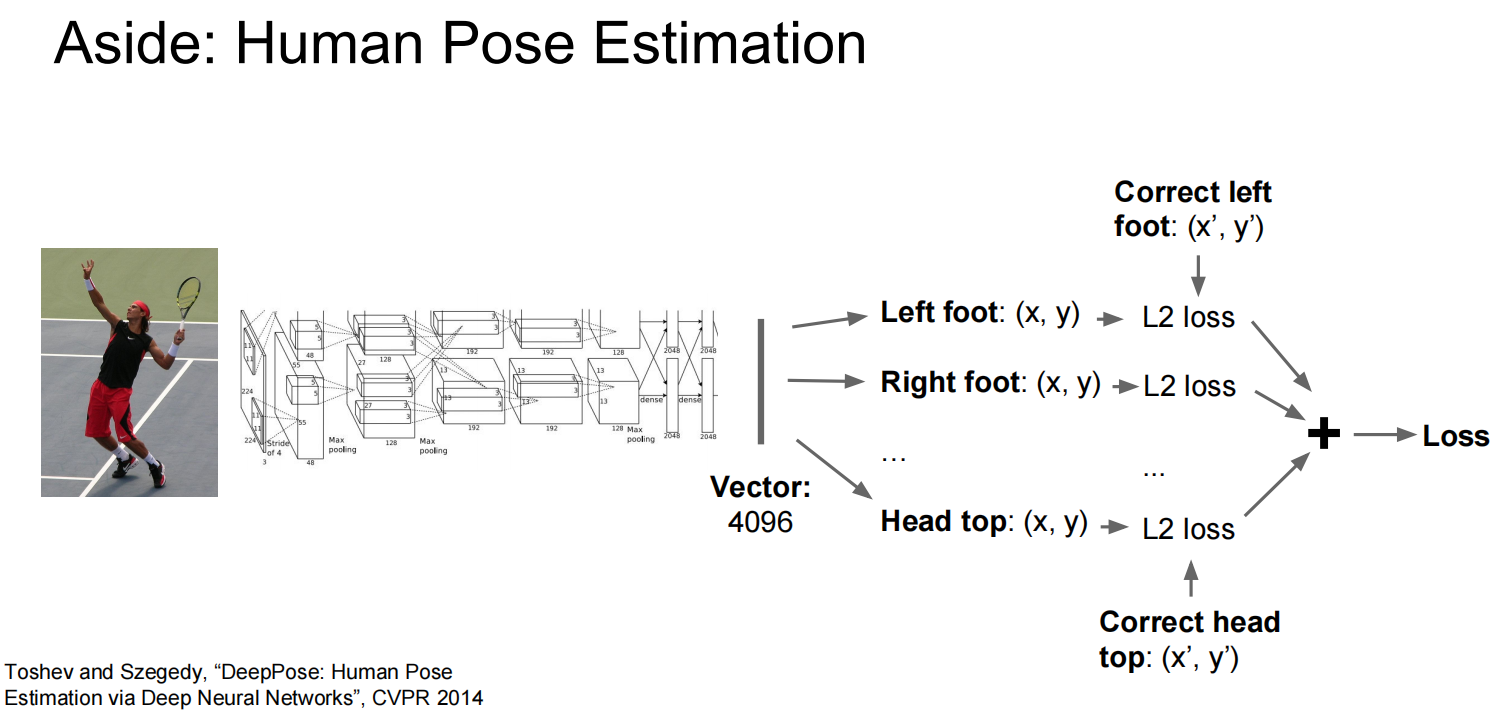
第三个:对象识别
Sliding window

如何获得候选的窗口:
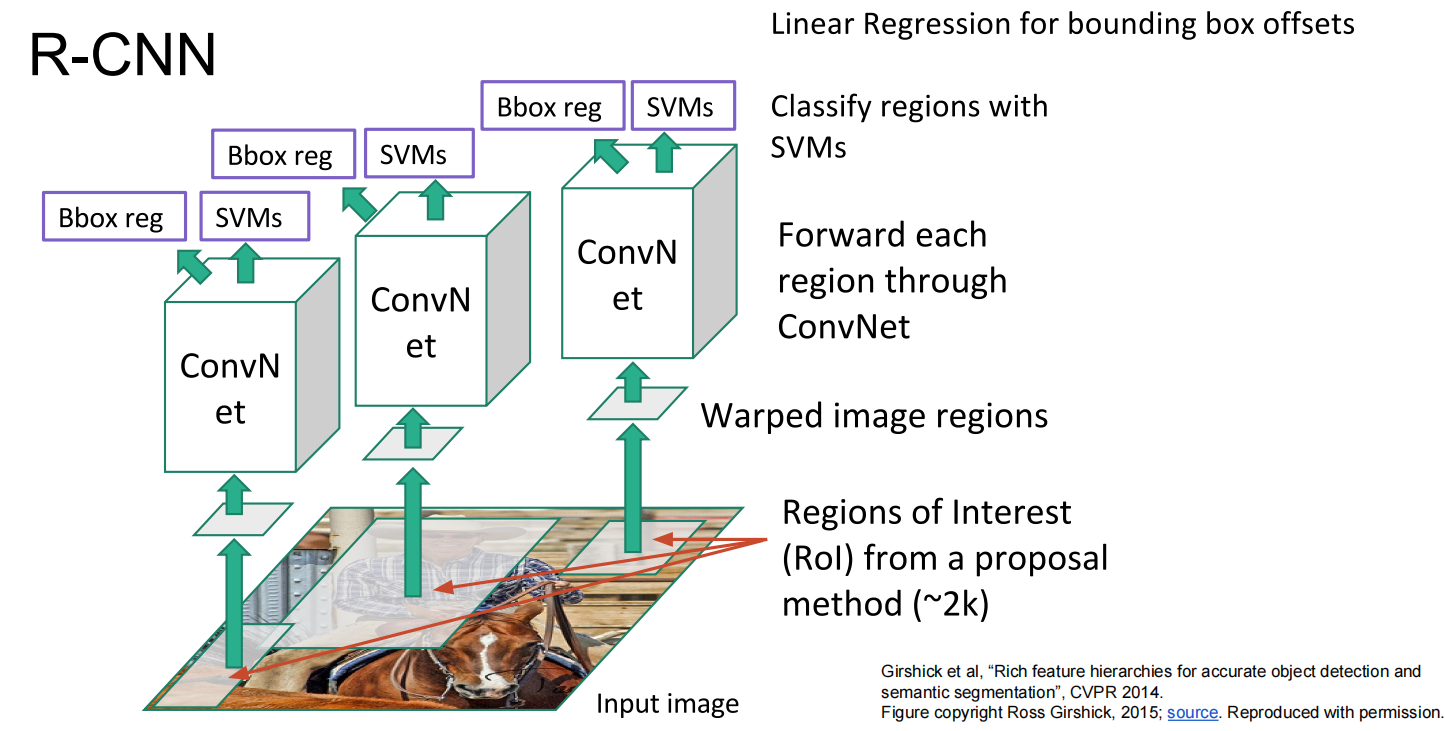
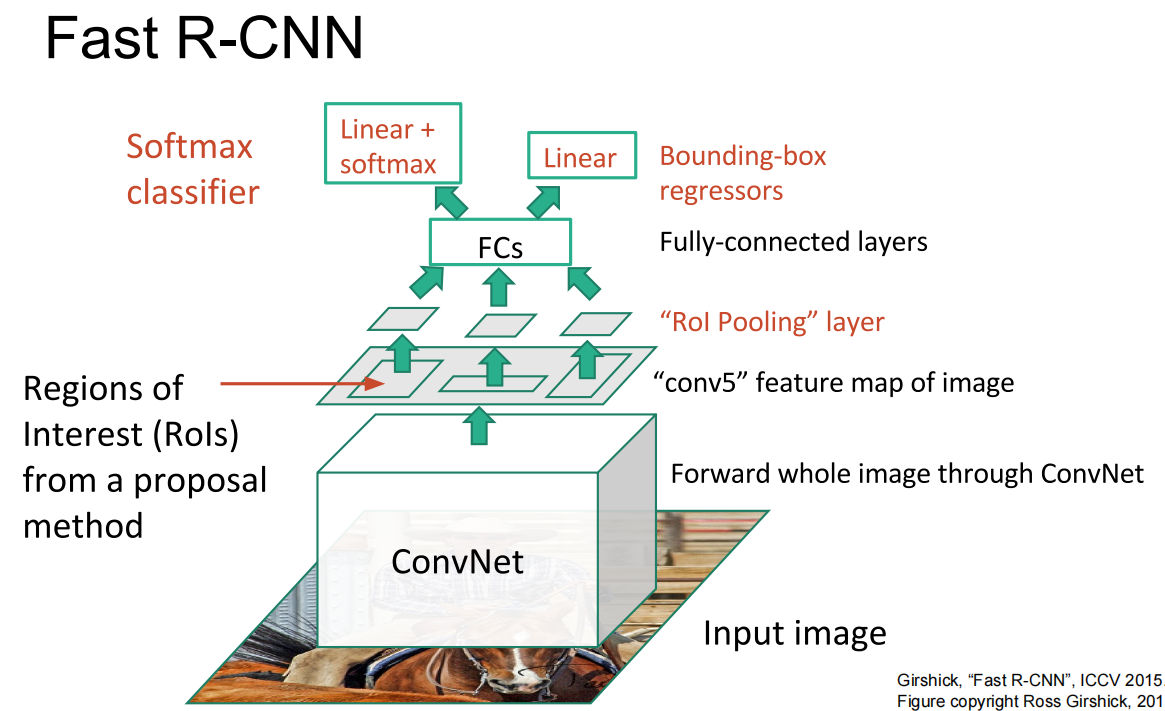
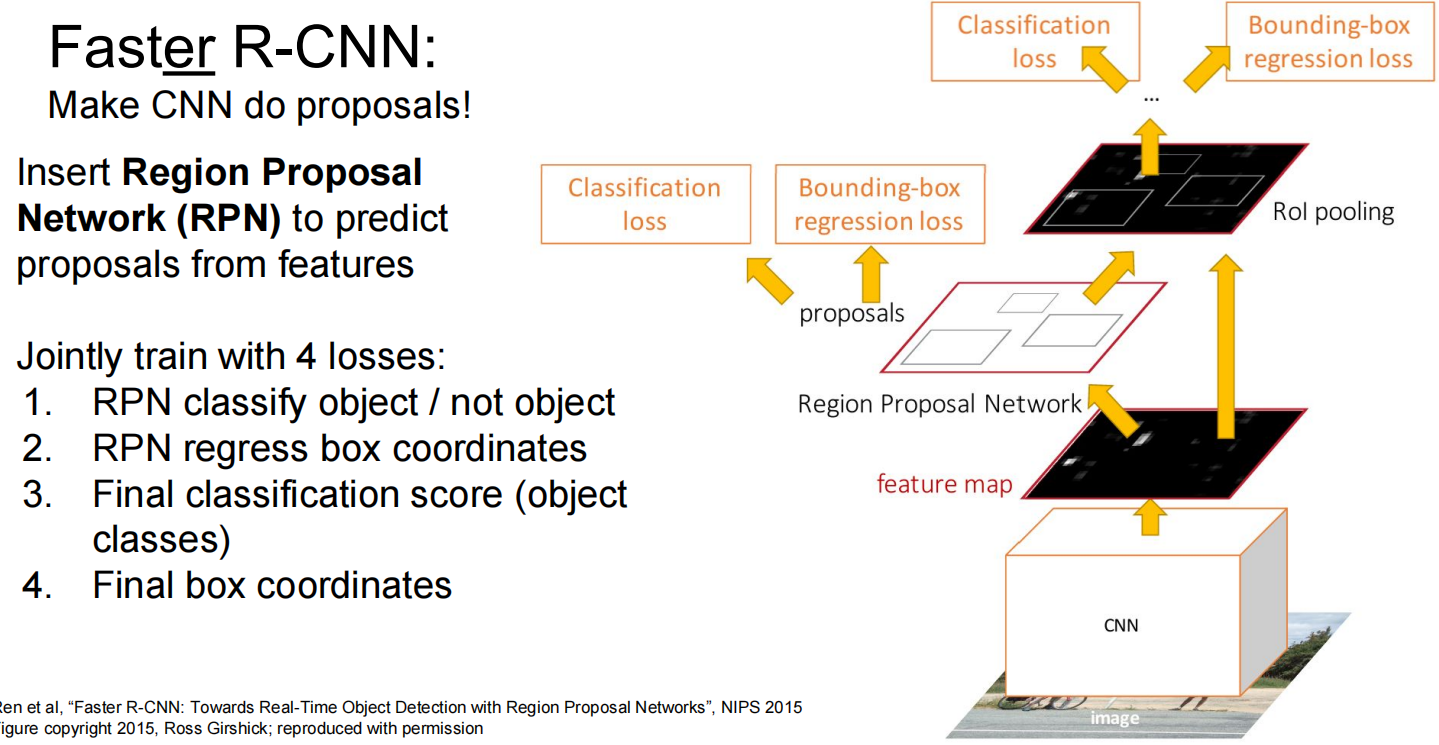
另一种方法:
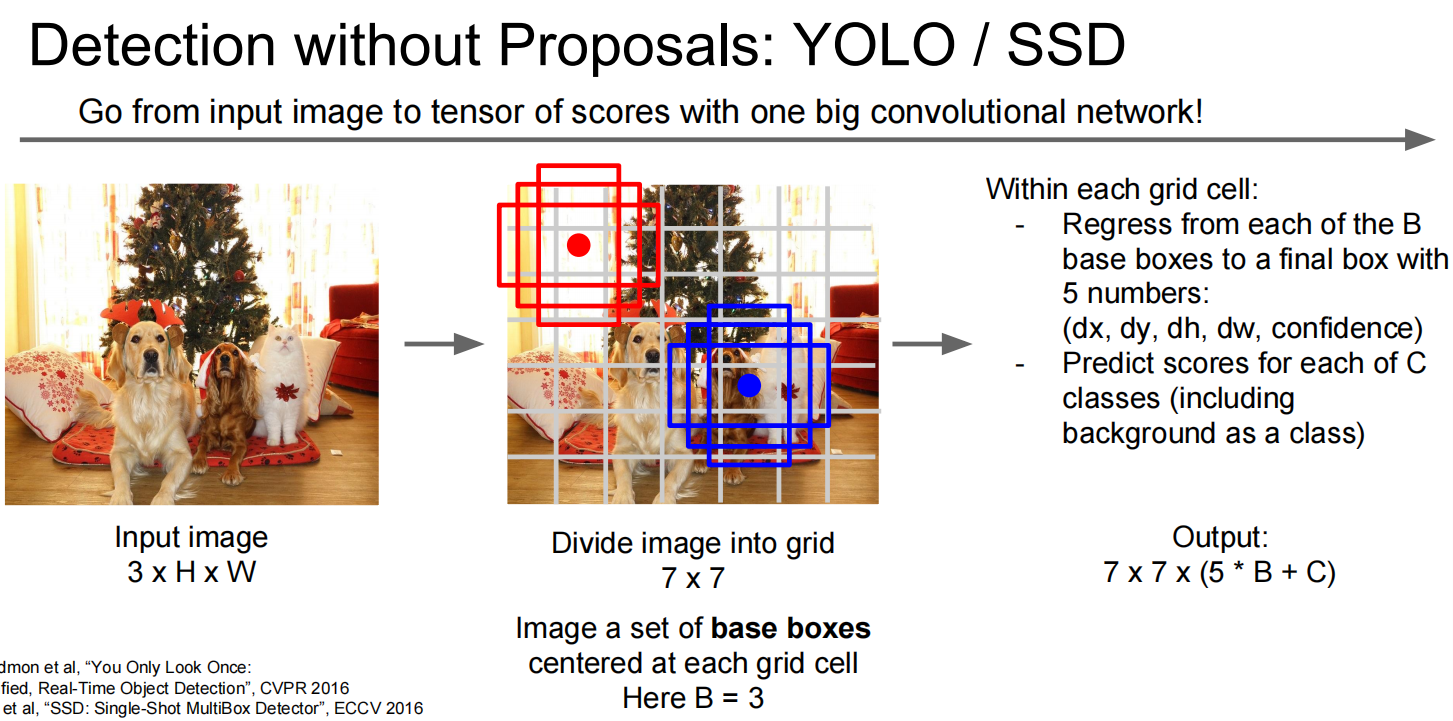
第四个:物体切割:
融合前几个事情,想要把一只狗切割出画面
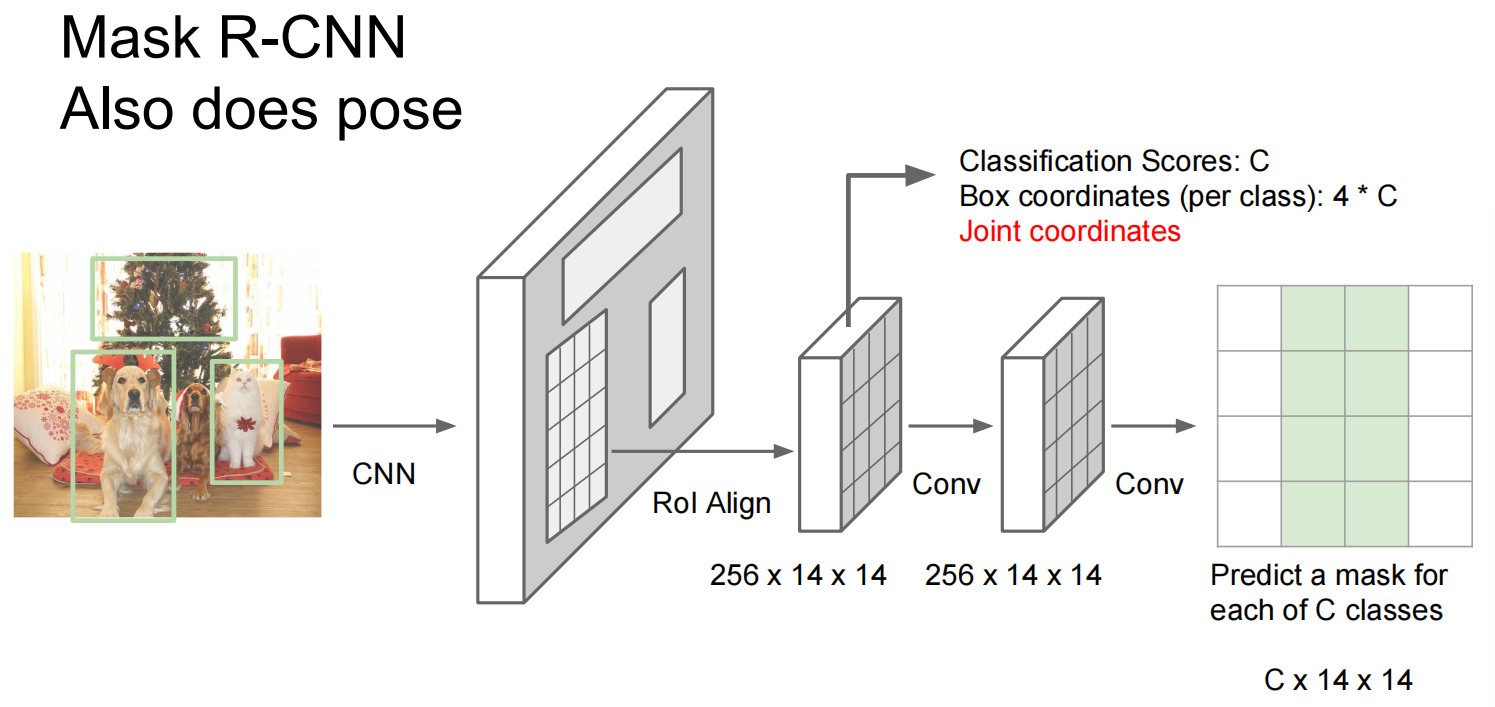
Lec12 Visualizing and understanding
可视化技术
为什么要可视化?神经网络备受争议,以为内塔西那个一个黑盒,里面在干啥是很难知道的,很难解释。所以可视化可以帮助我们知道内部的神经元都学到了什么,让这个黑盒可以解释一点点。
1. 可视化网络权重 (Filters)
最直接的方法是可视化网络第一层的卷积核权重 。
- 第一层: 学习到的卷积核通常是基础的特征检测器,如边缘、颜色块和简单的纹理 。
- 更高层: 更高层的卷积核权重(例如第二层、第三层)通常难以直接解释,因为它们作用于前一层的特征图,而不是原始图像像素 。

2. 可视化特征图 (Activations)
我们可以将单张图片输入网络,并可视化其中间层的激活图。
- 方法: 将中间层的激活张量(如一个 128×13×13 的特征图)视为128个 13×13 的灰度图像来观察 。这可以显示出对于给定输入,网络的哪些部分被激活了。
- 最大激活块 (Maximally Activating Patches): 为了理解某个特定神经元(或通道)的功能,我们可以在大量图片数据集中寻找最能激活该神经元的图像块 。这揭示了该神经元专门用于检测的视觉模式(如人脸、文字、狗的眼睛等) 。
在卷积之后的小空间内计算最近邻:
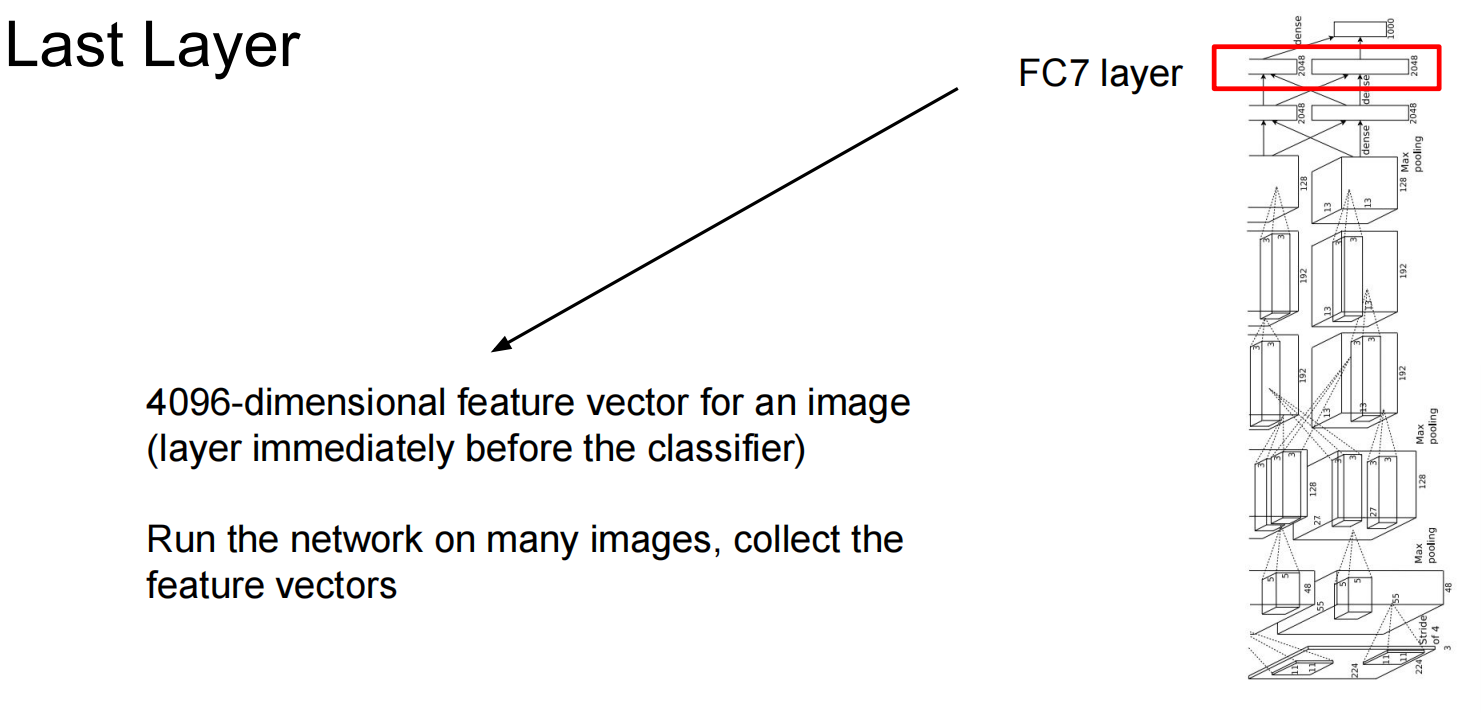
在最后一层降维,降成2维,于是就可视了:
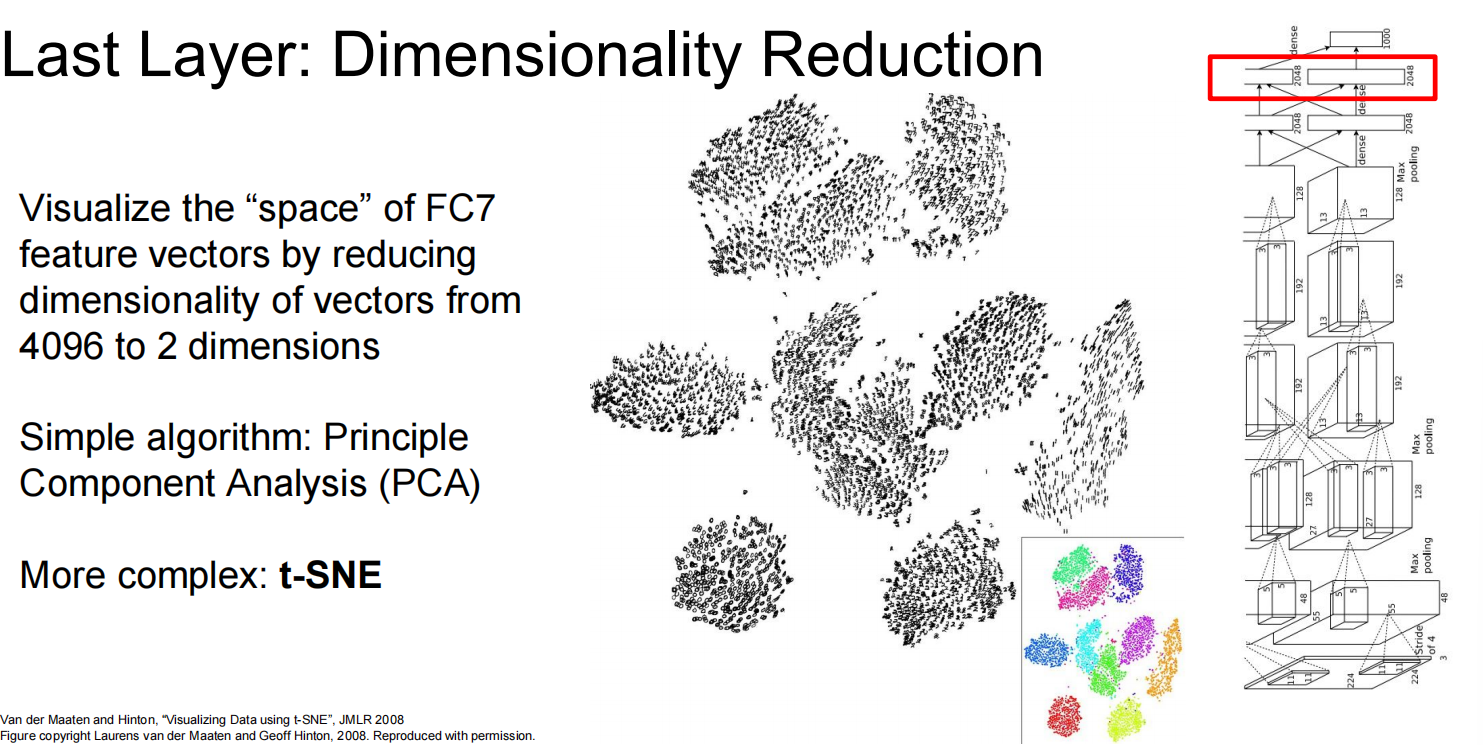
3. 基于梯度的方法
a) 显著图 (Saliency Maps)
该方法旨在回答:“图像中的哪些像素对最终的分类结果最重要?”
- 计算方式: 计算最终类别得分相对于输入图像像素的梯度,然后取其绝对值并在RGB通道上取最大值 。得到的图像会高亮显示对分类贡献最大的像素区域 。
- 应用: 显著图可以用于无监督的物体分割。例如,将显著图作为输入,利用GrabCut等算法可以从背景中分割出主体对象 。
b) 遮挡实验 (Occlusion Experiments)
这是一种探测性的方法,通过系统性地遮挡输入图像的不同部分,观察模型预测概率的变化。
- 操作: 用一个灰色方块滑过图像的各个位置,并记录每次遮挡后正确类别的预测概率 。
- 结果: 将概率变化绘制成热力图,可以直观地显示出模型做出决策时所依赖的关键图像区域 。
c) 梯度上升 (Gradient Ascent) 与类别可视化
该方法不是分析现有图像,而是生成一个能最大化激活特定神经元(或类别得分)的合成图像 。
- 流程:
- 从一张零值或随机噪声图像开始 。
- 将图像前向传播,计算目标神经元(或类别)的得分 。
- 反向传播计算得分关于图像像素的梯度 。
- 沿梯度方向更新图像,以微小步长提升得分 。
- 重复以上步骤 。
- 正则化: 为了使生成的图像看起来更“自然”,需要加入正则项,例如L2正则化、高斯模糊、裁剪低值像素等 。


d) 愚弄图像 (Fooling Images) / 对抗性样本 (Adversarial Examples)
这揭示了神经网络的脆弱性。通过对原始图像进行微小、人眼几乎无法察觉的改动,可以使网络做出完全错误的分类 。
- 生成过程: 从一张正常图像开始,选择一个任意的目标类别(错误的类别),然后通过梯度上升修改图像,以最大化这个错误类别的得分,直到网络被“愚弄” 。
应用
1. DeepDream
DeepDream是一种将梯度上升思想用于艺术创作的技术。它不是最大化特定类别,而是放大图像在网络某一层的现有特征 。
- 原理:
- 选择一张图像和一个CNN层 。
- 前向传播计算该层的激活值 。
- 将该层的梯度设置为其自身的激活值 。
- 反向传播计算梯度到图像上并更新图像 。
- 效果: 这个过程会不断强化网络在该层识别到的模式,产生奇幻、迷幻的“梦境”般图像,例如在云中看到动物和建筑 。
2. 特征反演 (Feature Inversion)
给定一个图像经过CNN得到的特征向量,此技术旨在重建一个新图像,使其特征向量与给定的特征向量相匹配 。
- 意义: 通过在不同层进行特征反演,我们可以看到网络在不同深度所保留的信息。从浅层重建可以很好地还原像素细节,而从深层重建则更多地保留了空间结构和语义信息,但丢失了精确的像素外观 。
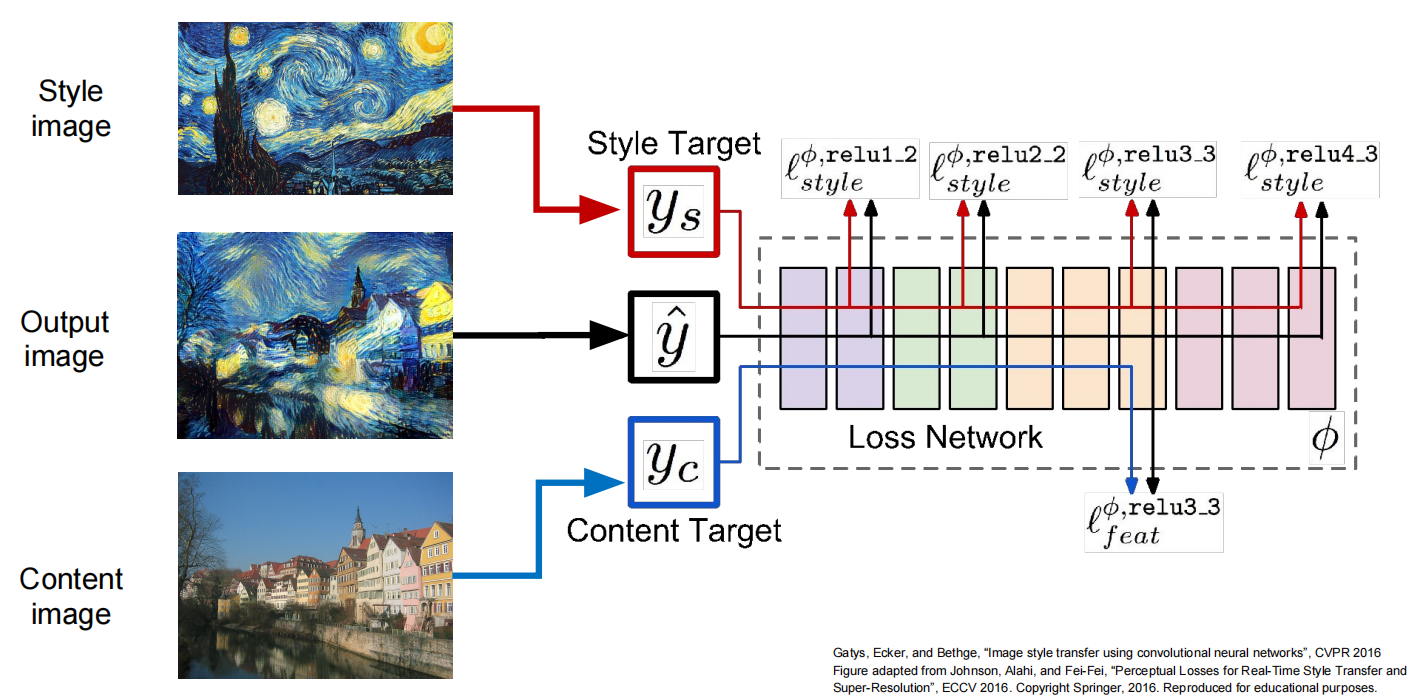
3. 神经风格迁移 (Neural Style Transfer)
这是一项惊人的技术,它将一张图像的“内容”和另一张图像的“风格”结合起来,生成一幅新的艺术作品 。
- 核心思想:
- 内容 (Content): 由CNN深层特征图的激活值本身来表示 。我们希望生成图像的深层特征图与内容图像的特征图尽可能相似。
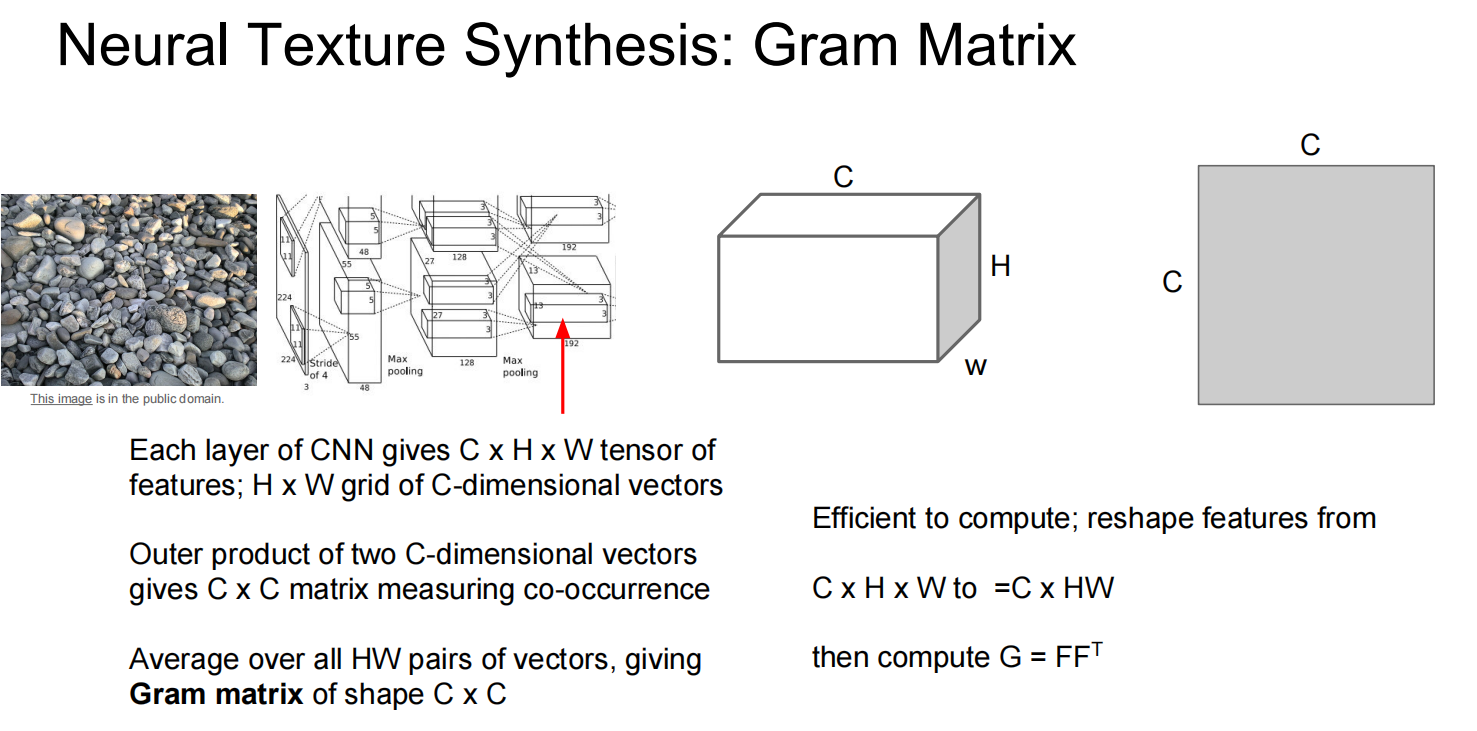
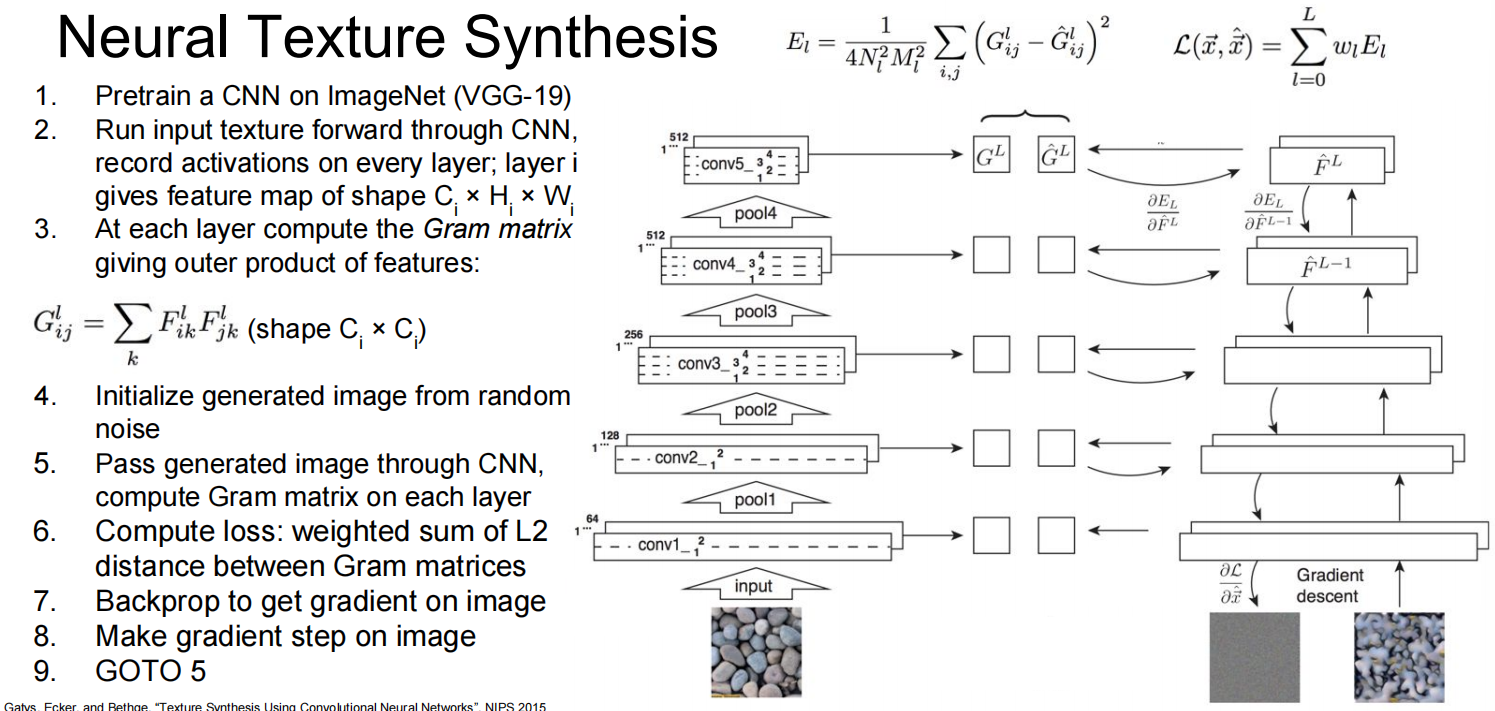
- 风格 (Style): 由CNN各层特征图的格拉姆矩阵 (Gram Matrix) 来表示 。格拉姆矩阵捕捉了特征之间的相关性,代表了纹理和笔触等风格信息 。我们希望生成图像的格拉姆矩阵与风格图像的格拉姆矩阵尽可能相似。
- 优化过程: 从一张随机图像开始,同时最小化与内容图像的“内容损失”和与风格图像的“风格损失” 。
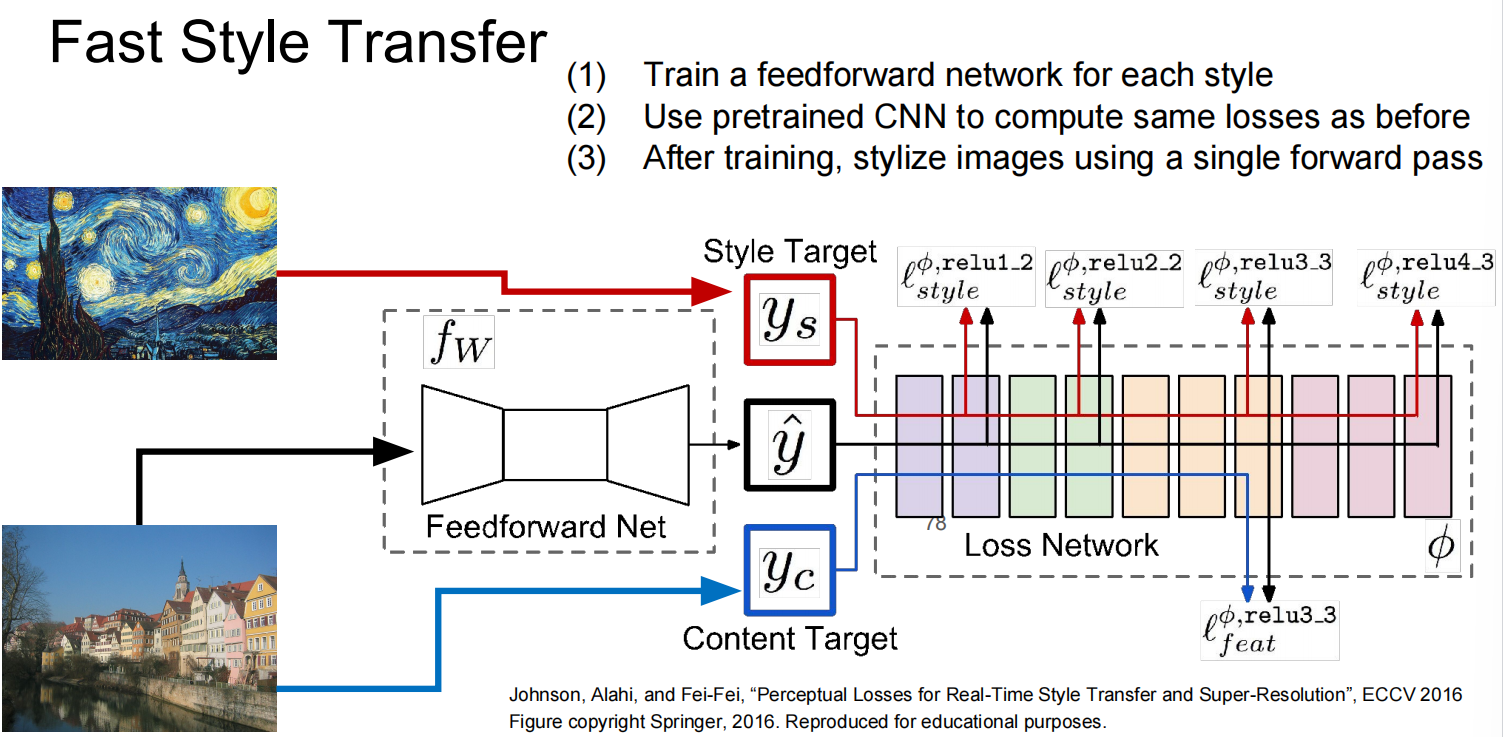
快速风格迁移 (Fast Style Transfer)
原始的风格迁移是一个缓慢的迭代优化过程 。为了加速,可以为每一种特定的艺术风格训练一个前馈网络 。
- 方法: 训练一个图像生成网络,其损失函数由预训练的VGG网络(损失网络)计算得出 。训练完成后,这个生成网络可以非常快速地(只需一次前向传播)将任意内容图像转换为特定风格 。
- 多风格网络: 进一步地,可以通过使用“条件实例归一化”(Conditional Instance Normalization) 技术,让单个网络学会多种风格,甚至可以对不同风格进行融合 。
Lec13 Generative Models
无监督模型-生成式
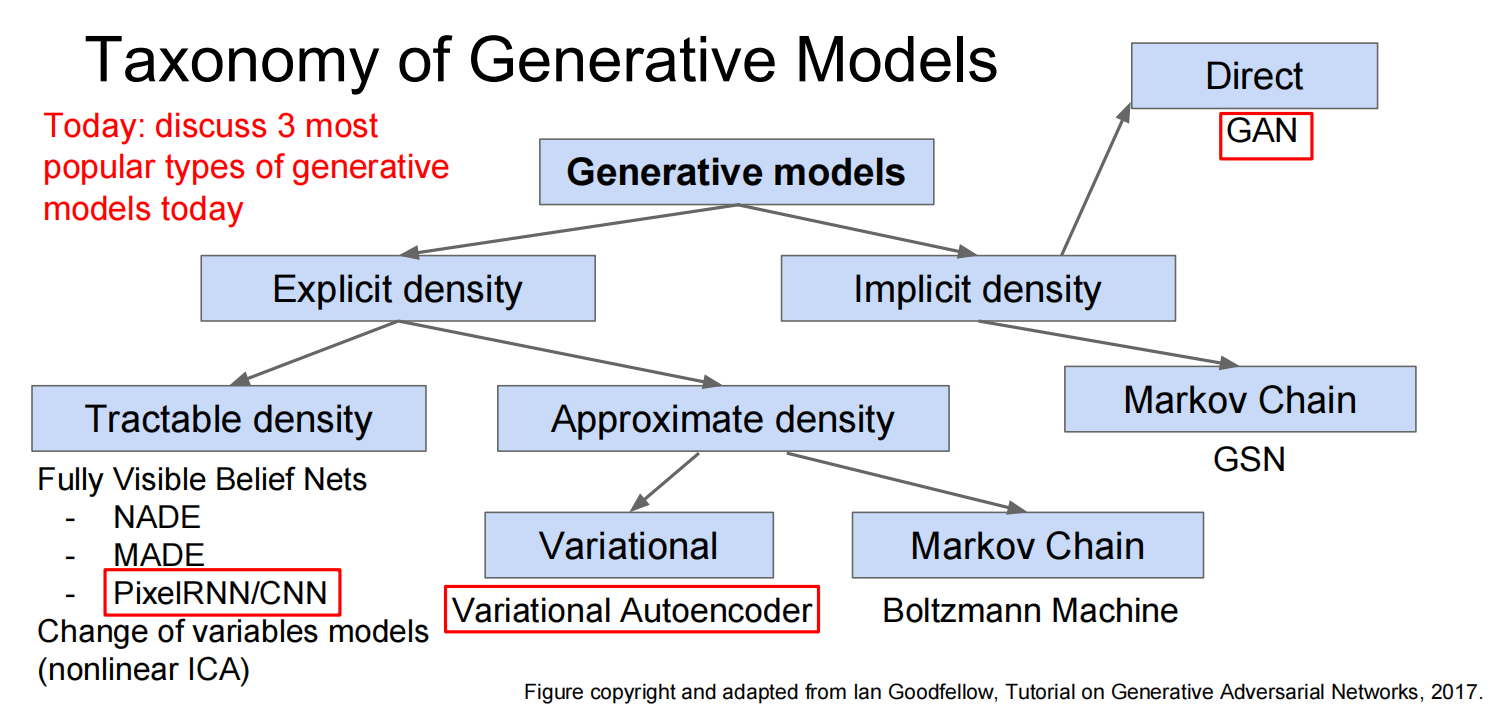
第一个,PixelRNN and PixelCNN

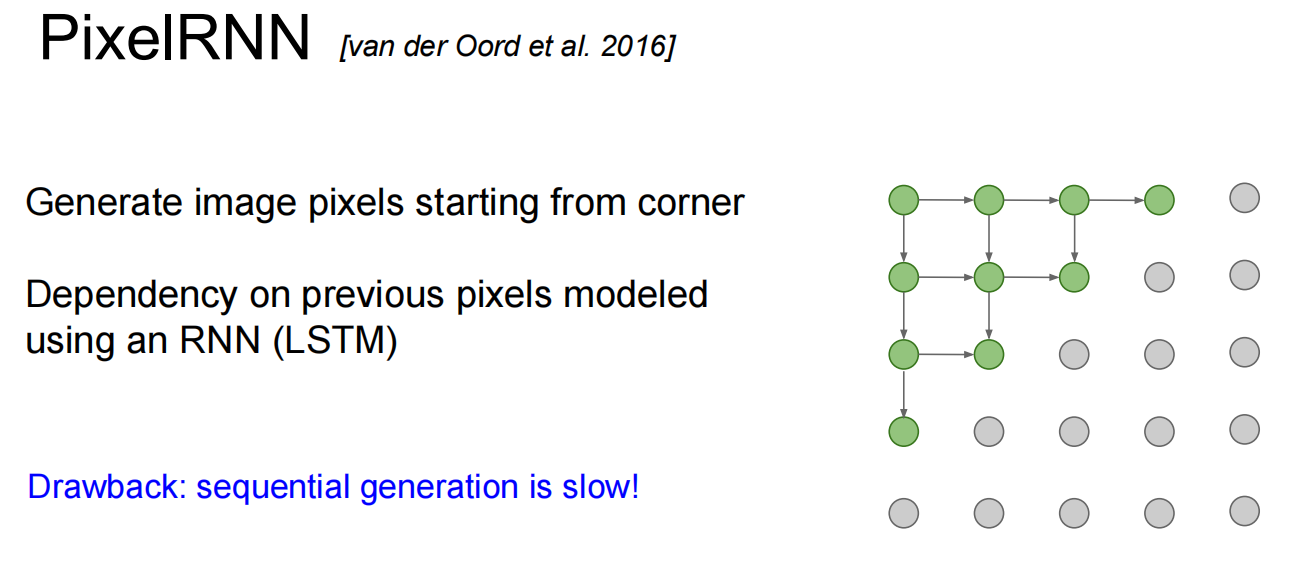
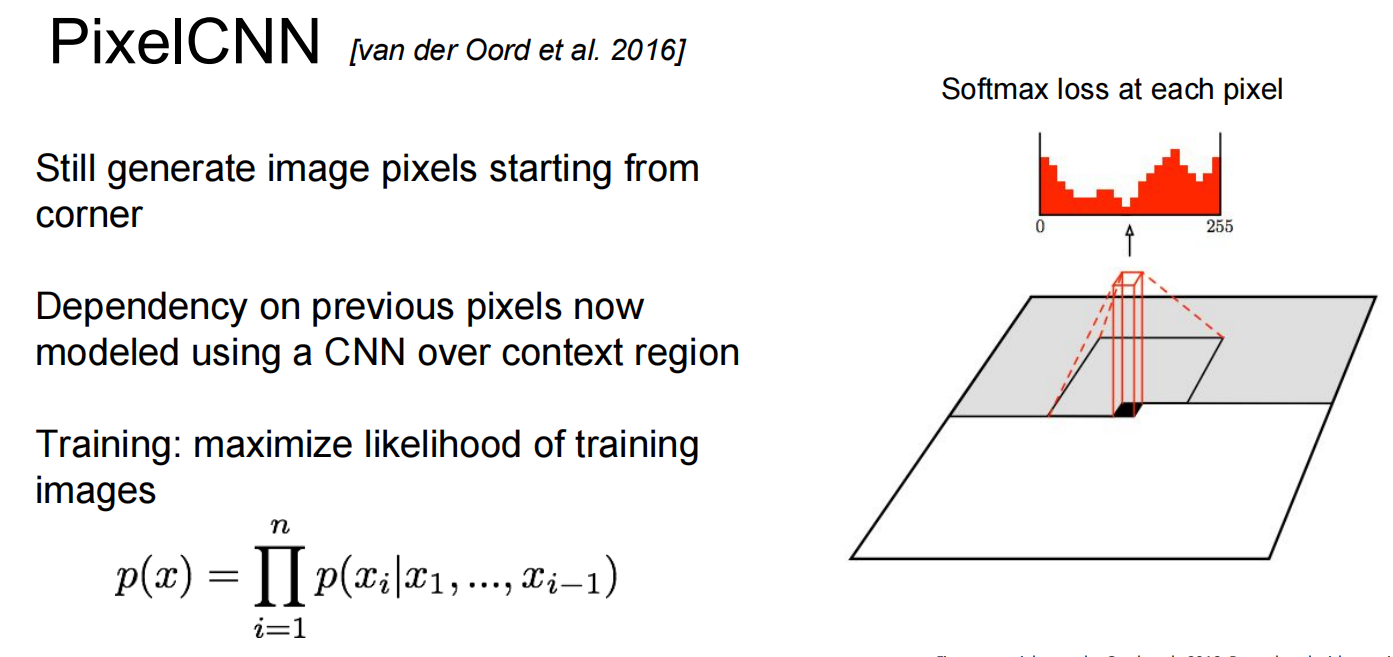
都比较慢
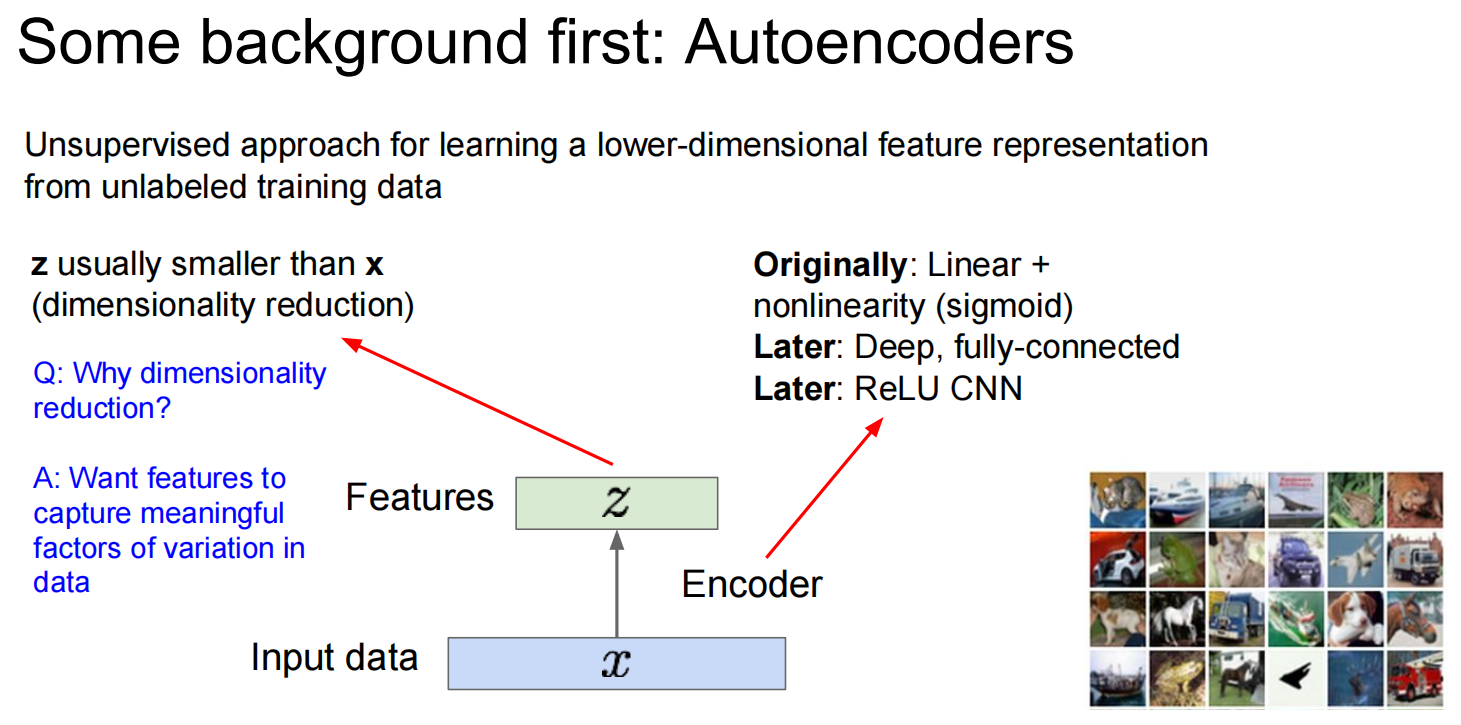
第二个,Variational Autoencoders (VAE)

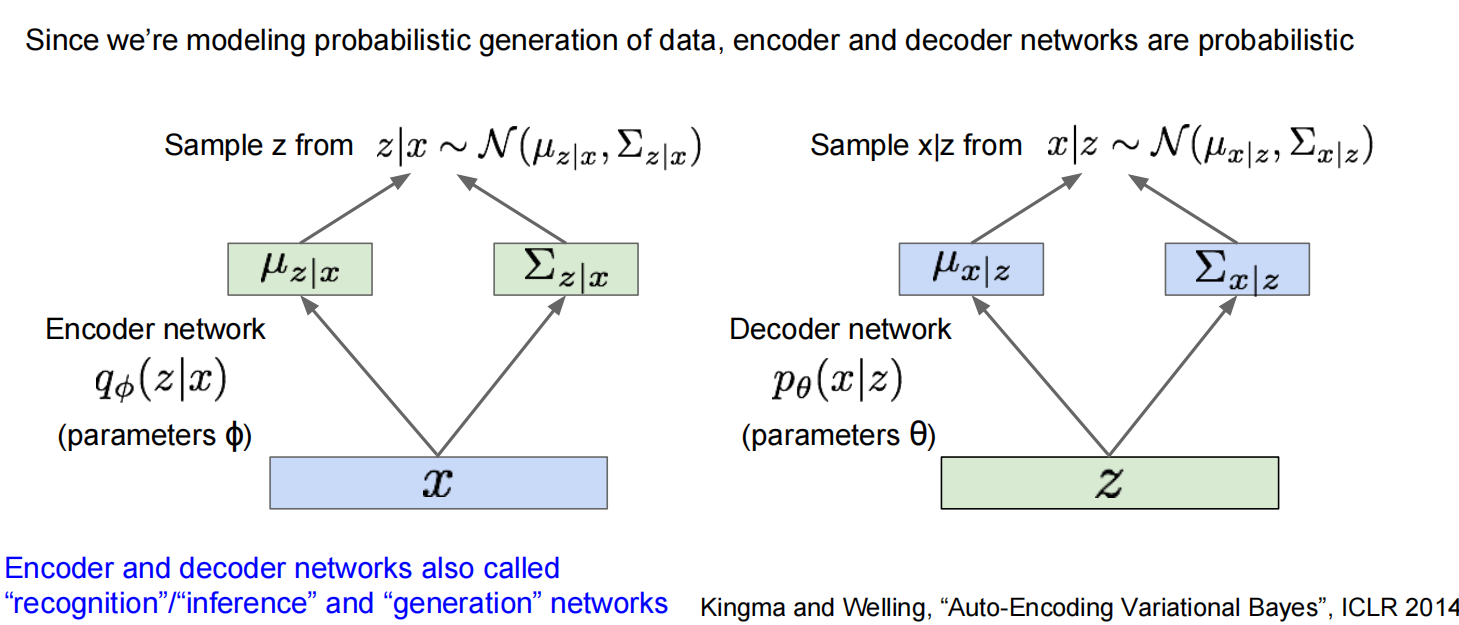


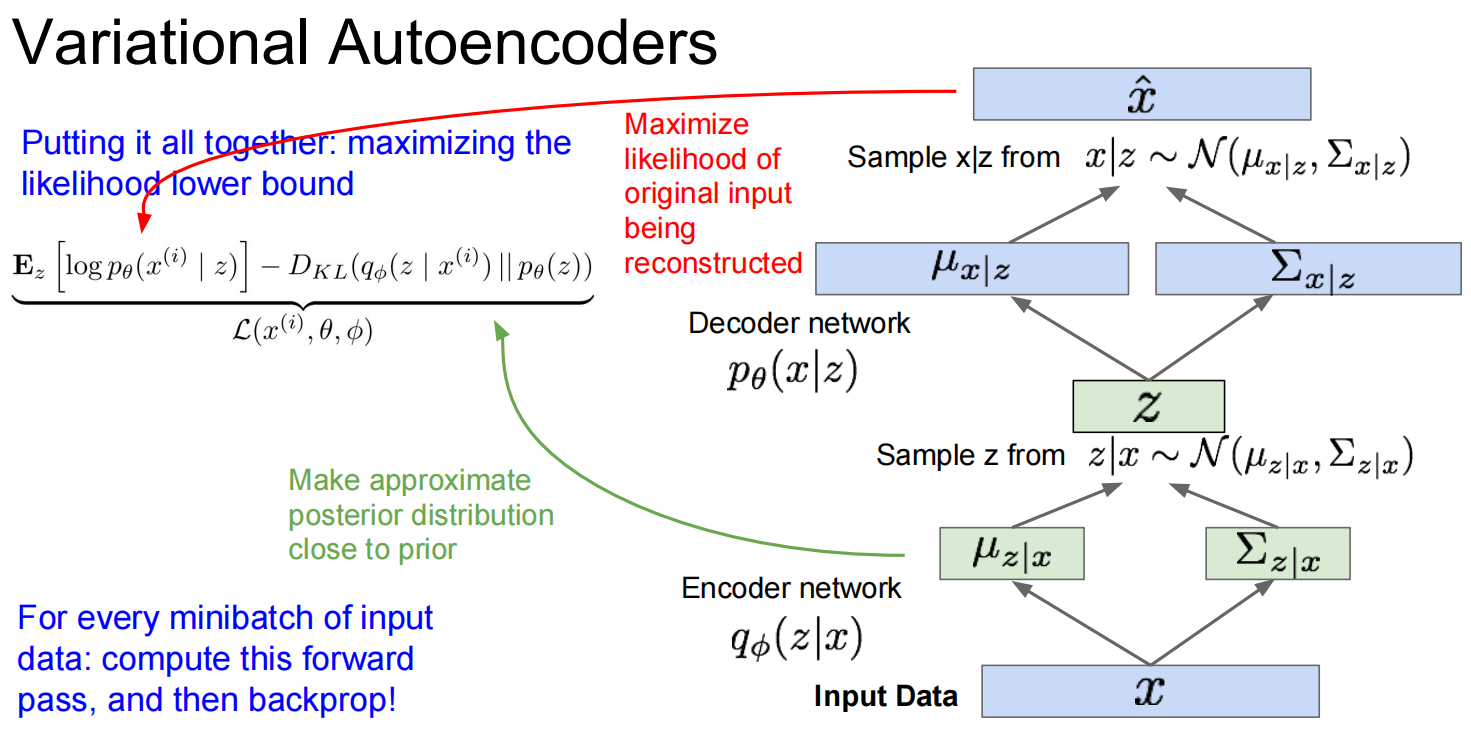
第三个:GAN



Lec14 Reinforcement Learning
强化学习
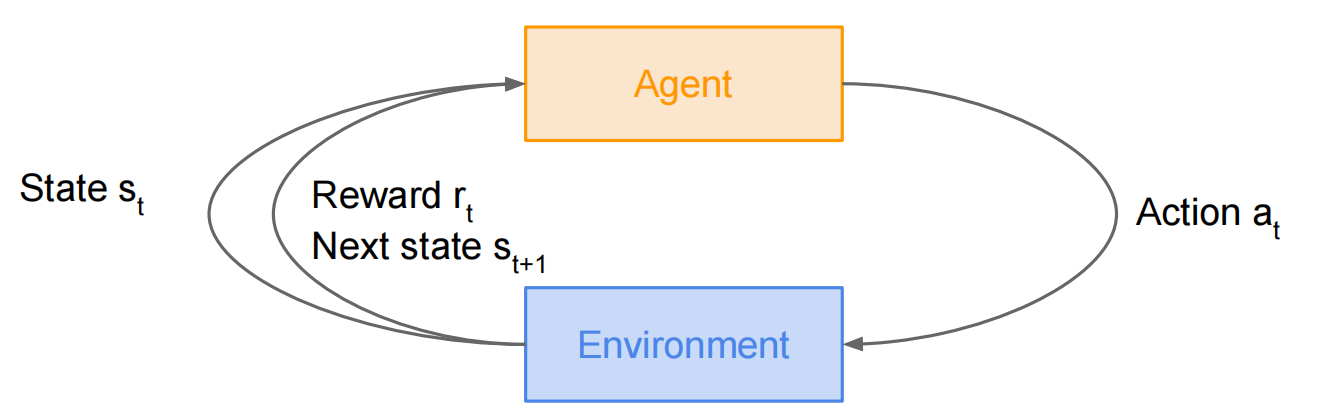




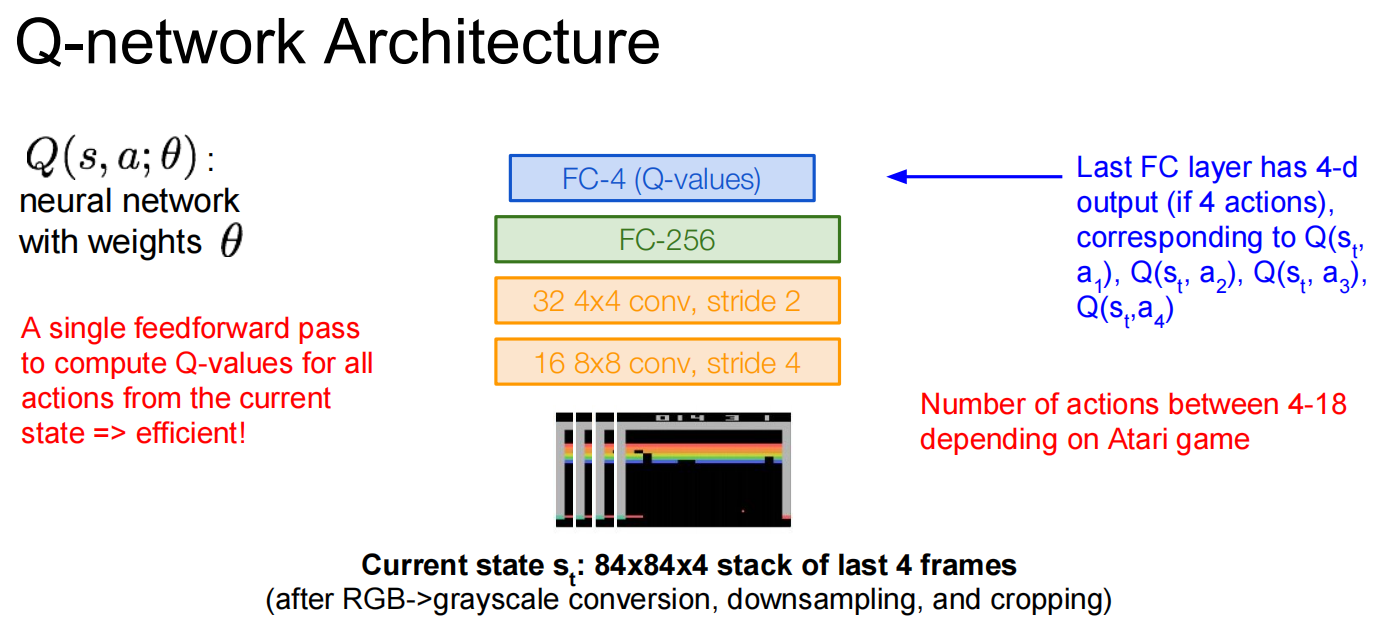
有一些问题:学习率低,容易走走过的路




方差缩减 (Variance Reduction)

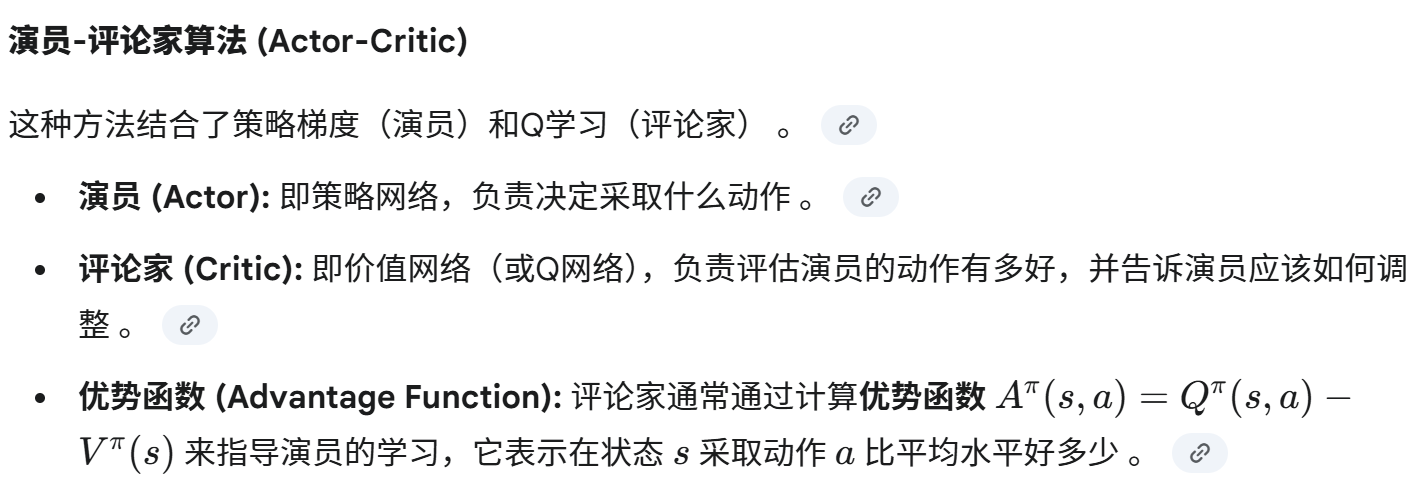
REINFORCE 算法的应用实例:循环注意力模型 (RAM)
RAM 模型是一种将强化学习应用于计算机视觉任务(如图像分类)的经典模型 。它的核心思想是模仿人类视觉系统,不是一次性处理整张图片,而是通过一系列的“扫视”(glimpses) 来选择性地关注图像的关键区域,从而做出决策 。
强化学习框架
RAM 将图像分类问题构建成一个强化学习任务 :
- 状态 (State): 到目前为止已经“看”过的所有扫视区域的信息 。
- 动作 (Action): 下一次扫视的中心位置坐标 (x,y) 。
- 奖励 (Reward): 这是一个延迟奖励。只有在最后一个时间步,如果模型最终正确分类了图像,则奖励为1,否则为0 。
RAM 使用一个循环神经网络 (RNN) 来实现其功能 。
- 在每一个时间步,RNN 会根据其内部的隐藏状态(代表了之前所有扫视的信息)来决定下一个扫视的位置 (xt,yt) 。
- 模型从该位置提取一个小的、多分辨率的图像块(即一个 glimpse),并将其输入一个小型神经网络进行特征提取 。
- 提取出的特征被送入 RNN,用于更新其隐藏状态,并为下一步的扫视决策做准备 。
- 这个过程重复固定的次数后,RNN 的最终隐藏状态被送入一个分类器(如 Softmax),以得出最终的类别预测 。
Lec15 Efficient Methods and Hardware for Deep Learning
Part 1: Algorithms for Efficient Inference
pruning
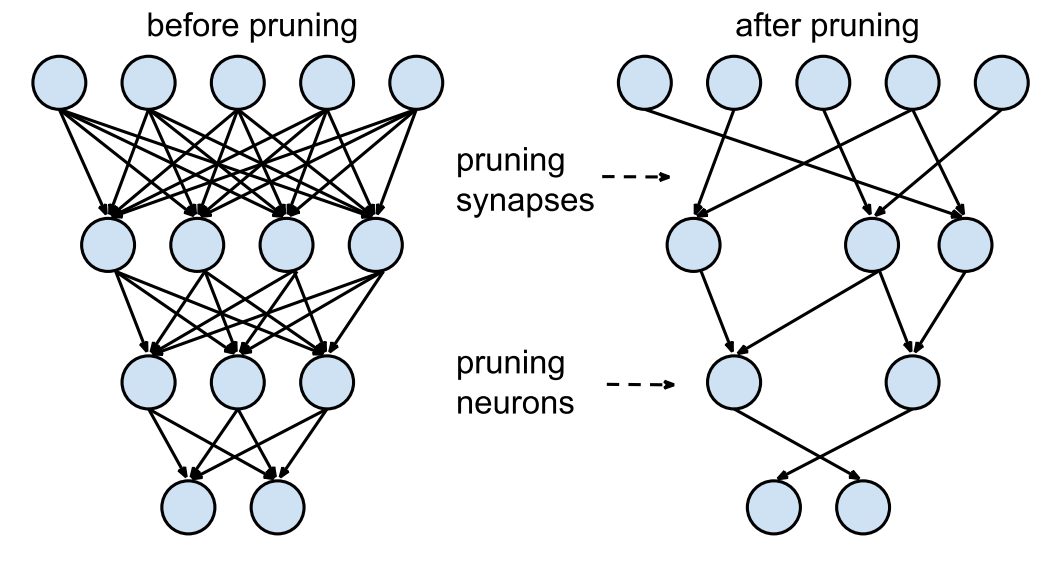
剪枝,重训练,剪枝,重训练
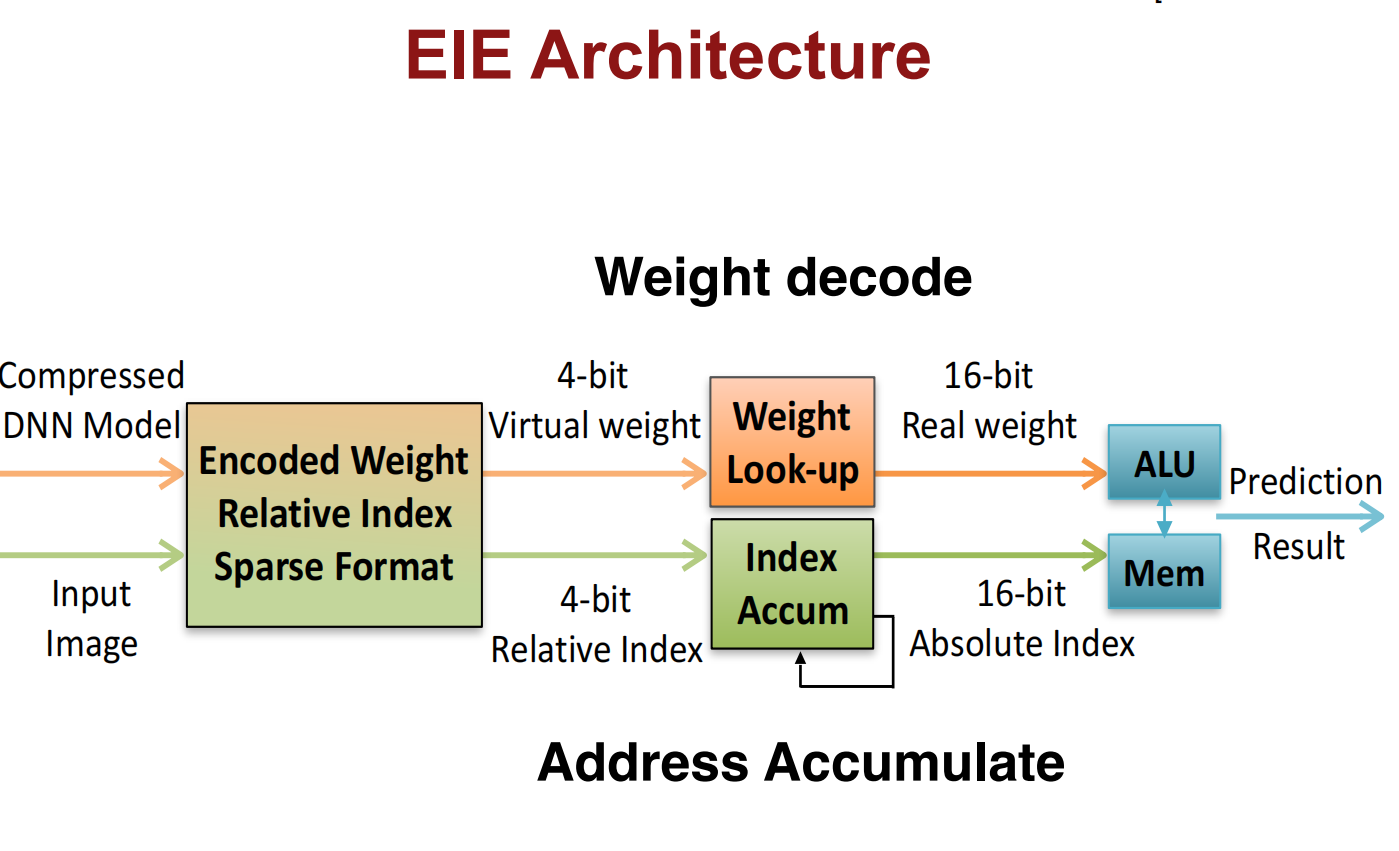
Weight Sharing
减小位数,权重共享
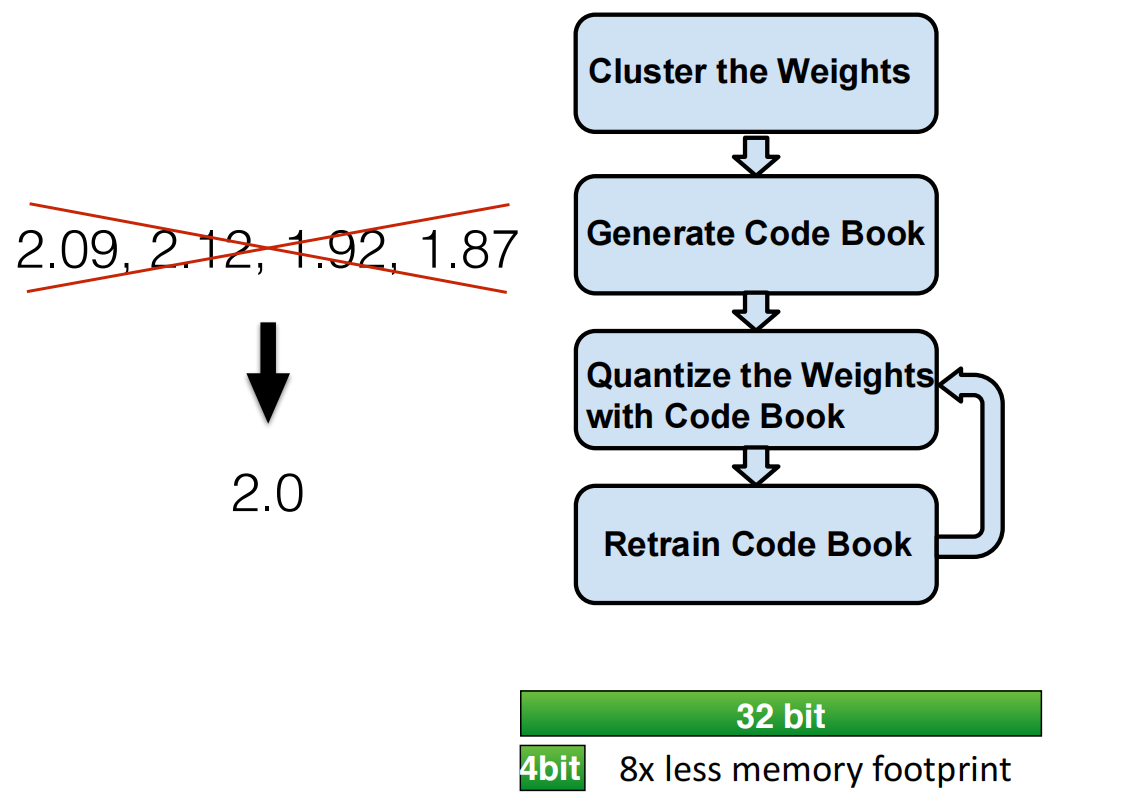
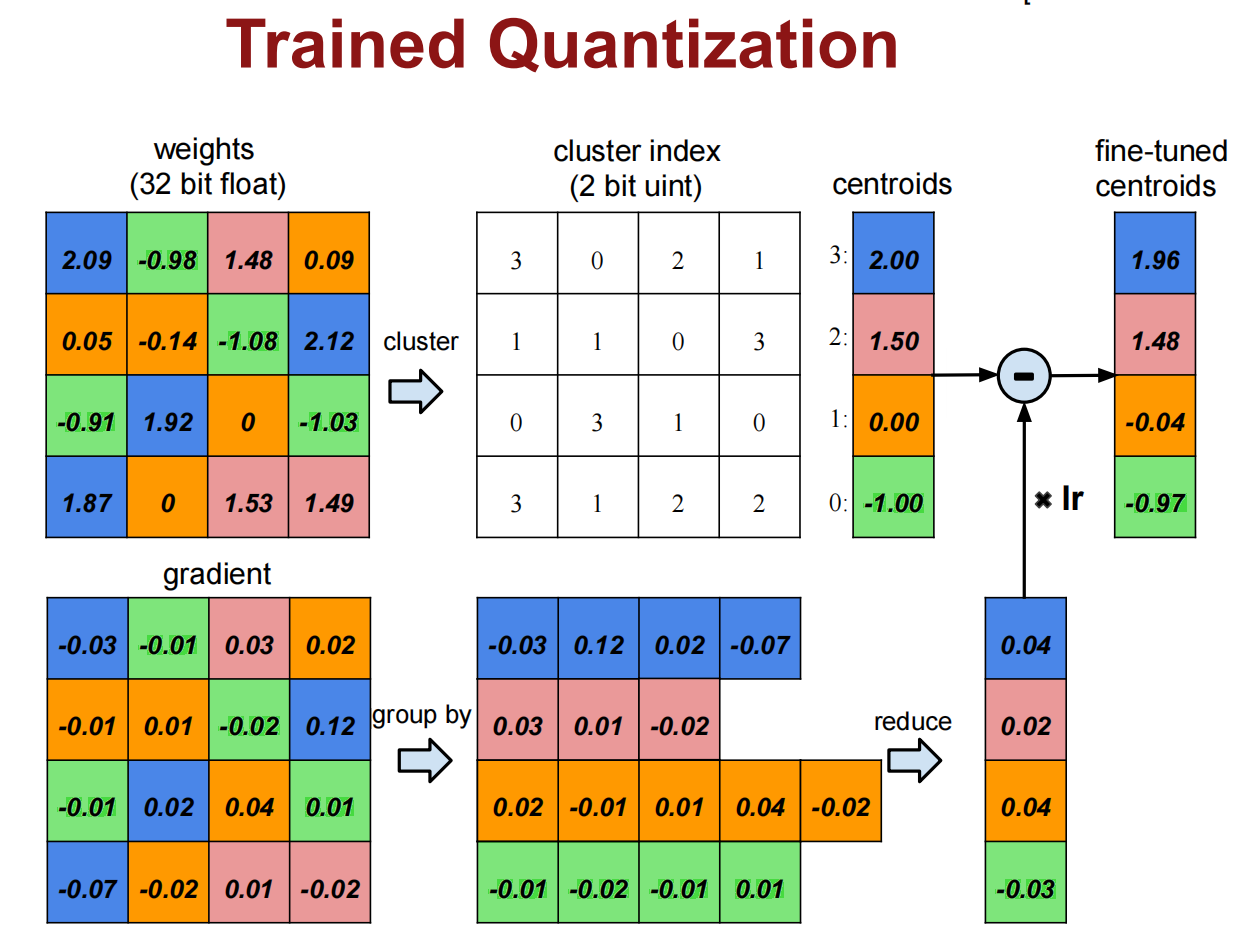
或者使用哈夫曼编码减小位数
进一步压缩:
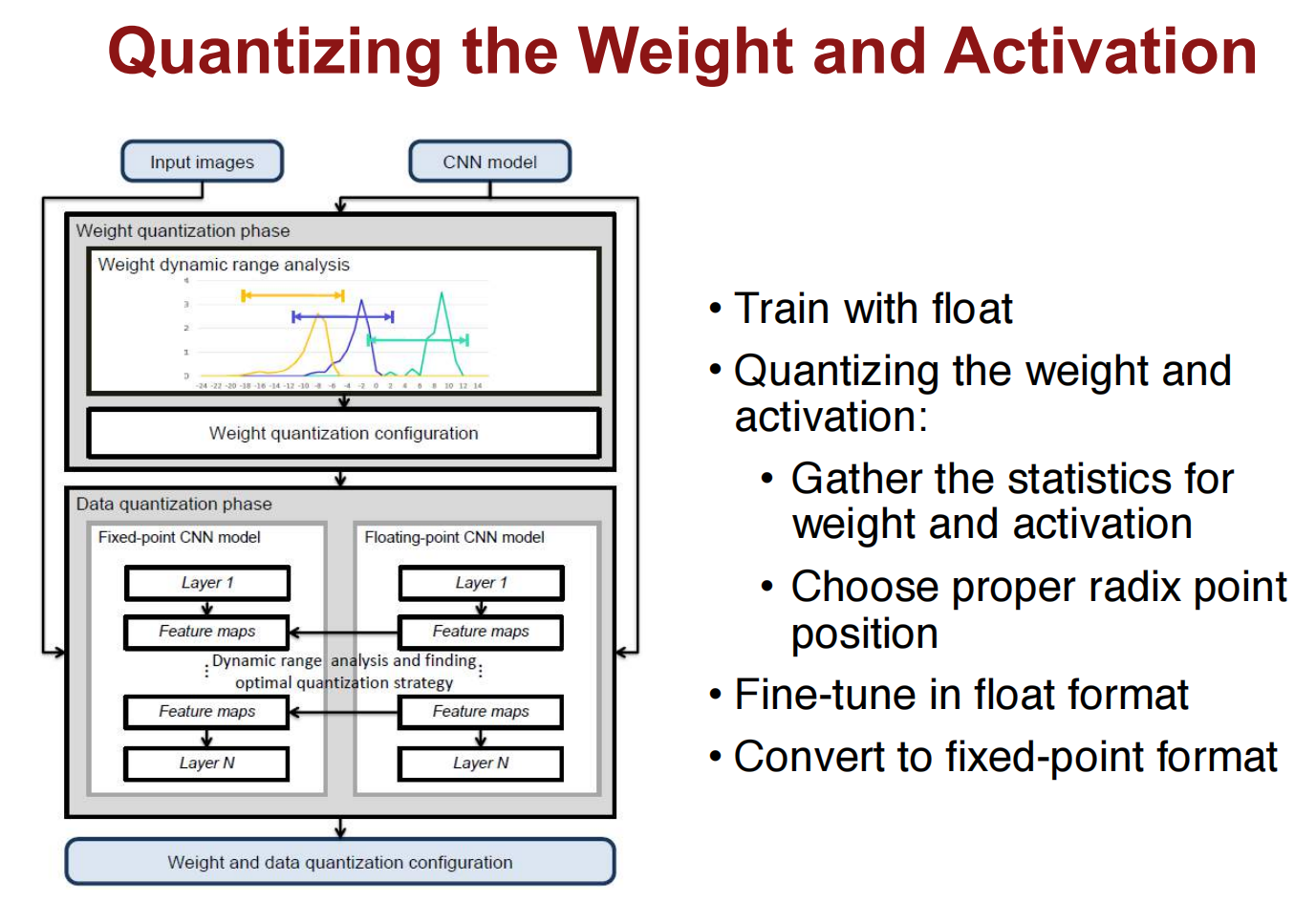
Quantization
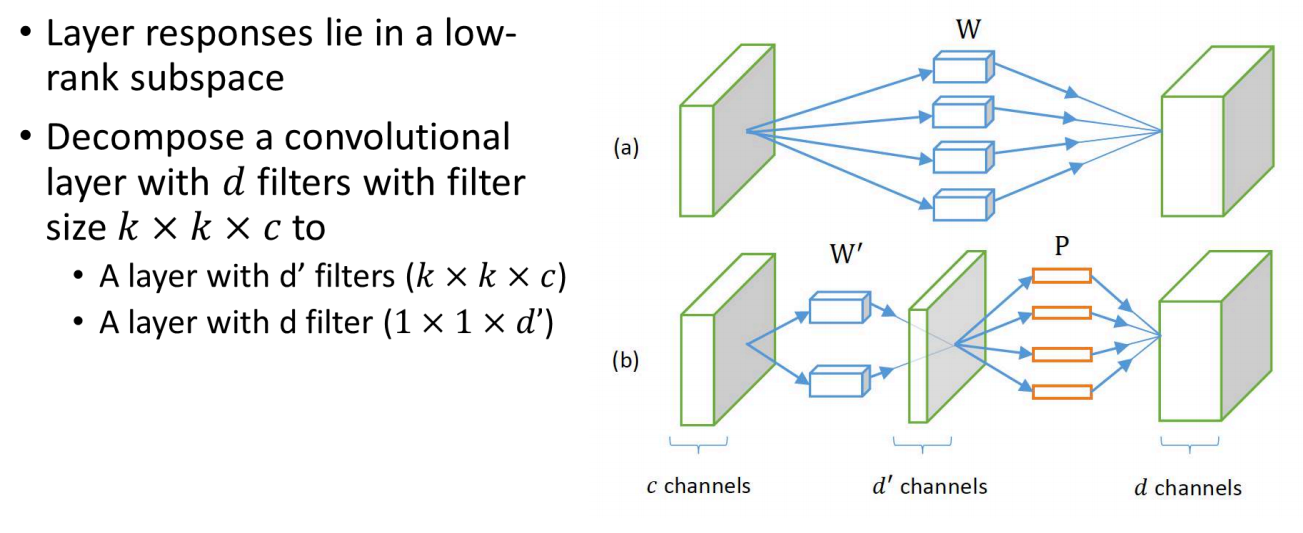
Low Rank Approximation
Binary / Ternary Net
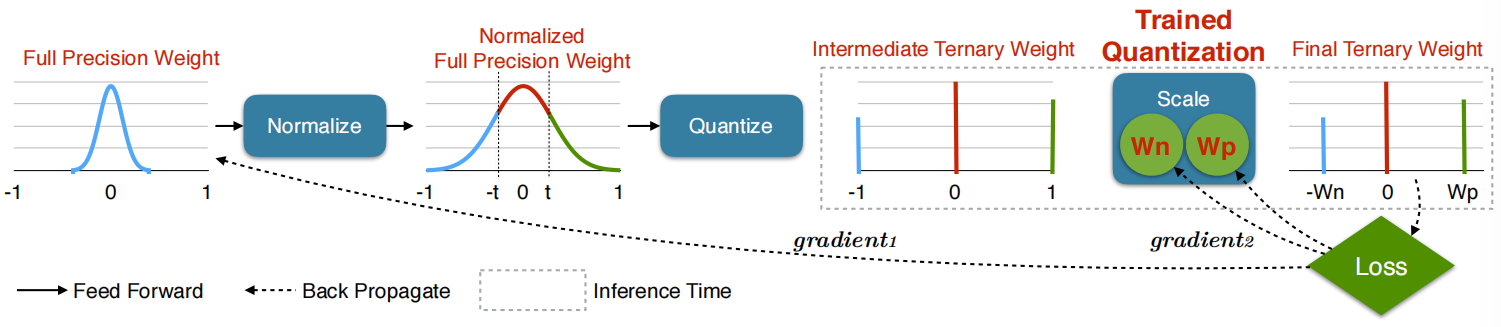
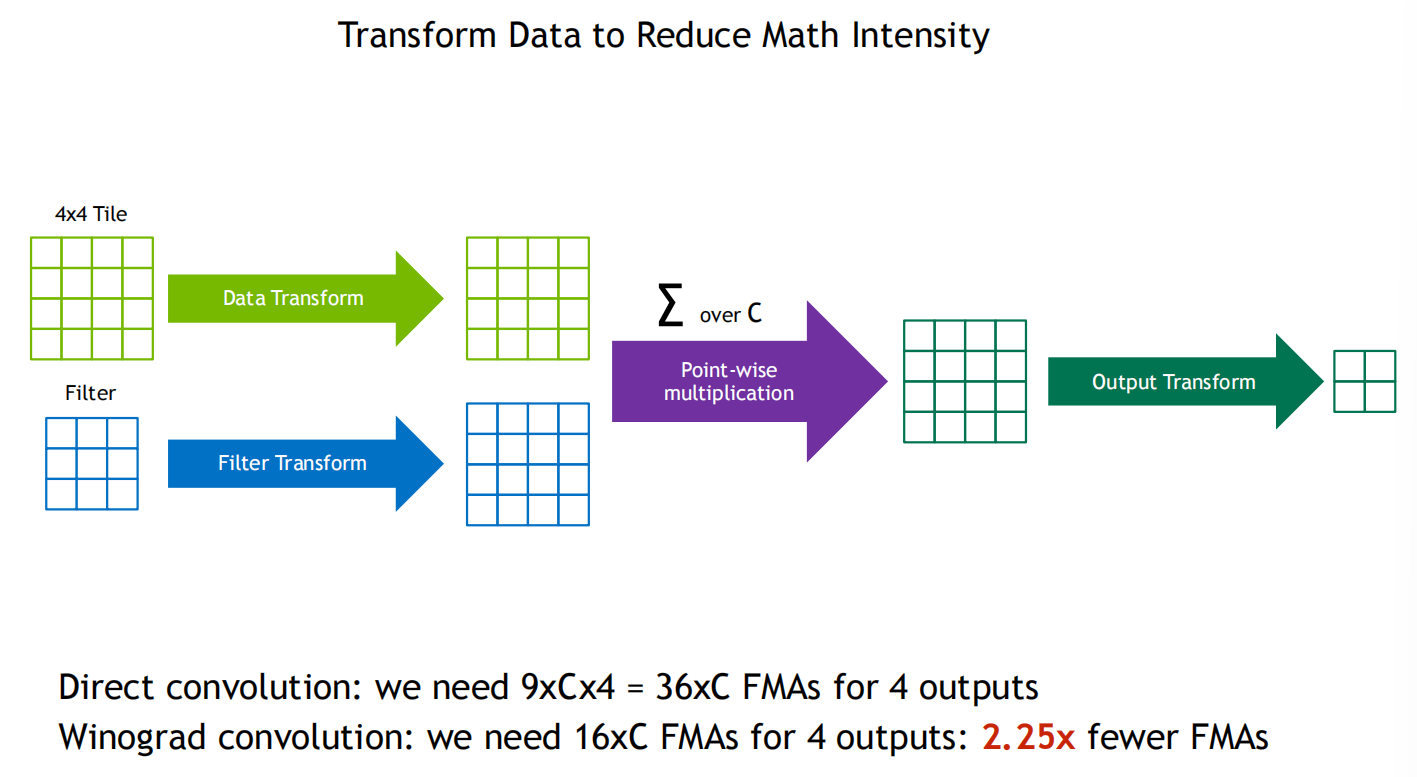
Winograd Transformation
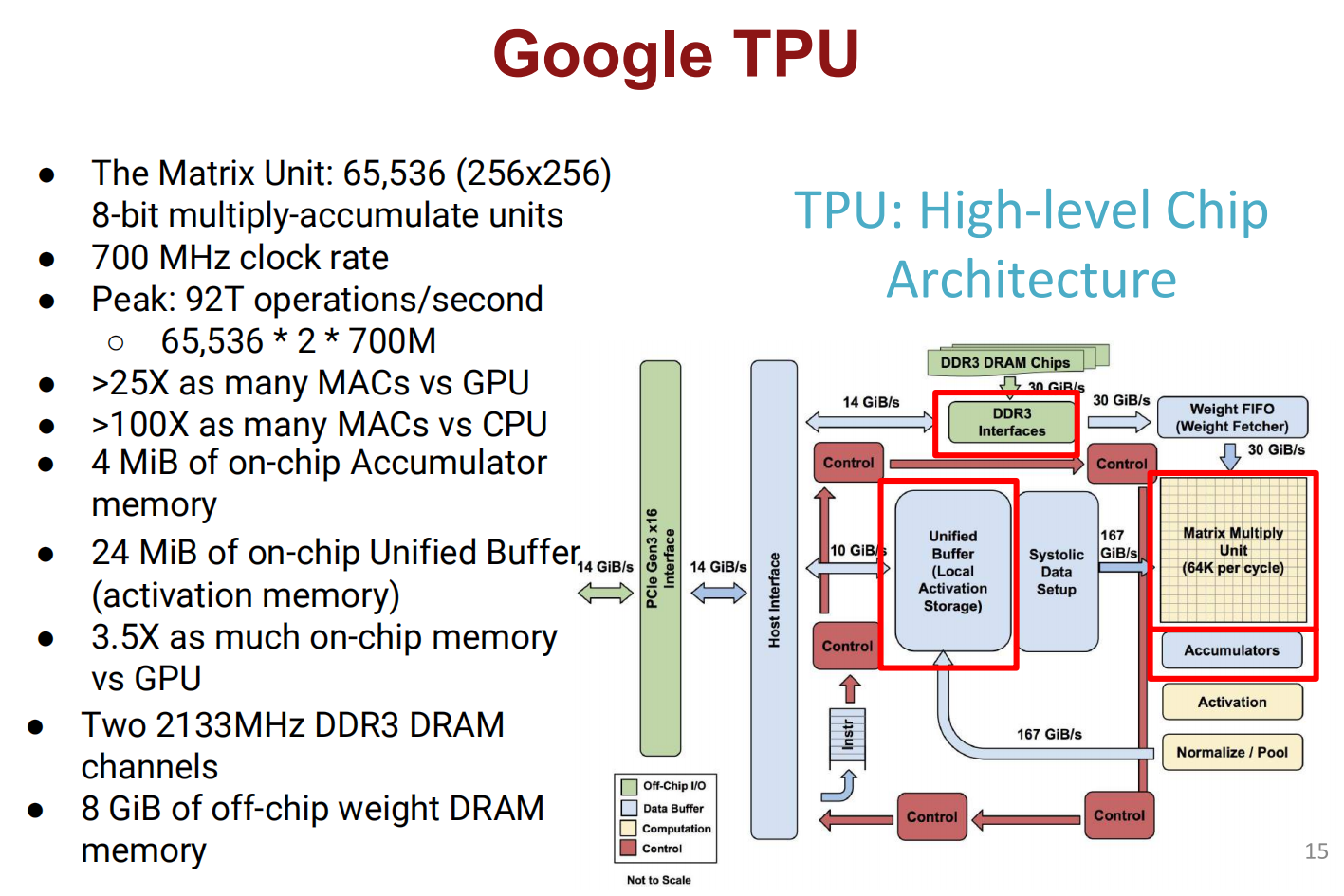
Part 2: Hardware for Efficient Inference
TPU
Part 3: Efficient Training — Algorithms
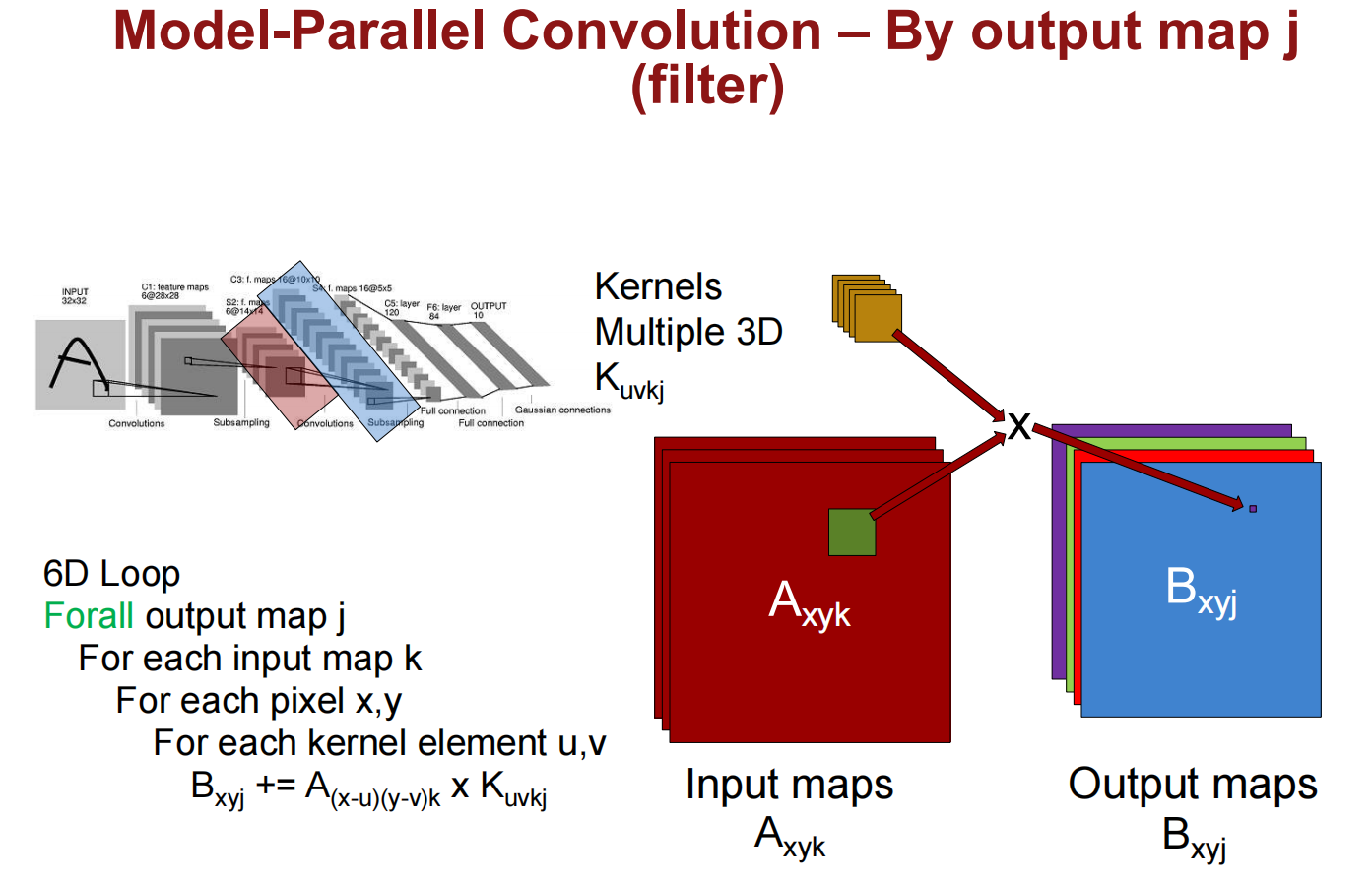
Parallelization

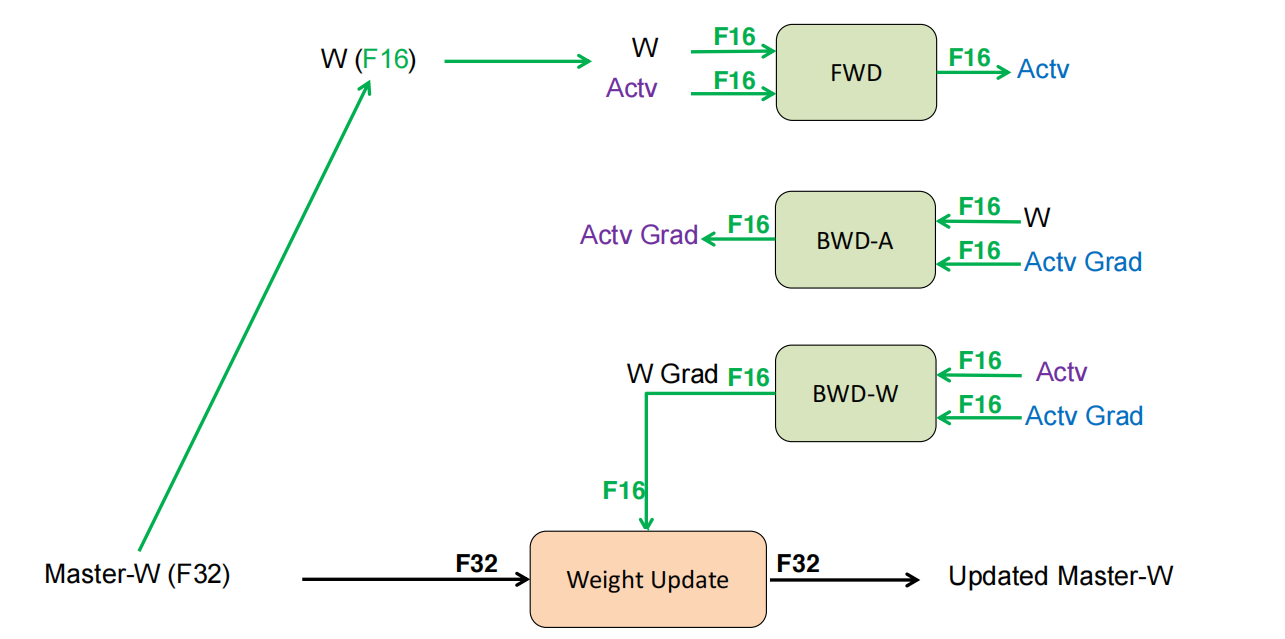
Mixed Precision with FP16 and FP32
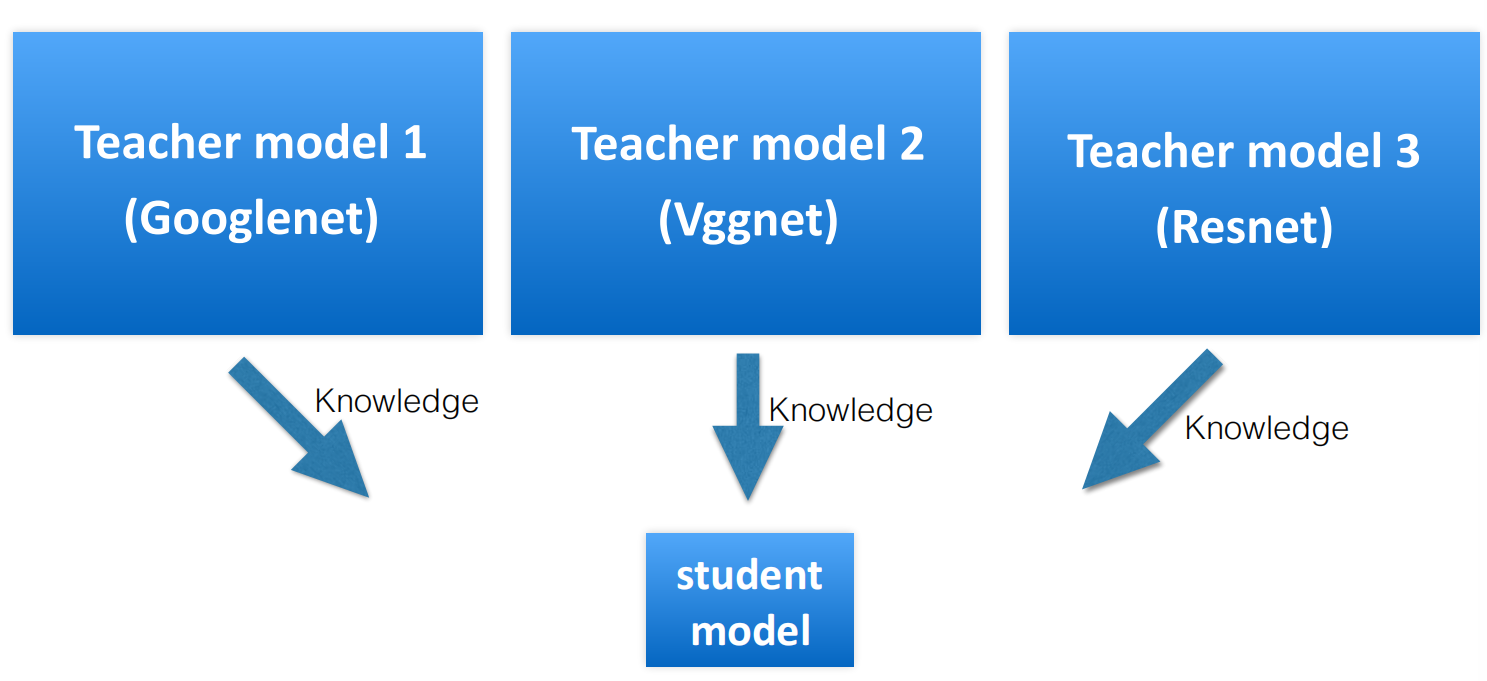
Model Distillation

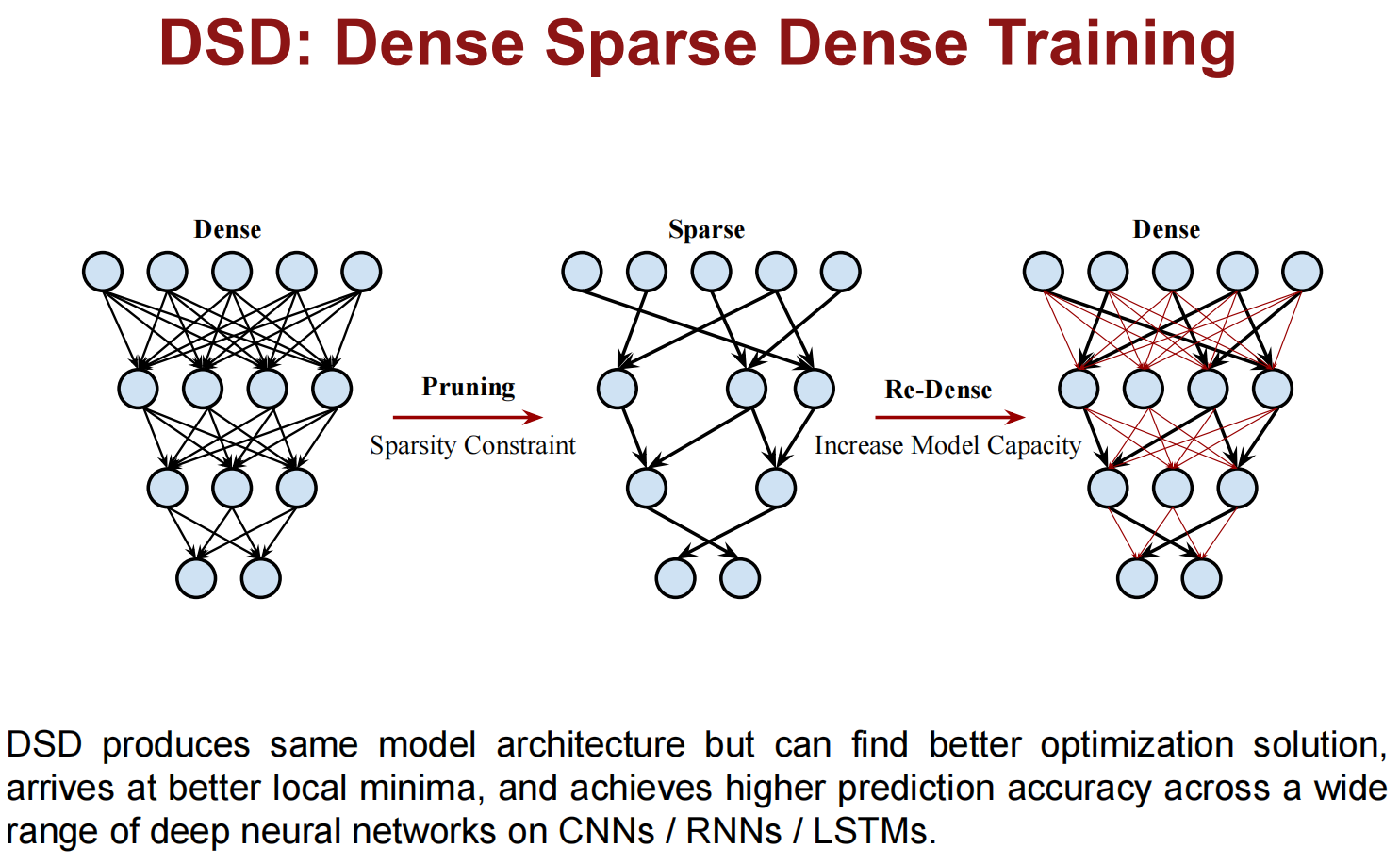
DSD: Dense-Sparse-Dense Training
Part 4: Hardware for Efficient Training
CPU GPU TPU
Lec16 Adversarial Examples and Adversarial Training
AI是很容易被欺骗的。

可能是欠拟合而非过拟合
怎么制造对抗样例:快速梯度符号法 (Fast Gradient Sign Method, FGSM)
扰动L2

构造攻击的模型:


对抗性样本的特性
- 迁移性 (Transferability): 为一个模型生成的对抗性样本,通常也能成功欺骗其他不同架构、甚至在不同数据集上训练的模型。
- 跨模型迁移: 在DNN上生成的样本可以攻击LR、SVM等模型。
- 跨数据迁移: 在不同训练数据子集上训练的相同架构模型之间也存在迁移性。
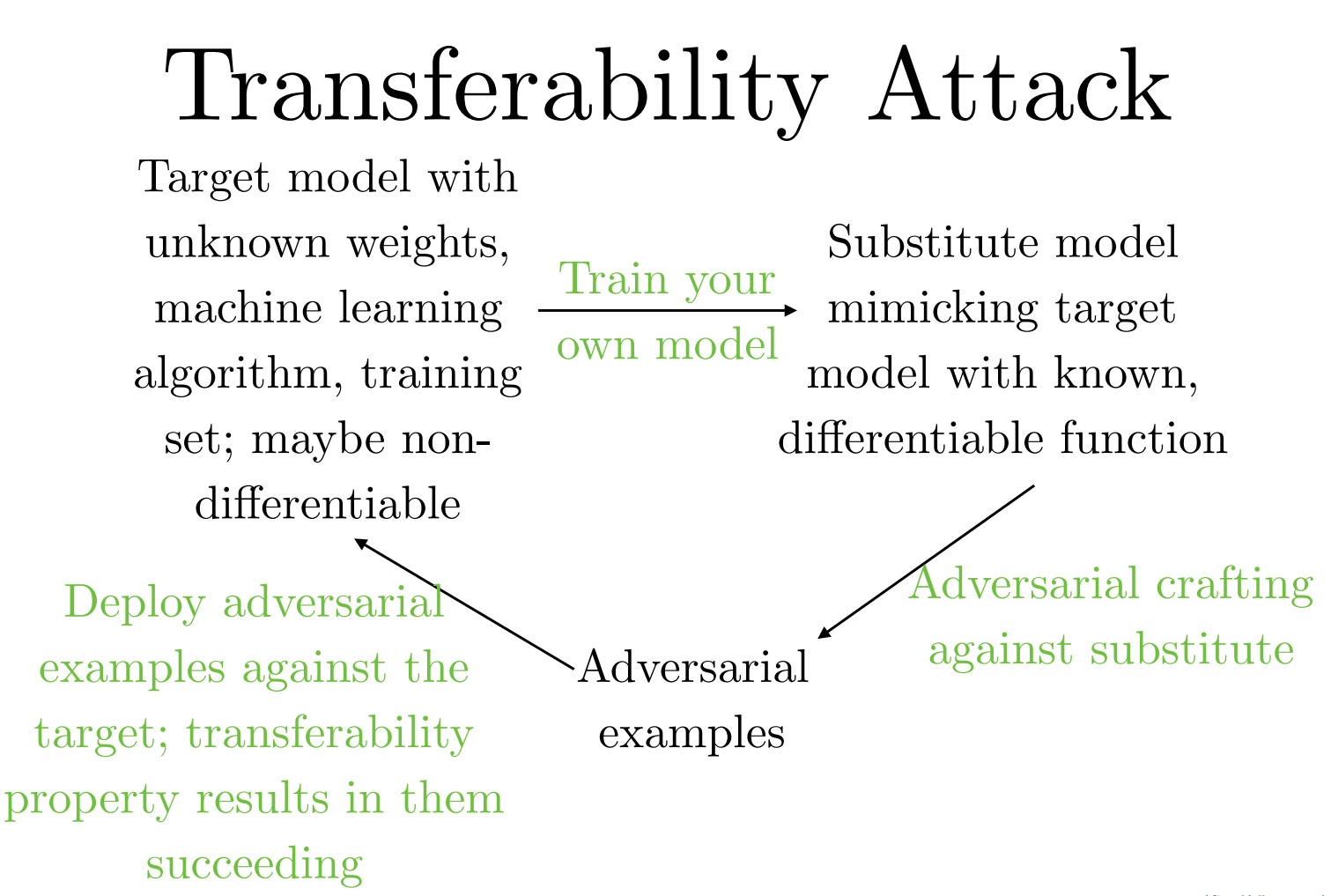
- 黑盒攻击 (Transferability Attack): 利用迁移性,攻击者可以进行黑盒攻击。具体步骤如下:
- 训练替代模型: 攻击者训练一个自己的“替代模型” ,使其功能上模仿未知的“目标模型” 。
- 生成样本: 在已知的替代模型上生成对抗性样本。
- 发起攻击: 将这些样本输入到目标模型中,由于迁移性,攻击很大概率会成功。
- 物理世界攻击: 对抗性样本并非只存在于数字世界。将对抗性图片打印出来,再通过摄像头拍摄,依然可以欺骗机器学习系统,证明了其在物理世界中的威胁。
防御
有效的防御:对抗性训练 (Adversarial Training)
目前最有效的防御手段是在训练过程中引入对抗性样本。
- 核心思想: 将通过FGSM等方法生成的对抗性样本和其对应的正确标签一起加入到训练集中,从而迫使模型学习对这些扰动的鲁棒性。
- 效果:
- 显著降低模型在对抗性样本上的误分类率。
- 它也扮演了一种正则化的角色,有时甚至能提升模型在干净样本上的表现。
- 在所有机器学习模型中,经过对抗性训练的神经网络在防御对抗性样本方面取得了最好的经验性成功率。
- 局限性: 尽管有效,对抗性训练后的模型依然存在弱点,并不能完全解决问题。
半监督学习:虚拟对抗性训练 (Virtual Adversarial Training, VAT)
VAT将对抗性训练的思想扩展到半监督学习领域。
- 核心思想: 对于一个未标记的样本,首先让模型给出一个预测。然后,计算一个对抗性扰动,这个扰动的目标是最大化模型对原样本和扰动后样本预测结果之间的差异。 最后,训练模型,使其对原样本和扰动后样本的预测保持一致。
- 应用: 在文本分类等任务上取得了当时最好的(SOTA)结果。