

This blog is used to note down all the knowledge I’ve learned in this lesson.
Here is some links to this lesson.
CMU 15-418 Home Page ( Spring 2018 version )
I did the projects for Stanford CS149 but not CMU 15-418. But actually, they are similar.
lec01 Why parallelism



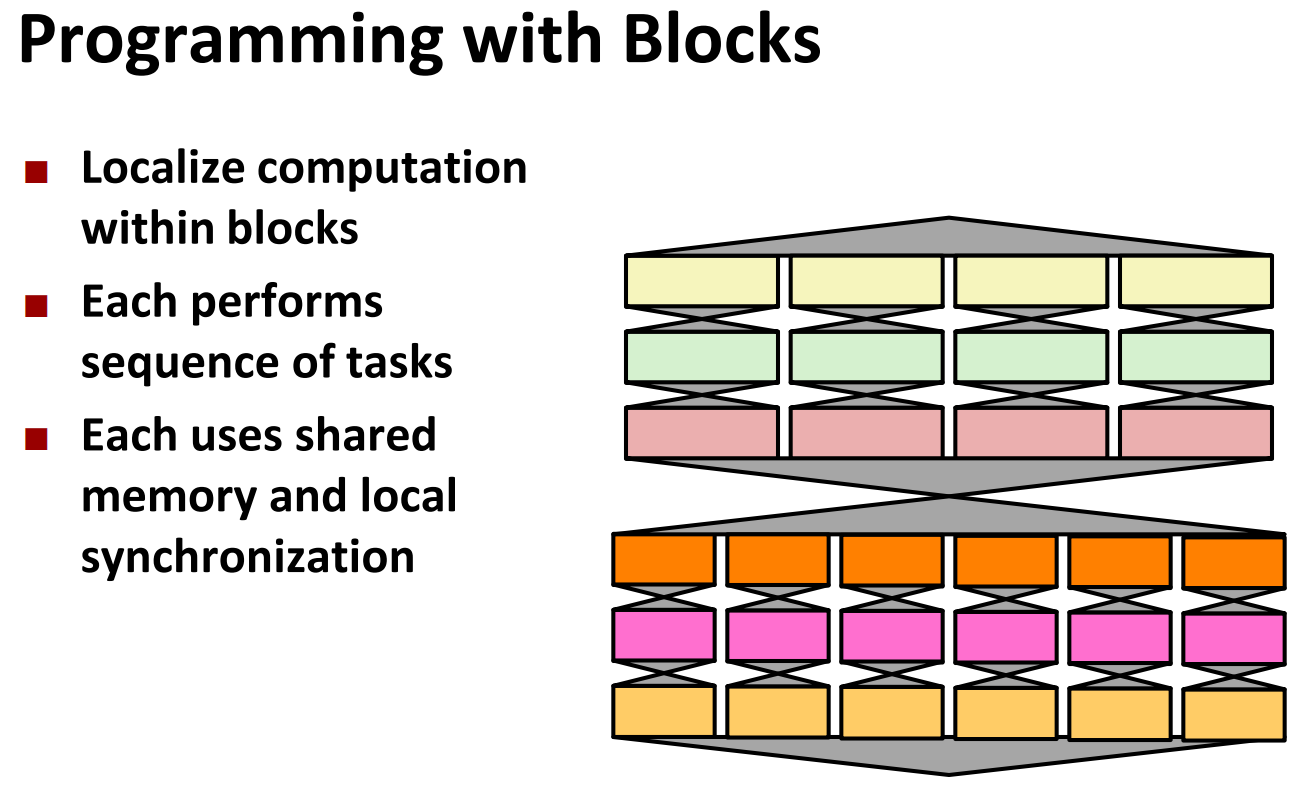
lec02 A Modern Multi-Core Processor
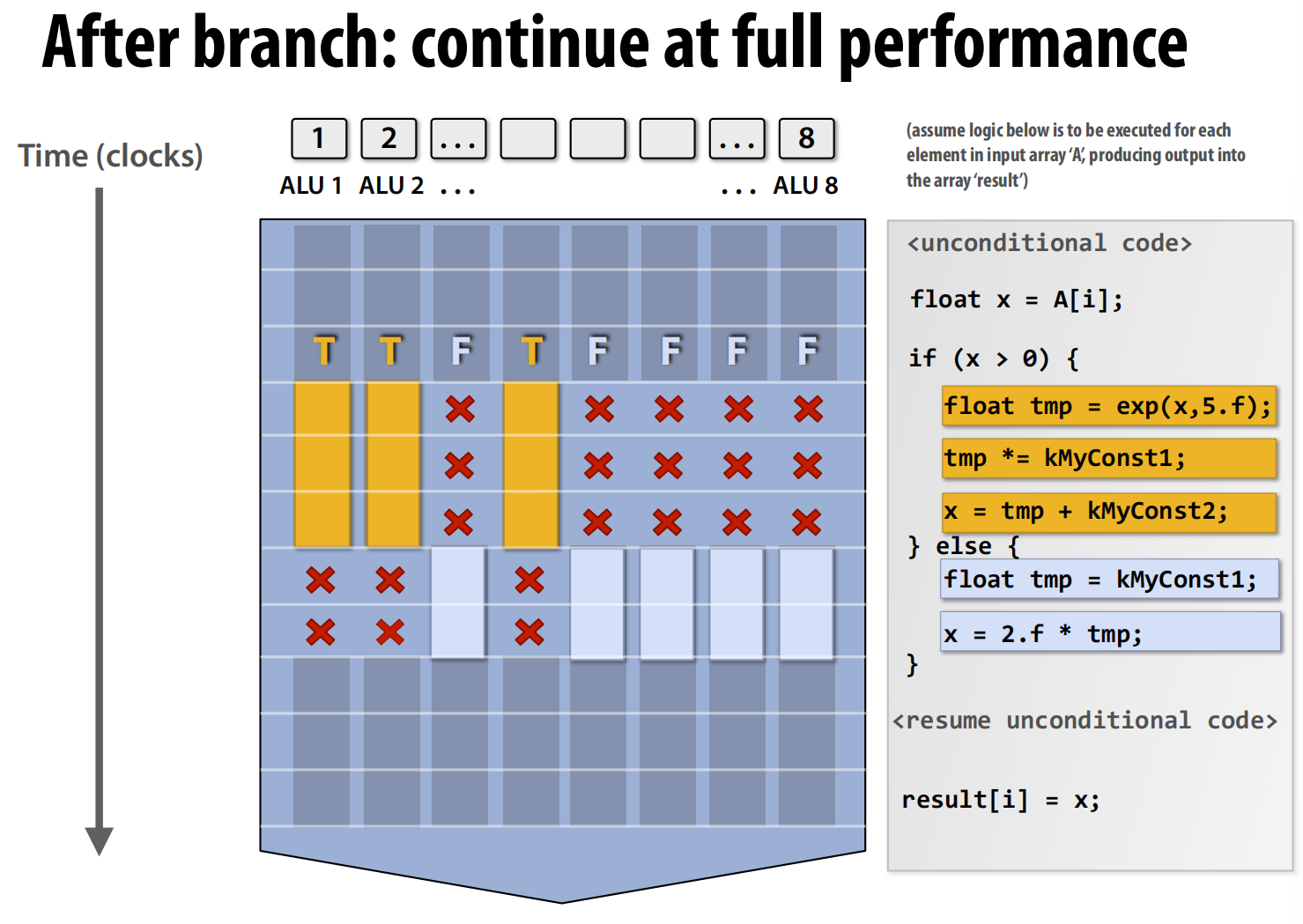
分支会破坏一致性:当处理器执行到 if 语句时,ALU 1, 2, 4 的判断结果为真(T),而其他 ALU 的结果为假(F)。接下来执行 if 代码块内的指令(float tmp = exp(...) 等,图中橙色部分)。由于 SIMD 要求所有单元执行相同的指令,所以当执行 if 块的指令时,那些判断结果为假(F)的 ALU (3, 5, 6, 7, 8) 必须被“屏蔽”掉,不能执行操作(图中用红色的 X 表示它们处于空闲或无效状态)。它们只能等待,直到 if 块执行完毕。
几个关键术语:
- 指令流一致性 coherency:
- 定义: 指的是在同一时刻,所有处理单元(elements)执行完全相同的指令序列。
- 重要性: 对于高效利用 SIMD 处理资源至关重要。SIMD 的设计思想就是用一条指令同时处理多个数据,如果指令流是一致的,那么所有处理单元都能保持忙碌,发挥最大效能。
- 与多核并行的区别: 它强调了这与多核(multi-core)并行不同。在多核处理器中,每个核心(core)都有自己独立的取指/解码单元,可以运行完全不同的程序(指令流),因此它们之间不需要指令流一致性。
- 分支发散 (Divergent execution):
- 定义: 指缺乏指令流一致性的情况。当程序中出现条件分支(如
if-else语句),并且不同的数据导致需要执行不同的分支时,就会发生这种情况。
- 定义: 指缺乏指令流一致性的情况。当程序中出现条件分支(如
| 特性 | 多核 (Multi-core) | 单指令多数据流 (SIMD) | 超标量 (Superscalar) |
|---|---|---|---|
| 并行位置 | 核心之间 (Inter-core) | 核心内部 (Intra-core) | 核心内部 (Intra-core) |
| 并行对象 | 不同的指令流 (线程) | 同一指令,不同数据 | 同一指令流,不同指令 |
| 并行粒度 | 粗粒度 (线程级) | 中等粒度 (数据级) | 细粒度 (指令级) |
| 谁来管理 | 软件 (程序员) | 编译器 / 程序员 / 硬件 | 硬件 (对程序员透明) |
Stall
等待内存可用
Prefetching reduces stalls (hides latency)
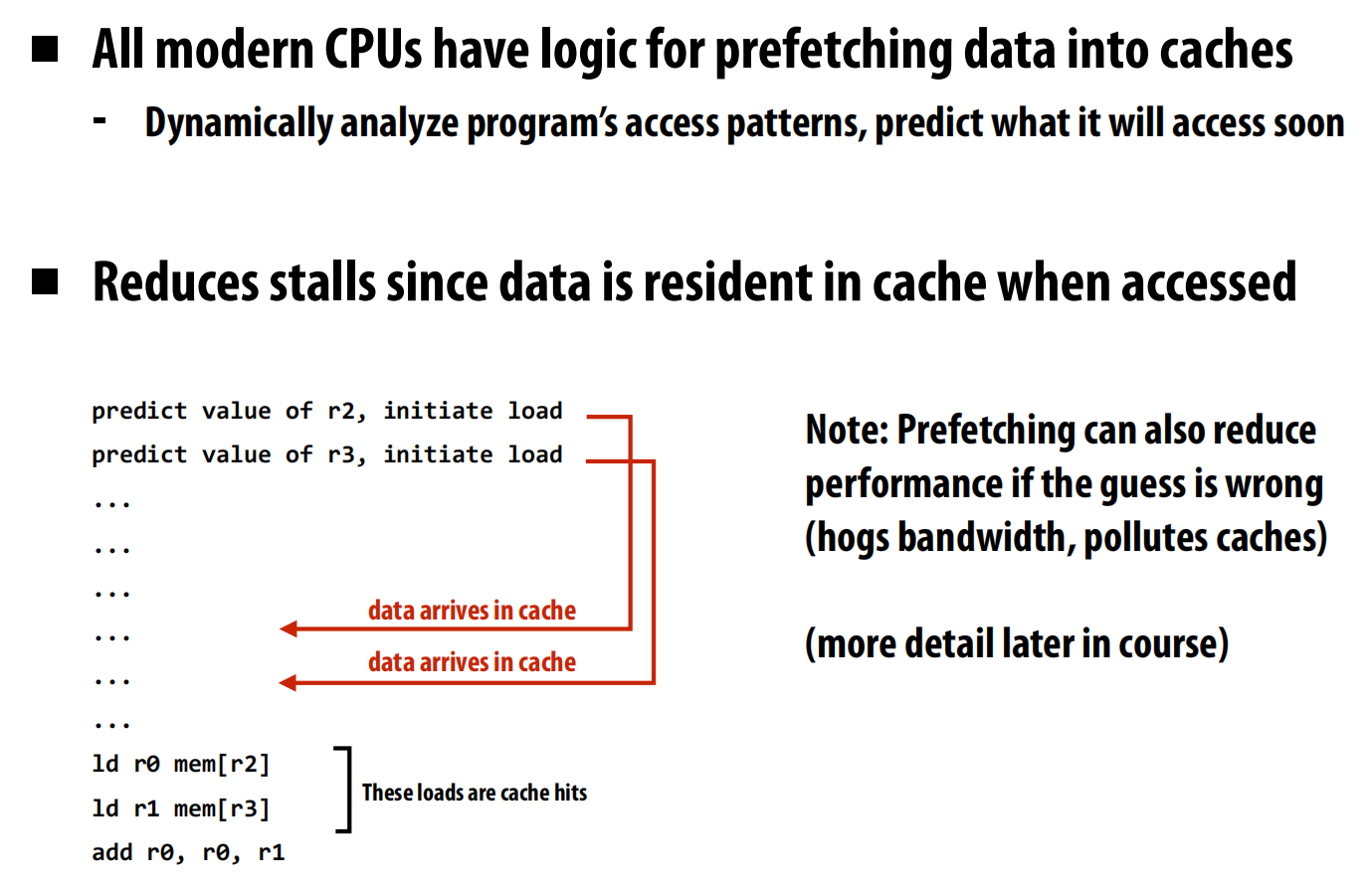
Multi-threading reduces stalls
体系结构有讲
lec03 Parallel programming models
ISPC编程。SPMD:single program multiple data
交错:interleaved

分块:

智能:foreach,编译器帮我做

第一种:
第二种:


将一个相同的函数或操作,应用到一个数据集合的所有元素上 。ISPC 的 foreach 就是一个例子 。

lec04 Parallel Programming Basics
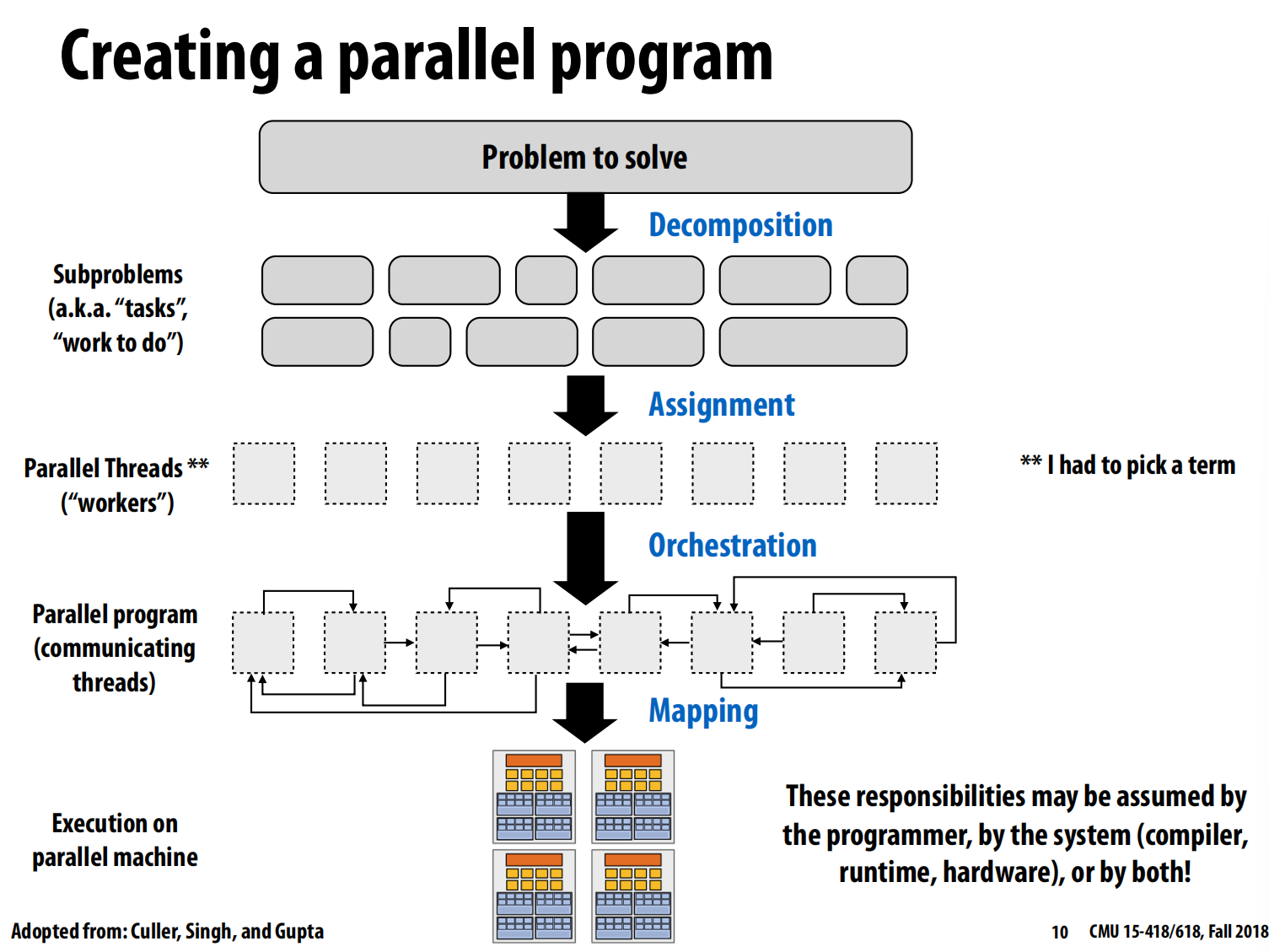
分解,分配,协调,映射


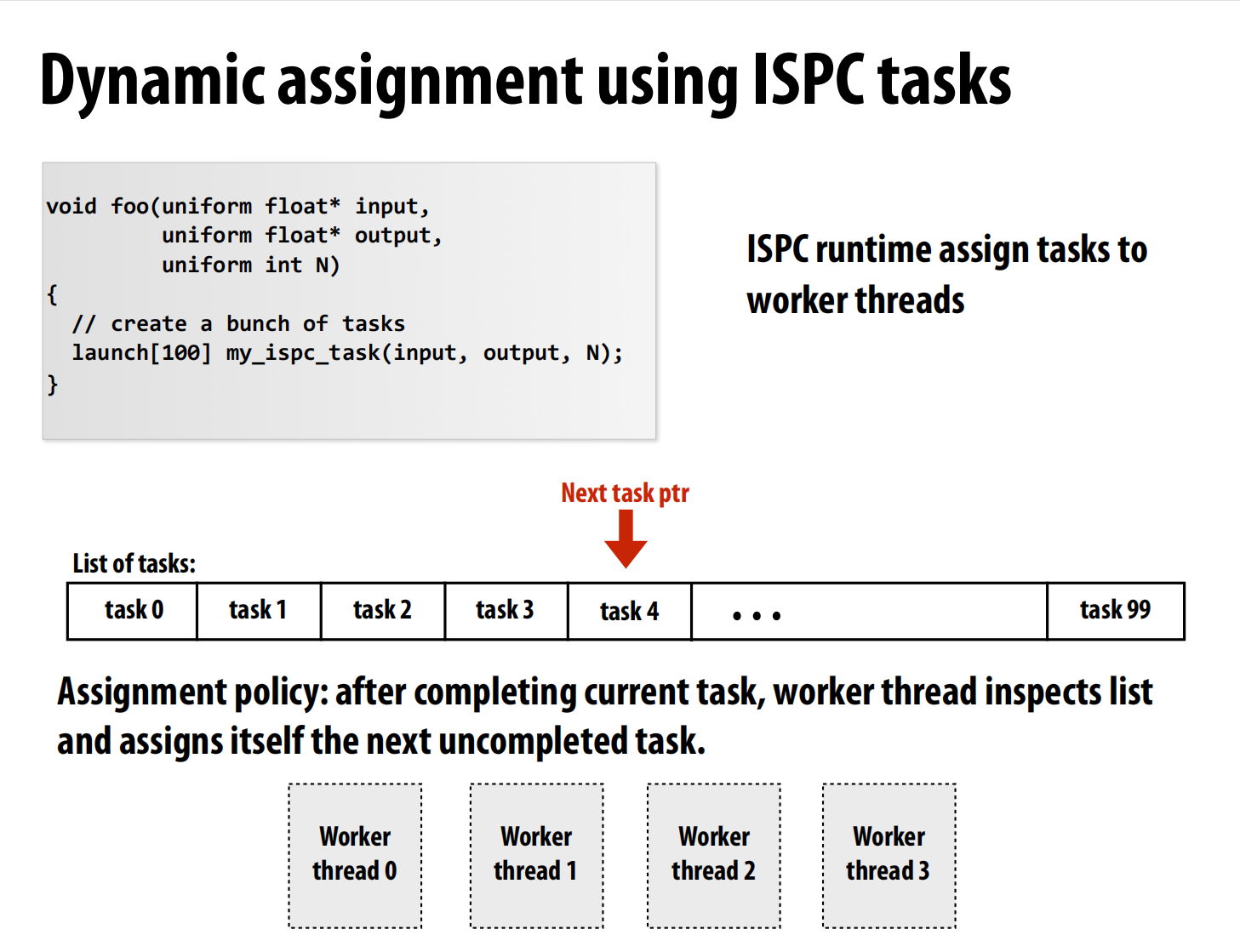
静态分配可能不能很好的分配(有些快,有些慢)->动态分配:把所有任务想象为一个队列,一个线程取出一个任务做,做完之后取下一个。

提高性能:1.局部加和,线程的最后一次性的加到总和里
设置屏障:


减少信息传递:

只传一次(send,recv)传一行下去/上去

但是,如果同时发送接收,会死锁:我在发送,那我的就锁了,别人也在发,等着他人收,只有别人收了我的锁才释放,我才能收。每个人都在等着别人收我的->死锁。
修改->奇数行先发,偶数行后发
lec05 Work distribution and scheduling
静态分配Static assignment:每个工作量差不多的时候这样做
半静态Semi-static assignment:当数据变化的很慢的时候可以每隔一段时间重新分配一次,每次分配下去之后静态运行一段时间
动态分配Dynamic assignment:用一个队列存,每次每个线程去里面拿。
问题一:如果队列里的最后一个任务很大,导致分配不均怎么办?ans:预先估计大小,大的放前面
问题二:大家不停地拿,要是队列很长,每个任务很小,会导致队列的锁不停地被取,产生排队?ans:合并小的变为大一些的(打包),一次多拿点
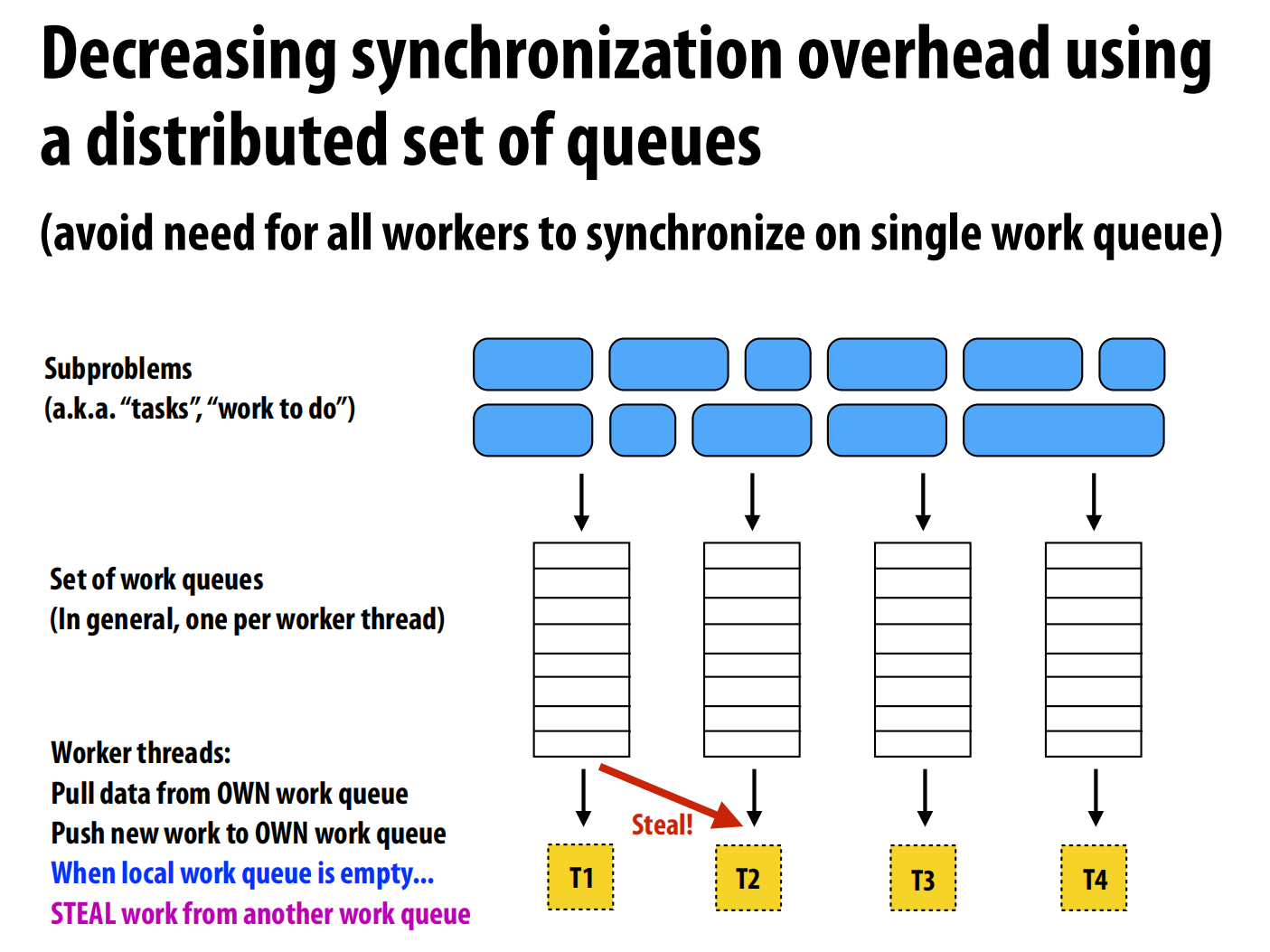
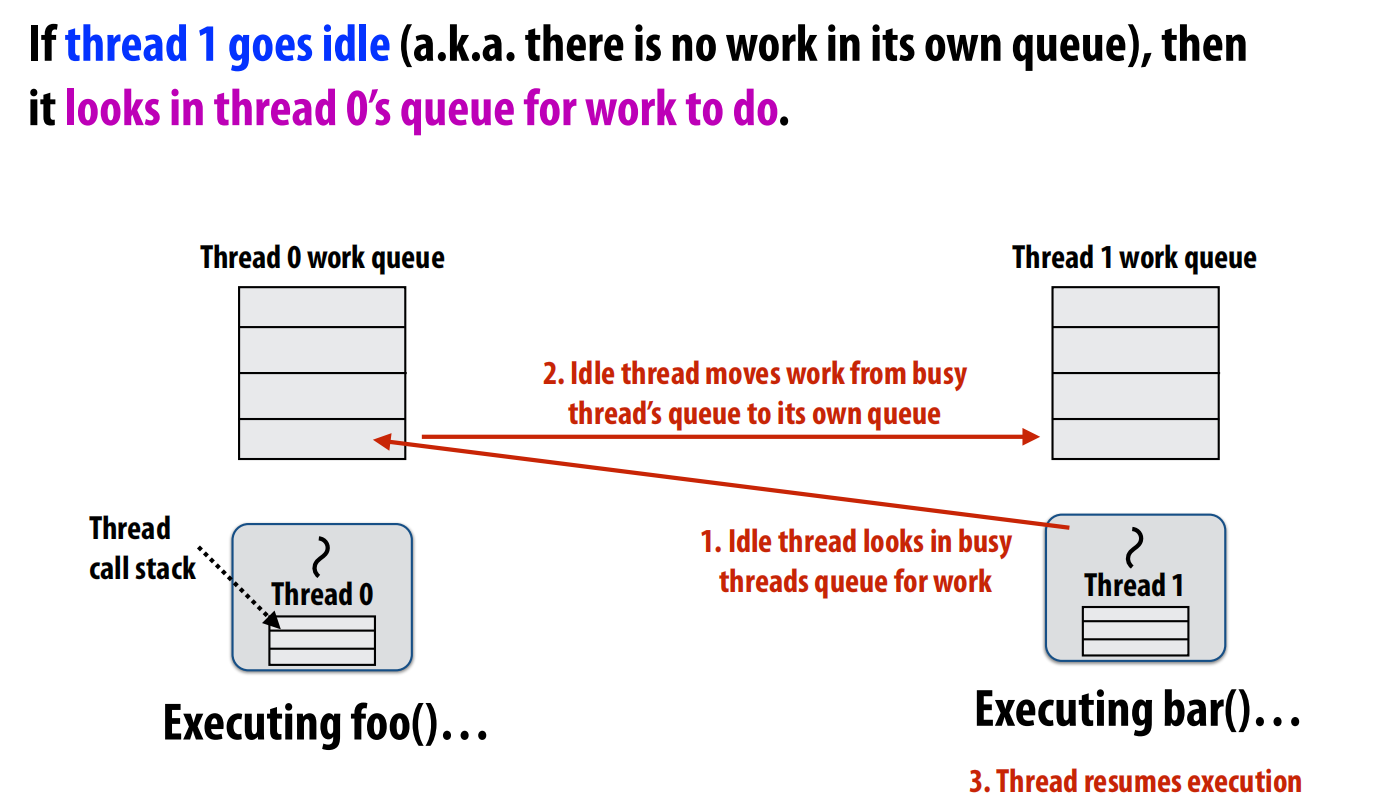
问题三:(另一个方案):首先先估计每个任务的时间之后分成4个队列。每个人先从自己的队列里取,这样就根本的防止了大家一起在队列里拿的问题。当有人做完了自己队列的任务之后,从他人的队列里“steal”一点来做。
第二部分内容:Scheduling fork-join parallelism
解决分治的并行问题
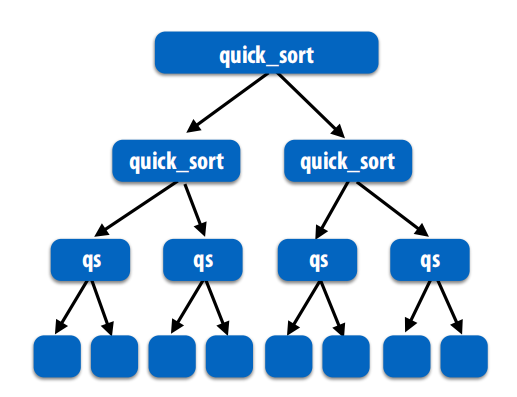

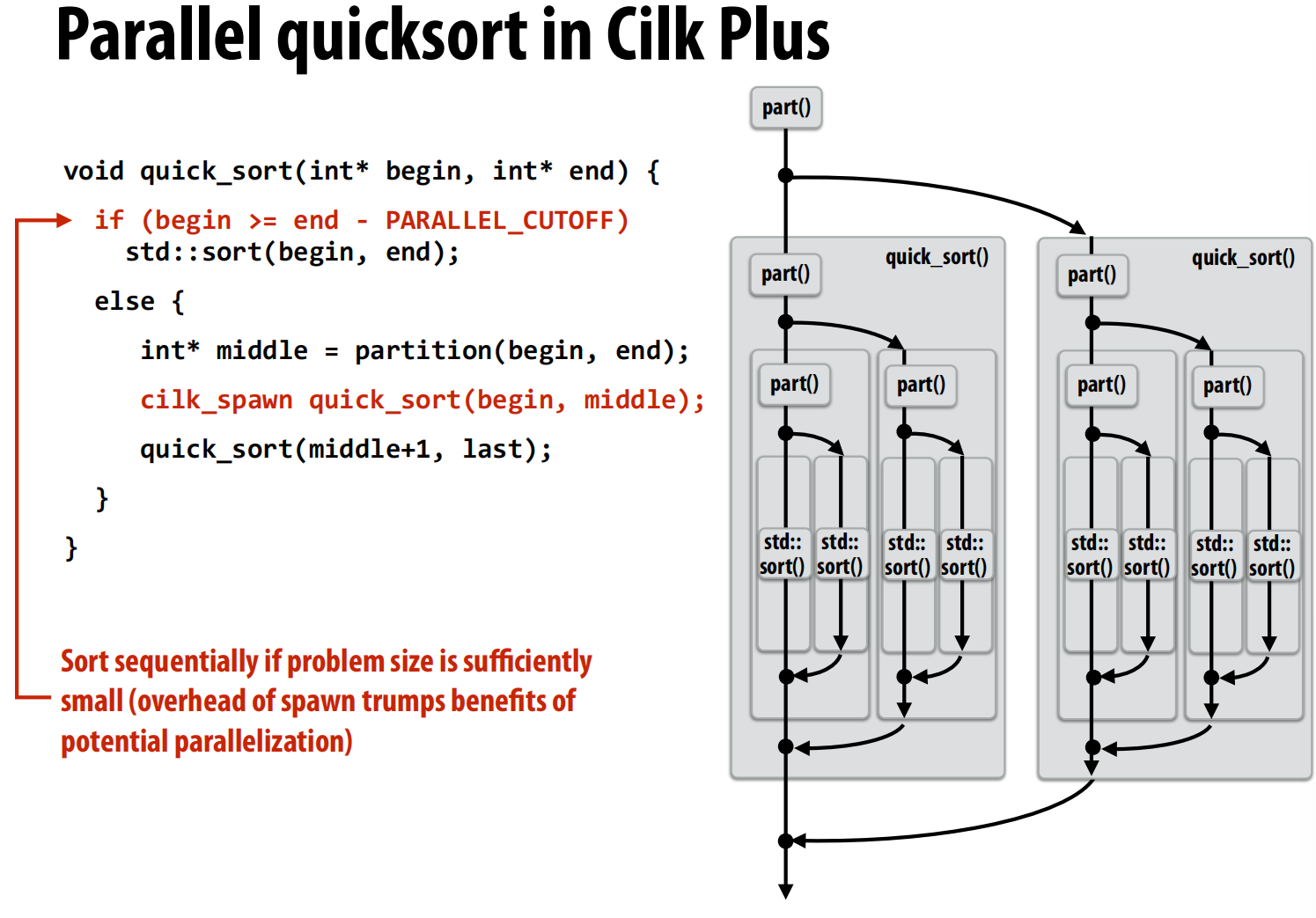
cilk_spawn:分出去一个线程。cilk_sync:合起来
在快排的时候,注意当线程数量足够多的时候就没必要再细分了,否则可能反而导致性能下降
cilk是生成,告诉系统有潜在的并行性,而非创建,线程不够就不会创建。
在运行到这一行的时候,我们现在的线程是该运行子任务还是继续做之前的延续呢?
子任务窃取 (Child Stealing):父任务优先,把子任务留给别人,放到队列里等着别人窃取。
延续窃取 (Continuation Stealing):子任务优先,把父任务的“后半辈子”留给别人。
考虑在以下情形中:
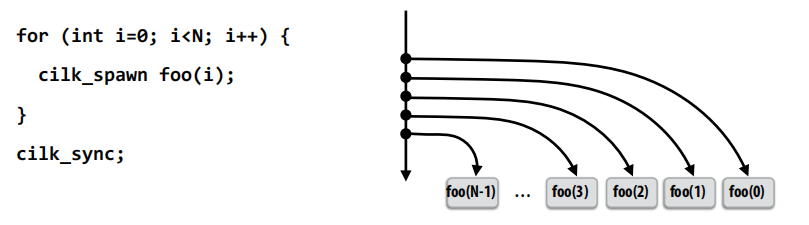
第一种:

那我就直接循环完了,把所有子任务都放到了队列里,这看似不错,然后别人想要也可以来拿
第二种:

我要把foo(0)之后才能继续,所以此时我的队列里只有一个事(后n-1次循环),而且这个事情如果被别人拿了我就没事情做了。
但是——第一种会填满队列,放很多很多东西。这通常是不好的。所以我们更愿意做第二种——先处理子任务。
下一件事情:在cilk_sync时,我要确保所有线程都做完了(这个用一个数据结构存),那我在哪个线程上继续做呢?贪心的想法是,我在最后一个结束任务的线程上做,这样我就只需要在这个线程结束任务的时候确认——欧,别人都已经做完了,就剩我了,那我就继续做吧~这样的效率更高。
Recitation ILP, SIMD instructions
1 | ls /proc |
lec06 Graphic processing units and CUDA
GPU
CUDA编程:


讲解:
1. 主机端代码 (Host Code)
const int Nx = 12; const int Ny = 6;- 定义了我们要处理的数据规模,这里假设是一个 12x6 的矩阵。
dim3 threadsPerBlock(4, 3, 1);- 定义线程块 (Block) 的维度。
dim3是一个 CUDA 的数据类型,通常用来表示三维的维度。 - 这里我们定义每个线程块包含 4x3=12 个线程。你可以把它想象成一个小的线程网格。
- 定义线程块 (Block) 的维度。
dim3 numBlocks(Nx/threadsPerBlock.x, Ny/threadsPerBlock.y, 1);- 定义网格 (Grid) 的维度,也就是需要多少个线程块。
Nx / threadsPerBlock.x->12 / 4 = 3Ny / threadsPerBlock.y->6 / 3 = 2- 所以,整个任务会被划分为一个 3x2=6 个线程块的网格。
matrixAdd<<<numBlocks, threadsPerBlock>>>(A, B, C);- 启动核函数 (Kernel Launch)。
matrixAdd是我们想在 GPU 上运行的函数的名字(即核函数)。<<<...>>>是 CUDA 特有的语法,用于指定执行配置:- 第一个参数
numBlocks:告诉 GPU 我们要启动 6 个线程块。 - 第二个参数
threadsPerBlock:告诉 GPU 每个块里有 12 个线程。
- 第一个参数
- 这个调用会触发 GPU 总共启动 6 * 12 = 72 个 CUDA 线程。
(A, B, C)是传递给 GPU 核函数的参数,通常是指向 GPU 内存中数据的指针。- 这个调用是异步的,CPU 发出指令后会立即返回,不会等待 GPU 计算完成。
2. 设备端代码 (Device Code) - CUDA 核函数定义
这部分展示了真正在 GPU 上成千上万个线程具体执行的代码。
__global__ void matrixAdd(...)__global__是 CUDA 的一个关键字,表示这个函数是一个核函数,它可以在 CPU 上被调用,但在 GPU 上执行。void表示这个函数不向 CPU 返回值。计算结果会直接写在 GPU 的内存里(例如写入到 C 数组中)。
- SPMD (Single Program, Multiple Data) 执行模型
- 这是 CUDA 的核心理念之一。意思是同一个程序(核函数代码),会被许多个不同的线程执行,每个线程处理不同的数据。
- 线程索引计算
int i = blockIdx.x * blockDim.x + threadIdx.x;int j = blockIdx.y * blockDim.y + threadIdx.y;- 这是核函数内部最核心的部分。每个线程启动后,都会有自己唯一的身份标识:
threadIdx: 线程在其所在块 (Block) 内的索引(ID)。blockIdx: 线程块在整个网格 (Grid) 中的索引(ID)。blockDim: 线程块的维度(大小),在我们这个例子中是 (4, 3, 1)。
- 通过这几个内置变量,每个线程可以计算出自己需要处理的数据在全局内存中的唯一位置 (overall grid thread id)。例如,第
(i, j)个线程就负责处理矩阵中(i, j)位置的数据。
C[j][i] = A[j][i] + B[j][i];- 所有 72 个线程会同时执行这行代码,但每个线程计算的
i和j都不同。 - 因此,它们会各自读取 A 和 B 矩阵中不同位置的元素,相加后,存入 C 矩阵的对应位置。这就实现了矩阵加法的大规模并行计算。
- 所有 72 个线程会同时执行这行代码,但每个线程计算的
可以不是线程数的倍数:多的线程不做事就行了:

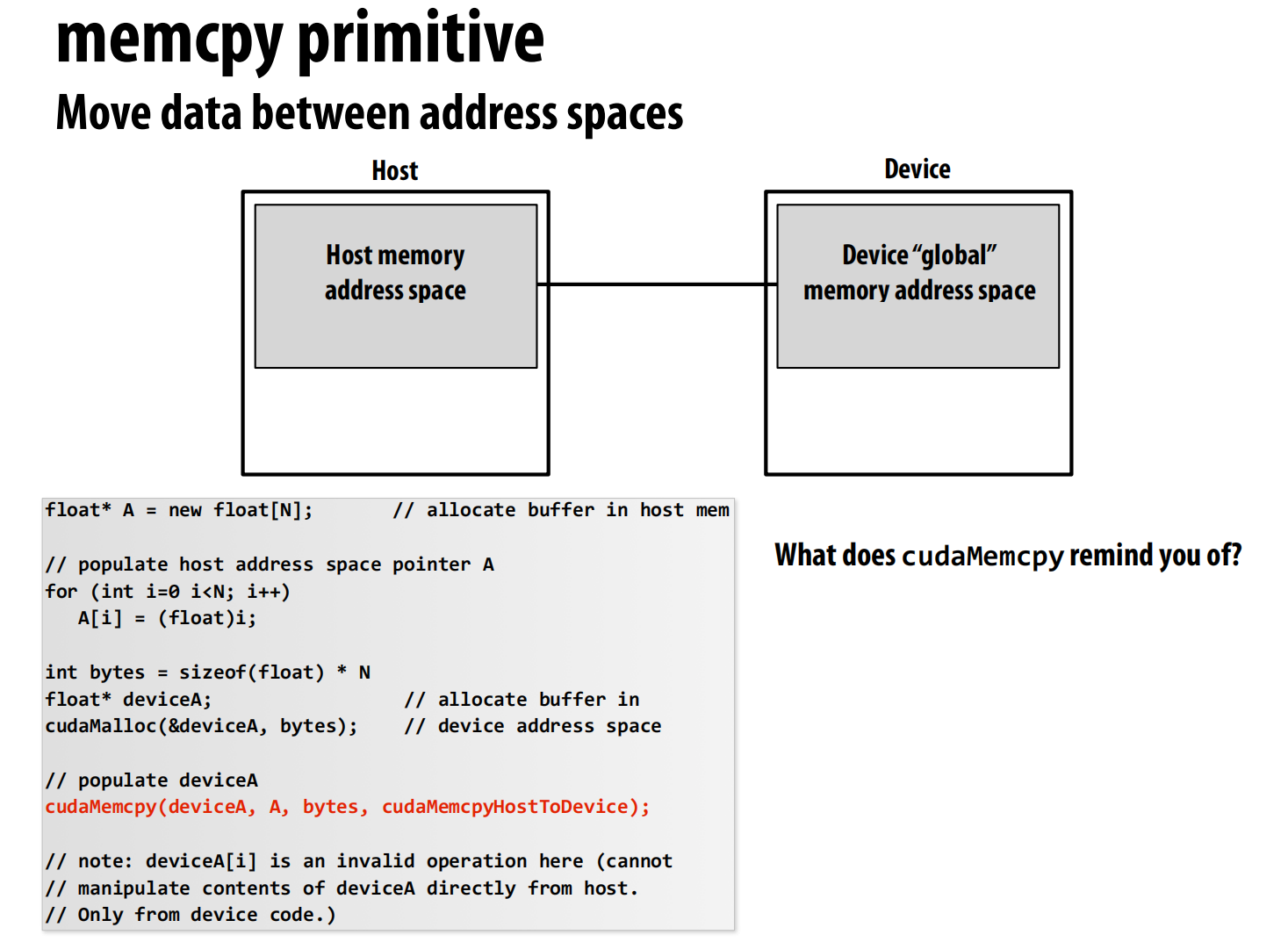
memcpy 原语 - 在主机和设备间移动数据
如何移动数据。
首 CPU (主机, Host) 和 GPU (设备, Device) 拥有各自独立的物理内存。
图中的代码演示了将数据从 CPU 传输到 GPU 的标准流程:
-
在主机 (Host) 上分配内存
1
float* A = new float[N];
-
在设备 (Device) 上分配内存
1
2float* deviceA;
cudaMalloc(&deviceA, bytes);cudaMalloc是 CUDA 版本的malloc。- 它在 GPU 的全局内存 (Global Memory) 中分配指定大小(
bytes)的空间。 deviceA是一个指向 GPU 内存地址的指针。
-
执行内存复制
1
cudaMemcpy(deviceA, A, bytes, cudaMemcpyHostToDevice);
cudaMemcpy是实现数据传输的“桥梁”函数。deviceA: 目标地址 (Destination),这里是 GPU 上的内存指针。A: 源地址 (Source),这里是 CPU 上的内存指针。bytes: 要复制的数据大小。cudaMemcpyHostToDevice: 传输方向的标志。
- 在主机代码中,你不能直接通过
deviceA指针去访问或修改 GPU 上的数据。
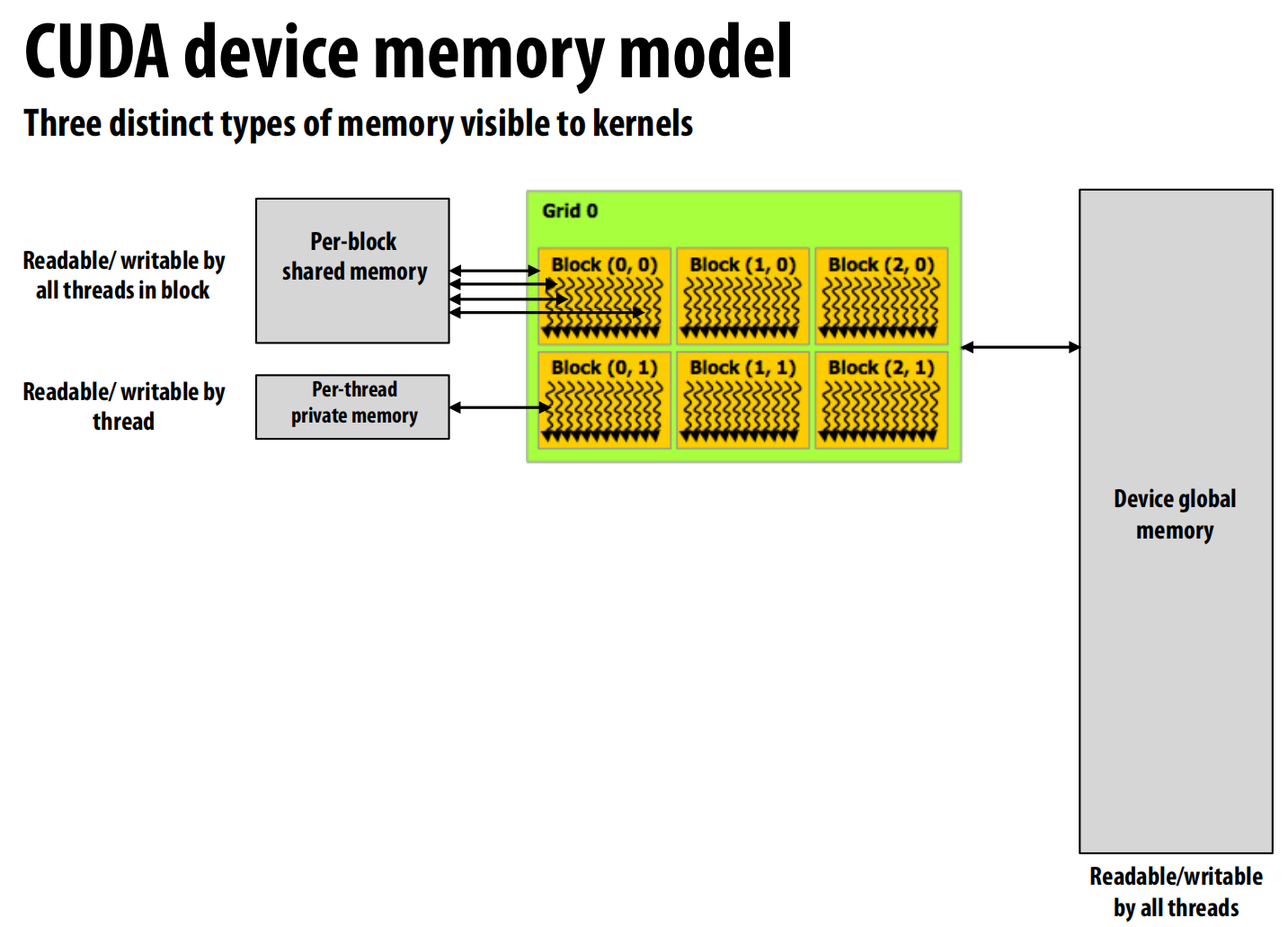
GPU 内部分层的内存结构。
-
设备全局内存 (Device Global Memory)
-
每块共享内存 (Per-block Shared Memory)
-
每线程私有内存 (Per-thread Private Memory)
这样的内存可以局部缓解CUDA没有缓存这个缺点,利用共享内存加速读取:
下方代码实现了对于一个数组,对于每三个连续的数取平均值这一功能。
下方代码中的__shared__就是共享的内存。__syncthreads是一个屏障,意味着没有线程会在所有线程都到达这里之前跨越这个屏障。

CUDA的同步性有以下这些内容:
第一个是CUDA线程之间的同步,第二个是保证对于同一内容的写入,第三个是返回host的时候会确保所有的CUDA线程都已完结。


线程块 (Thread Block): 程序员组织线程的基本单位。一个块内的所有线程可以相互协作,例如通过**共享内存(Shared Memory)**进行通信和数据交换,还可以进行同步。
流式多处理器 (SMM): GPU的计算核心单元,可以看作是GPU内部一个独立的处理器。一个线程块(Thread Block)会被调度到一个SMM上执行,并且在执行期间不会被迁移到其他SMM。
Warp (线程束): 这是GPU硬件执行的基本单位,不是程序员直接控制的抽象。一个Warp由 32个 连续的线程组成。SMM以Warp为单位来调度和执行指令。幻灯片中提到,我们定义的128个线程的块,会被硬件自动划分为 128 / 32 = 4 个Warp来执行。
SPMD (Single Program, Multiple Data): 单一程序,多份数据。这是CUDA的编程模型。同一个线程块中的所有线程(以及所有Warp)都执行相同的代码(内核函数),但每个线程都有自己独特的ID(threadIdx),因此可以处理不同的数据。
Warp 0 到 Warp 63: 这表示一个SMM上可以同时“驻留”(Resident)最多64个Warp。这些Warp包含了它们的执行上下文(程序计数器、寄存器等),总共占用了256KB的寄存器文件。
Warp Selector (Warp选择器): 这是SMM中的硬件调度器。在每个时钟周期,它会从所有“准备就绪”(Runnable)的Warp中选择一个或多个(图中显示最多可以选择4个)来执行指令。
延迟隐藏 (Latency Hiding): 为什么要有这么多驻留的Warp?假设Warp 0正在执行一条从全局内存读取数据的指令。内存读取非常慢,需要几百个时钟周期。此时,Warp 0会进入“等待”状态。Warp选择器不会干等着,而是立刻切换到另一个准备就绪的Warp(比如Warp 5)去执行它的指令。这样,计算单元就始终保持在工作状态,从而隐藏了内存访问的延迟,极大地提高了GPU的利用率。这就是所谓的线程级并行(Thread-Level Parallelism, TLP)。
Recitation CUDA programming 1
首先是一些编程的vocabulary和syntax:
Vocabulary
CPU: A central processor unit, i.e. a normal processor
GPU: A graphics processing unit, i.e. what we are learning about
Host: The “normal computer” to which the GPU is connected
▪ Of especial note are the CPU(s) and memory
Device: The GPU and its memory
CUDA: Compute Unified Device Architecture. nVidia’s framework for utilizing their GPUs for general purpose programming
OpenCL: Open Computing Language. The “generic version”
Global memory: Device memory shared across the various blocks
▪ CUDAMalloc(), CUDAMemcpy(), CUDAFree()
Shared memory: Memory shared only by threads within the associated block (not across blocks)
▪ __shared__
Kernel: The work, written as a function, to be parallelized across the GPU’s cores.
Thread: An abstraction for the work associated with an instance of the kernel.
Thread Block: A partition of threads and associated work that will be dispatched to a Streaming Media (SM)
processor, basically a GPU.
Block: See Thread Block
Grid: Set of all blocks
CUDA Core: A single graphics processor core. Within the CUDA architecture, these aren’t one-offs, but architected into Streaming Multiprocessors (SMs).
Streaming Multiprocessor (SM): A collection of CUDA Cores architected together to form a single GPU. Threads within a thread block concurrently execute on an SM.
Warp: A division of a block created within the SM to assign work to cores. Warps aren’t schedule until a core is available for each thread within the warp.
Syntax
nvcc: nVidia C compiler. Can compiler host and device code.
shared : Qualifier to declare a variable in shared (per thread block) memory
global: Qualifier to place a function into device memory, for execution onto the device, but enabling it to be callable from the host.
cudaMalloc() , cudaMemcpy(), cudaFree()
▪ Allocates, Frees, and copies to/from device memory.
▪ cudaMemcpyHostToDevice/cudaMemcpyDeviceToHost flag sets direction of copy
__syncthreads()__
▪ barrier to ensure all threads get there before any continue.
someGlobalFunctionName<<<N,M>>>
▪ “Kernel Launch”
▪ N thread blocks
▪ M threads per thread block
blockIdx: block index within the (up to 3D) grid
▪ threadIdx.x is 1D index
threadIdx: thread index within the (up to 3D) thread block
▪ threadIdx.x is 1D index
int index = threadIdx.x + blockIdx.x * M;
▪ Global thread index, given M threads per block
blockDim, gridDim
▪ 3D block and grid dimensions
▪ E.g., blockDim.x, gridDim.x, etc
同样的gdb:


对printf的输出保持怀疑态度:一旦有很多线程printf,新的会覆盖旧的。而且会串行化,降低速度

误区:
你的代码(软件模型): Grid -> Block -> Thread 你用这个逻辑层级来组织任务。
GPU的执行(硬件模型): Warp GPU的硬件调度器不认识“Block”这个整体。当你的一个Block被分配到某个计算单元(SM)上时,调度器会立即把它切分成Warp。
-
用 Block 和 Grid 组织的软件模型,和硬件实际处理时使用的 Warp 模型是两回事。
-
无论 Block 怎么定义,硬件在执行时都必然会把它“翻译”成一个个的 Warp 来处理。
-
Block 的共享内存和 Warp 不但不冲突,反而是协同工作的关键。如果Block中thread的个数不是32的倍数,那也会包装为整数个wrap来做,这些wrap共享我们定义的__shared__内存。所以我们最好使用32的倍数
-
一个 1024*1024 的线程网格会产生上万个 Warp。
-
SM:
GPU (整个显卡):是整个工厂园区。园区里有多个车间。
SM (流式多iprocessor):就是园区里的一个独立生产车间。一个GPU拥有数十个甚至上百个这样的车间。
Global Memory (全局内存):是工厂的中央大仓库,所有车间(SM)都能访问,但距离远,速度慢。
Block (线程块):是一个项目团队,被总调度室分配到**一个指定的车间(SM)**里去完成任务。一个团队进驻一个车间后,就不会再换地方。
-
__syncthreads()__这个barrier是在对block(很多个wrap)进行同步。wrap内部是不需要同步的(完全一致),wrap之间用这个同步,block之间通过回到host的时候完全同步
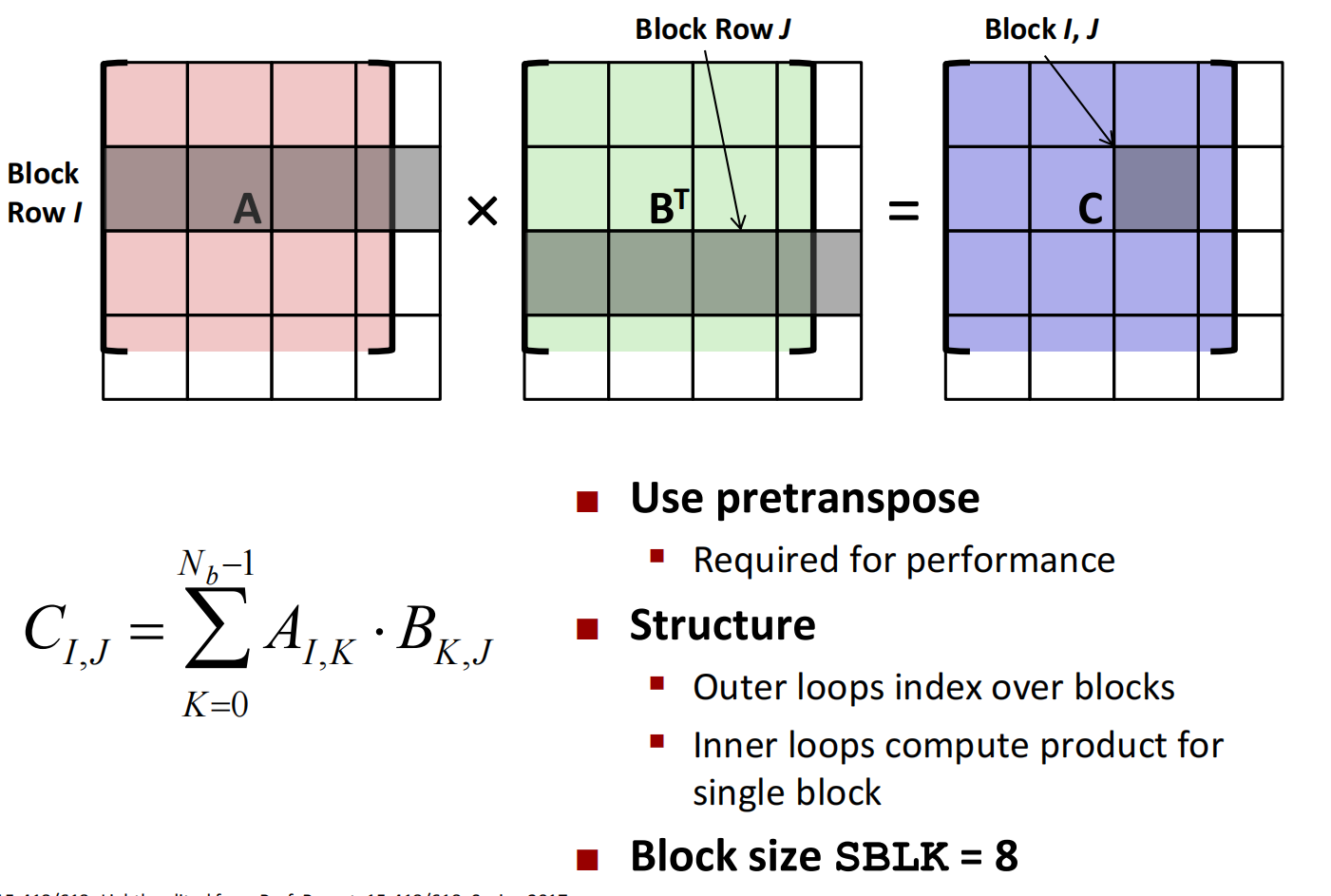
影响效率的典型例子:CUDA计算矩阵乘法:

GPU以一个叫 Warp(线程束) 的单位来执行的。一个Warp包含 32个线程。
这32个兄弟线程是“命运共同体”:
- 它们同时执行同一条指令。也就是说,对于一段代码,他们会同时执行第一行,第二行,…(完全步调一致)
- 它们在线程块中的ID,
threadIdx.x是从0到31连续的(假设线程块是一维或二维的第一行)。
当这条指令是“从全局内存读取数据”时,GPU硬件最高效的模式是 内存合并 (Memory Coalescing)。
- 内存合并(高效👍):如果一个Warp里的32个线程恰好要访问 一块连续的内存(比如连续的32个整数),GPU的内存系统可以把这次访问合并成一笔或极少数几笔大的传输
- 非合并访问(低效👎)
情况一:正确写法 (Regular)
1 | // i 对应全局行号, j 对应全局列号 |
我们来看这个Warp里的32个线程访问 data[i][j] 时,i和j的值如何变化:
- 对于
i:blockIdx.y,blockDim.y,threadIdx.y对这32个线程来说都是不变的。所以,所有32个线程计算出的i值完全相同。 - 对于
j:blockIdx.x,blockDim.x是不变的,但threadIdx.x是从0到31连续递增的。所以,这32个线程计算出的j值是连续的 (j_0,j_0+1,j_0+2, …,j_0+31)。
访问模式分析: 这个Warp的32个线程在同一时刻访问的是 data[一个固定的i][一个连续变化的j]。 根据第一步的知识,这正是访问连续的内存地址!。
情况二:错误写法 (Inverted)
1 | // i 和 j 的计算方式交换了 |
我们再来看这个Warp里的32个线程访问 data[i][j] 时,i和j的值如何变化:
- 对于
i:threadIdx.x是从0到31连续递增的。所以,这32个线程计算出的i值是连续的 (i_0,i_0+1,i_0+2, …,i_0+31)。 - 对于
j:threadIdx.y对这32个线程来说是不变的。所以,所有32个线程计算出的j值完全相同。
这些地址是不连续的!
结果:发生了灾难性的 非合并访问!内存系统需要进行多次零散的读取,性能急剧下降。
事实上,还可以进一步加速:
分块,在共享内存而非全局内存中读取!
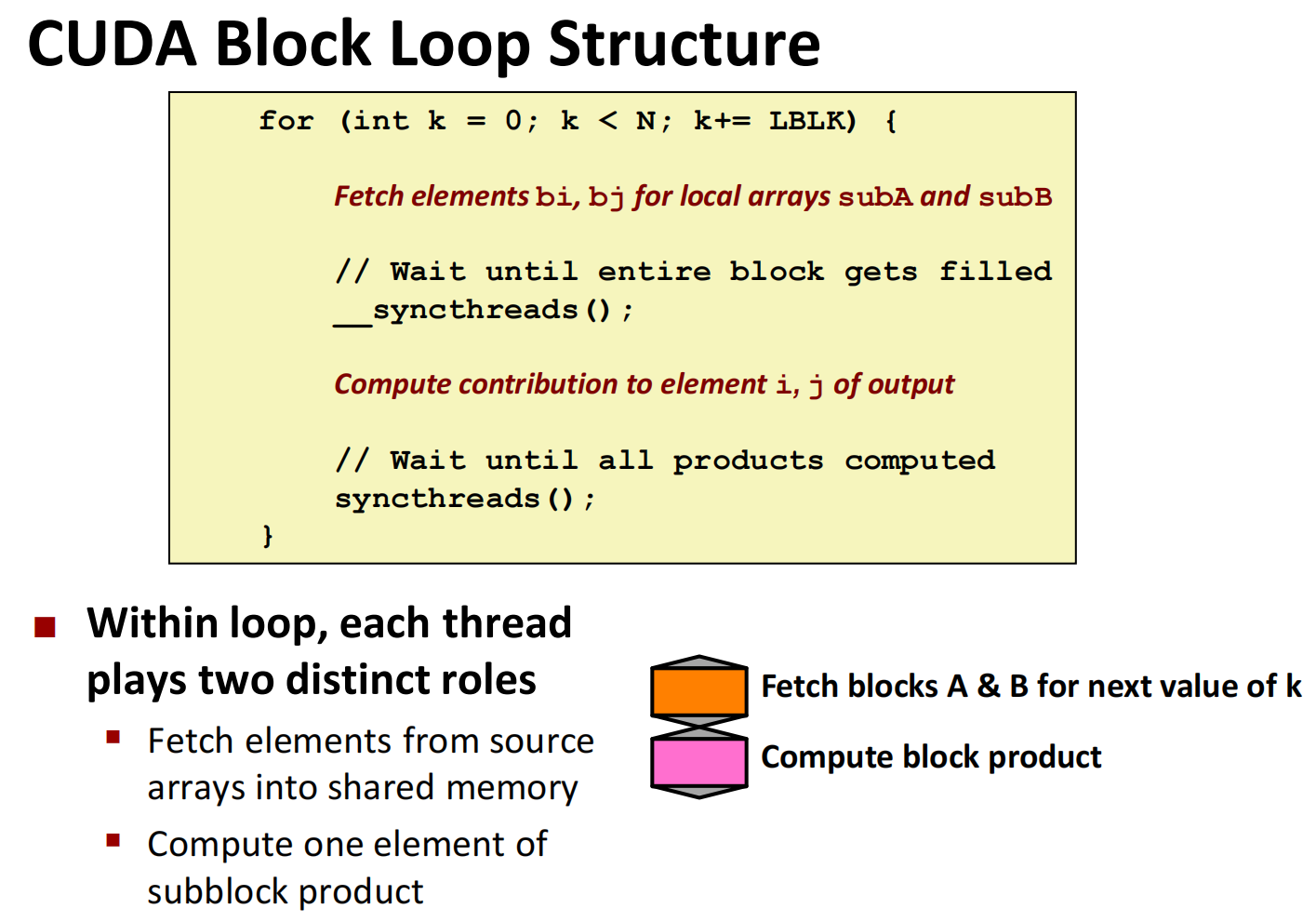
加入边缘检查后会发生什么?

if 条件语句导致一部分线程可能永远无法到达 __syncthreads() 同步点,从而造成整个线程块(Block)的永久性死锁(Deadlock)。所以应该修改为:
1 | for (int k = 0; k < N; k+= LBLK) { |

lec07 Locality, communication, and contention
回到之前的发信息的例子(把最上面一排和最下面一排传递)当时讲到了会死锁,只能奇数先发偶数后发,下面我们来详细讲讲:
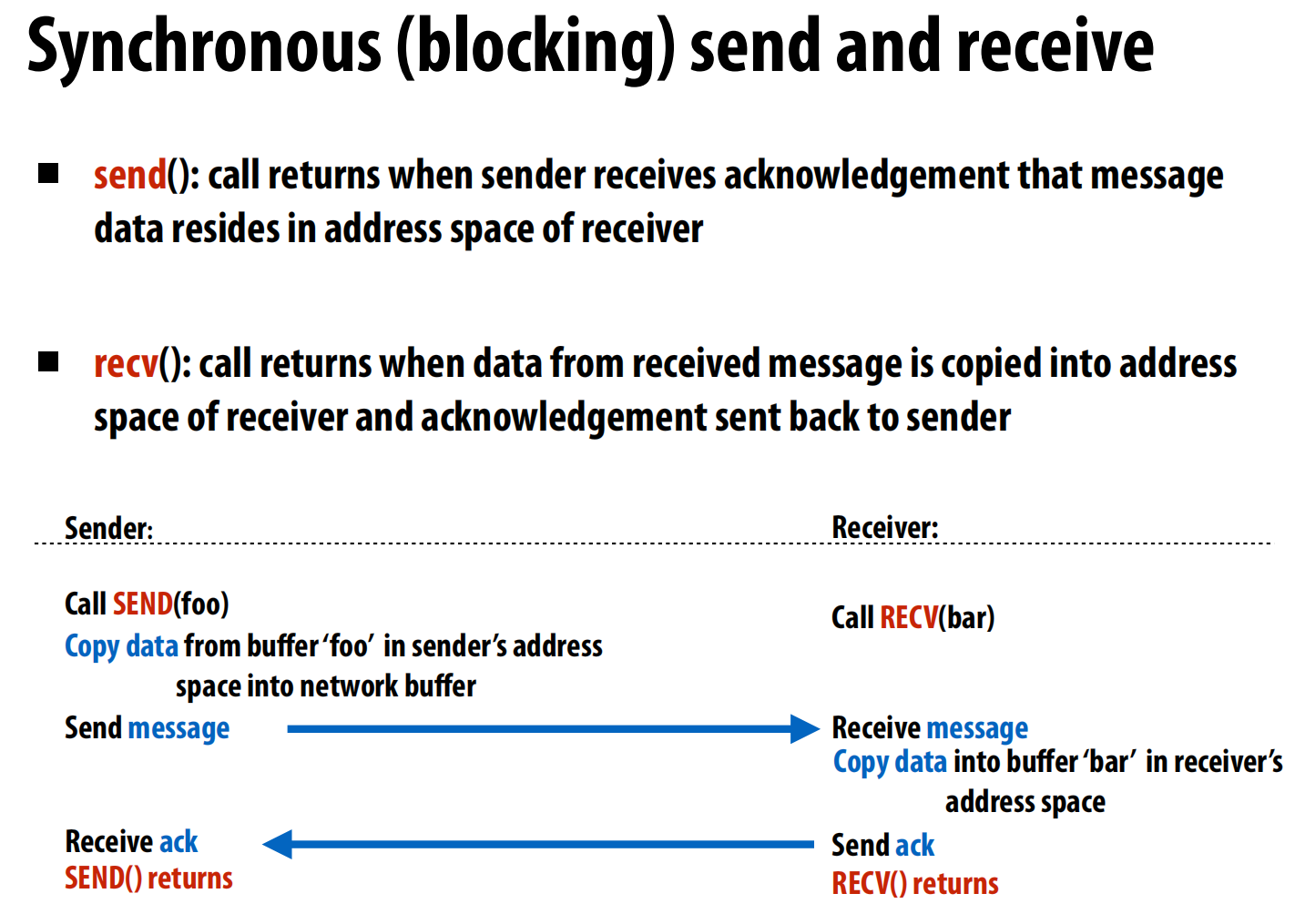
**同步(Synchronous)或称阻塞型(Blocking)**通信
send()(发送): 当你调用send函数时,程序会停(阻塞)在那里。它不仅会把数据发出去,还会一直等待,直到接收方确认收到了数据(发回一个ack信号)后,send函数才会返回,你的程序才能继续执行下一步。recv()(接收): 当你调用recv函数时,程序也会**停(阻塞)**在那里。它会一直等待,直到成功收到了发送方的数据,并把数据拷贝到指定内存位置后,recv函数才会返回。
因此会死锁,需要奇先偶后
第二种:
**异步(Asynchronous)或非阻塞型(Non-blocking)**通信。
send()(发送): 调用后立即返回,不会等待。它就像是告诉系统:“麻烦帮我把这份数据发出去”,然后你的程序就可以立刻去做别的事情了。系统会在后台进行数据发送。recv()(接收): 调用后也立即返回。它相当于告诉系统:“我准备好了一个空篮子,未来如果有数据送来,请放在这里”,然后你的程序也可以立刻去做别的事情。
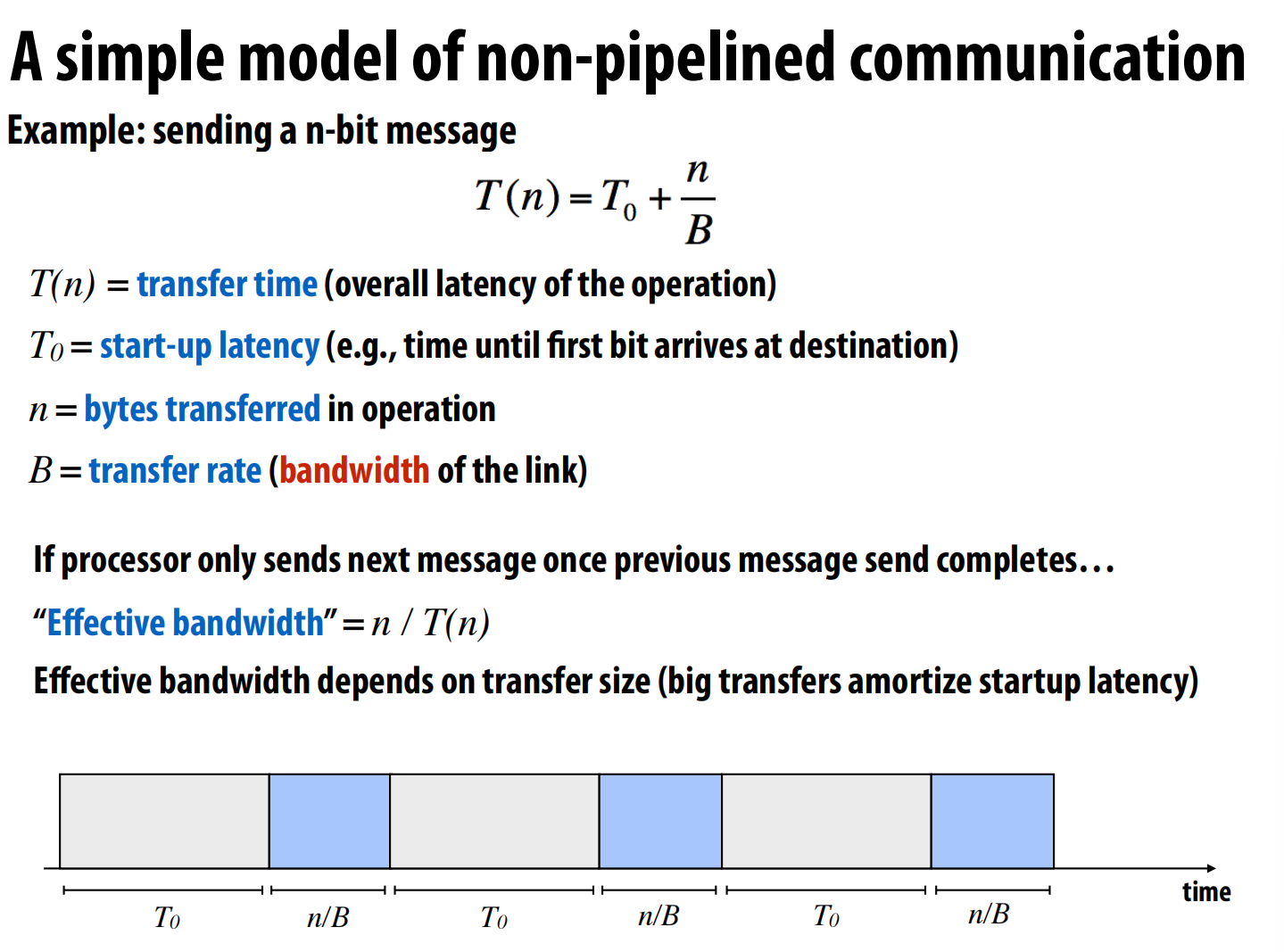
Latency and Bandwidth
延迟是单个事情开始到结束的时间,带宽是吞吐量。
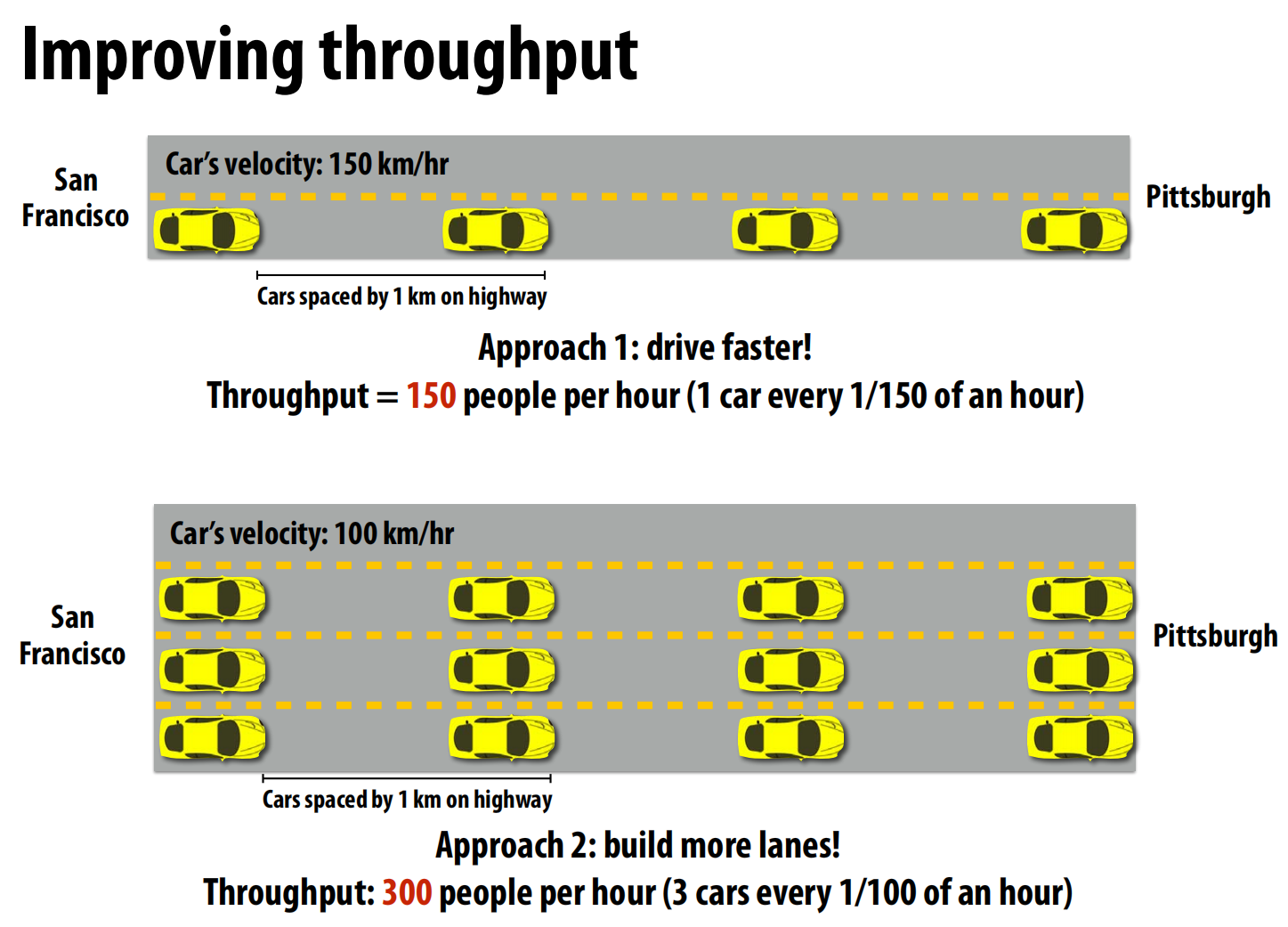
提高运输数量可以提高带宽,提高运行速度可以减小延迟
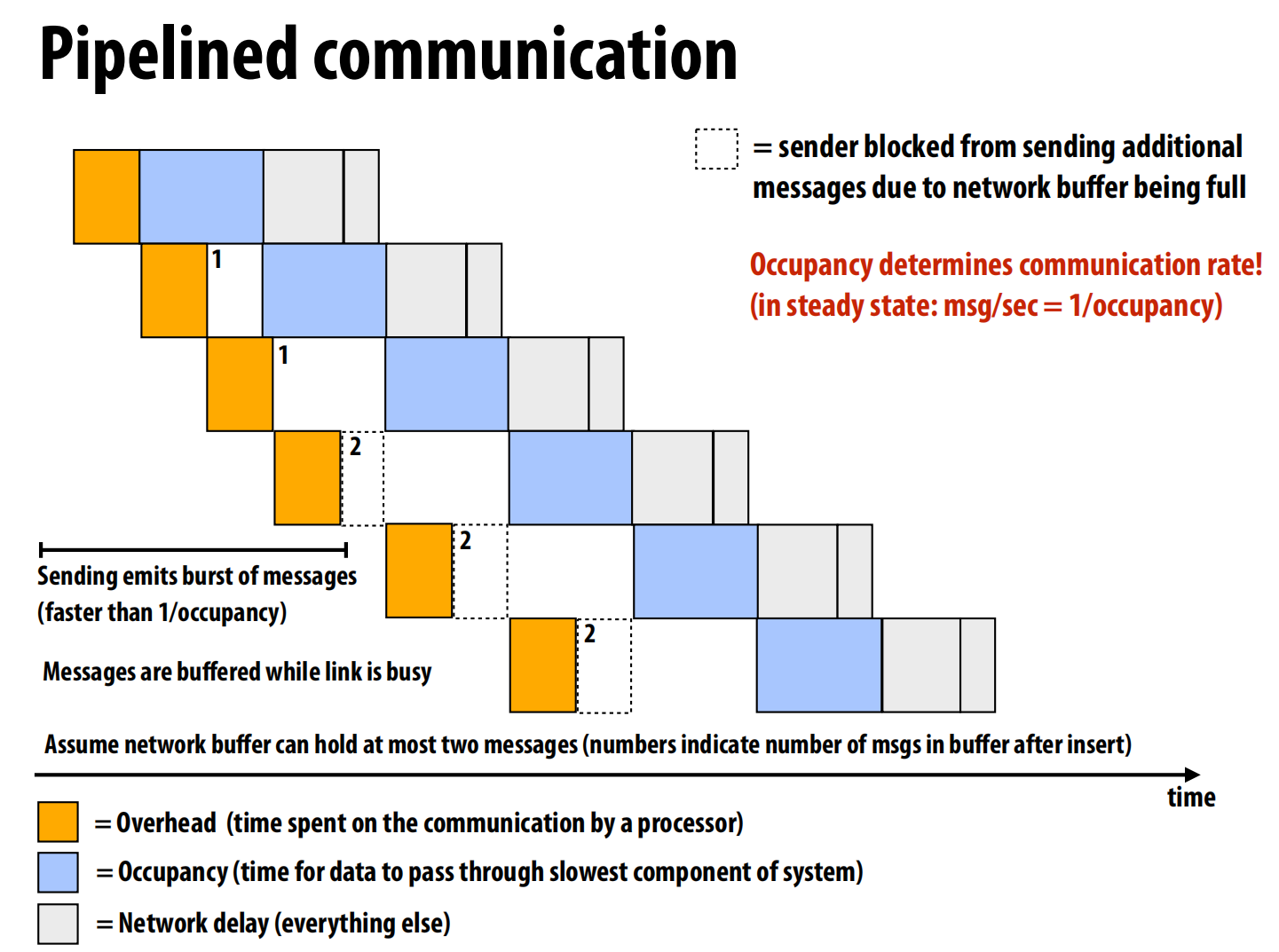
pipeline提高吞吐量:

算数强度:计算量/通信量,越小越好

固有通信:缓存无限等情况下,必须要通信的量。
伪通信:实现上的通信,由于硬件限制的通信等


四种cache miss:

伪通信举例:
1.矩阵乘法行列
2.我在取周围某个点的内存的时候cache帮我取了连续四个。多取了
3.“伪共享” (False Sharing)
- 固有通信: 数据被简单地按列切分给两个处理器P1和P2。P1只访问和修改左半边的数据,P2只访问和修改右半边的数据。从算法逻辑上看,它们各干各的,没有任何数据共享,因此固有通信应该是零。
- 问题根源: 一个缓存行非常不幸地跨越了P1和P2的分界线
- P1想要修改它负责的、位于这个缓存行末尾的数据。为了写入,它必须获取整个缓存行的所有权,并把它加载到自己的本地缓存中。
- 紧接着,P2想要修改它负责的、位于同一个缓存行开头的数据。
- 由于P1刚刚修改了缓存行,为了保证数据一致性(缓存一致性协议),系统必须先把P1缓存中整个更新后的缓存行作废或写回主存,然后再让P2把整个缓存行读取到它自己的缓存中。
- 这个**缓存行在两个处理器的缓存之间来回“颠簸”**的过程,就是一次通信
- 问题根源: 一个缓存行非常不幸地跨越了P1和P2的分界线
一个方法:改变cache的排布方式
Contention(竞争)
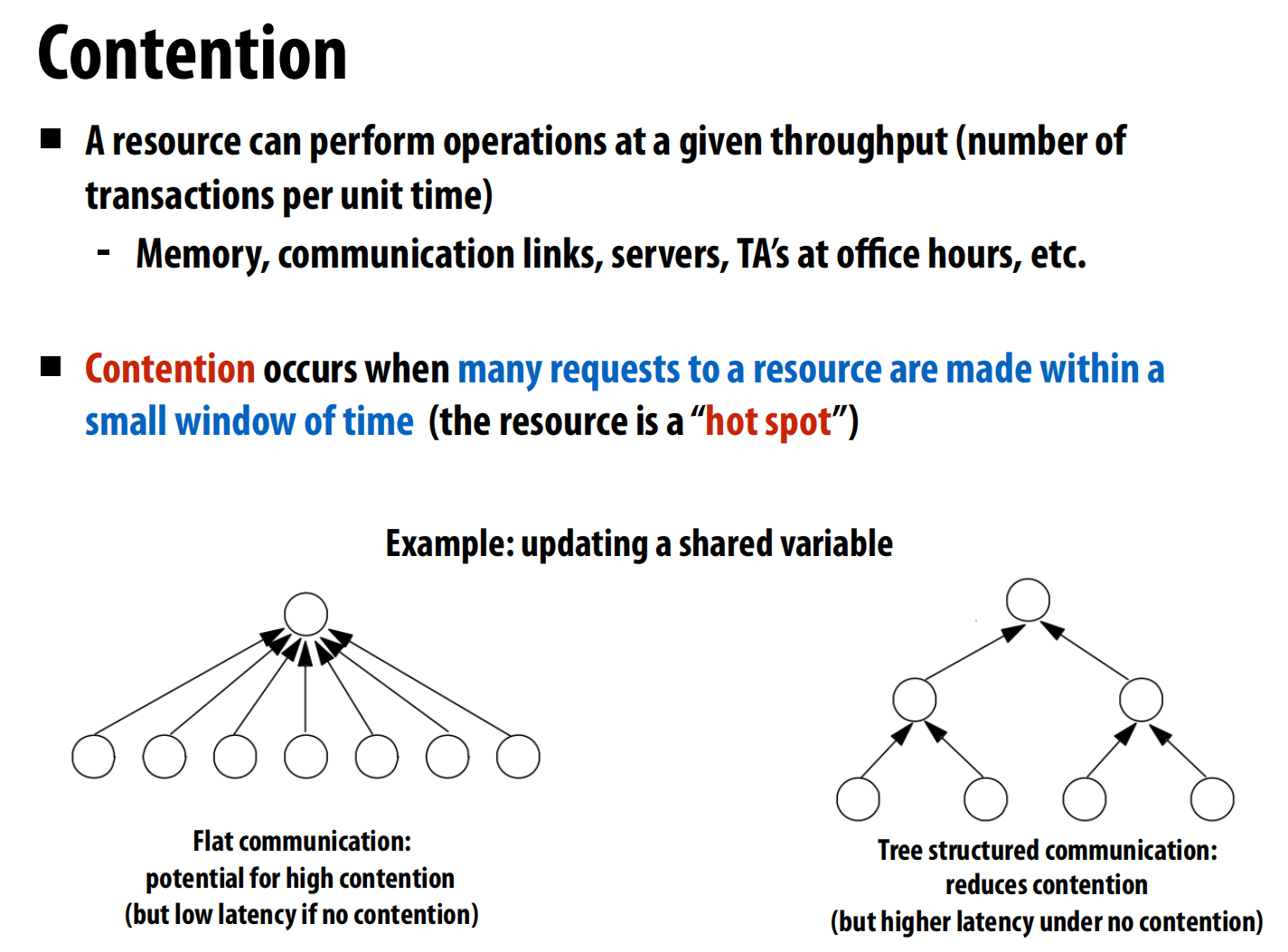
举例:
- 场景: 我们有成千上万的粒子散布在一个空间里。为了快速找到某个粒子附近的邻居(例如,在半径R范围内的所有粒子),一个有效的方法是先将空间划分成一个个大小为R x R的网格(Cell)。
- 核心任务: 建立一个数据结构,将每个粒子放入其对应的网格列表中。这样,要找一个粒子的邻居时,我们只需要检查它所在网格以及周围8个网格里的粒子即可,大大减少了搜索范围。
- 并行挑战: 如何在拥有数千个核心的GPU上,高效、并行地完成这个“粒子到网格”的分配过程?主要矛盾在于,多个线程(代表多个粒子)可能会同时尝试更新同一个网格的列表,这会产生冲突和竞争。
解决方案一(按单元并行)
- 思路: 不按粒子并行,而是按网格单元(Cell)并行。假设有16个网格,就启动16个并行任务。每个任务负责一个网格,它会遍历所有粒子,判断哪些粒子属于它这个网格,然后将其加入列表。
- 缺点:
- 并行度不足: 只有16个并行任务,对于拥有数千个核心的GPU来说,绝大部分计算资源都被浪费了。
- 工作效率极低: 假设有100万个粒子,这个方法总共要执行
16 * 100万次“判断粒子是否在单元内”的计算。相比于只遍历一次粒子(100万次计算)的串行算法,它做了16倍的无用功
解决方案二(按粒子并行 + 全局锁)
- 思路: 这是一种更自然的思路,按粒子并行。一个线程负责一个粒子。线程计算出粒子所属的网格,然后去更新该网格的列表。
- 问题: 为了防止多个线程同时修改列表导致数据错乱,代码中使用了一个全局锁(Global Lock)。
- 缺点: 巨量竞争: 这个全局锁成为了系统的唯一瓶颈。这使得并行程序退化成了串行执行
解决方案三(细粒度锁)
- 思路: 我们不用一个锁管所有列表,而是每个网格列表配一把自己的锁。
- 缺点: 竞争依然存在,如果粒子分布不均,某些“热门”网格的锁仍然会成为瓶颈
解决方案四(局部计算 + 合并)
-
- 分解: 将所有粒子分给不同的线程块(Thread Block)。
- 局部计算: 每个线程块在自己**私有的、高速的共享内存(Shared Memory)**中,构建一个局部的、小型的“网格-粒子列表”。
- 合并: 将所有这些局部列表合并成一个最终的全局列表。
- 缺点: 需要额外的内存来存储大量的局部列表,并且最后的合并步骤是额外的工作量。
解决方案五(数据并行方法)
-
- 步骤一:计算网格索引。并行计算每个粒子所属的网格ID。输出是一个
grid_index数组,grid_index[i]存储的是particle i所属的网格ID。 - 步骤二:排序。这是最关键的一步。对
grid_index数组进行并行排序。在排序时,原始的粒子索引数组particle_index也跟着进行同样的交换。排序完成后,particle_index数组就变得井然有序:所有属于网格0的粒子排在一起,然后是所有属于网格1的粒子,以此类推。 - 步骤三:寻找起止点。再次并行遍历排序后的
grid_index数组,通过比较相邻元素,可以非常快速地找到每个网格的粒子在particle_index数组中的起始和结束位置。
- 缺点: 依赖于一个高性能的并行排序算法(这本身就很复杂),并且需要对数据进行多次完整的遍历,对内存带宽有一定要求。
- 步骤一:计算网格索引。并行计算每个粒子所属的网格ID。输出是一个
结论:一种非常优雅且高效的并行算法设计模式,是现代GPU编程的精髓之一。
lec08 Application case studies
案例研究一:海洋模拟
这是一个基于网格的模拟程序,通过将海洋三维空间离散化成二维网格来计算洋流的演变 。
- 分块方式(Strips vs. Blocks):讲座对比了按“条带”切分和按“块”切分两种方式 。结论是块状划分更好,因为它最小化了每个区域的“边界面积”,从而减少了处理器之间需要通信的数据量 。
- 内存布局(Memory Layout):为了最大化利用局部性,讲座对比了标准的二维行主序(row-major)布局和一种**4D块主序(block-major)**布局 。4D布局能确保分配给某个处理器的整个数据块在内存中是连续的,极大地提升了缓存命中率和访存效率 。
案例研究二:星系演化(Barnes-Hut算法)
这个案例模拟宇宙中大量星体(粒子)在引力作用下的运动 。Barnes-Hut算法通过构建一个四叉树/八叉树(Quad-Tree/Oct-Tree),将远处的一群粒子近似看作一个质点,从而将复杂度降低到 O(N log N) 。
-
负载均衡策略:代价区域(Cost Zones):这是一种非常聪明的半静态任务分配方法 。
- 首先,程序通过一次模拟运行来“自我剖析”,估算出计算每个粒子的“代价”(即它需要进行多少次交互)。
- 然后,将所有粒子的总代价 W 计算出来,并均分给 P 个处理器,每个处理器负责 W/P 的工作量 。
- 最巧妙的是,这个分配是基于对整个树的深度优先遍历来划分的,确保了每个处理器分到的是在空间上连续的一片区域(代价区域),从而同时实现了负载均衡和数据局部性 。
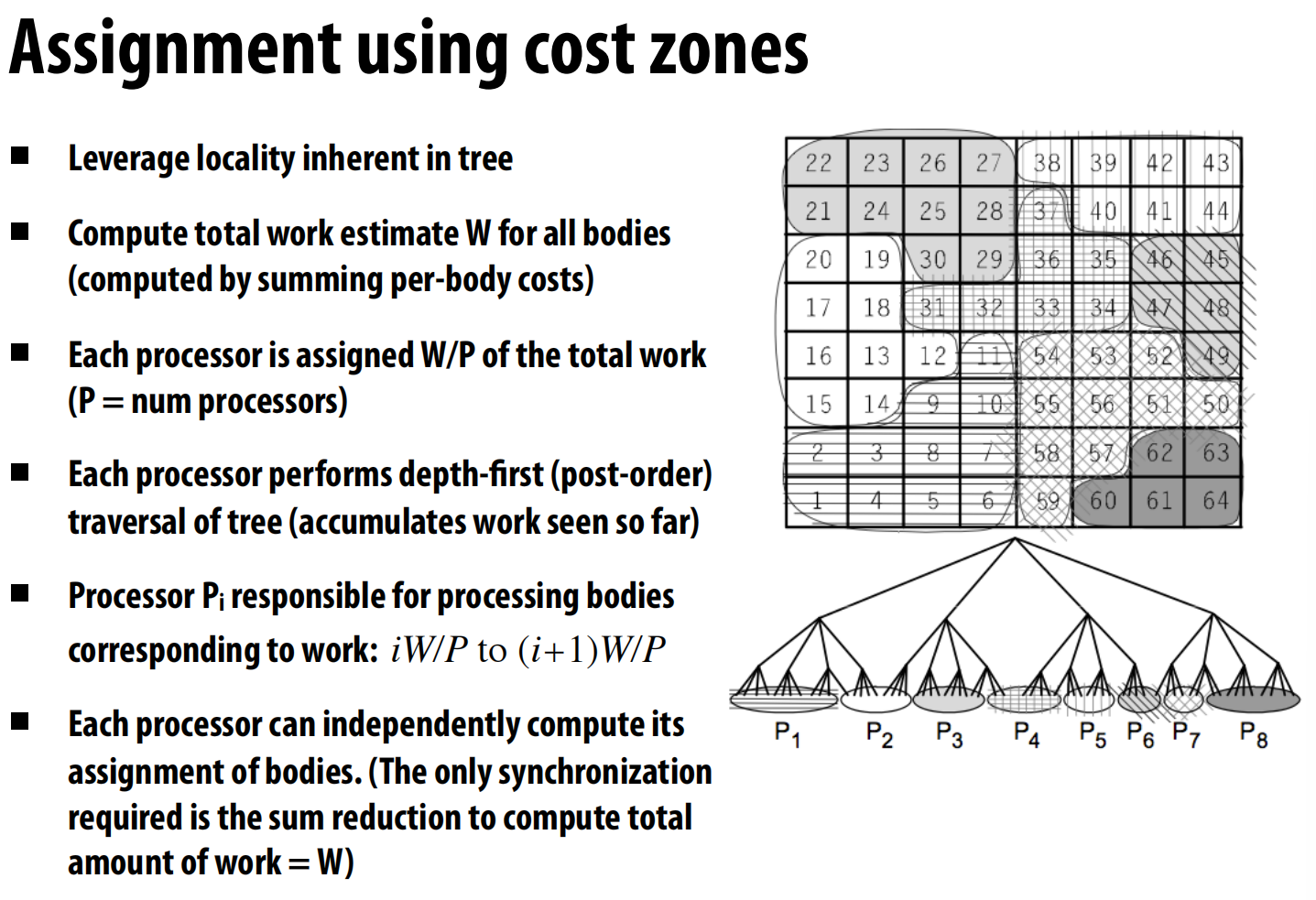
-
数据分布:与海洋模拟不同,Barnes-Hut的计算有很强的时间局部性——一个处理器连续处理的粒子在空间上很近,它们需要访问的树节点也高度重合 。因此,只要处理器缓存足够大,数据是否严格分布在本地内存中,对性能影响不大 。
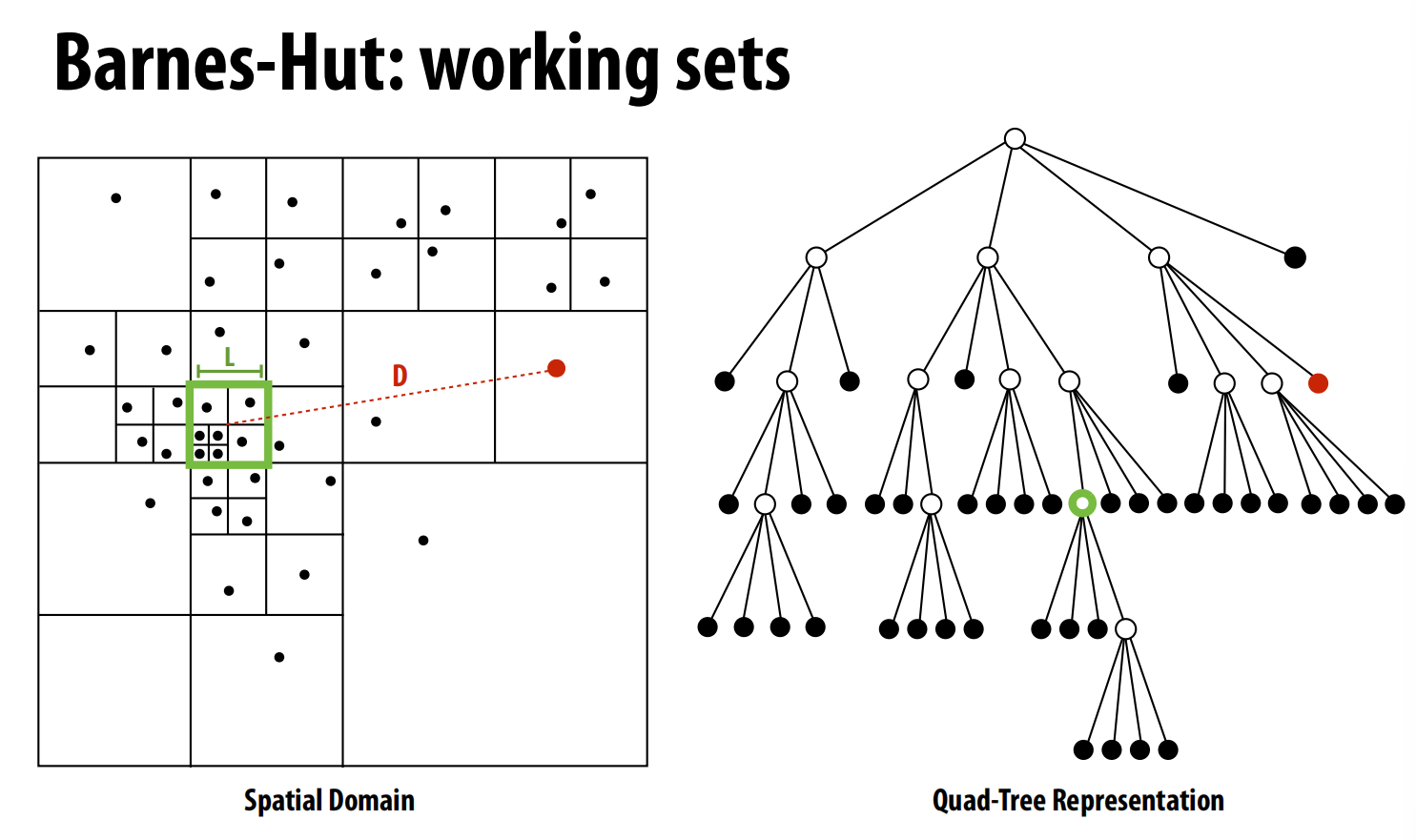
优秀的任务分配(Work Assignment)比复杂的数据分布(Data Distribution)更重要 。
案例研究三:并行扫描(Parallel Scan)
扫描(也称前缀和)是一个看似串行但可以被高效并行的基础算法 。例如,输入[1, 2, 3, 4],输出[1, 3, 6, 10]。
-
算法演进:
-
朴素并行算法:讲座首先展示了一个简单的并行算法,但其总工作量为 O(N log N),比串行算法的 O(N) 还要多,效率低下 。(类似树状数组)
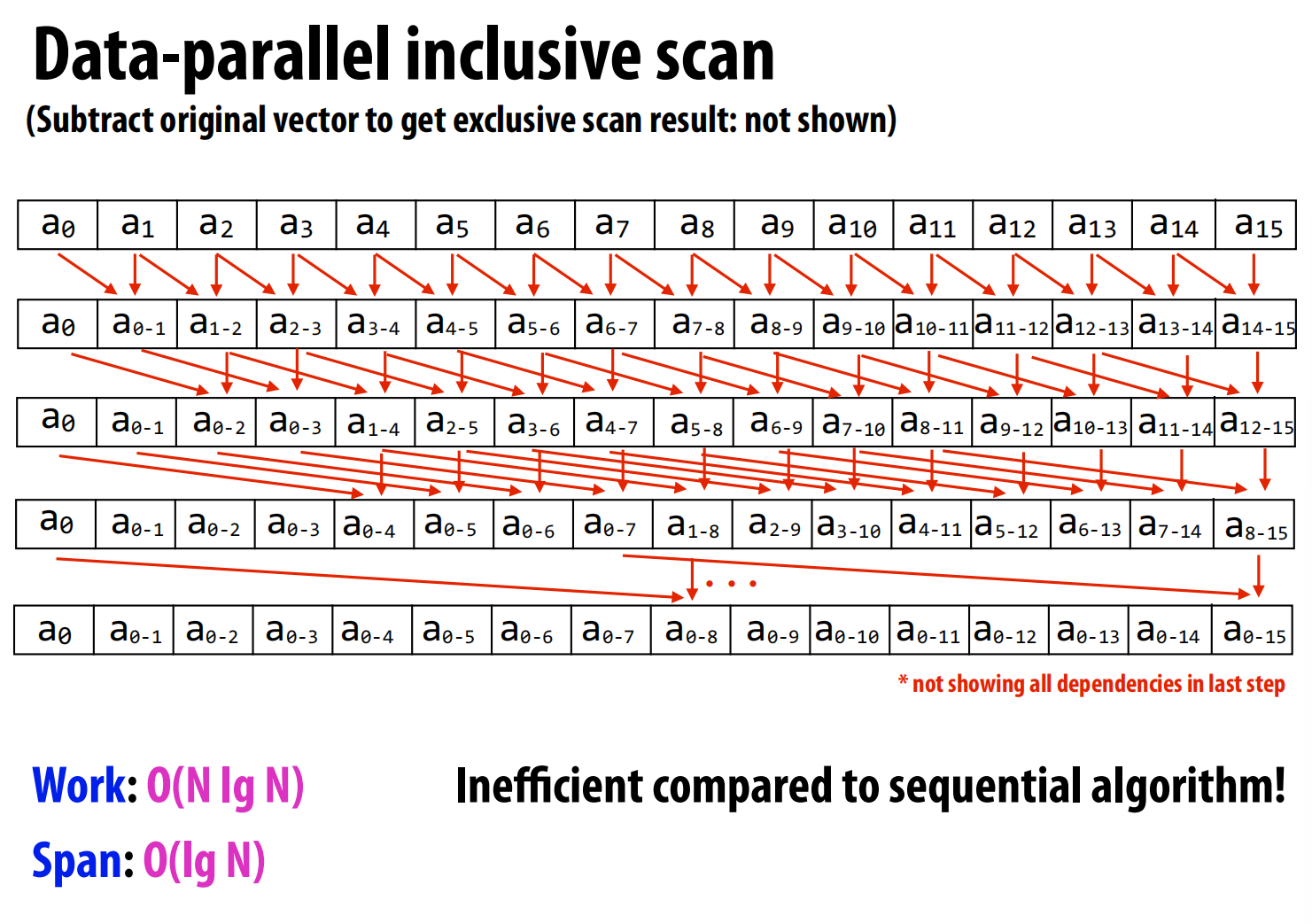
-
高效并行算法:接着介绍了一个经典的两步(Up-sweep 和 Down-sweep)算法,总工作量为 O(N),达到了与串行算法相同的效率 。
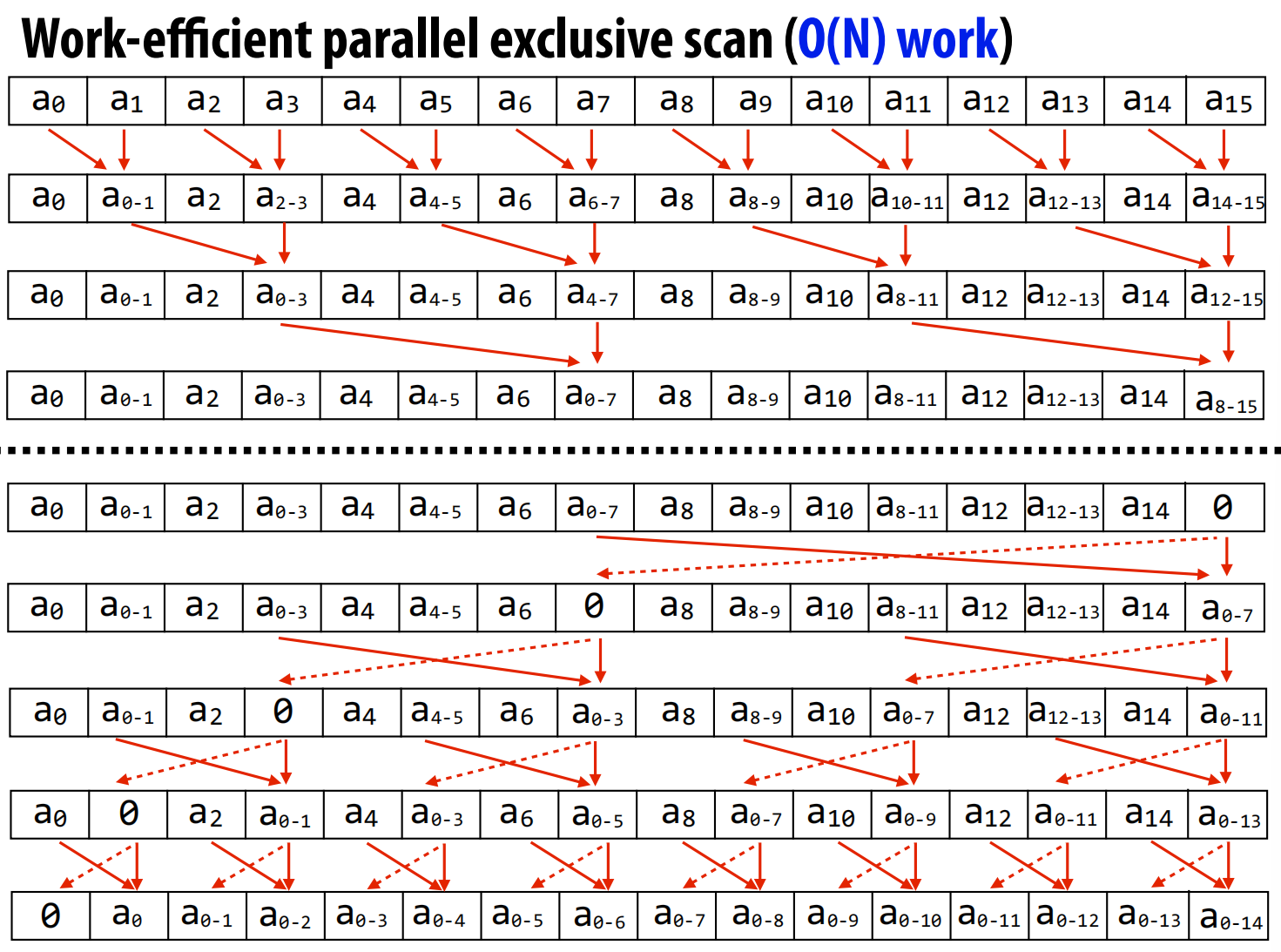
-
GPU (SIMD) 实现:在讨论GPU实现时,揭示了一个深刻的权衡。在Warp(32个线程的执行单元)内部,为了充分利用SIMD的32个通道,反而会选择那个理论上“工作量大”的O(N log N)算法,因为它能让所有通道都保持工作 。而理论上“高效”的O(N)算法,在执行时会导致大量SIMD通道闲置,实际性能更差 。
-
分层设计(Hierarchical Design):为了在GPU上实现对大规模数组的扫描,采用了分层策略 。
- Warp内扫描:使用上述的SIMD友好算法。
- Block内扫描:每个Warp先对自己的一小段数据做扫描,然后由一个Warp汇总所有Warp的结果,计算出每个Warp的起始偏移量,最后再加回到每个Warp的结果上 。
- 全局扫描:如果数组太大一个Block处理不了,就分给多个Block,最后再通过一次额外的内核启动来合并所有Block的结果 。
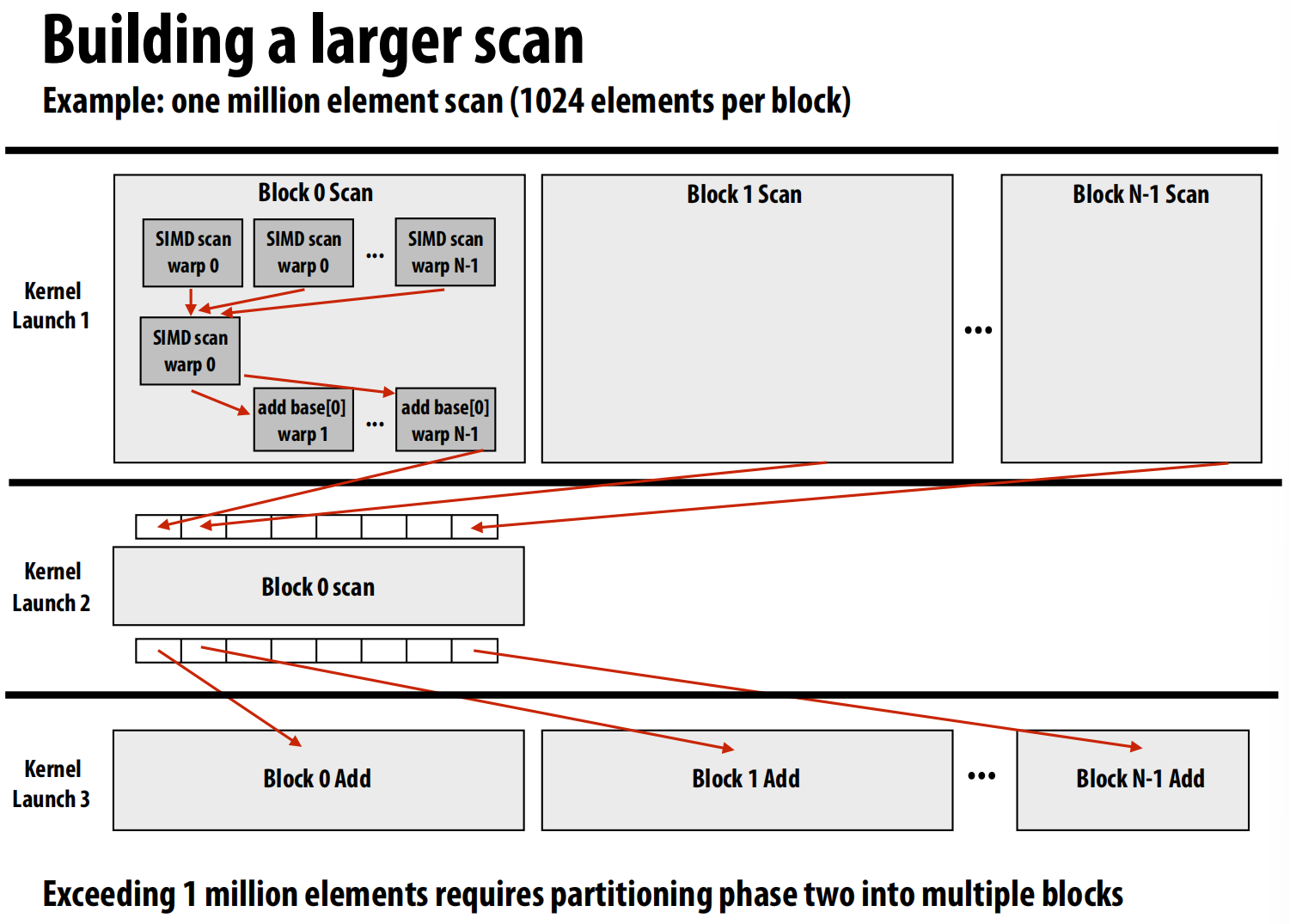
-
结论:并行扫描的案例完美展示了根据硬件不同层级的特性,采用不同算法策略的思想 。
附加内容:分段扫描与光线追踪
-
分段扫描(Segmented Scan):这是扫描算法的推广,可以对一个大数组中划分出的多个不规则长度的小片段,同时进行扫描 。它通过引入一个“标志位”数组来标记每个小片段的开头,并在扫描算法中加入判断逻辑,以确保扫描不会跨越片段边界 。这对于处理图、粒子列表等不规则数据结构非常有用 。
-
并行光线追踪(Parallel Ray Tracing):
-
挑战:光线追踪的核心是判断一条光线与场景中哪个物体最先相交 。在SIMD架构上,挑战在于不同光线会沿着不同路径与场景交互,导致执行路径
分化(Divergence),降低SIMD效率 。
-
解决方案:光线包(Ray Packets):核心思想是一次性追踪一“包”光线(比如32条),而不是单条光线 。
- 优点:可以分摊访问场景加速结构(如BVH树)的数据读取开销(一个节点读取一次,给包里所有光线用),并且天然适合SIMD执行 。
- 缺点:随着光线与场景的交互,包内的光线路径会越来越不一致(incoherent),导致包里只有少数几条光线是“活跃”的,造成SIMD通道浪费 。
- 实践:最佳实践通常是混合策略,在光线路径还很一致时(如刚从相机射出)使用大的光线包,当路径分化严重后,切换到更小的包或者单条光线追踪的模式 。
-
Recitation CUDA programming 2




第一部分:识别性能瓶颈 (Identifying Performance Limiters)
这一部分的目标是建立一个系统性的优化流程:首先,确定是什么在限制你的程序跑得更快,然后有针对性地去优化 。
程序的性能瓶颈通常分为三类 :
- 内存吞吐量 (Memory Throughput):程序访问内存的速度跟不上计算的速度 。
- 指令吞吐量 (Instruction Throughput):程序的计算量太大,GPU的计算单元已经满负荷运转,内存访问反而很清闲 。
- 延迟 (Latency):内存或指令的延迟没有被有效地隐藏,导致GPU在很多时间里处于“空等”状态 。
为了找出瓶颈所在,讲座介绍了三种由浅入深的方法 。
方法一:算法分析 (Algorithmic Analysis)
这是一种“纸上谈兵”的估算方法 。
- 做法:分析你的算法,计算出计算操作数量与内存访问字节数的比值 。然后,将这个比值与你的GPU硬件的“平衡比”进行比较 。
- 例子:向量加法
C[i] = A[i] + B[i],需要读取2个4字节浮点数,写入1个4字节浮点数,总共访问12字节内存,而只有1次加法操作 。这个“计算/访存比”远低于GPU的硬件平衡比,因此可以初步判断它是内存瓶颈型程序 。 - 缺点:非常不精确,因为它忽略了大量的额外指令(如地址计算、循环控制)和硬件效应(如缓存行大小)。
方法二:使用性能分析器 (Using the Profiler)
这是最常用、也更可靠的方法 。
- 做法 1:计算实际比例:使用性能分析器(Profiler)获取实际的指令执行数 (
instructions_issued) 和DRAM读写数 (dram_reads,dram_writes) 。用这些更精确的数字来计算“计算/访存比”,并与硬件平衡比进行比较 。 - 做法 2:对比理论峰值:性能分析器会直接告诉你程序的实际指令执行速率(IPC)和实际内存带宽(GB/s) 。你可以将这两个值与硬件的理论峰值进行比较 。
- 如果其中一项指标非常接近(比如达到理论值的70%以上),那么它很可能就是瓶颈 。
- 如果两项指标离理论峰值都很远,那么很可能是延迟问题,即GPU的并行度不足以隐藏访存或指令延迟 。
方法三:修改源代码 (Modifying Source Code)
这是最精确,但也是最麻烦的方法 。
- 做法:将你的内核代码修改成几个特殊版本并分别计时 :
- 完整版 (full-kernel):原始代码的执行时间。
- 纯内存版 (mem-only):注释掉所有计算代码,只保留内存读写。
- 纯计算版 (math-only):注释掉所有全局内存读写,并“欺骗”编译器保留计算逻辑(否则编译器会因为计算结果未被使用而将其优化掉)。
- 分析:通过对比这几个版本的执行时间,可以清晰地看出瓶颈所在 。
- 如果
完整时间 ≈ 纯内存时间,说明是内存瓶颈 。 - 如果
完整时间 ≈ 纯计算时间,说明是计算瓶颈 。 - 如果
完整时间 < 纯内存时间 + 纯计算时间,说明内存访问和计算有很好的重叠(Overlap),延迟隐藏得很好 。 - 如果
完整时间 ≈ 纯内存时间 + 纯计算时间,说明重叠很差,延迟是主要问题 。
- 如果
- 注意:修改代码时,要确保不改变程序的占用率(Occupancy),否则会影响结果的公平性。必要时可以通过增减共享内存大小来维持占用率不变 。
第二部分:本地内存与寄存器溢出 (Local Memory and Register Spilling)
这一部分深入探讨了一个常见的性能陷阱:寄存器溢出。
什么是本地内存 (Local Memory)?
- 定义:首先,“本地内存(Local Memory)”是一个容易引起误解的名字。它不是一块特殊的物理硬件,而是指每个线程私有的一块内存区域,而这块区域实际上是划分在**全局内存(DRAM)**中的 。
- 用途:当一个线程需要的**寄存器(Register)**数量超过了硬件限制时(例如,代码太复杂,局部变量太多),编译器就会把一部分“放不下”的变量“溢出”(Spill)到本地内存中 。此外,在核函数中定义的、编译期无法确定索引的数组,也必须放在本地内存里 。
寄存器溢出的性能影响
寄存器溢出不总是坏事,但它可能通过两种方式损害性能 :
- 增加内存流量:原本在超高速寄存器里的操作,现在变成了对慢速全局内存的读写。
- 增加指令数量:需要额外的加载(load)和存储(store)指令来访问本地内存。
如果溢出的数据能一直保留在高速的L1缓存中,那么对性能的影响就可能不大 。
如何分析和优化寄存器溢出问题
1. 检查是否存在溢出
- 使用
nvcc编译器选项-Xptxas -v,它会在编译时打印出每个核函数使用的寄存器数量和lmem(本地内存)大小 。
2. 分析溢出的影响
- 使用性能分析器,查看与本地内存相关的计数器,如
l1_local_load_miss。 - 通过公式估算由本地内存溢出导致的L2缓存访问量占总访问量的百分比 。如果你的程序是内存瓶颈,而这个百分比很高,那问题就严重了。
3. 案例研究
- 讲座中一个内存瓶颈的程序,为了提高占用率而将寄存器限制为32个,导致了44字节的溢出 。
- 通过性能分析器发现,高达53.38%的L2缓存流量都是由这44字节的溢出造成的! 这严重抢占了真正有用的数据所需要的内存带宽。
4. 优化策略
- 增加每线程寄存器上限:放宽
-maxrregcount限制,或者修改__launch_bounds__。 - 增大L1缓存大小:GPU的L1缓存和共享内存是同一块物理硬件,可以动态划分。通过调用
cudaFuncSetCacheConfig()将L1缓存从默认的16KB增加到48KB,可以大大提高溢出数据的缓存命中率 。 - 使用非缓存加载:对于全局内存的访问,使用非缓存加载(
-dlcm=cg),可以减少L1缓存中“有用数据”和“溢出数据”之间的竞争 。
lec09 Workload-driven performance evaluation





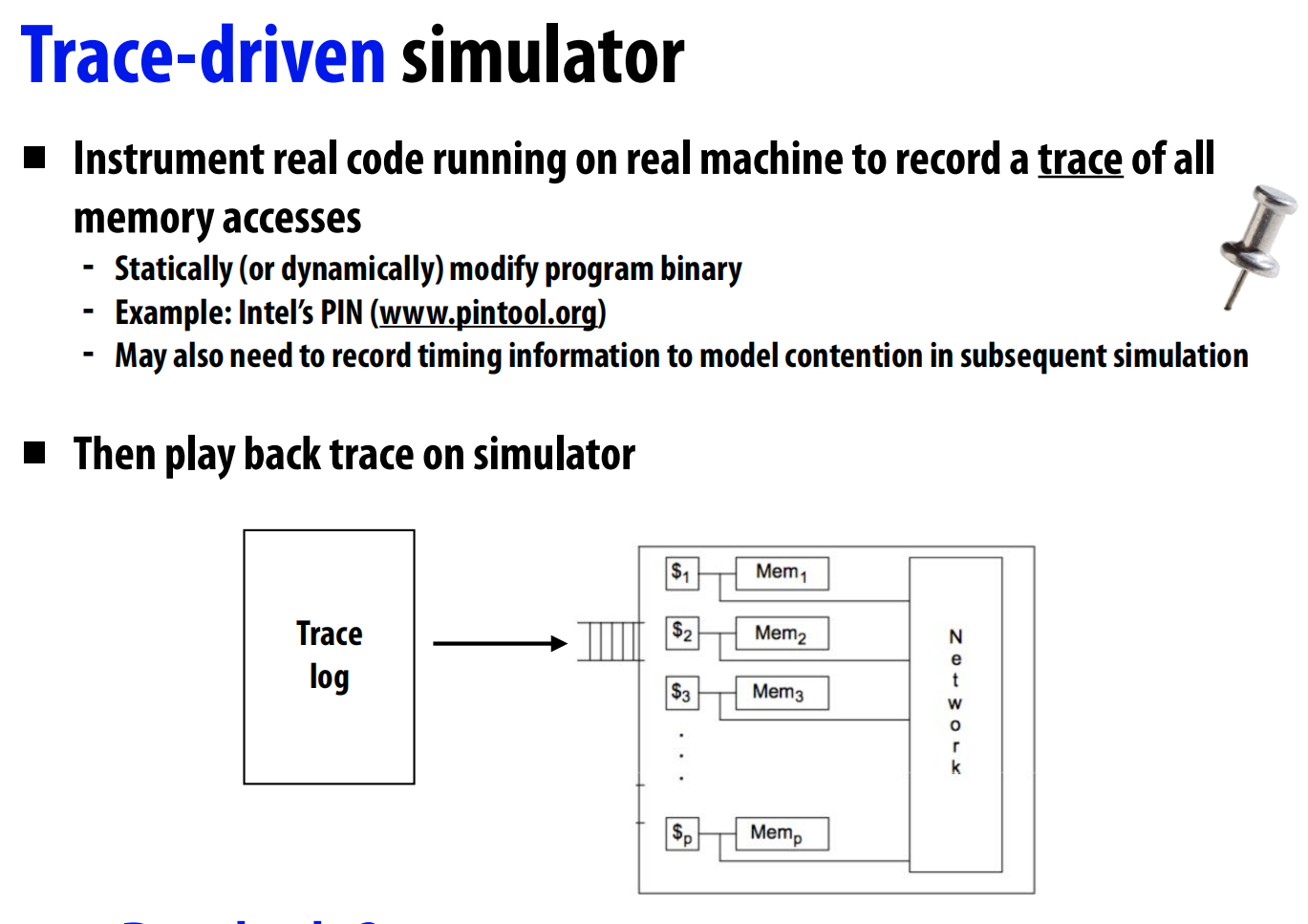
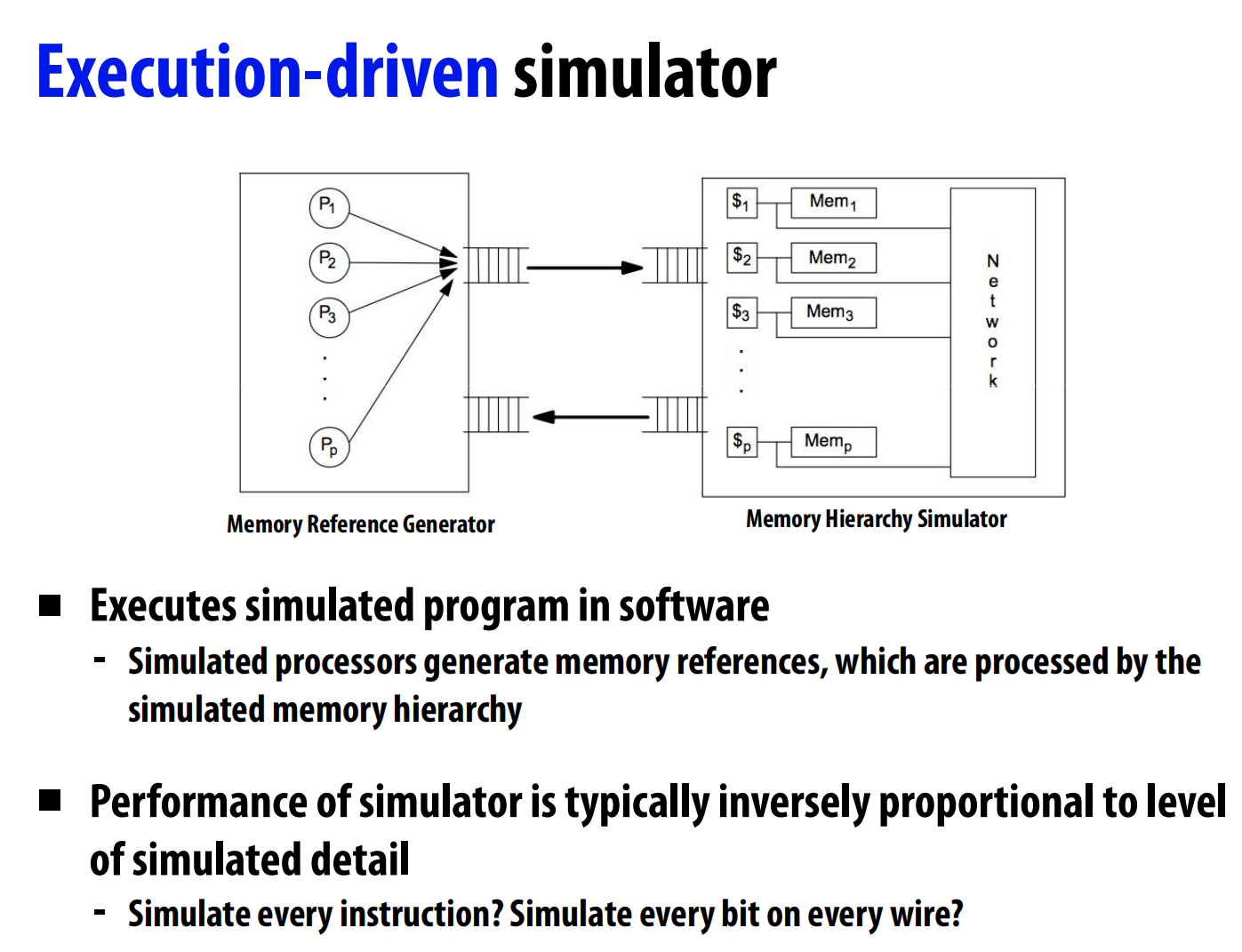
模拟器:

硬件性能模拟器定量评估新功能的好坏 。模拟器分为踪迹驱动(记录真实程序的内存访问序列,然后回放) 和执行驱动(直接在软件中模拟处理器和内存系统的行为) 两种。
软件开发者的技巧
- 建立“高水位线” (Establishing High Watermarks):通过一系列“思想实验”式的代码修改,来探明性能的理论上限 。例如:
- 去掉所有同步操作(锁、原子操作),看性能能提升多少?这揭示了同步开销的上限 。
- 将所有内存访问都改成
A[0],看性能能提升多少?这揭示了优化数据局部性的潜力的上限 。
- Roofline模型:一个强大的可视化分析工具,它将一个程序的**计算强度(Arithmetic Intensity, 每访问一字节内存所做的浮点运算次数)与机器的可达性能(GFlops/s)**画在一张图上 。
- 这张图有一个“屋顶”,由两条线构成:一条水平线代表机器的峰值计算性能,一条斜线代表机器的峰值内存带宽 。
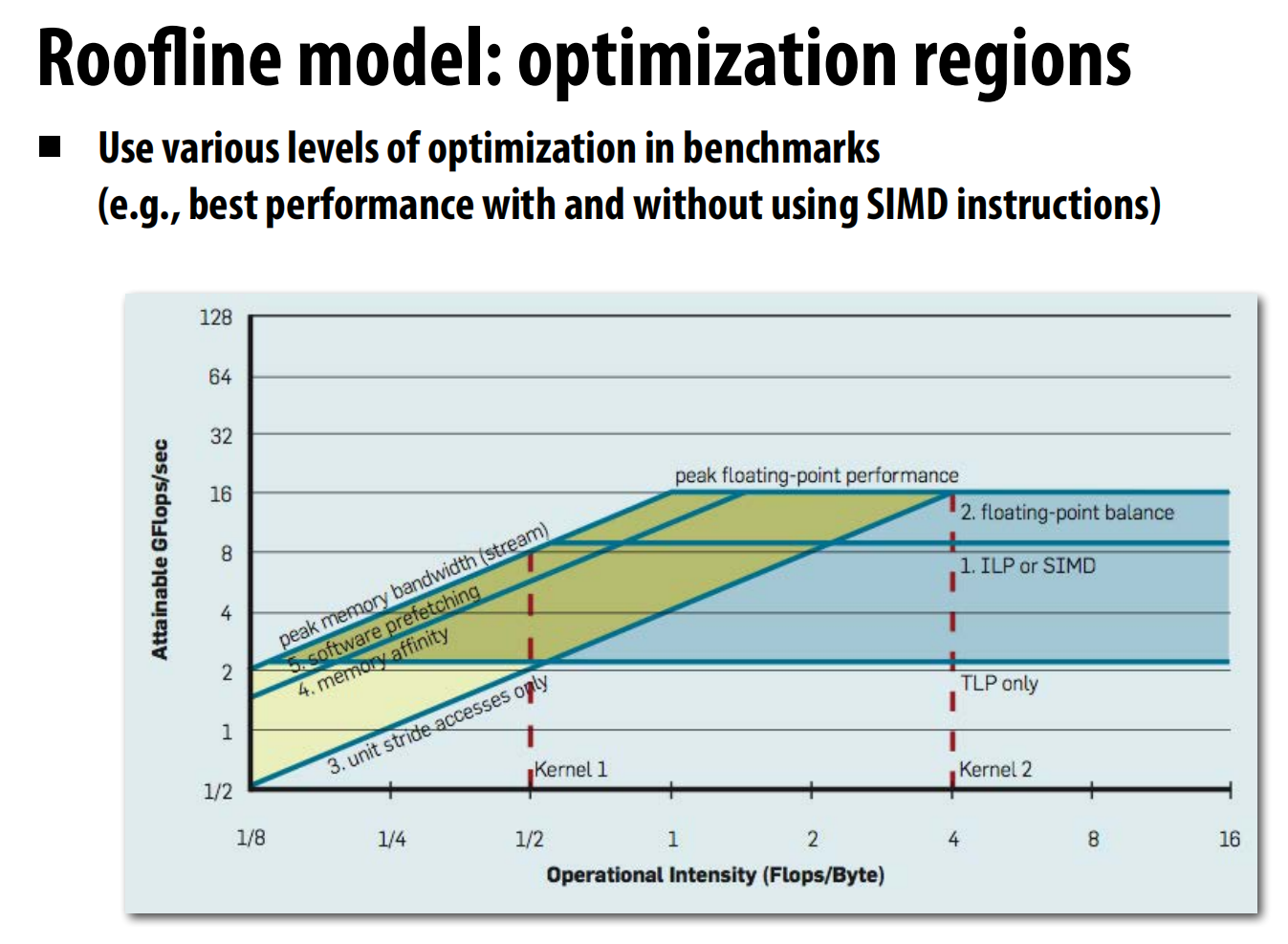
lec10 Snooping-based cache coherence
写回 (Write-Back) vs. 写通 (Write-Through) 缓存:
- 写回缓存: 处理器写入数据时,只修改缓存行并设置脏位。数据只在缓存行被替换(evict)时才写回主内存。这减少了对主内存的访问带宽。
- 写通缓存: 处理器每次写入数据时,都会同时更新缓存和主内存。
写分配 (Write-Allocate) vs. 写不分配 (Write-No-Allocate) 缓存:
- 写分配: 当发生写未命中(write miss)时,系统会先将对应的数据块从内存加载到缓存中,然后再进行写入操作。
- 写不分配: 发生写未命中时,数据直接写入主内存,而不会加载到缓存中。
由于不同处理器的cache之间的信息问题,产生cache coherency问题。
一个内存系统被称为是一致的 (coherent),如果它满足以下条件 :
- 程序顺序 (Program Order): 一个处理器对某个地址的读操作,如果发生在它自己对同一地址的写操作之后,那么读操作必须返回这次写入的值(假设中间没有其他处理器写入) 。这保证了单处理器内部的逻辑。
- 写传播 (Write Propagation): 一个处理器P2对地址X的写入,必须最终对其他处理器P1可见。也就是说,如果P1在P2写入足够长的时间后去读取X,它应该得到P2写入的值 。
- 写串行化 (Write Serialization): 所有处理器观察到的、对同一个内存地址的多次写入操作,其顺序必须是一致的 。例如,如果P1写入X=1,然后P2写入X=2,那么任何其他处理器都不可能先看到X=2,再看到X=1 。
实现一致性的方法
- 基于软件的方案: 通常由操作系统通过页面错误机制来实现,适用于分布式系统,但我们这里不深入讨论 。
- 基于硬件的方案:
- 基于监听 (Snooping-based): 每个缓存控制器“监听”共享总线或互连上的内存事务,并做出相应反应。
- 基于目录 (Directory-based): 使用一个集中的“目录”结构来跟踪每个缓存行的状态和共享者。
本次讲座我们介绍基于监听的方案,下次课介绍基于目录的方案。
监听协议
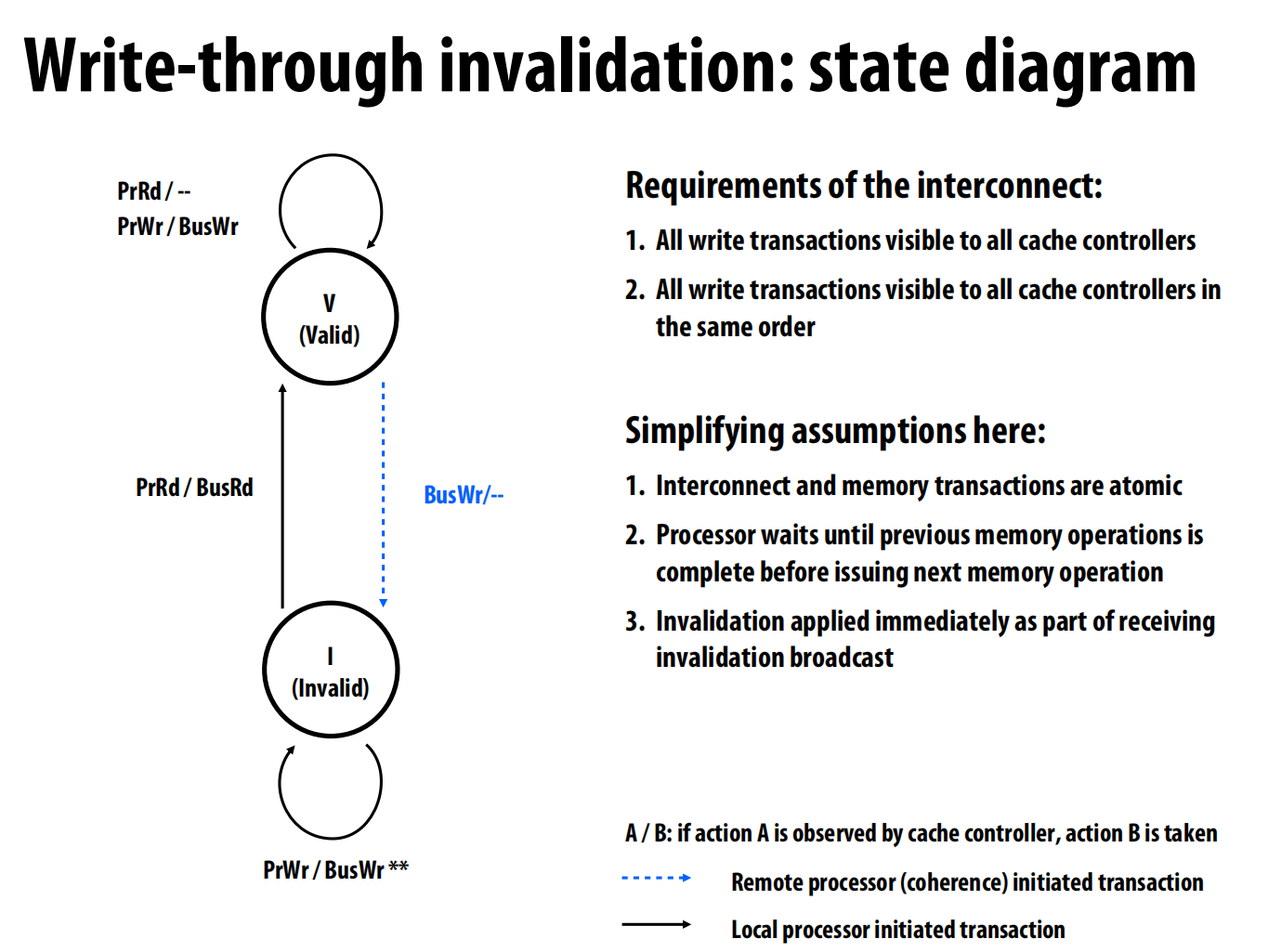
写通作废协议 (Write-Through Invalidation Protocol)
一个简单的方案:每个cache的缓存行有两个状态——valid 和 invalid
当写入操作时同时写入主内存,通过广播让其他地方的这个数据无效(监听)
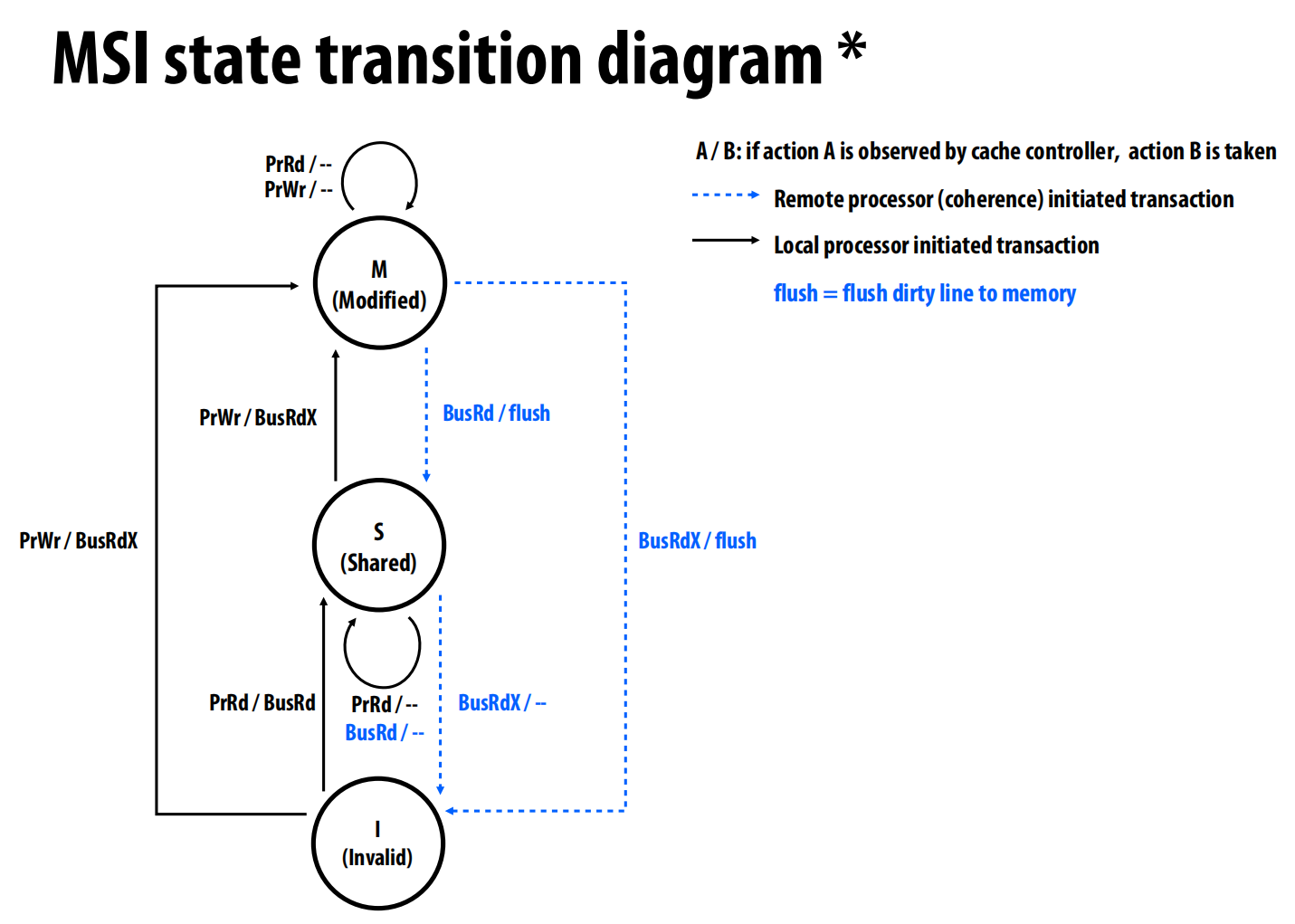
写回作废协议:MSI
每个缓存行三个状态 :
- 已修改 (M - Modified): 该缓存行是系统中唯一有效的副本,并且它已经被修改过(是“脏”的),与主内存不一致。该缓存是此数据的“所有者” (owner),有责任在未来提供最新数据 。
- 共享 (S - Shared): 有一个或多个缓存拥有该行的有效副本,且数据与主内存一致(非“脏”) 。处于S状态的行是只读的。
- 无效 (I - Invalid)
实现:
读操作 (PrRd):
- 若行是I状态(未命中):缓存控制器在总线上发起
BusRd请求。其他拥有该行的缓存会响应,数据被加载后,状态变为 S。 - 若行是S或M状态(命中):直接读取,状态不变。
写操作 (PrWr):
-
若行是M状态(命中):直接写入,状态不变 。
-
若行是S状态(命中):不能直接写。缓存控制器必须先在总线上发起
BusRdX(Read-Exclusive) 请求,告诉其他缓存“我要写这个数据,你们的副本都作废”。收到此消息的缓存将自己的副本置为I。发起者将状态变为 M 。 -
若行是I状态(未命中):发起
BusRdX请求,获取独占权和数据,然后状态变为 M 。
监听到总线事务:
- 监听到
BusRd:如果本地行为M状态,说明自己有最新数据,必须将数据“冲刷”(flush)到总线(供给请求者)和内存,然后将自己的状态变为 S 。如果本地行为S状态,则无需操作。 - 监听到
BusRdX:如果本地行为M或S状态,说明有其他缓存要独占写入,必须将自己的副本置为 I 。如果行是M状态,还需提供最新数据。 -
在此基础上,衍生出MESI 协议
新增状态:独占 (E - Exclusive)
- E 状态表示:当前缓存是唯一拥有该行副本的缓存,但数据是“干净”的(与主内存一致) 。
当一个处理器读取一个其他任何缓存都没有的数据时,可以直接将行状态置为 E(通过 PrRd/BusRd,并发现总线上没有其他缓存响应共享) 。
之后,如果该处理器要写入此行,由于它已经是独占的(处于E状态),无需任何总线事务,可以直接在本地将状态从 E 变为 M 并写入 。
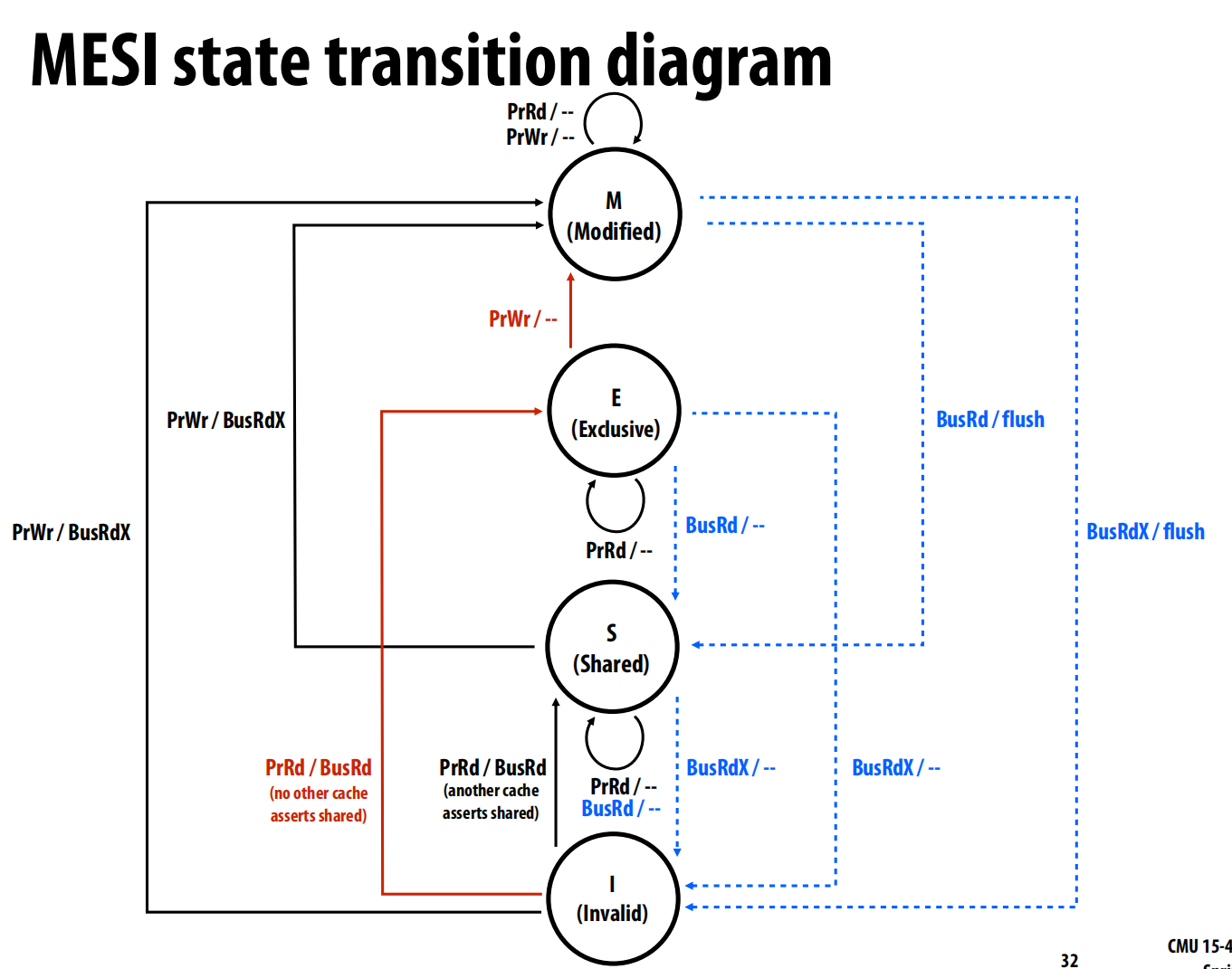
衍生协议:
MESIF: Intel处理器使用。在MESI的基础上增加了一个**F (Forward)**状态。当多个缓存共享一个行时(都处于S状态),指定其中一个为F状态。当有新的缓存需要读取该行时,由处于F状态的缓存负责响应,而不是所有S状态的缓存都响应。
MOESI: AMD处理器使用。在MESI的基础上增加了一个**O (Owned)**状态。在MESI中,当一个M状态的行被其他缓存读取时,它需要先将数据写回内存再变为S状态 。在MOESI中,它可以直接变为O状态,表示“数据是脏的,我是所有者,但允许多个其他缓存共享(S状态)”。这样避免了不必要的内存写回,由O状态的缓存直接为其他缓存提供数据 。
更新协议 (Update-based Protocols)
我们之前讨论的都是作废协议 (Invalidation-based):一个处理器要写,就让其他处理器的副本失效 。另一种选择是更新协议 (Update-based):一个处理器写入共享数据时,不作废其他副本,而是广播更新的值,让其他缓存也同步更新 。
- Dragon 协议: 一个经典的写回更新协议 。它有四个状态 :
- E (Exclusive-clean): 独占且干净。
- M (Modified): 独占且脏。
- Sc (Shared-clean): 可能多个缓存共享,数据可能是干净的(如果所有副本都是Sc),也可能是脏的(如果某个副本是Sm) 。
- Sm (Shared-modified): 多个缓存共享,但此副本是脏的,并且是“所有者”,负责更新内存 。
- 作废 vs. 更新:
- 更新协议的优势: 如果一个数据被多个处理器频繁地读写(生产者-消费者模式),更新协议可以避免后续读取时的缓存未命中,因为数据总是最新的 。
- 作废协议的优势: 如果一个处理器对某数据进行多次连续写入,而其他处理器在这期间并不读取它,作废协议更好。它只需要一次作废消息,而更新协议会产生大量不必要的更新流量 。
多级缓存
在真实的多级缓存(如L1, L2, L3)中,如何实现监听?让所有级别的缓存都去监听总线效率太低 。一个关键的解决方案是维持包含属性 (Inclusion Property) 。
- 包含属性: 指靠近处理器的缓存(如L1)中的所有内容,都必须是远离处理器的缓存(如L2)内容的子集 。
- 好处: 如果满足包含属性,那么只需要让最外层的私有缓存(如L2)去监听互连就足够了。因为任何与L1相关的事务,也必然与L2相关 。
Recitation Understanding Assignment 3
由于暂时没有做这个项目的准备,所以暂时没看这节课。如果要做的话再补(B站链接)
lec11 Directory-based cache coherence
ccNUMA: 指“缓存一致性的非均匀内存访问” (cache-coherent, non-uniform memory access) 架构 。
分布式共享内存 (DSM): 指的是一种架构,它提供缓存一致性的共享地址空间,但其物理内存是分布式的 。
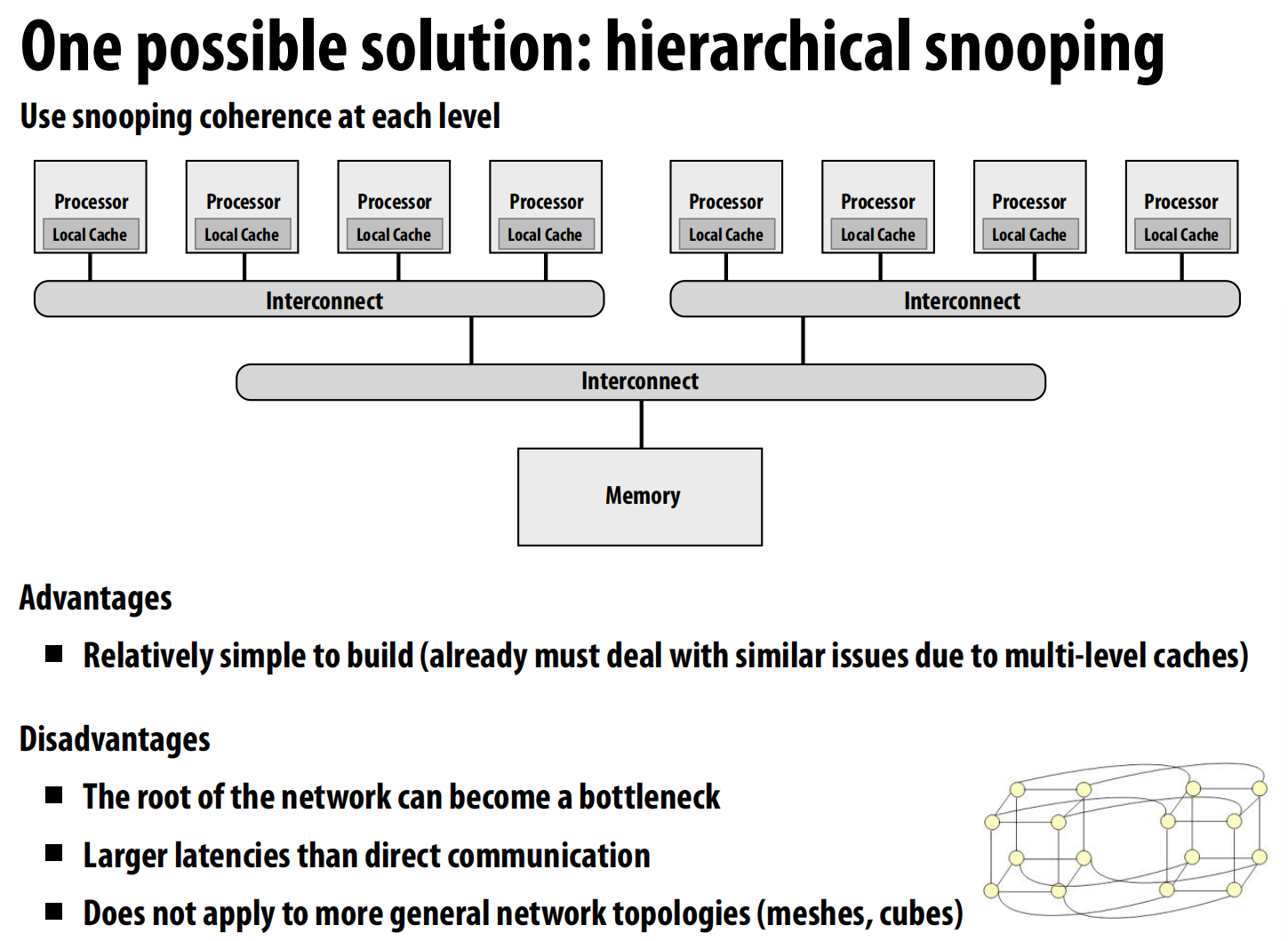
**一个潜在方案:分层监听 (Hierarchical Snooping) **
一种看似可行的方案是构建分层的监听协议。例如,可以将处理器分成小组,每个小组内部使用监听协议,而小组之间再通过一个更高层次的协议进行通信 。
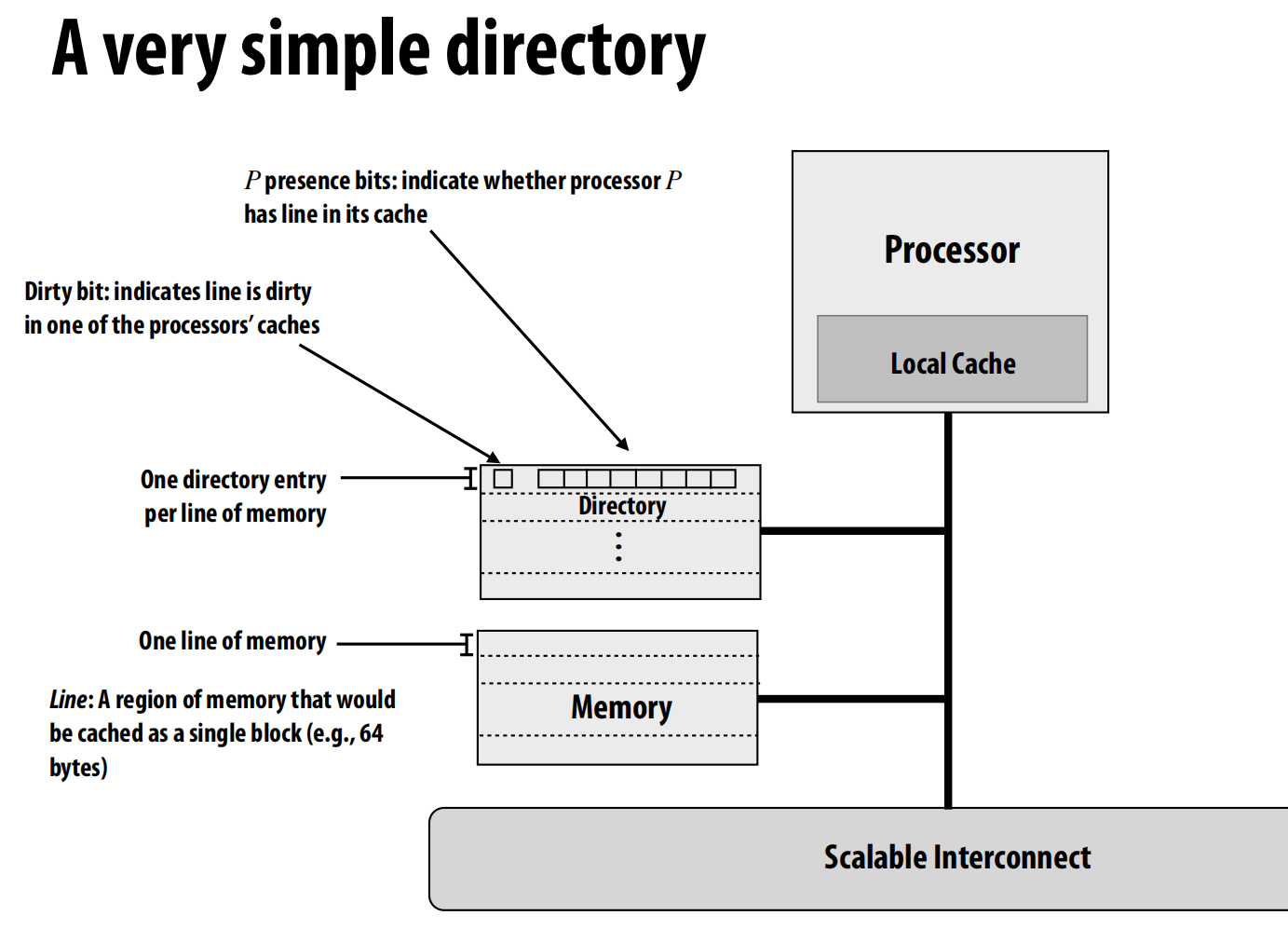
目录协议
- 每个内存行(cache line)在目录中都有一个对应的条目 (entry),记录了该行在所有处理器缓存中的状态 。当缓存需要信息时,它们会查询目录 。
- 一致性通过点对点 (point-to-point) 消息在“需要知道”的基础上进行维护,而不是通过广播 。
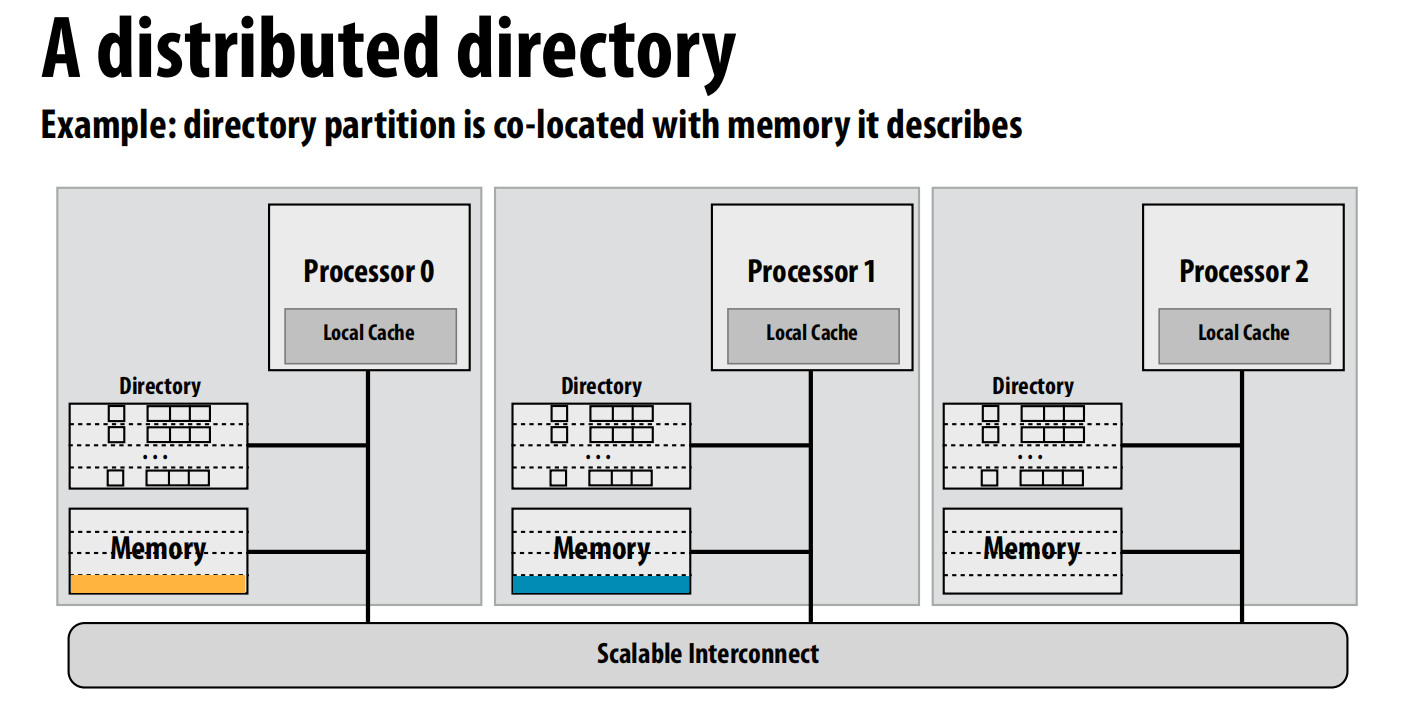
目录的结构与分布
- 一个简单的目录条目:
- 存在位 (P presence bits): 一个比特向量,每一位对应一个处理器,指示该处理器是否缓存了这一行 。
- 脏位 (Dirty bit): 一位,指示该行是否在某个处理器缓存中被修改过(即处于“脏”状态)。
- 每个内存行都有一个对应的目录条目 。
- 分布式目录 (Distributed Directory): 为了提高可扩展性,目录本身也是分布式的。通常,描述某块内存的目录部分与该内存物理上放在一起(即同地协作)。
- 归属节点 (Home node): 存放着某个内存行对应数据和目录条目的节点 。
- 请求节点 (Requesting node): 发起内存访问请求的处理器所在的节点 。
工作流程
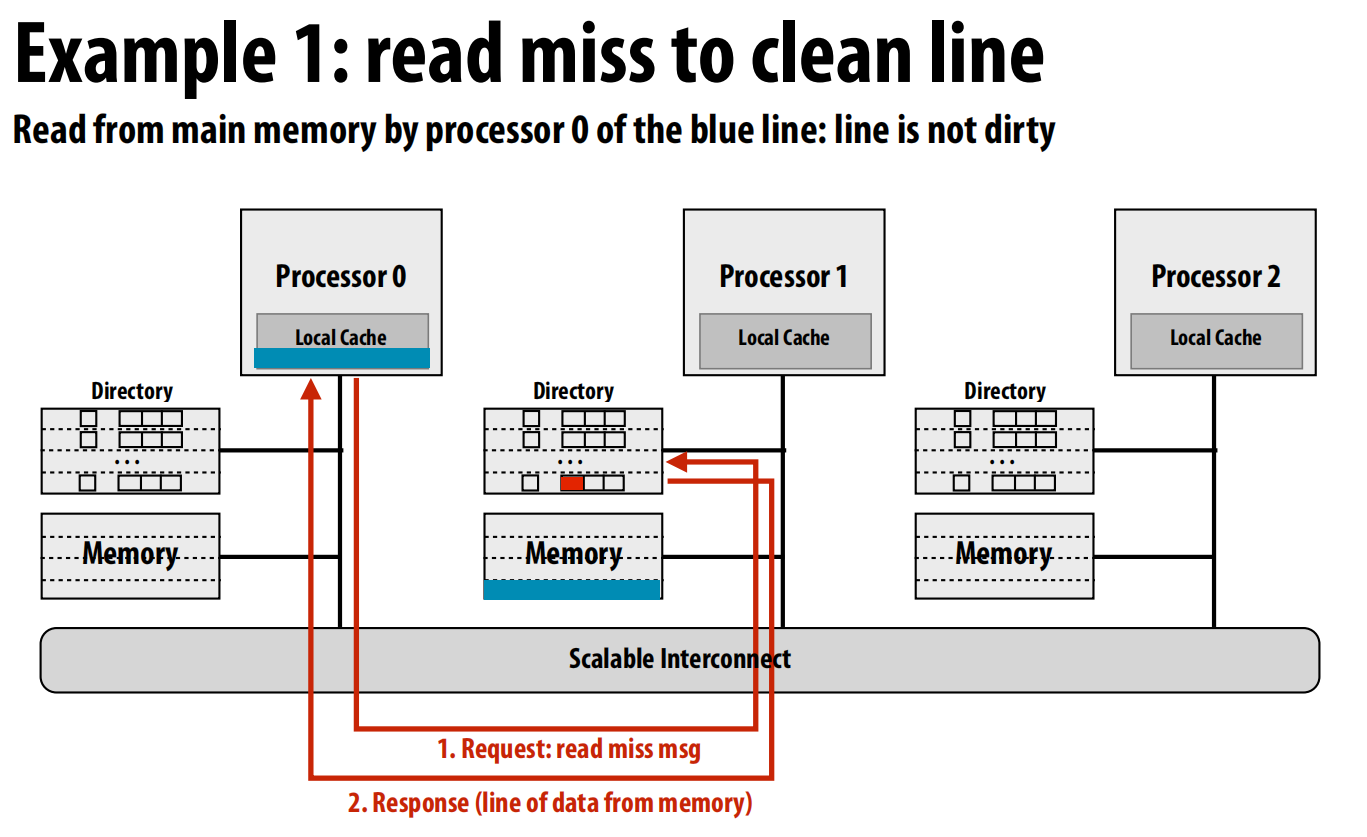
-
示例 1: 读取一个“干净”的行 (Read miss to a clean line)
- 请求: P0的缓存未命中,它向该行的归属节点(这里是Node 1)发送一个读请求消息 。
- 响应: Node 1的目录控制器检查目录条目,发现数据是干净的。它直接从本地内存中读取数据,然后将数据发送给P0 。同时,它更新目录条目,将P0对应的存在位置为true 。
-
示例 2: 读取一个“脏”的行 (Read miss to a dirty line) 最新的数据不在内存中,而是在另一个处理器的缓存里(这里是P2)。
- 请求: P0向归属节点 (Node 1) 发送读请求 。
- 转发信息: Node 1的目录发现脏位是开启的,并且所有者是P2 。它不能直接从内存提供数据,而是回复P0,告诉它行的所有者是P2 。
- 二次请求: P0向所有者P2发送请求,索要数据 。
- 数据响应: P2将数据发送给P0。同时,因为现在数据被共享了,P2将自己缓存中该行的状态从“已修改”降级为“共享”(只读)。
- 目录更新: P2还会向归属节点Node 1发送一份最新的数据和更新信息。Node 1收到后,更新自己的内存,清除脏位,并更新存在位(现在P0和P2都缓存了该行)。
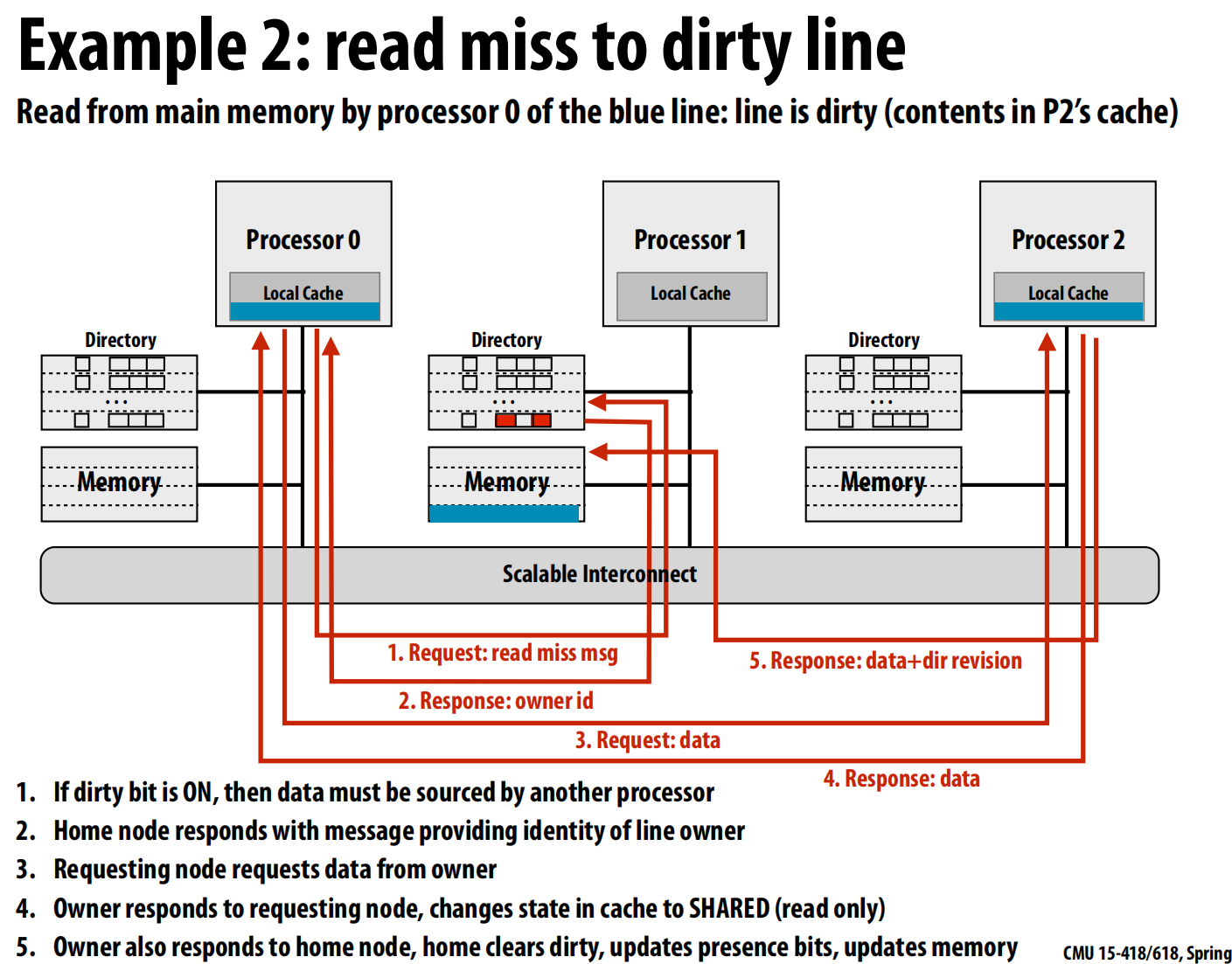
-
示例 3: 写未命中 (Write miss) 假设P0要写入一个行,该行目前是干净的,但被P1和P2共享。
- 请求: P0向归属节点 (Node 1) 发送一个写请求(请求独占访问权)。
- 获取共享者列表: Node 1的目录查到P1和P2是当前的共享者。它将共享者列表(P1, P2)和数据发送给P0 。
- 发送作废请求: P0向列表中的所有共享者(P1和P2)发送作废(invalidate)消息 。
- 等待确认: P1和P2收到作废消息后,将本地副本置为无效,并向P0发回确认(ack)消息 。
- 完成写入: P0在收到所有共享者的确认后,才能安全地进行写入操作,并将自己的缓存行状态置为“已修改” 。
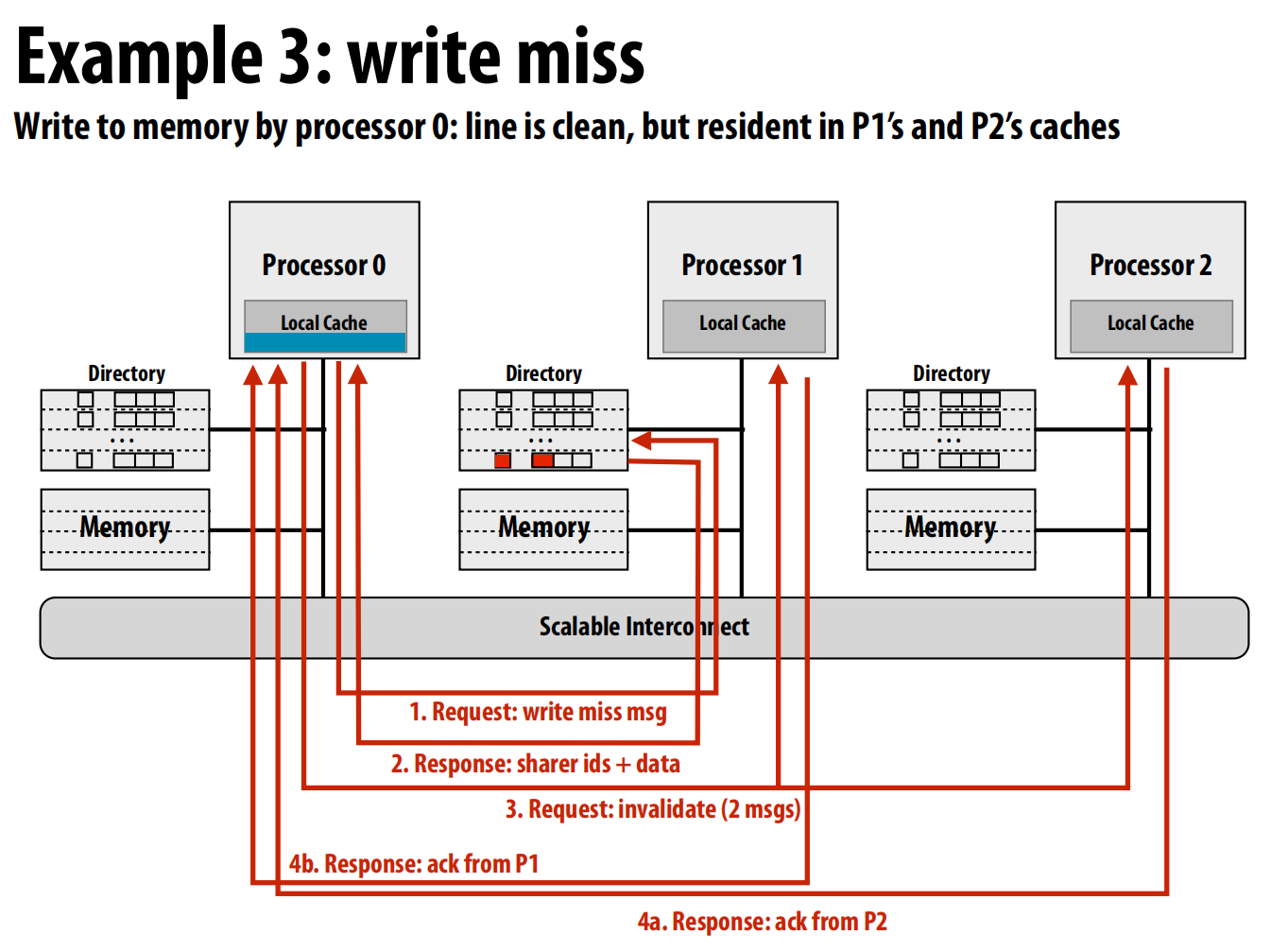
可以看出目录的优势:所有通信都是点对点的,而不是点对面。
但目录也有很多劣势,比如多占用了很大一块空间等。
改进:
- 有限指针方案 (Limited Pointer Schemes):
- 核心思想: 既然共享者数量通常很少,我们不需要为所有处理器都保留一位,而是只存储少数几个指向共享者的指针即可 。
- 例子: 对于一个1024核系统,全比特向量需要1024位。而使用指针,每个指针需要
log₂(1024) = 10位。如果只存8个指针,开销会大大降低 。 - 溢出处理: 当共享者数量超过指针数量时怎么办?
- 回退到广播(如果系统支持)。
- 不允许超过最大共享者数量,新来的请求者会替换掉一个旧的共享者(强制其失效)。
- 使用粗粒度向量,一个比特代表一组处理器 。
- **稀疏目录方案 (Sparse Directories) **:
- 核心观察: 在任何时刻,主内存中的绝大部分数据都未被任何缓存所缓存 。
- 解决方案: 只为那些当前正被缓存的内存行创建目录条目,而不是为所有内存行都创建 。这极大地减少了目录所需的总条目数。目录本身就像一个缓存,有自己的标签(Tag)来标识它描述的是哪一个内存行 。
优化消息传递路径
让我们再次审视“读取脏行”这个最复杂的场景。基础方案需要5次网络传输,其中4次在关键路径上 。
-
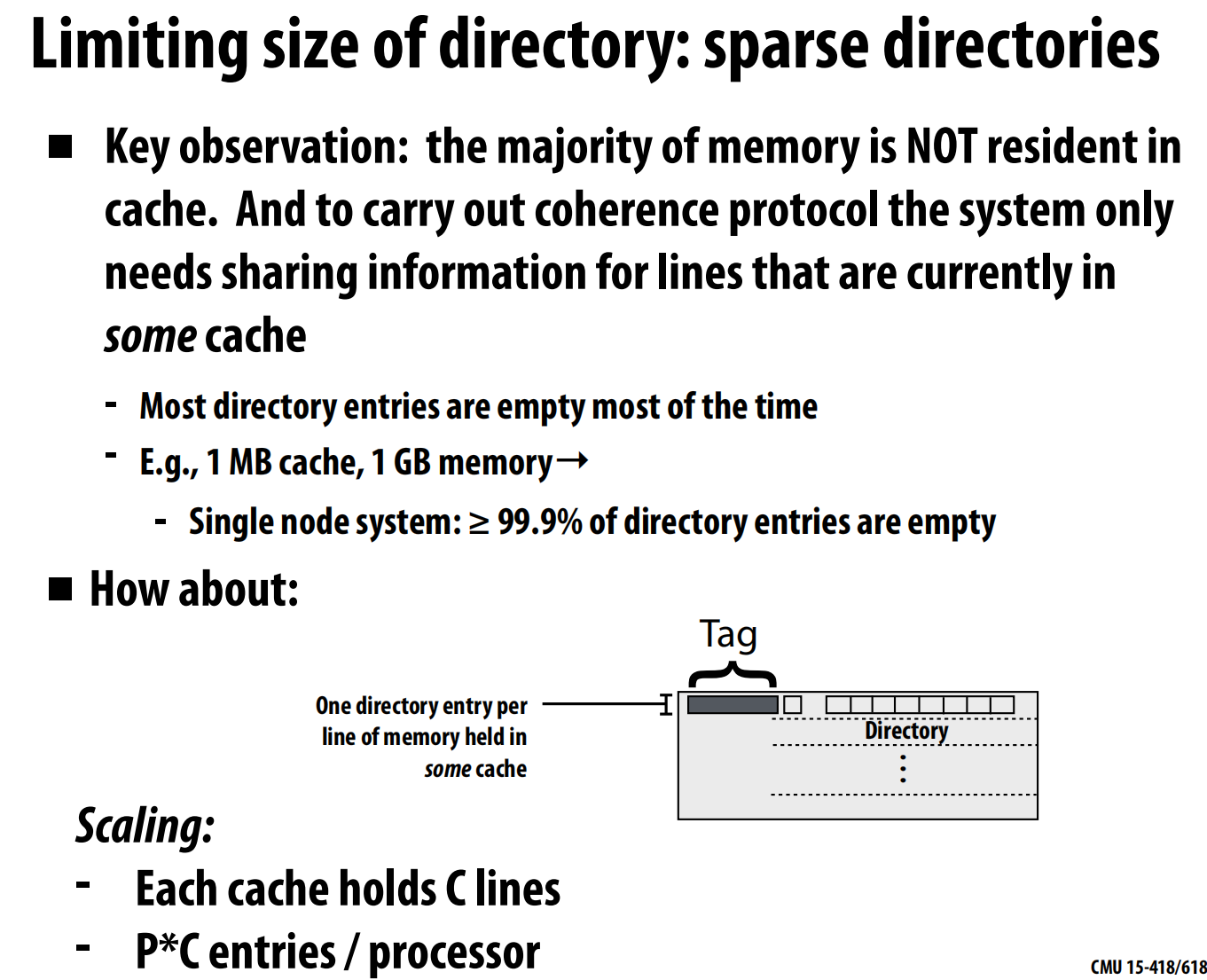
干预转发 (Intervention Forwarding):
- 流程: 请求节点 -> 归属节点 -> 所有者节点 -> 归属节点 -> 请求节点。
- 效果: 归属节点“干预”并协调数据传输。总消息数减少到4条,但关键路径仍然是4条 。
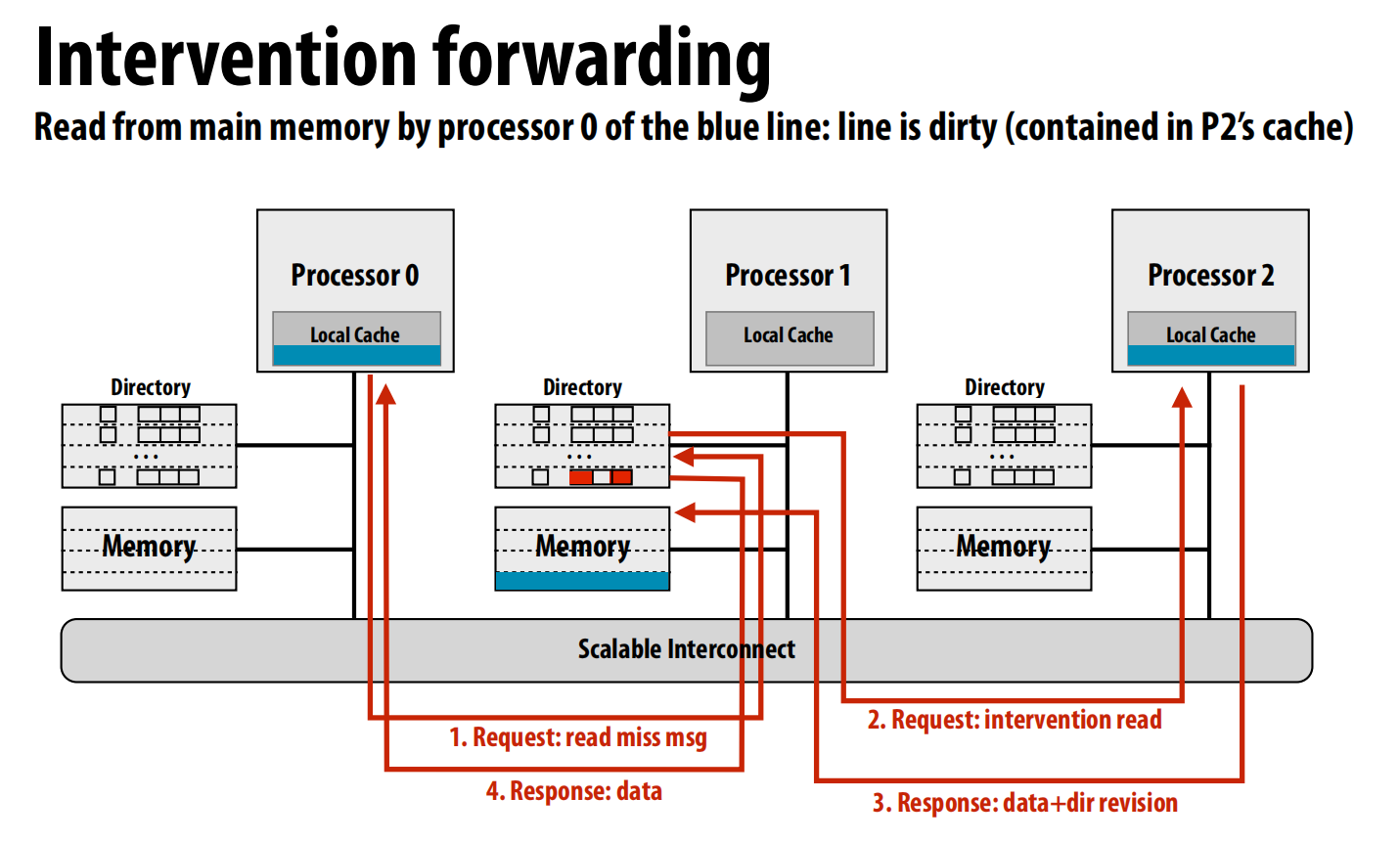
-
请求转发 (Request Forwarding):
- 流程: 请求节点 -> 归属节点。归属节点直接将请求“转发”给所有者节点,并指示所有者直接将数据发送给请求节点。所有者节点同时向归属节点发送更新。
- 效果: 这是最高效的方式。总消息数仍为4条,但关键路径缩短为3跳(请求节点->归属节点->所有者节点->请求节点)。
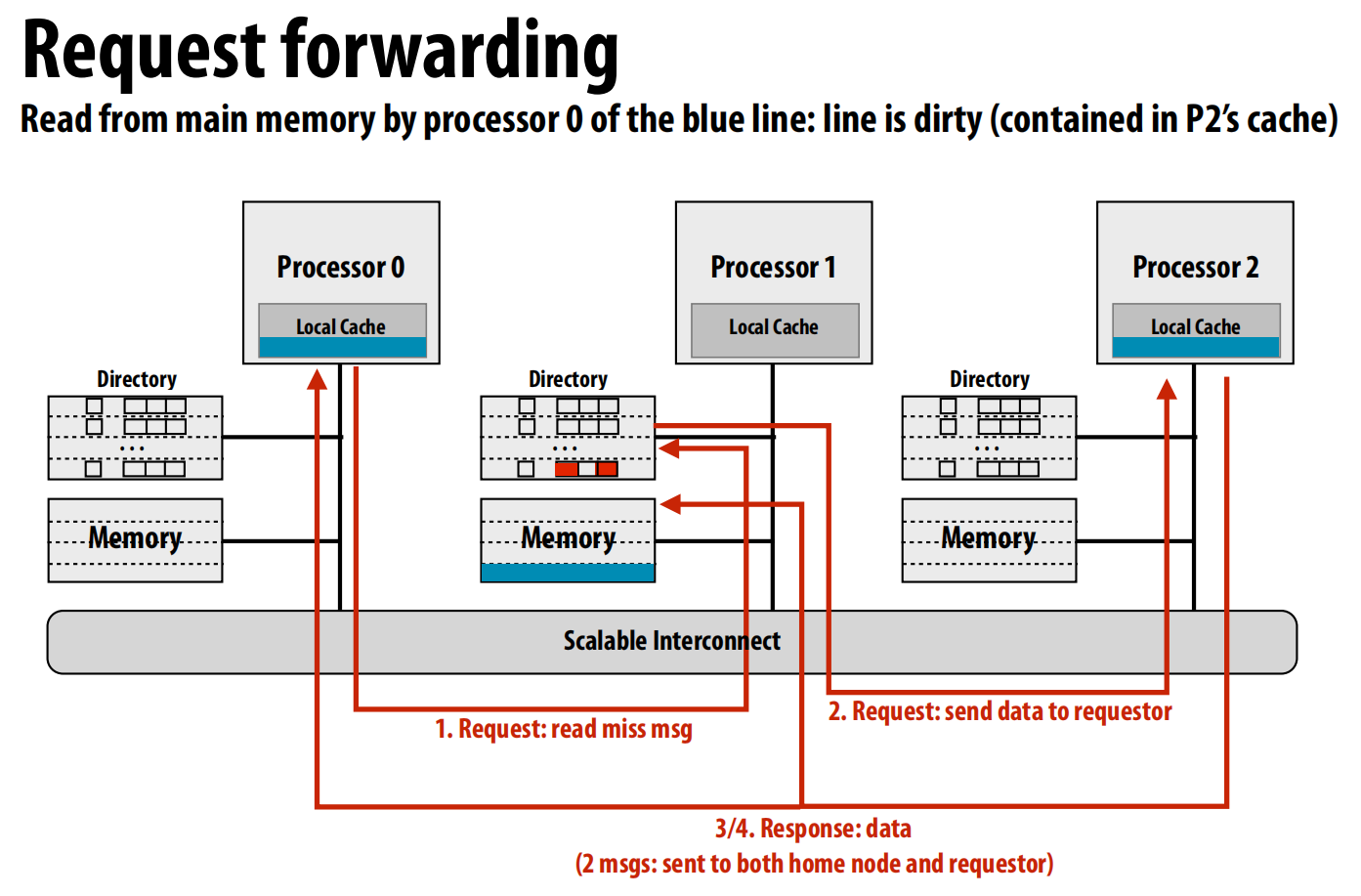
真实案例:
Intel Core i7 (单芯片):
- 共享的L3缓存扮演了目录的角色 。
- 它维护一个列表,记录了哪些核心的L2缓存中含有某一行 。
- 这样,一致性消息只需点对点地发送给真正持有该行的L2缓存,而不是广播到所有L2 。
Intel多路服务器系统:
- 使用位于内存中的目录(由归属代理/内存控制器缓存)来减少跨芯片(socket)的一致性流量 。
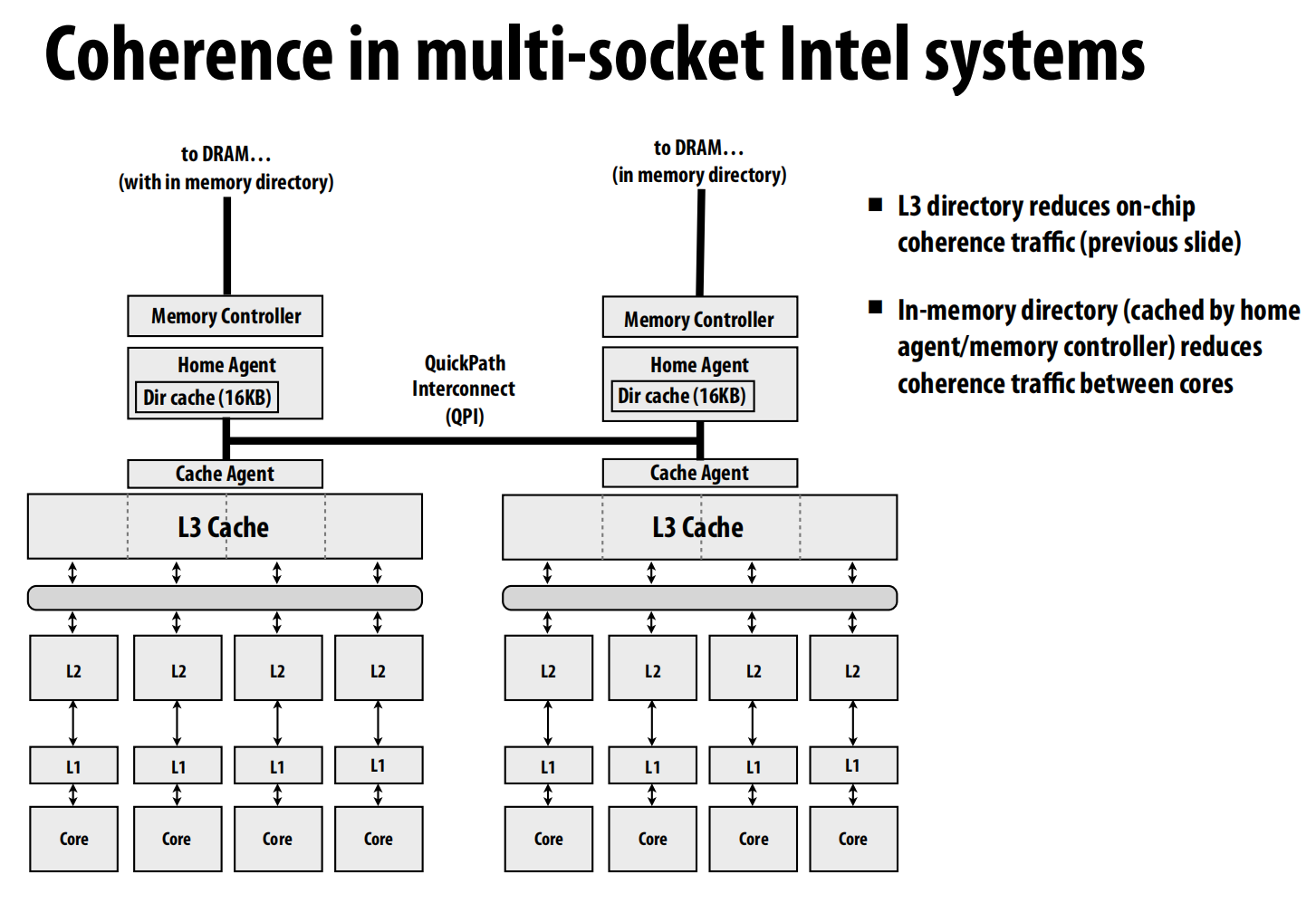
Intel Xeon Phi (协处理器):
-
Knight’s Corner: 拥有超过50个x86核心 ,通过一个双向环形互连 (bidirectional ring) 连接 。分布式标签目录 (Tag Directories, TD) 跟踪所有L2缓存中的缓存行 。
-
Knight’s Landing: 下一代产品,拥有72个核心 ,组织成一个
2D网格 (2-D mesh) 互连 。这种拓扑结构必须使用更传统的点对点目录协议方案,因为网格不适合广播 。
lec12 Snooping implementation
现在我们对于监听的方案(bus总线的方案)做具体实现。
需要发送哪些消息(如BusRdX, flush),并假设这些消息和状态转换是原子操作 (atomic) 。
多级缓存与包含属性 (Inclusion Property): 真实系统如Intel Core i7拥有多级缓存(L1, L2, L3)。为了让监听协议在多级缓存下高效工作,通常需要维护
包含属性,即L1缓存的内容是L2缓存内容的子集 。这使得只需要L2缓存去监听互连总线就足够了 。
维护包含性: 包含属性并非自动满足,因为L1和L2的替换策略可能不同,导致一个行在L1中被保留但在L2中被驱逐 。为了强制维护包含性,需要额外的硬件逻辑 :
- 处理外部作废: 当L2因监听到
BusRdX而使其行X失效时,它必须也通知L1使其行X失效 。这可以通过在L2的缓存行中增加一个“in L1”位来实现 。 - 处理L1写命中: 当L1是写回缓存时,处理器对L1中行X的写入会使其变“脏”,但L2中的数据此时就变成了“过时的 (stale)”数据 。当L2需要冲刷(flush)该行时,它必须先从L1获取最新的数据 。这可以通过增加一个“modified-but-stale”(已修改但已过时)位来解决 。
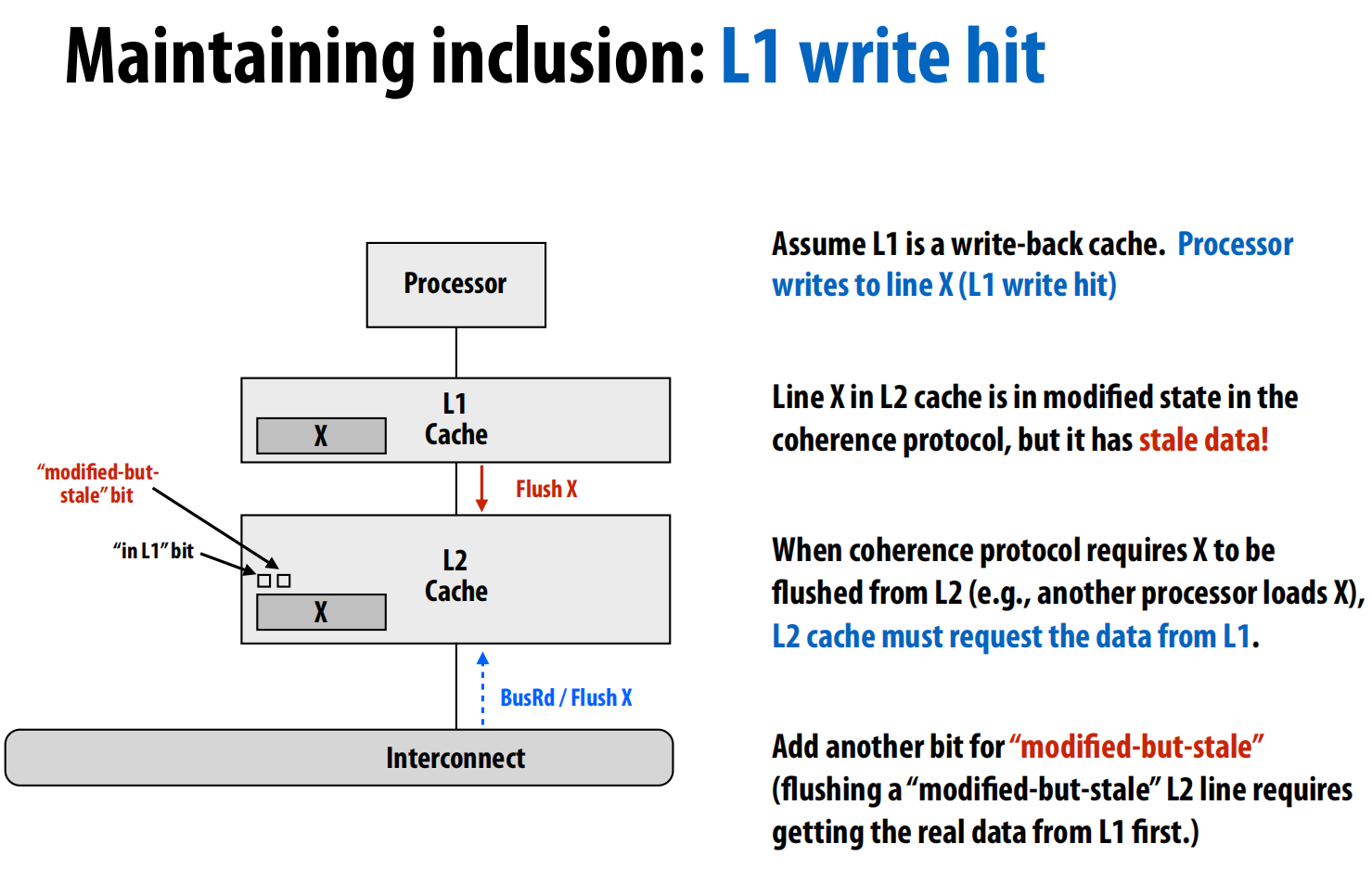
一些概念:
1. 死锁 (Deadlock)
- 发生死锁的四个必要条件:
- 互斥 (Mutual exclusion): 资源一次只能被一个进程持有 。
- 持有并等待 (Hold and wait): 进程在等待其他资源的同时,继续持有已经获得的资源 。
- 不可抢占 (No preemption): 资源不能被强制性地从持有它的进程中剥离 。
- 循环等待 (Circular wait): 存在一个进程等待链,形成一个环路 。
2. 活锁 (Livelock)
- 定义: 活锁是指系统中的线程或进程虽然在不断地执行操作,但没有做出任何有意义的进展 。一个常见的例子是两个人在狭窄的走廊相遇,两人同时向同一边避让,然后又同时向另一边避让,来回重复,谁也过不去。在计算机系统中,这常常表现为操作不断地中止和重试 。这容易被提添加随机性解决,但这会减慢速度。
3. 饥饿 (Starvation)
-
定义: 饥饿是指系统整体在取得进展,但某个或某些进程却始终无法获得所需资源,从而无法取得进展 。这本质上是一个
公平性 (fairness) 问题 。例如,在一个十字路口,如果规则规定南北向的车辆(绿车)拥有绝对优先权,那么东西向的车辆(黄车)可能会一直等待,无法通过 。
基于原子总线的基本实现
1. 系统假设
- 每个处理器只有一个单级写回缓存,且一次只能有一个未完成的内存请求 。
- 互连是一个原子共享总线,意味着一次只有一个缓存可以通信 。一个总线事务(如BusRd)会占用总线,直到数据返回,期间不允许其他事务介入 。
2. 实现中的挑战与解决方案
- 缓存标签争用: 缓存的标签(Tags)是一个共享资源,本地处理器需要访问它来处理加载/存储,而监听控制器也需要访问它来响应总线上的请求 。
- 解决方案: 复制一套标签,或者使用多端口的标签存储器 。这两种方法都需要额外的硬件成本来换取性能 。

- 报告监听结果: 当一个缓存发起总线请求时(如BusRd),所有其他缓存如何集体报告它们的状态(例如,“我有脏数据”或“我是共享的”)?
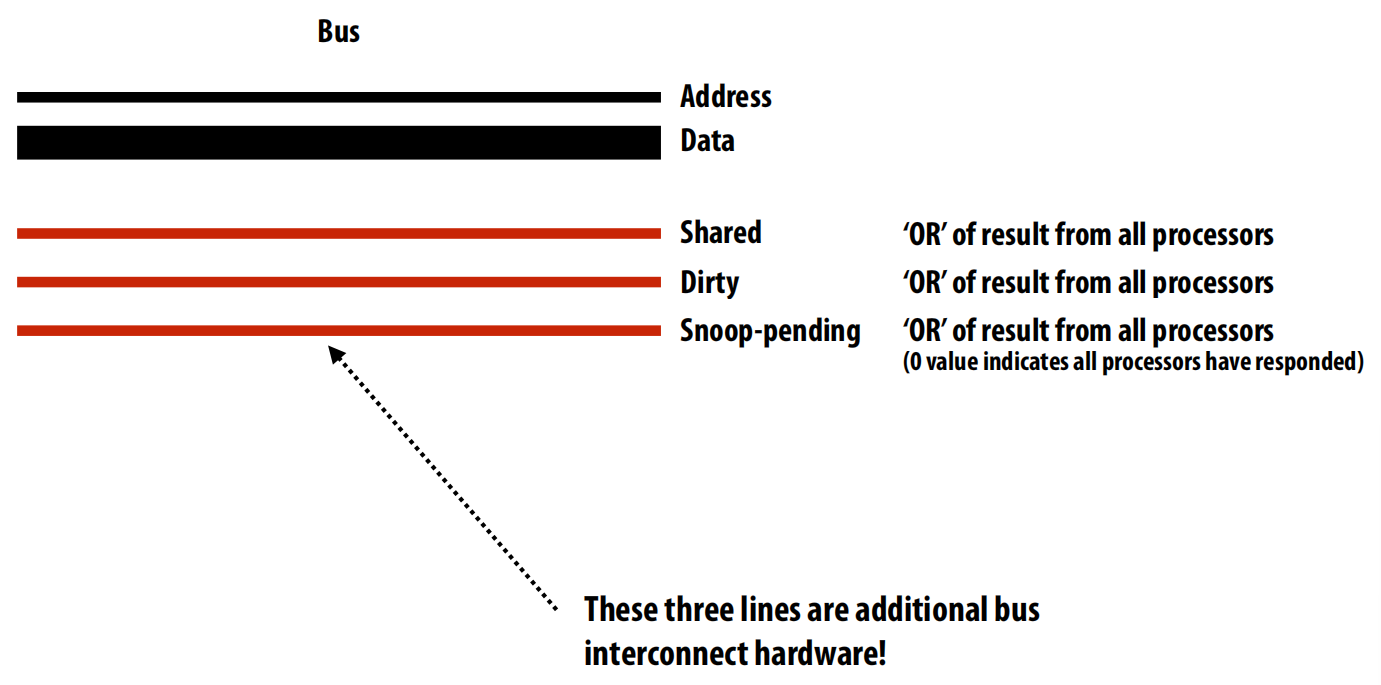
- 解决方案: 使用额外的总线线路,如
Shared和Dirty线,它们像一个“线或”(wired-OR)电路一样工作,任何一个缓存拉高这条线,总线上的所有参与者都能看到 。这使得请求者和内存控制器能够知道如何正确处理请求 。
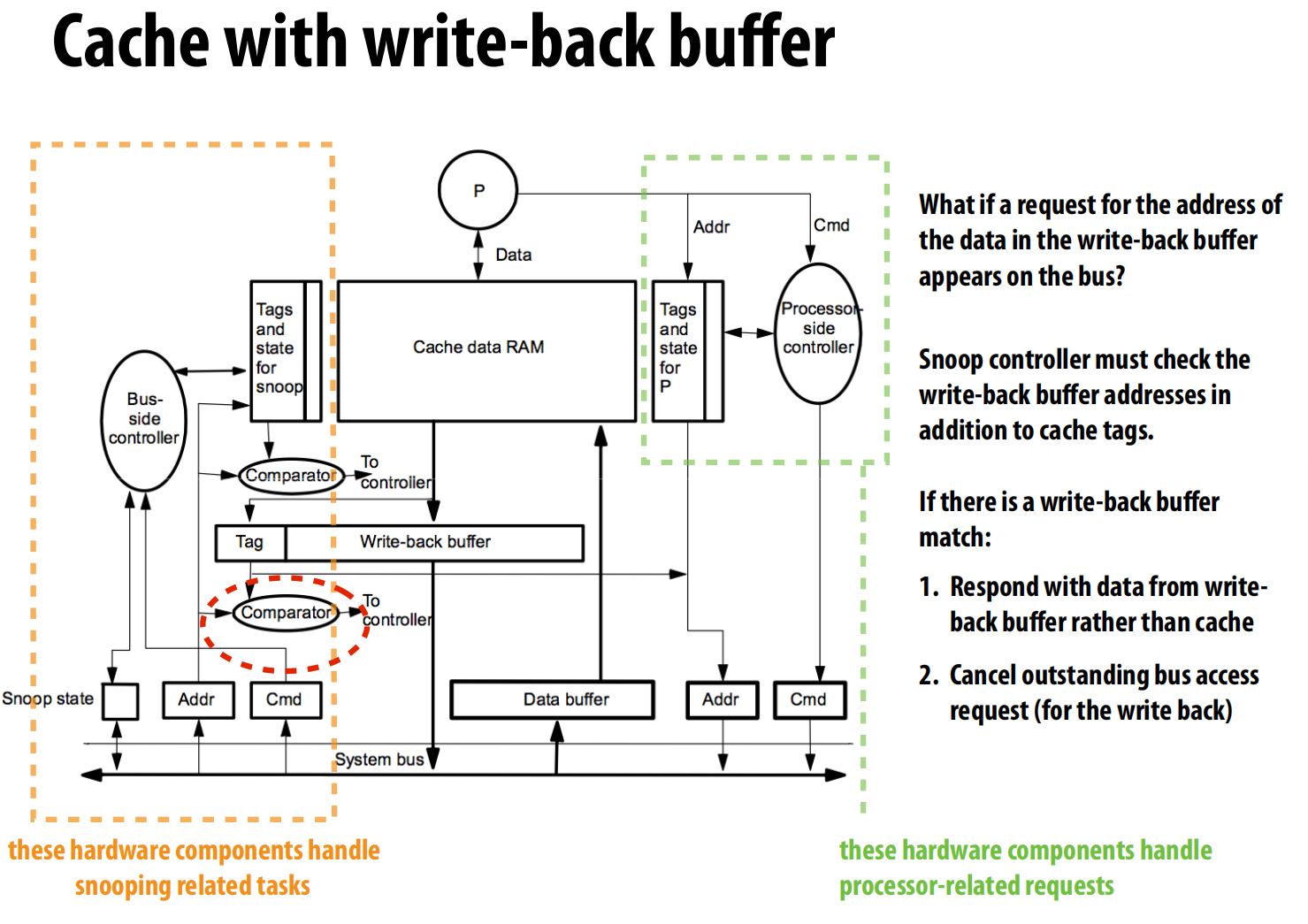
- 处理写回: 当一次缓存未命中需要驱逐一个“脏”行时,我们不希望处理器等待漫长的写回过程 。
- 解决方案: 使用写回缓冲区 (write-back buffer) 。脏行被放入缓冲区,处理器可以立即加载新数据并继续执行 。缓冲区的内内容稍后再写入内存 。
- 新问题: 监听控制器现在不仅要检查缓存标签,还必须检查写回缓冲区的内容 。
- 非原子状态转换与竞争条件: 协议图中的状态转换在现实中并非原子操作,它涉及一系列步骤(仲裁总线、等待响应等),这会引发竞争、死锁和活锁 。
-
竞争条件: 两个处理器P1和P2同时想升级一个S状态的行。P1赢得总线并发送
BusUpg。P2在等待总线的同时,监听到P1的请求,它必须作废自己的副本,并且把自己的待发请求从BusUpg改为BusRdX。这要求缓存控制器逻辑非常复杂。 -
取指死锁 (Fetch Deadlock): P1需要为A行腾出空间而写回脏行B,但此时总线上出现了对B行的读取请求。P1被卡住了。为避免死锁,缓存必须能够在等待发出自己请求的同时,还能服务传入的请求 。
-
活锁: P1获得总线并为B行发送
BusRdX,P2作废其副本。但在P1真正写入之前,P2又获得了总线并为B行发送BusRdX,导致P1作废其副本,如此往复。为避免活锁,一个获得了独占权的写操作必须被允许完成,然后才能放弃独占权 。
-
基于非原子(分离事务)总线的实现
1. 动机与核心思想
- 问题: 原子总线效率低下,因为它在等待响应(如内存读取)时处于空闲状态,浪费了宝贵的总线带宽 。
- 解决方案: 分离事务总线 (Split-transaction bus) 。将一个事务拆分为两个独立的部分:请求和响应 。在请求和响应之间,总线可以用于处理其他事务,从而提高利用率 。
2. 新的挑战与设计
分离事务总线引入了新的问题:如何匹配请求和响应?如何处理冲突请求?如何进行流控制?
- 设计:
- 总线可以看作两个独立的总线:请求总线和响应总线 。
- 使用一个所有总线客户端(如缓存)都维护的请求表 (Request Table) 。当一个请求被批准时,总线仲裁器会给它分配一个唯一的事务标签 (transaction tag),这个标签就是它在请求表中的索引 。后续的响应会带上这个标签,以便请求者进行匹配。
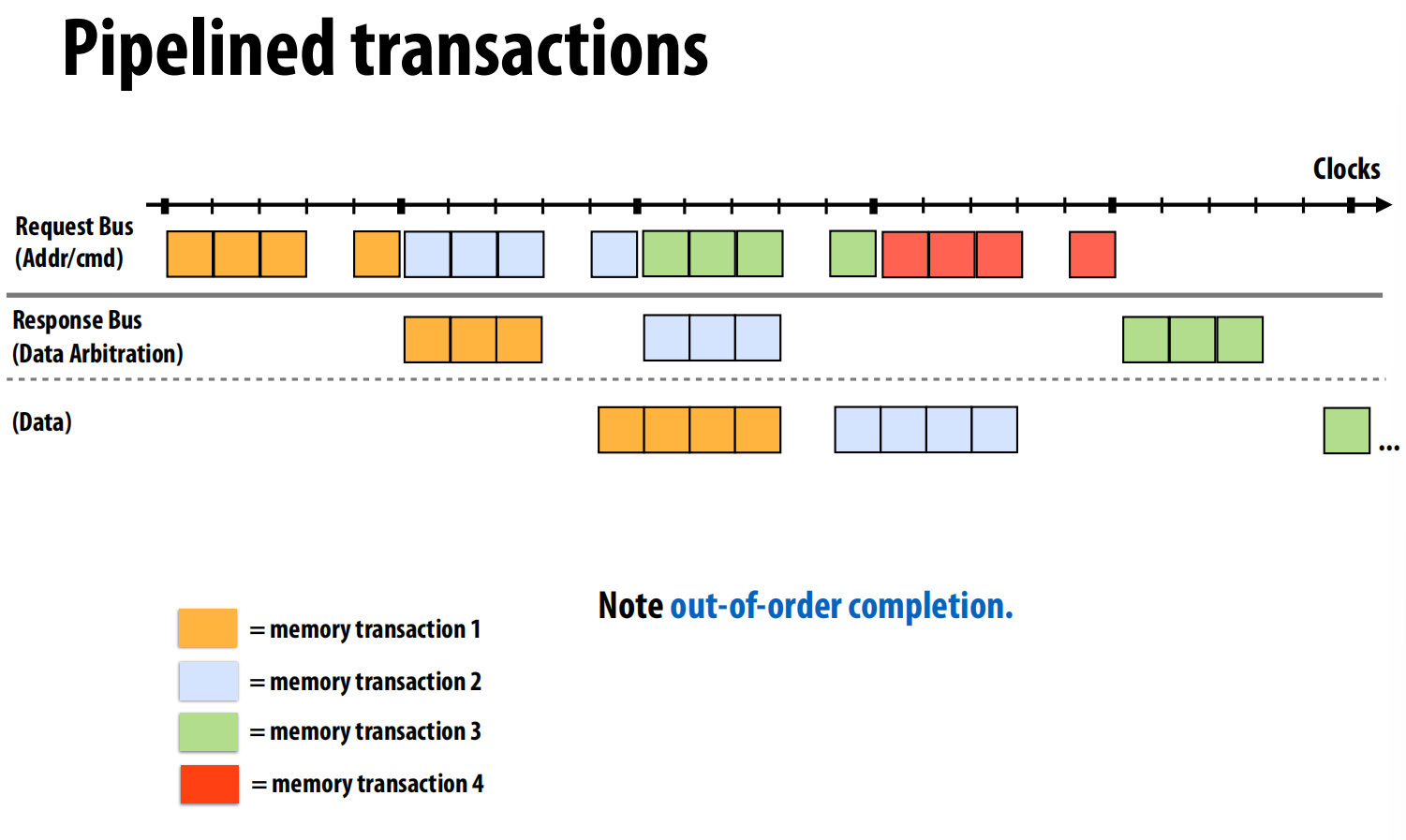
- 流水线事务: 这种设计使得多个事务可以在总线上流水线式地进行,极大地提高了总线吞吐量 。
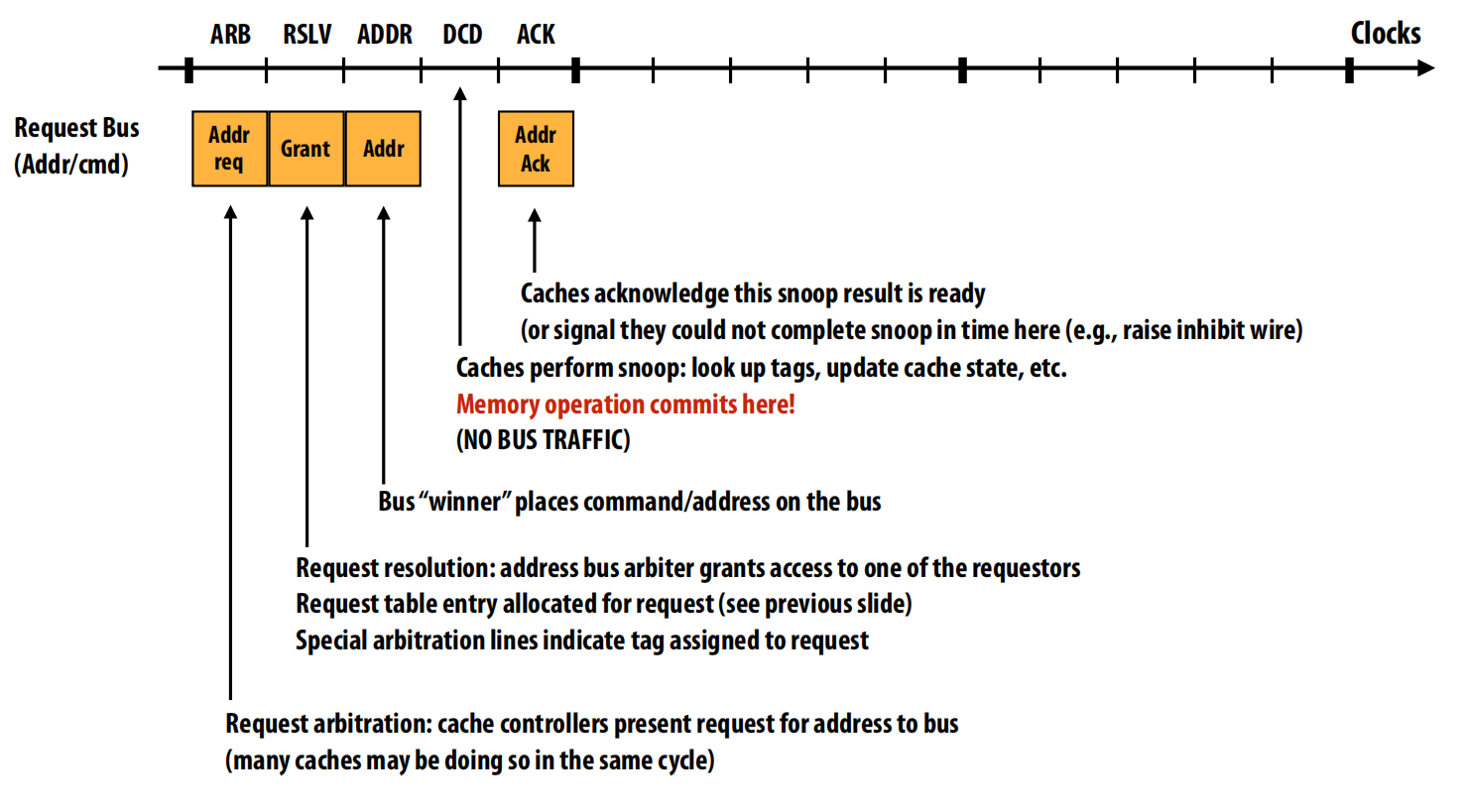
第一阶段:请求与提交 (顶部图表)
目标:请求方(某个处理器的缓存)向总线上的所有参与者宣告它需要读取某个地址,并在此过程中确定这个操作在整个系统中的全局顺序。
这个阶段只发生在请求总线 (Request Bus) 上,具体步骤如下:
- ARB (Arbitration - 仲裁):一个或多个缓存控制器同时向总线仲裁器发出总线使用请求 (
Addr req) 。 - RSLV (Resolution - 解决):总线仲裁器在所有请求者中选择一个“胜利者”,并授予它总线访问权 (
Grant) 。同时,系统会为这次事务分配一个唯一的事务标签 (transaction tag),并在所有缓存控制器维护的请求表 (Request Table) 中为它分配一个条目 。 - ADDR (Address/Command - 地址/命令):赢得了总线访问权的缓存控制器将它要执行的命令(例如
BusRd- 总线读取)和目标内存地址放到总线上 。 - DCD (Decode - 解码) & Snoop (监听):总线上所有其他的缓存控制器监听到这个地址和命令,开始执行监听操作,例如检查自己的缓存标签,确定是否持有该数据的副本 。
- ACK (Acknowledge - 确认):所有缓存控制器完成监听操作后,在总线上发出确认信号,表示它们的监听结果已经准备就绪 。
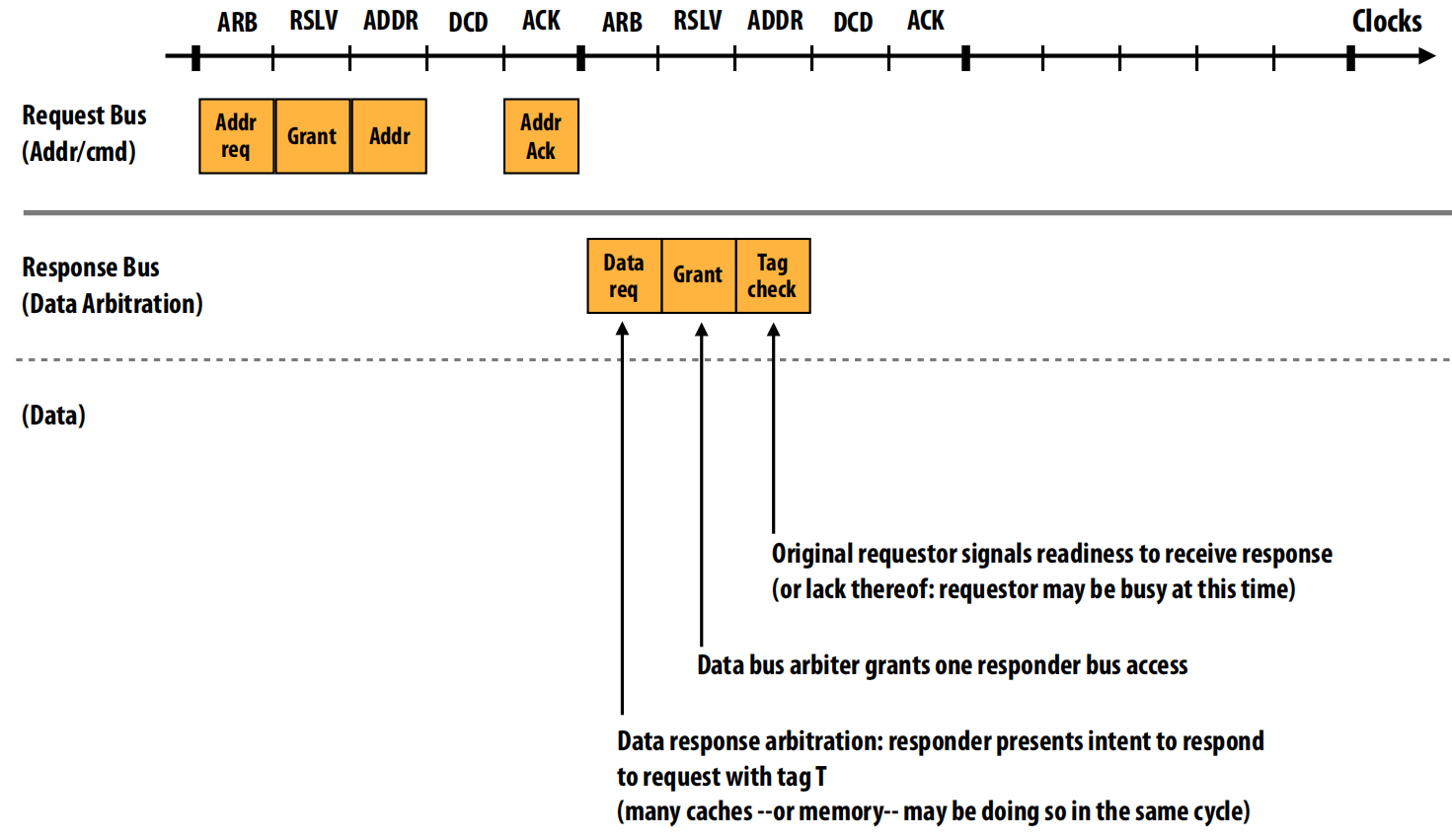
第二阶段:响应仲裁 (中部图表)
目标:在请求提交后,真正持有数据的部件(可能是主内存,也可能是另一个持有“脏”数据的缓存,我们称之为“响应方”)需要获取响应总线 (Response Bus) 的使用权,以便将数据发回。
这个阶段发生在响应总线上。
- Data req (数据请求):一个或多个响应方(如果多个缓存都能提供数据)表明它们准备好为某个带有特定标签
T的请求提供数据了,因此向数据总线仲裁器请求总线使用权 。 - Grant (授予):数据总线仲裁器在所有潜在的响应方中选择一个,并授予它响应总线的访问权 。
- Tag check (标签检查):最初的请求方此时会收到通知,它需要确认自己是否已准备好接收数据 。这是一个流控制机制,如果它的接收缓冲区已满,它可能会暂时拒绝接收 。
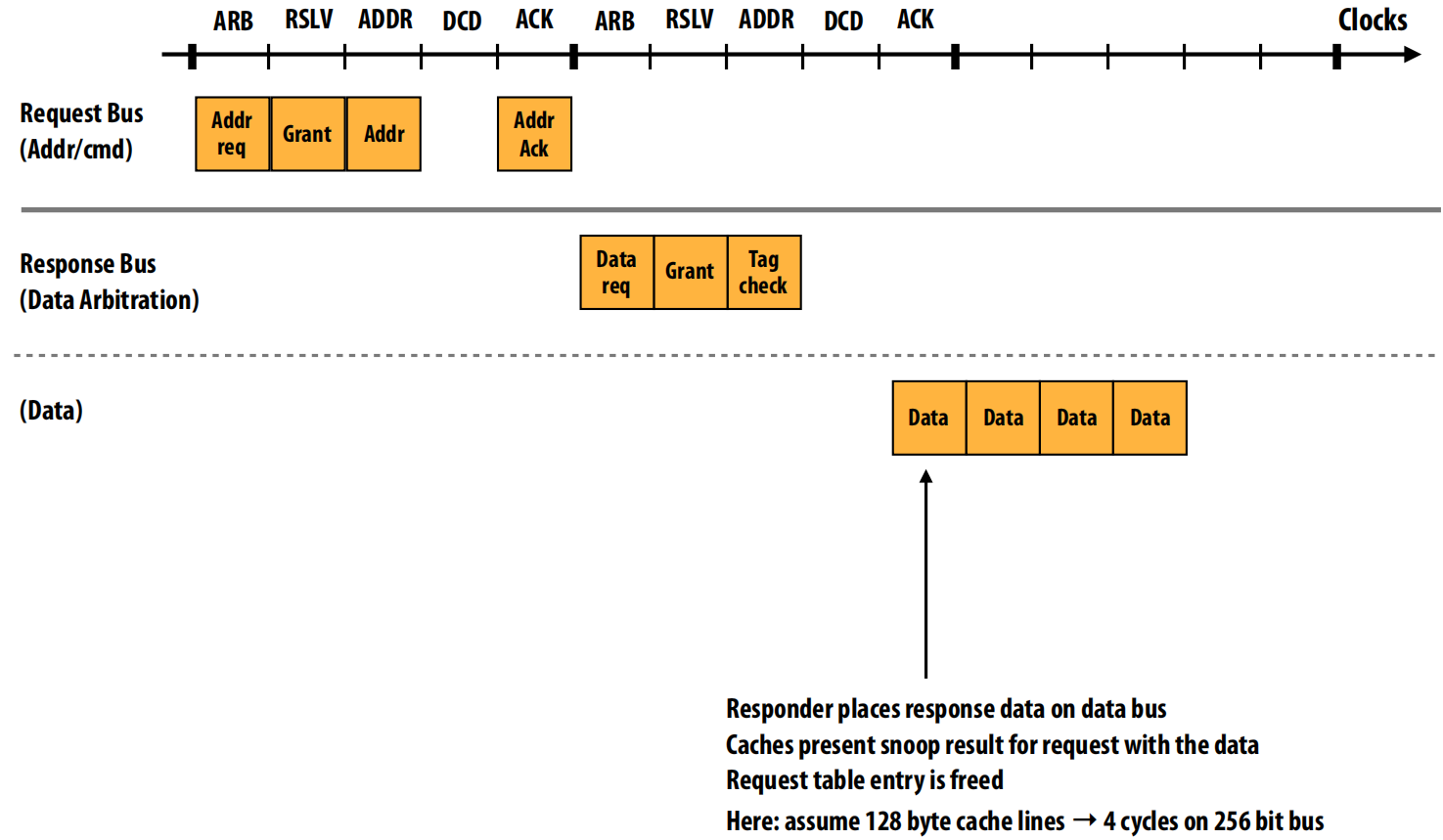
第三阶段:数据传输 (底部图表)
目标:将实际的数据从响应方传输给请求方,完成整个内存读取操作。
这个阶段发生在响应总线的数据通道上。
- Data Transfer (数据传输):赢得了响应总线访问权的响应方,将数据放到数据总线上进行传输 。
- 多周期传输:这个传输通常需要多个时钟周期。图示中显示了4个周期。这是因为总线的宽度是有限的。例如,假设总线宽度是256位(即32字节),而一个缓存行是128字节,那么传输整个缓存行就需要
128 / 32 = 4个时钟周期 。 - 完成操作:数据传输完毕后,所有相关的监听结果也会被处理,并且该事务在请求表中的条目会被释放,标志着这次内存读取操作彻底完成 。
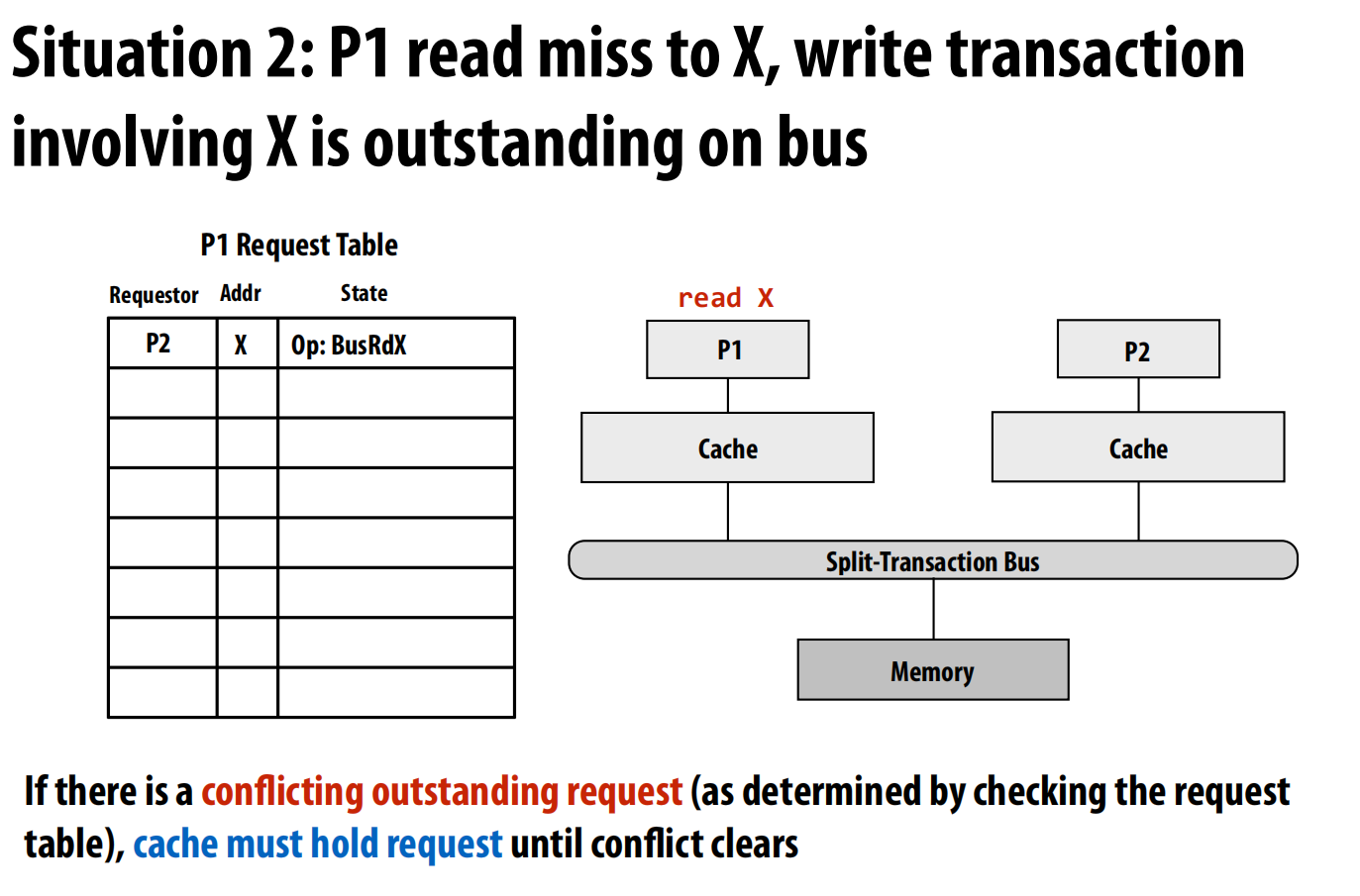
- 冲突处理: 缓存通过检查请求表来避免发起冲突的请求 。例如,如果P1看到请求表中已经有P2对地址X的写请求,它就会暂停自己对X的读请求,直到冲突清除 。
- 流控制: 如果接收缓冲区已满,客户端可以NACK (Negative Acknowledgement) 一个请求,强制发送方稍后重试 。
队列与死锁的最终解决方案
- 队列的作用: 在并行系统中,队列用于缓冲生产者和消费者之间不稳定的速率,只要平均速率匹配,队列就可以让双方都以最大效率运行,避免不必要的等待 。
- 队列导致的死锁: 在多级缓存中,L1和L2之间通过请求/响应队列通信。如果L1到L2的请求队列满了,同时L2到L1的响应队列也满了,就可能发生死锁,因为请求的响应需要占用对方的队列空间,形成了循环依赖 。
- 解决方案: 使用独立的请求和响应队列 。关键在于:
- 请求会增加队列的负担(产生新工作)。
- 响应则会减少队列的负担(完成旧工作),并且响应本身不会再产生新的事务 。
- 因此,即使一个缓存因为请求队列满而无法发送新请求,它仍然可以处理传入的响应。处理响应最终会释放缓冲区空间,从而打破循环依赖,避免死锁 。
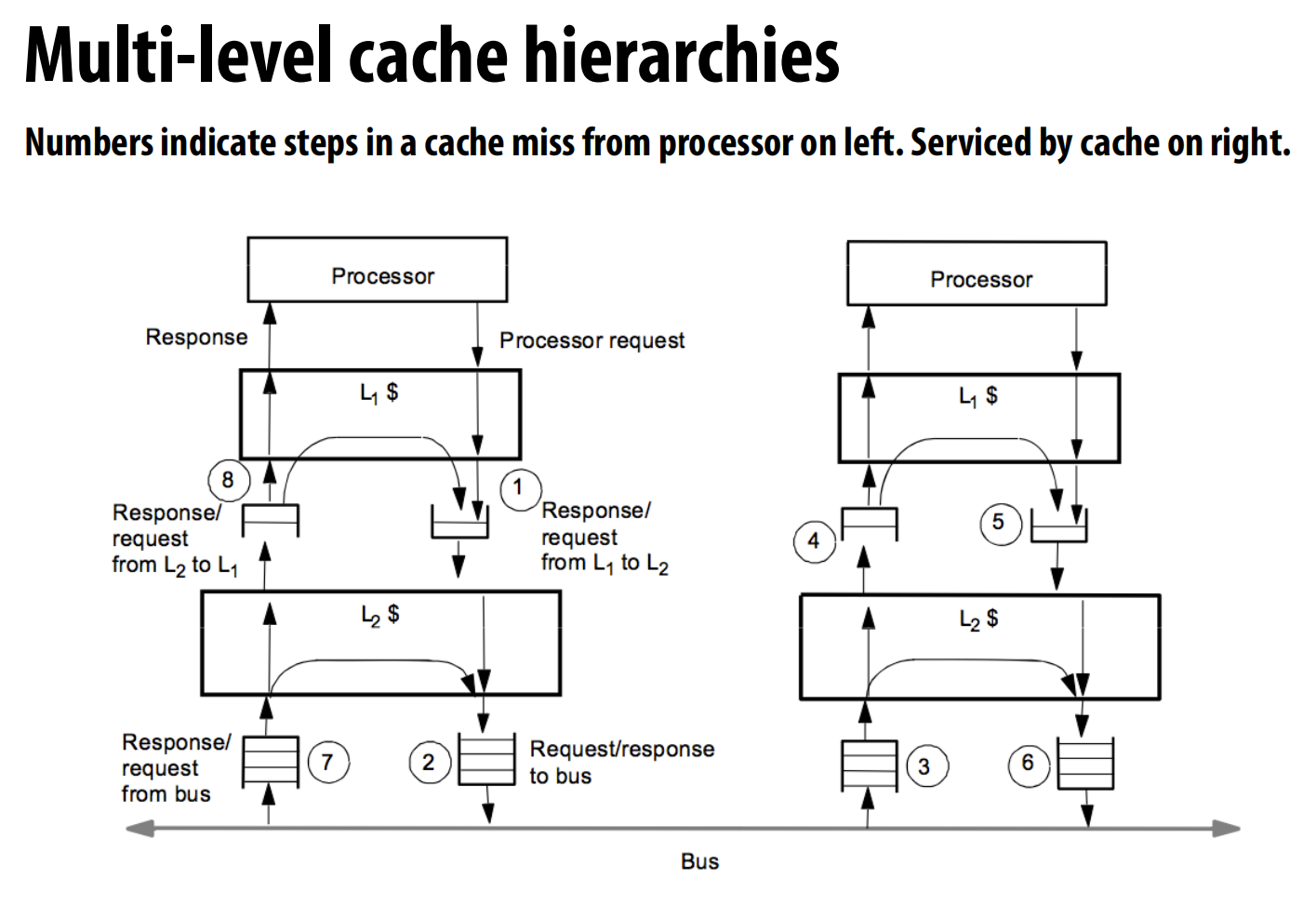
Recitation Matrix-vector Product, OMP programming


在omp for之后会默认填充一个barrier,如果不想加,可以写一个nowait:#pragma omp for nowait

归约操作指的是将一大组值(通常由多个线程并行计算得出)合并、简化成一个单一的最终值的过程 。
1 |
|
static(静态):工作分配在循环开始执行之前就一次性完成了,并且在循环执行过程中不会改变。
dynamic (动态调度):迭代也被分成块,但不是预先分配好的。任何线程完成自己的块后,会主动去任务池里领取下一个可用的块来执行。这种方式能很好地处理负载不均问题,但调度开销比static高。
guided (导向式调度):一种static和dynamic的混合策略。开始时分配的块很大,随着剩余任务的减少,分配的块越来越小。它试图在低开销和负载均衡之间取得平衡。
auto (自动调度):让编译器和运行时系统根据它对代码的分析,自动选择最佳的调度策略。
runtime (运行时决定):不在编译时确定策略,而是在程序运行时根据环境变量来决定,方便用户在不重新编译程序的情况下调优。
schedule(static, chunk_size)
当指定了块大小 chunk_size 后,OpenMP 会将迭代按指定的 chunk_size 分成很多个小块,然后像发牌一样,以轮询(round-robin)的方式把这些小块依次分配给每个线程。(发牌,轮流领取一块)
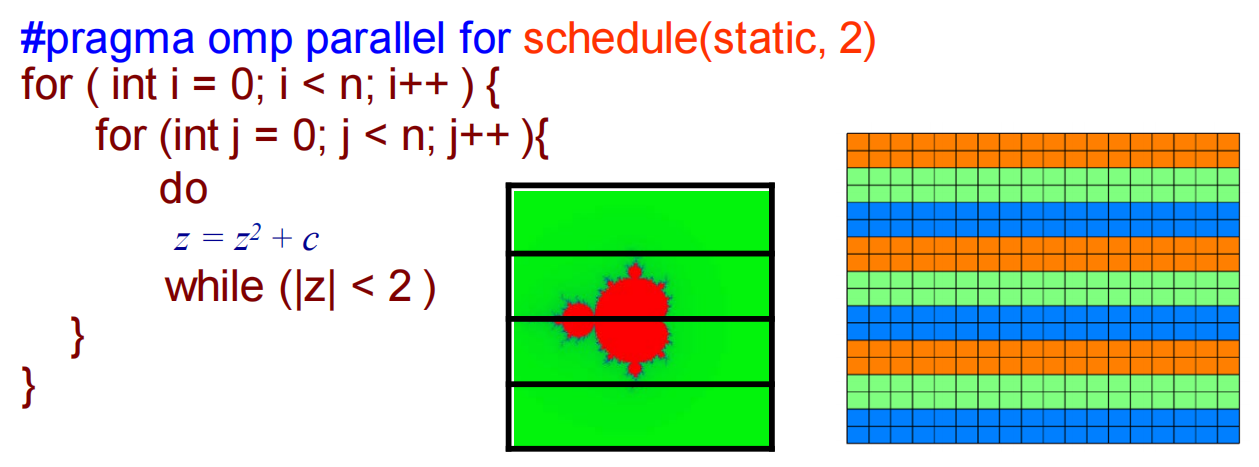
schedule(dynamic, chunk_size)
分块,但是做完了再来拿,能者多劳

- 在并行区域之外分配内存:像
malloc这样分配堆内存的操作,通常在程序的主线程中、进入并行计算前一次性完成。 - 在并行区域之内初始化数据:不要让主线程串行地初始化所有数据,而应该让所有线程并行地去完成初始化工作,每个线程负责初始化它未来将要处理的那部分数据。
“首次接触”策略 (First-Touch Policy) 操作系统在为程序分配物理内存时,普遍采用“首次接触”策略。这意味着,当一个线程第一次写入(接触) 某一块内存页时,操作系统会倾向于将这块内存页分配到该线程所在CPU核心的本地内存上。

malloc分配的是虚拟空间,后面初始化是真正分配物理内存的时候,此时会把这个东西的内存确定在线程所在的cpu,这样可以提高性能。
lec13 Memory consistency
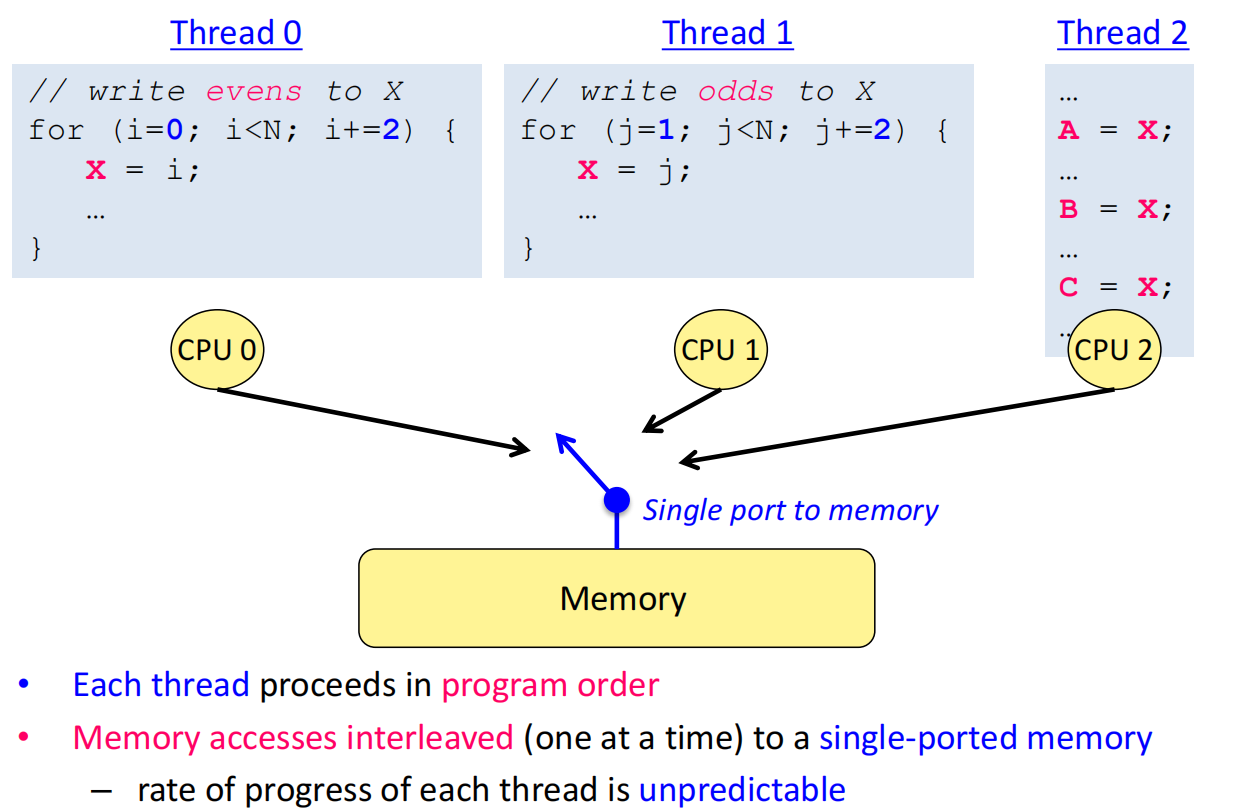


隐藏延迟的技术
- 写缓冲 (Write Buffer):为了隐藏写的延迟,处理器会将写操作先放入一个写缓冲队列中,然后立即继续执行后续指令,写操作会在后台慢慢完成 。这在单处理器上没问题,但在多处理器上会破坏一致性 。
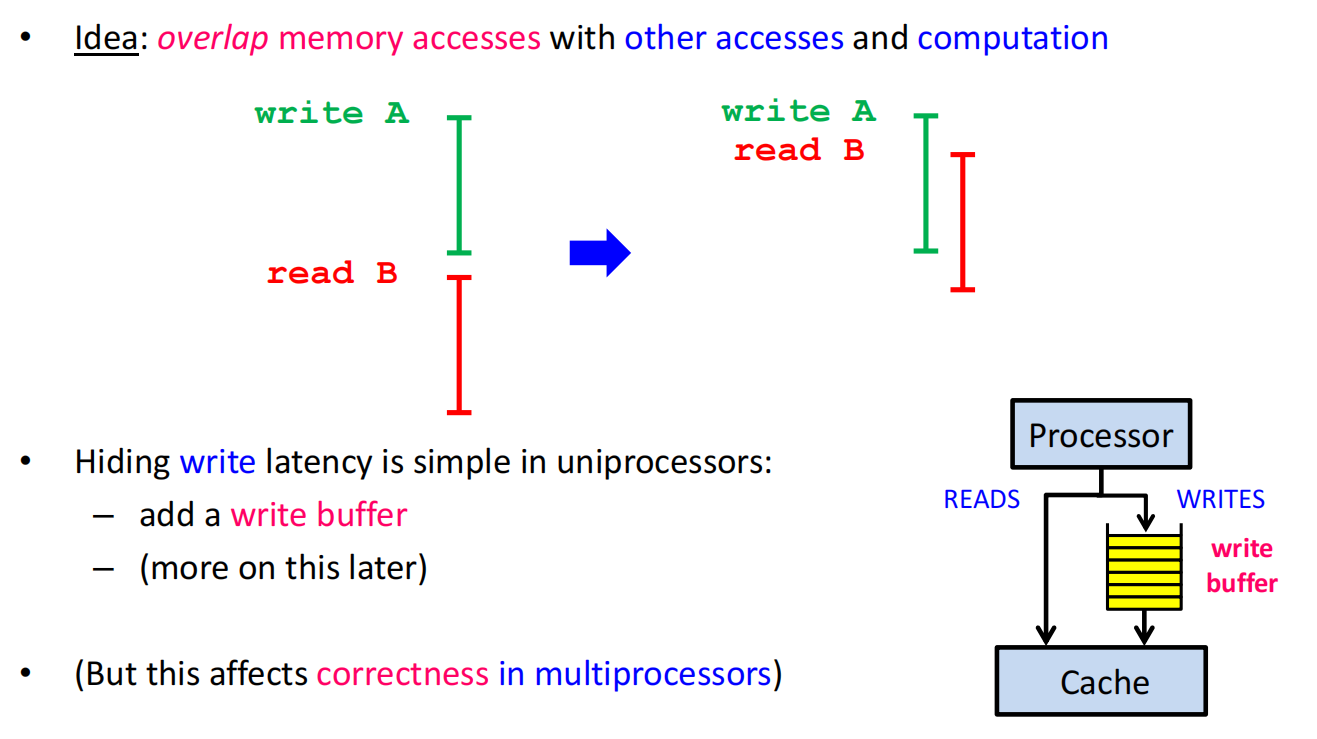
- 乱序执行 (Out-of-Order Execution):为了隐藏读的延迟,当一条指令(如
x = *p;)因为缓存未命中而卡住时,处理器会跳过它,去执行后面不依赖它的指令(如z = a+2;) 。这意味着内存访问的实际发生顺序可能和程序顺序完全不同 。 - 分支预测与推测执行 (Speculative Execution):处理器甚至不需要等待一个条件分支的结果,它可以“猜测”一个最可能的结果,然后提前执行那条路径上的代码 。如果猜错了,再撤销所有操作,走另一条路 。
- 重排缓冲区 (Reorder Buffer):现代CPU通过重排缓冲区等结构来实现这种复杂性。指令按顺序取指,但乱序发射执行,最终再按序“毕业”(retire),以保证单线程内的逻辑正确 。
一个线程中的指令就像一个长条气球里的气体分子,它们本来有编号,但现在在气球里到处乱撞 。从另一个线程(气球外)观察,这些指令(内存访问)的顺序看起来是混乱的 。我们唯一能做的就是在这个气球上“打结”,强制规定顺序 。
Sequential Consistency Memory Model
顺序一致性模型
在SC模型下,一些在真实硬件上可能出现的“意外”结果是被禁止的。

然而,在真实硬件上,这些“不可能”的结果可能发生!
实现SC的一种方法是:
- 实现缓存一致性 。
- 强制每个处理器在上一次内存访问完成前,不能开始下一次访问 。
- 一次读操作完成,指其返回值被确定 。
- 一次写操作完成,指其新值对其他处理器变得“可见”,即它被提交到了全局的串行顺序中 。
这种严格的限制严重阻碍了硬件和编译器的优化 ,导致处理器大部分时间都在等待内存操作完成。
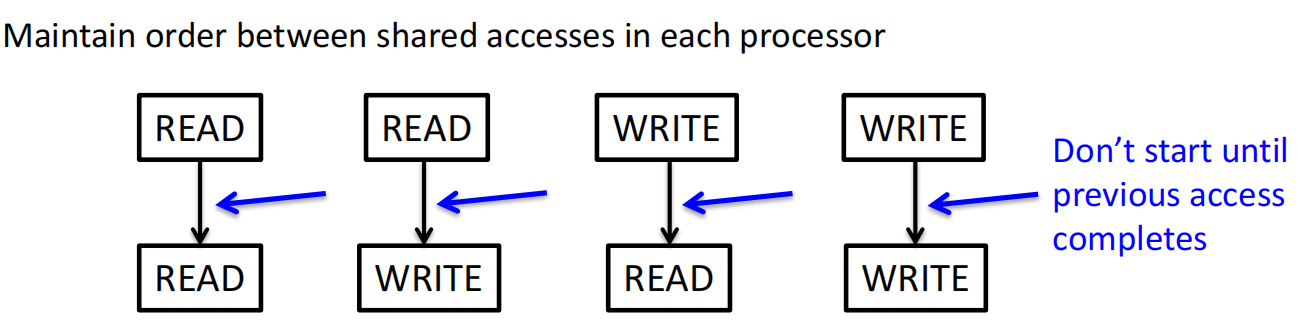
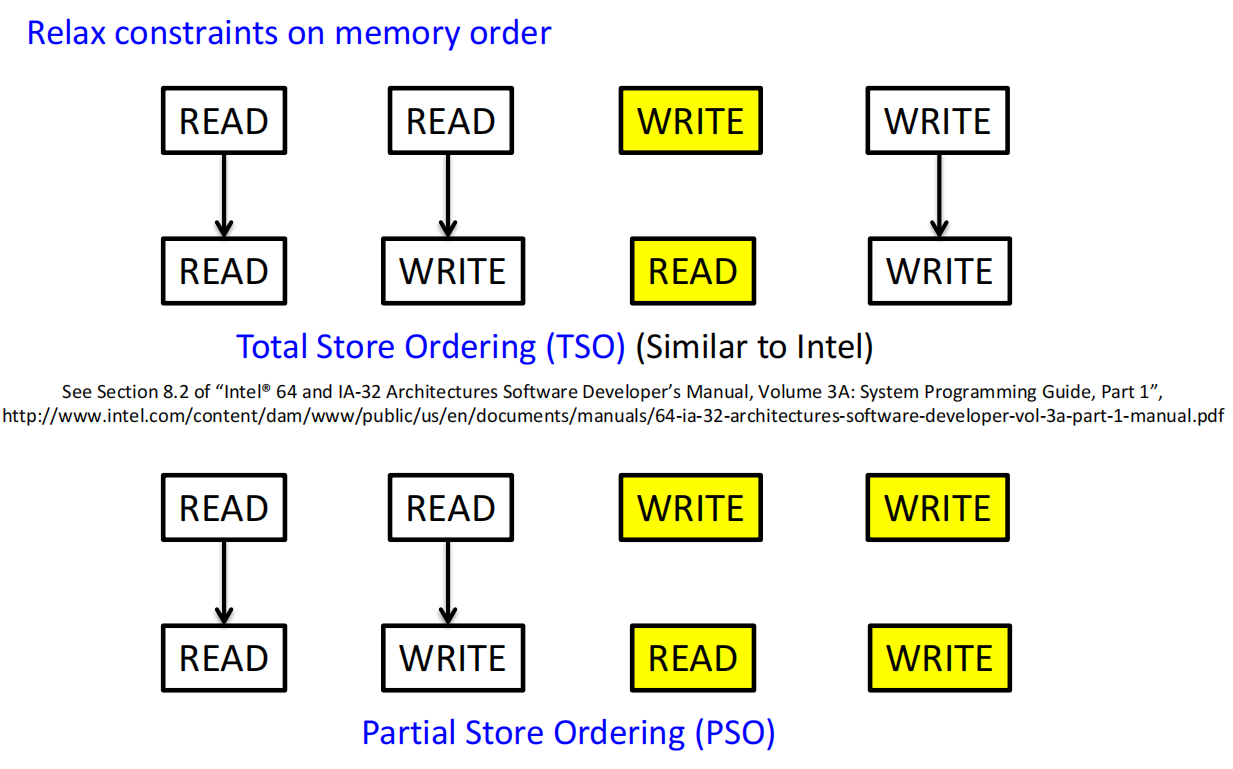
放宽限制以提升性能
现代硬件普遍采用宽松内存一致性模型 。它们放宽了对读写操作顺序的某些限制。
- TSO (Total Store Ordering):类似Intel x86的模式。允许读操作越过(reorder)比它早的、地址不同的写操作。这使得写缓冲可以被高效利用 。
- PSO (Partial Store Ordering):更宽松,甚至允许写操作之间进行重排 。
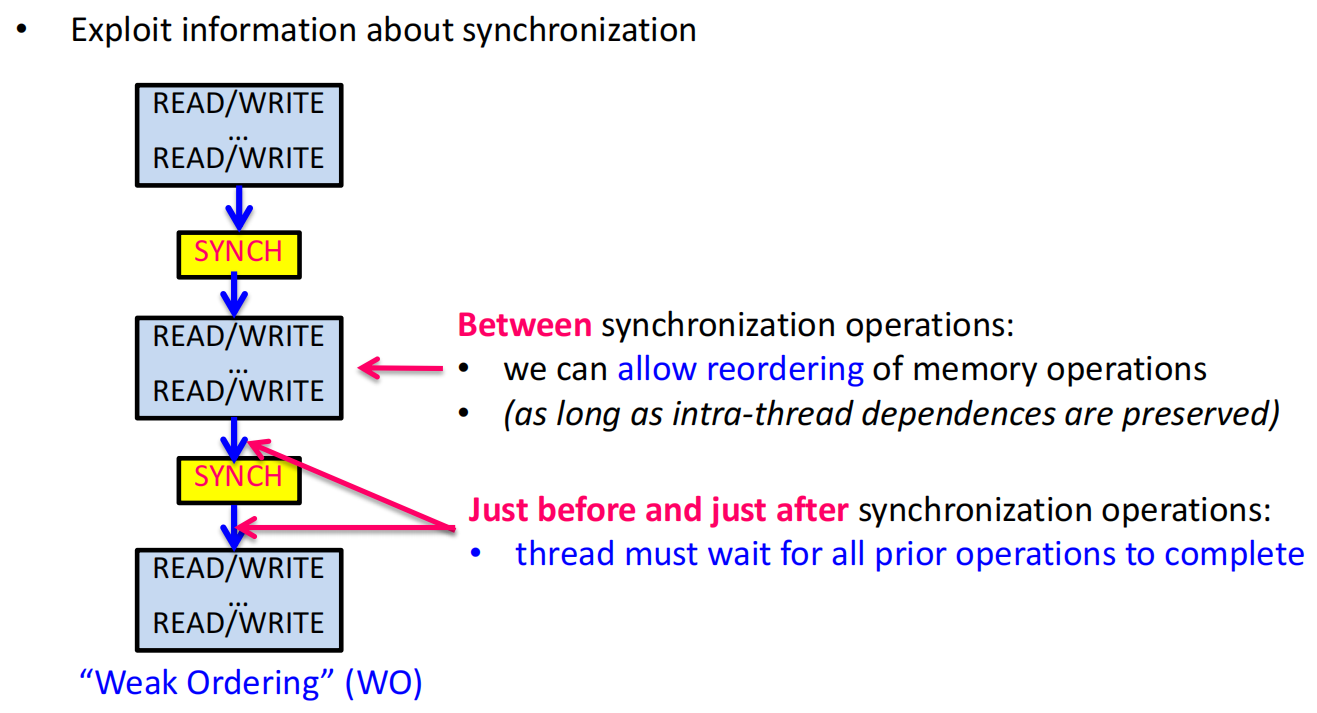
2. 如何保证正确性?
显式同步。
- 数据竞争 (Data Race):当两个不同线程的访问冲突(访问同一地址且至少一个是写),并且它们之间没有通过同步操作排序时,就发生了数据竞争 。
- 正确同步的程序 (Properly Synchronized Programs):如果一个程序中所有的数据访问都通过同步操作(如锁)进行了排序,那么即使在宽松模型下,它的行为也应该和在SC模型下一样 。

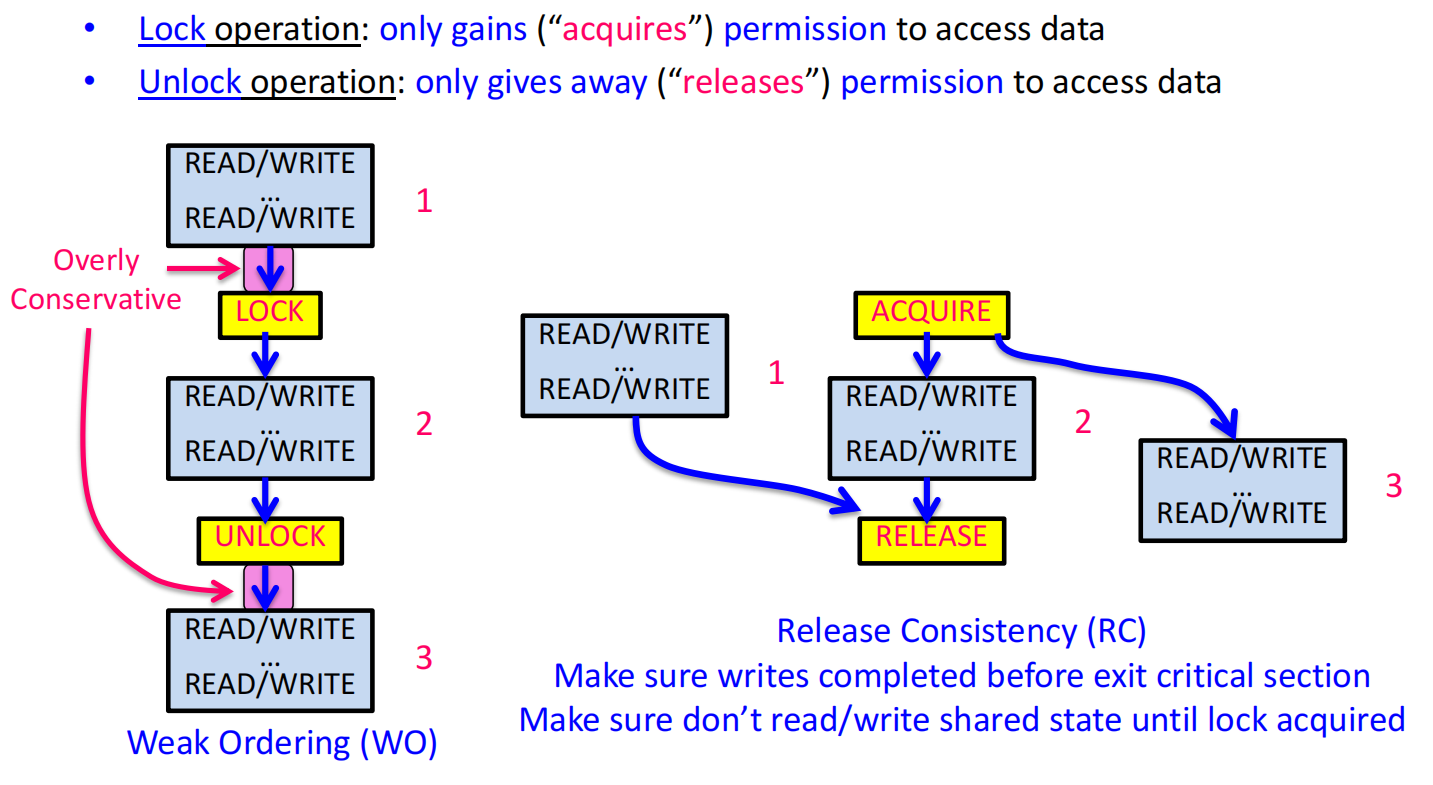
- 弱序模型 (Weak Ordering, WO):利用这一思想,硬件可以自由地重排普通读写操作,但当遇到同步操作时,它必须保证在该同步点之前的所有操作都已完成,且在该同步点之后的所有操作都还没开始 。
内存栅栏 (Memory Fence)
程序员可以通过内存栅栏指令来手动强制规定顺序。
-
Intel的
MFENCE指令就是一个例子。它确保在该指令之前的所有读写操作都已完成,之后的所有读写操作才能开始 。就像在之前提到的气球上“打一个结”,气体分子无法穿过这个结,从而在结的两边形成了有序的区域 。 -
修正错误:通过在关键位置插入
MFENCE(或SFENCE/LFENCE),我们可以修复之前因为乱序而出现问题的代码 。 -
MFENCE不会“把数据推给其他线程”,它只是阻塞当前线程,直到它自己的写缓冲清空等操作完成 。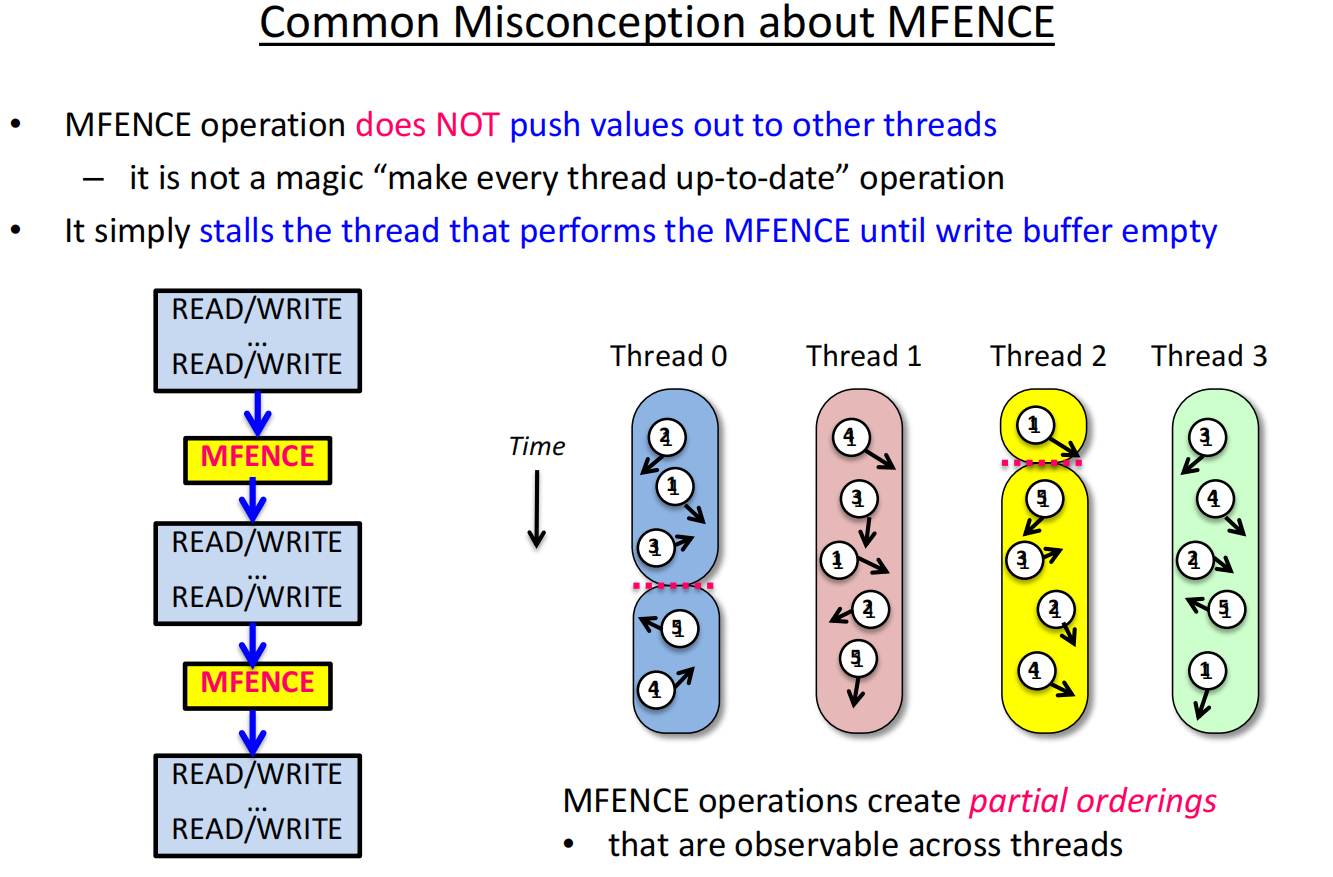
释放一致性 (Release Consistency, RC)
这是一种比弱序更优化的模型。它利用了同步操作的非对称性:
-
获取锁 (Acquire):是一个“只进不出”的栅栏。它保证在获取锁之后的读写操作不会被乱序到它之前。
-
释放锁 (Release):是一个“只出不进”的栅栏。它保证在释放锁之前的所有读写操作都已经完成。 这提供了更细粒度的控制,允许更多的乱序,从而获得更高性能 。

Recitation OMP & MPI
MPI基础
一个最小的MPI程序
一个最基础的MPI程序(C语言版)包含以下几个关键部分 :
#include "mpi.h":必须包含MPI头文件 。MPI_Init(&argc, &argv):初始化MPI执行环境,这是每个MPI程序都必须调用的第一个MPI函数 。MPI_Finalize():结束MPI环境,这是必须调用的最后一个MPI函数 。- 错误处理:默认情况下,MPI中发生错误会导致所有进程中止 。用户可以自定义错误处理机制,例如让函数返回错误码,或是在C++中抛出异常(MPI-2特性)。
运行环境与身份识别
- 运行程序:MPI-1标准并未规定如何启动一个MPI程序 。这通常依赖于具体的MPI实现。常用的命令是
mpiexec或mpirun。 - 获取环境信息:程序中最常见的两个问题是:“总共有多少个进程?”和“我是哪一个进程?” 。MPI提供了两个函数来回答:
MPI_Comm_size(comm, &size):获取指定通信域中的进程总数 。MPI_Comm_rank(comm, &rank):获取当前进程在通信域中的秩 (rank),这是一个从0到size-1的唯一标识号 。
1 |
|
点对点通信:Send 和 Recv
这是MPI最核心的通信方式。一次基本的通信需要明确以下几点 :
- 如何描述要发送/接收的数据?
- 如何识别目标/源进程?
- 接收方如何识别和筛选消息?
- 操作何时算完成?
为了解决这些问题,MPI引入了几个核心概念:
- 通信域 (Communicator):它是一个进程组(group)和一个上下文(context)的集合 。所有初始进程都属于一个默认的通信域
MPI_COMM_WORLD。进程的秩是在通信域内定义的 。 - MPI数据类型 (Datatype):一条消息的数据由三元组
(地址, 数量, 数据类型)描述 。MPI预定义了如MPI_INT,MPI_DOUBLE等基本类型 ,并允许用户构建自定义的复杂数据类型 。这使得MPI可以在不同内存表示的异构机器间进行通信 。 - 消息标签 (Tag):发送消息时可以附带一个用户定义的整型标签,接收方可以用它来筛选特定类型的消息 。
基本的阻塞式函数:
MPI_Send(start, count, datatype, dest, tag, comm):发送一条消息 。当这个函数返回时,表明数据已经被安全地交给了MPI系统,发送缓冲区可以被重用,但这并不保证消息已经被接收方收到 。MPI_Recv(start, count, datatype, source, tag, comm, status):接收一条消息 。这个函数会一直等待(阻塞),直到一条匹配的消息(源和标签都匹配)到达 。
非阻塞式通信:
MPI_Isend和MPI_Irecv:这些是非阻塞版本,函数会立即返回一个MPI_Request句柄,而通信在后台进行 。



MPI_Wait(request, status):阻塞等待一个非阻塞操作完成 。MPI_Test(request, &flag, status):检查一个非阻塞操作是否完成,不阻塞 。
简单的MPI:许多并行程序只需要6个核心函数就能编写:MPI_Init, MPI_Finalize, MPI_Comm_size, MPI_Comm_rank, MPI_Send, MPI_Recv 。
集体通信 (Collective Communications)
集体通信操作必须由一个通信域中的所有进程共同调用 。
MPI_Bcast(buffer, count, datatype, root, comm):广播。由root进程将一份数据发送给通信域中的所有其他进程 。MPI_Reduce(sendbuf, recvbuf, count, datatype, op, root, comm):归约。从所有进程收集数据,通过指定的操作(如MPI_SUM求和)进行合并,并将最终结果存放在root进程中 。
示例:计算PI 讲义中给出了一个通过数值积分计算PI的例子。
- 进程0通过
MPI_Bcast将n广播给所有其他进程 。 - 通过
MPI_Reduce将所有进程的mypi值用MPI_SUM操作相加,最终结果pi存放在进程0中 。
1 | MPI_Bcast(&n, 1, MPI_INT, 0, MPI_COMM_WORLD); |
对于多数值算法,用Bcast/Reduce替代Send/Recv可以使代码更简洁高效 。
其他
死锁 (Deadlock)

解决方案:
- 小心地安排操作顺序:让一个进程先发送再接收,另一个进程先接收再发送 。
- 使用非阻塞操作:所有进程都使用
Isend/Irecv发起通信,然后调用Waitall等待所有操作完成 。

其他
- MPI实现:MPICH是一个著名的高性能、可移植的MPI实现 。
- MPI-2特性:MPI-2标准引入了许多高级功能,如动态进程管理、单边通信、并行I/O等 。
- 何时使用MPI:当追求可移植性与性能、处理不规则数据结构、构建并行库或需要精细化管理各处理器内存时,MPI是很好的选择 。
lec14 Performance Measurement and Tuning

各种分析工具,从略。
lec15 Interconnection networks
改进为:
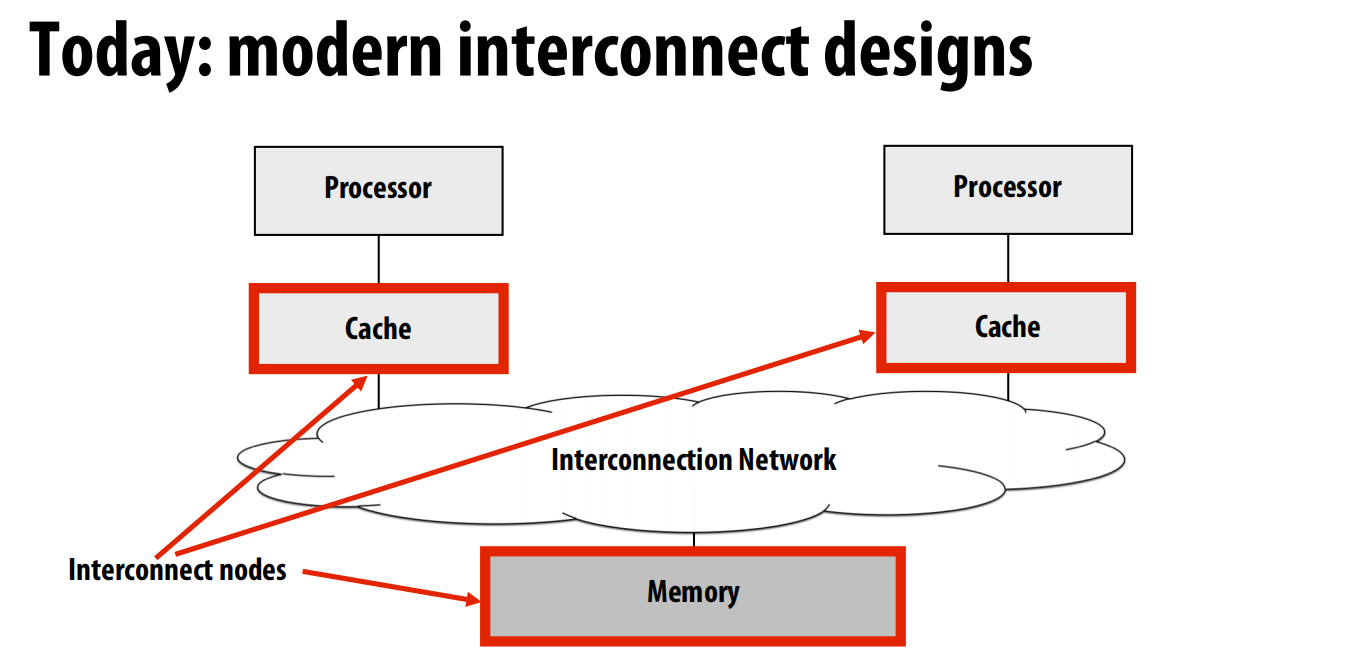
术语:
节点(Node):网络的一个端点,如处理器缓存或内存控制器。
网络接口(Network Interface):将节点连接到网络的组件。
交换机/路由器(Switch/Router):网络中的核心组件,负责将数据从输入链路转发到输出链路。
链路(Link):连接交换机或节点的一束导线,用于传输信号。
核心问题:
拓扑(Topology):交换机之间如何连接,这决定了网络的物理结构,影响路由、延迟和成本。
路由(Routing):消息如何从源头找到通往目的地的路径。可以是固定的(静态路由)或根据网络负载动态变化的(自适应路由)。
缓冲与流控(Buffering and Flow Control):网络中如何存储数据(例如,是存储完整的数据包还是部分?),以及如何管理缓冲区空间以避免数据丢失。
更多术语:
路由距离(Routing Distance):消息从源到目的地需要经过的链路数,也称为“跳数”(hops)。
直径(Diameter):网络中任意两个节点间的最大路由距离。
平均距离(Average Distance):所有节点对之间路由距离的平均值。
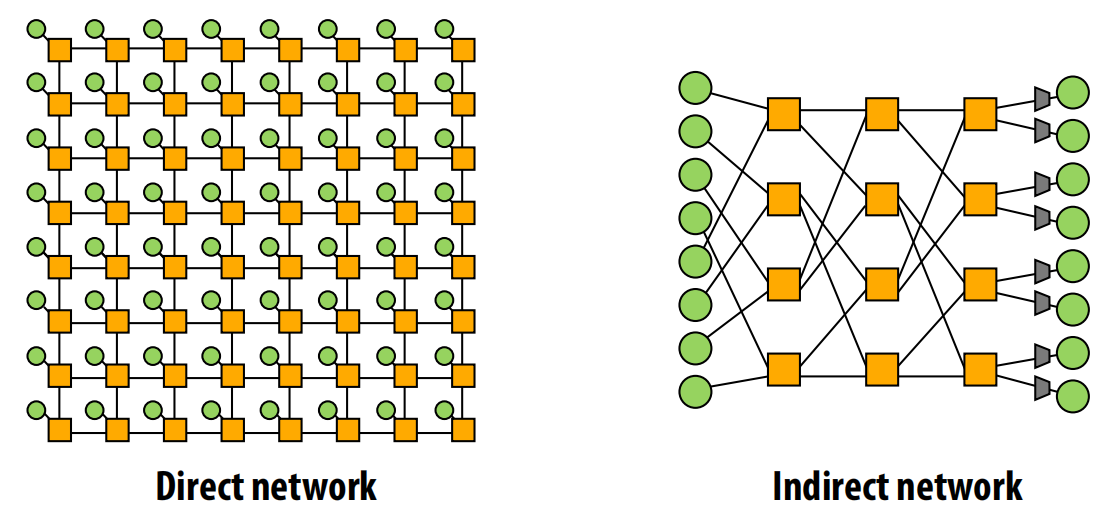
直接 vs. 间接网络(Direct vs. Indirect):
- 直接网络:端点(如处理器核心)本身就是网络的一部分,兼具交换机功能。例如,网格(Mesh)网络。
- 间接网络:端点位于网络外部,通过交换机连接。例如,多级网络。
剖分带宽(Bisection Bandwidth):将网络切成两半,所有被切断的链路的总带宽。这是一个衡量网络全局通信能力的常用指标,但有时会产生误导,因为它未考虑交换机效率和路由算法的影响。
阻塞与性能曲线
阻塞 vs. 非阻塞(Blocking vs. Non-blocking):
- 如果一个网络可以同时满足任意不冲突的节点对之间的连接请求,它就是非阻塞的。
- 反之,如果某些现有的通信会阻止其他不相关的节点对建立连接,那么这个网络就是阻塞的。
负载-延迟曲线(Load-Latency Curve):
- 随着网络负载(单位时间内的通信量)的增加,消息的平均延迟也会增加。
- 空载延迟(Zero load latency):网络没有流量时的最小延迟,由拓扑结构、路由算法和流控共同决定。
- 饱和吞吐量(Saturation throughput):当网络达到其容量极限时,延迟会急剧上升,此时的吞吐量就是饱和吞吐量。网络的吞吐量上限依次受到拓扑、路由算法和流控机制的限制。
常见的互连拓扑
总线(Bus)
- 优点:设计简单,成本低(尤其对于少量节点),易于实现缓存一致性(通过监听)。
- 缺点:扩展性差,所有节点争用一个共享信道,带宽有限,电气负载高导致频率低、功耗大。

交叉开关(Crossbar)
- 结构:一个完全连接的间接网络,每个输入都能直接连接到任意一个输出。
- 优点:非阻塞,提供极低的 O(1) 延迟和高带宽。
- 缺点:成本极高,需要 O(N²) 个交换单元,难以扩展,大规模仲裁复杂。
- 实例:Oracle (Sun) 的 SPARC T2 和 T5 多核处理器使用了交叉开关作为核心互连。在芯片上,一个交叉开关(CCX)占用的面积约等于一个处理器核心。
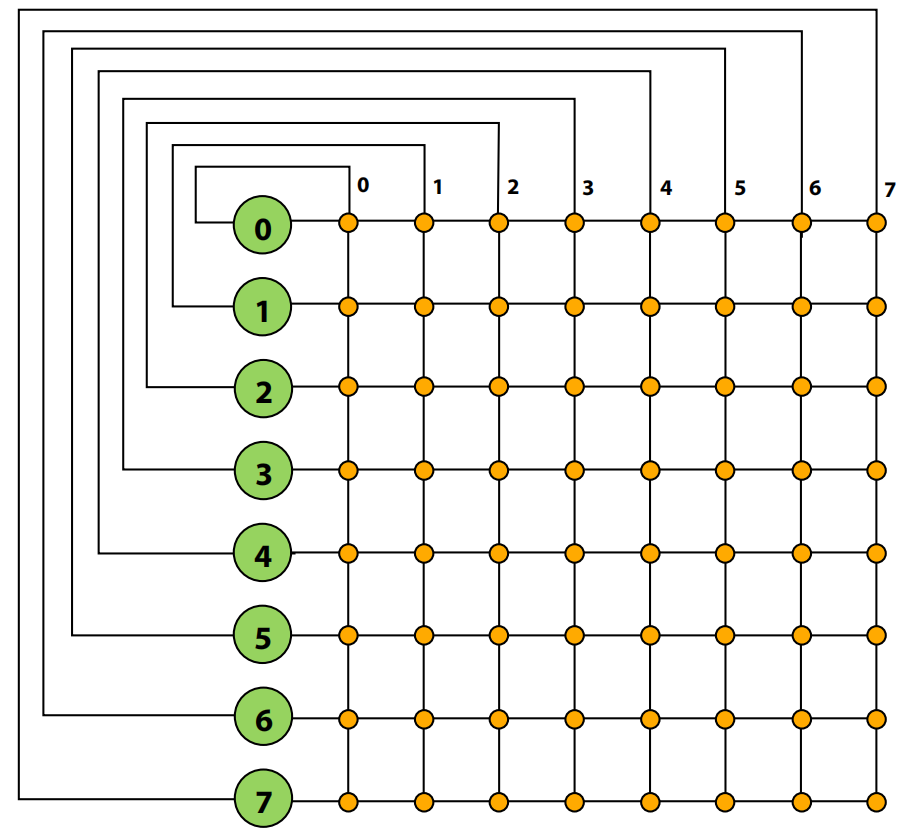
环形(Ring)
- 优点:结构简单,成本低 (O(N))。
- 缺点:延迟高 (O(N)),剖分带宽是恒定的,增加节点数并不能提升总带宽,扩展性差。
- 实例:英特尔的Sandy Bridge微架构引入了环形总线来连接CPU核心、L3缓存片、系统代理和图形单元。这个设计包含四个独立的环(请求、监听、确认、数据)。
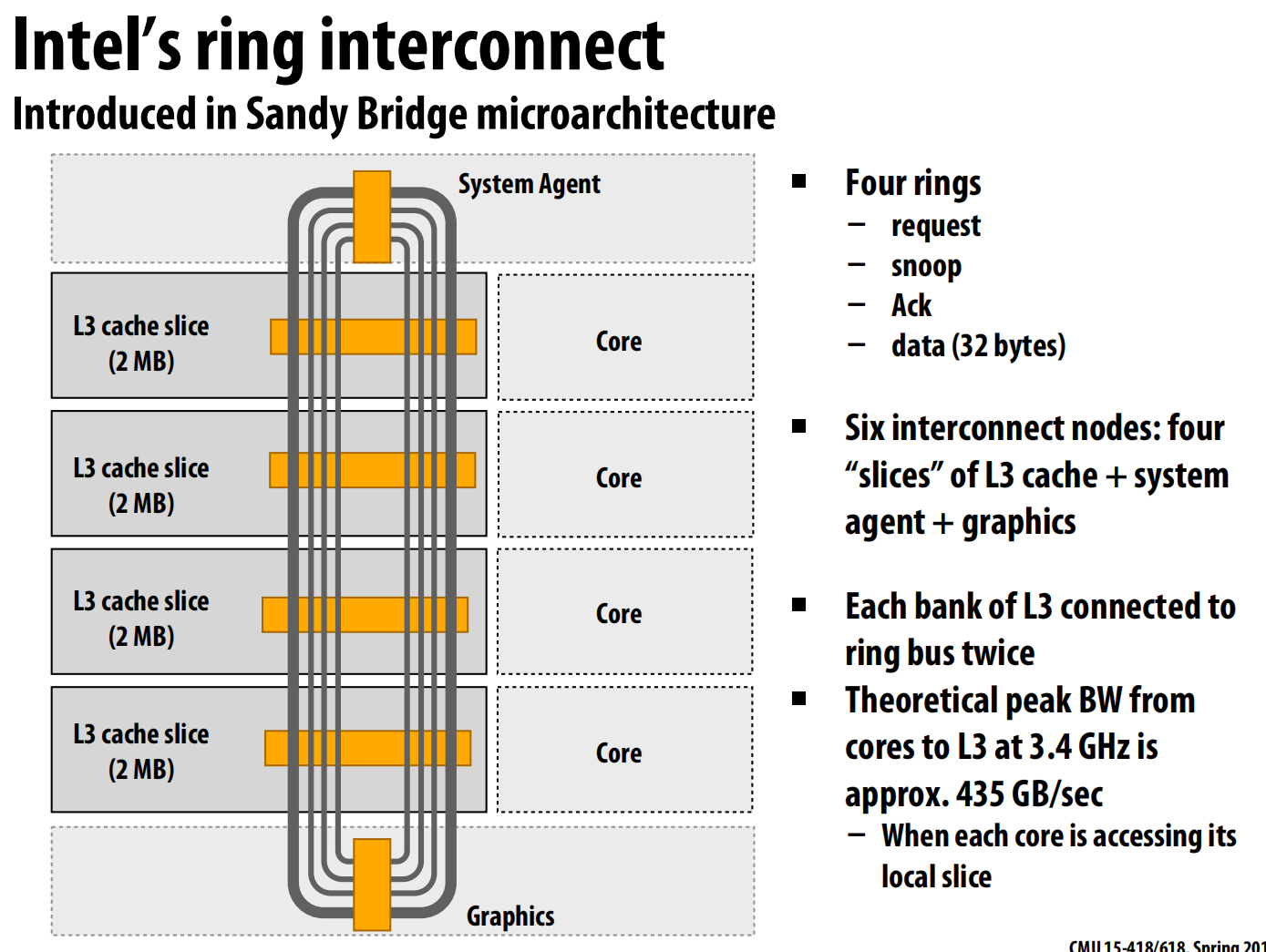
网格(Mesh)
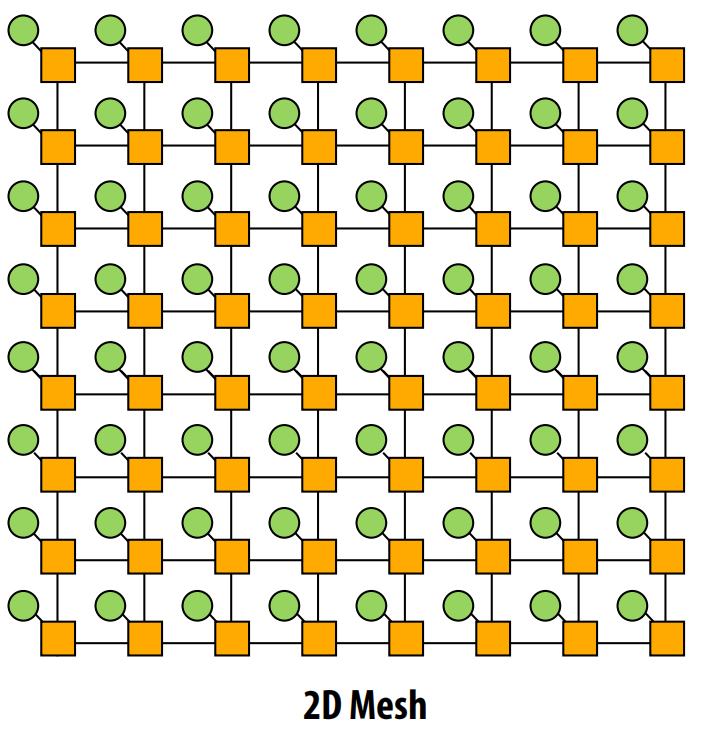
- 结构:节点排列成二维网格,每个节点同时也是一个交换机(直接网络)。
- 优点:成本为 O(N),平均延迟为 O(sqrt(N)),易于在芯片上布局,路径多样性好。
- 实例:Tilera的多核处理器和英特尔的72核Xeon Phi(Knights Landing)都使用了2D网格拓扑。Xeon Phi使用YX路由算法:消息先沿Y轴移动,再沿X轴移动到目的地。
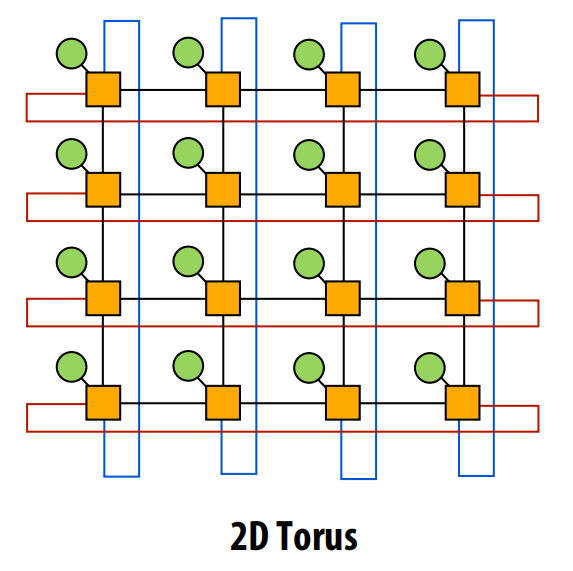
环面(Torus)
- 结构:在网格的基础上,将边缘的节点用“回绕”链路连接起来,形成一个环面。
- 优点:消除了网格的边缘效应,路径多样性和剖分带宽优于网格。
- 缺点:成本比网格高,布局更复杂,因为回绕链路很长。
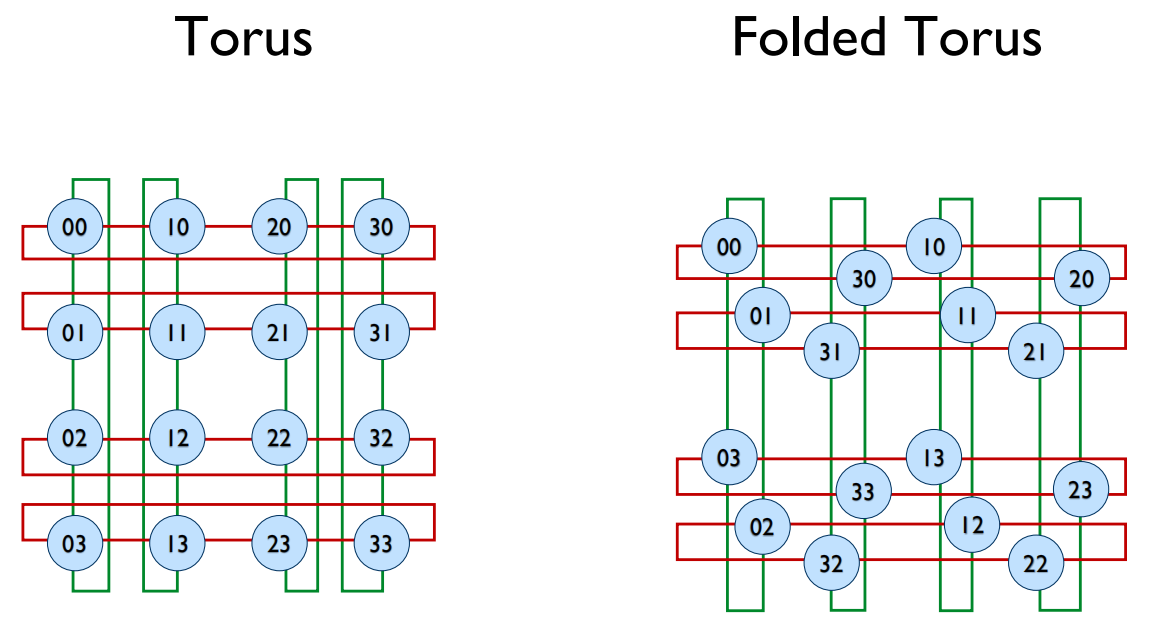
- 折叠环面(Folded Torus):一种布局技巧,通过交错排列行和列,使得所有链路的长度更加均匀,解决了长连接问题。
树(Tree)
- 结构:分层的平面拓扑,适合具有局部性通信模式的应用。
- 优点:延迟低 (O(log N))。
- 缺点:根节点容易成为带宽瓶颈。
- 胖树(Fat Tree):为了解决根节点瓶颈,越靠近根节点的链路,其带宽也越宽。这提供了O(N)的剖分带宽。
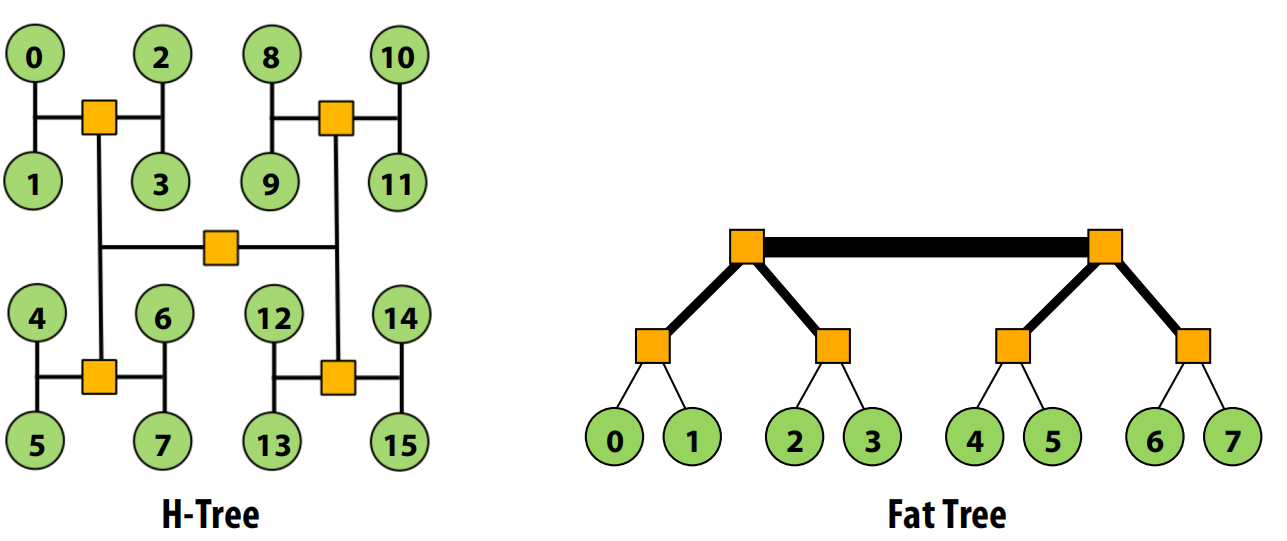
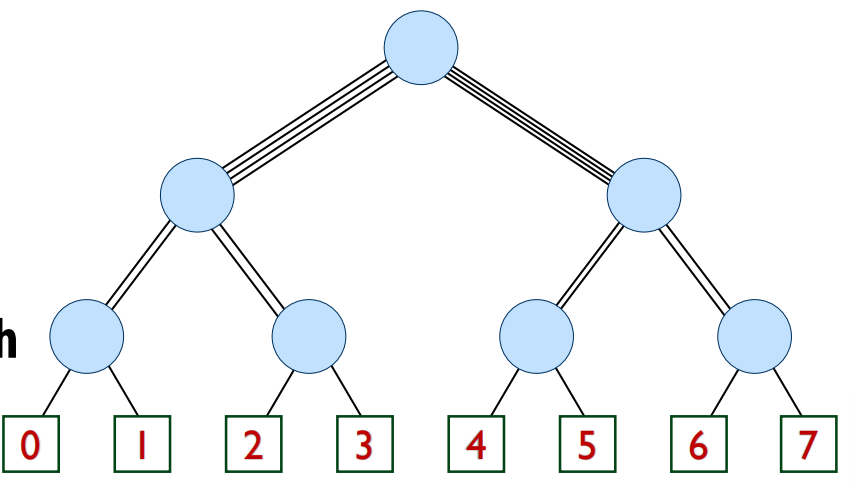
- 恒定宽度胖树(Folded Clos Network):一种特殊的胖树,所有交换机的度数(连接数)都相同,简化了硬件设计。
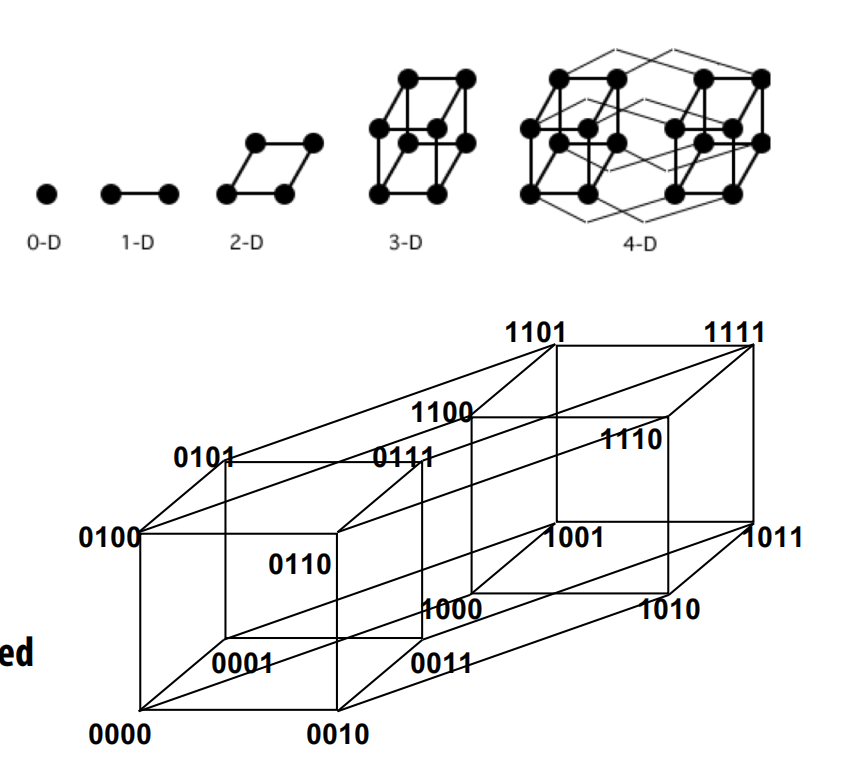
超立方体(Hypercube)
- 结构:N维立方体,N=2^k个节点,每个节点的地址用k位二进制表示,两个节点相邻当且仅当它们的地址只有一位不同。
- 优点:延迟非常低 (O(log N))。
- 缺点:节点的度数随网络规模增长 (O(log N)),链路总数多 (O(N log N)),实现复杂。
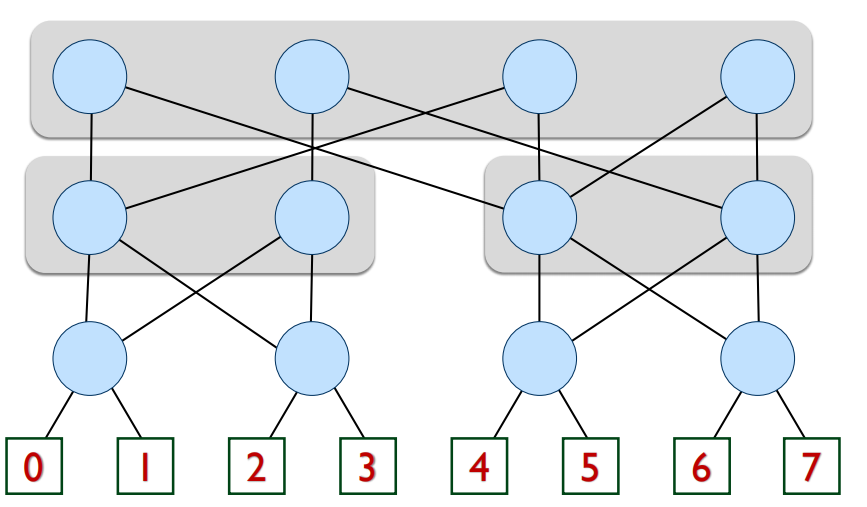
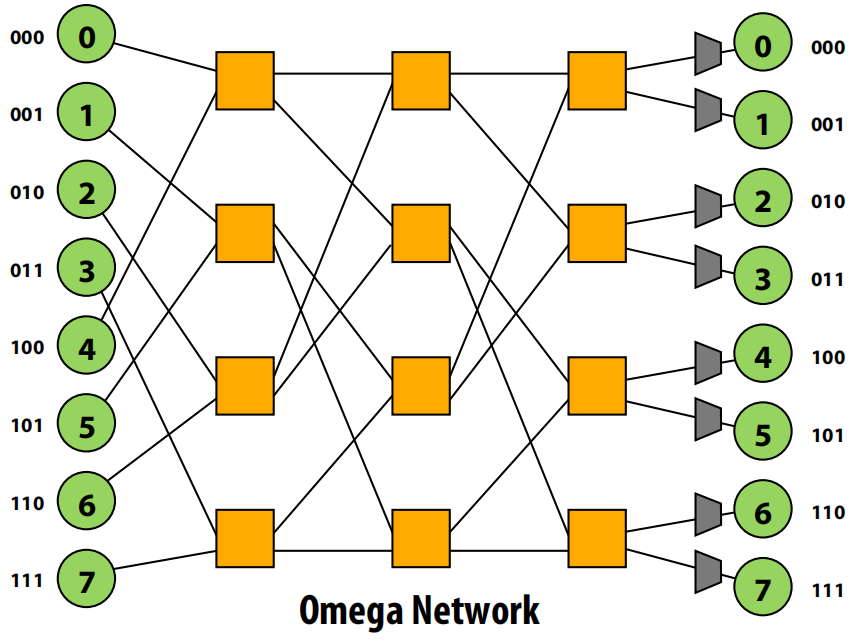
多级对数网络(Multi-stage Logarithmic)
- 结构:一种间接网络,由多个交换机级联而成,如Omega网络、Butterfly网络等。
- 优点:成本 O(N log N),延迟 O(log N)。
- 路由:通常使用“目的地标签路由”。例如在Omega网络中,从源到目的地,在第i级交换机,根据目的地地址的第i位来决定走上出口(0)还是下出口(1)。
缓冲与流控
交换方式与数据粒度
-
电路交换 vs. 分组交换(Circuit vs. Packet Switching)
- 电路交换:在发送数据前,先在源和目的地之间建立一条完整的、专用的物理路径(电路)。优点是数据传输时无竞争、无开销;缺点是建立和拆除电路有延迟,链路利用率低。
- 分组交换:将消息拆分成一个个“包”(Packet),每个包独立路由。优点是链路利用率高,无需建立电路;缺点是每个包都需要路由和缓冲,会产生开销和拥塞。
-
通信粒度:
- 消息(Message):应用层面的传输单位。
- 包/分组(Packet):网络层面的传输单位,包含头部(路由信息)、载荷(数据)和尾部(校验码等)。

- 流控单元/片(Flit - Flow control digit):为了更精细地控制数据流,包可以被进一步拆分成更小的“片”。Flit是网络中流量控制和缓冲的最小单位。
-
拥塞处理:当两个包要抢占同一个出口时,可以采取缓冲、丢弃或绕路(deflection)等策略。本讲义主要关注缓冲。
流控机制
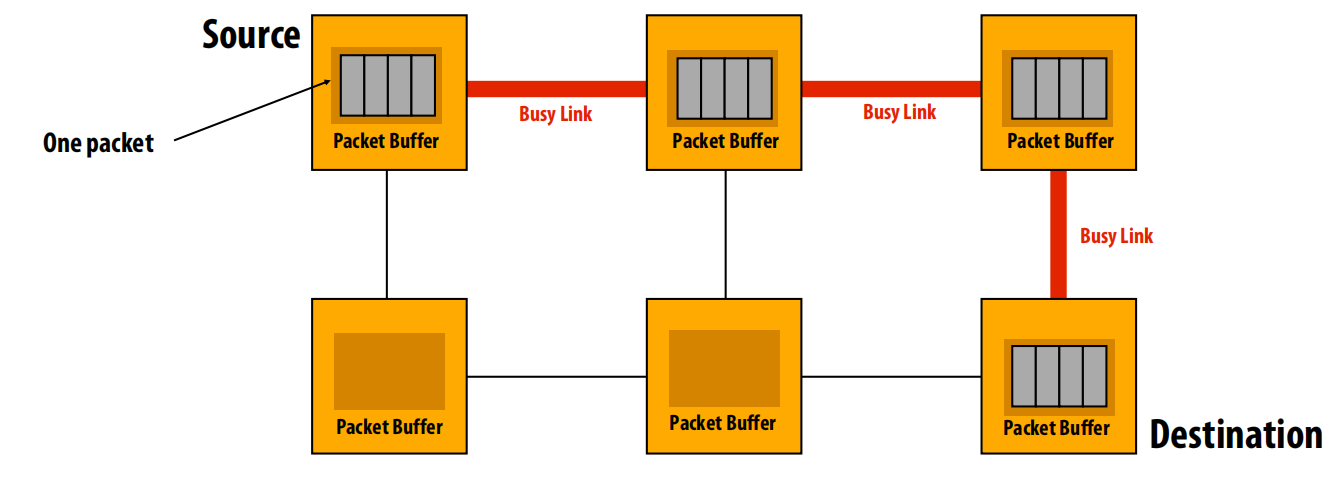
- 存储转发(Store-and-forward)
- 机制:交换机必须完整接收整个数据包,将其存储在缓冲区后,再转发到下一个节点。
- 特点:延迟高,等于包的传输时间乘以跳数。需要大的缓冲区(至少一个完整包大小)。
-
直通(Cut-through)
- 机制:交换机一旦收到包的头部并确定了路由,就立刻开始向下一个节点转发数据,无需等待整个包接收完毕。
- 特点:大大降低了传输延迟。但在高拥塞情况下,如果出口被阻塞,整个包还是会被迫存储在交换机中,退化为存储转发模式。因此仍需完整数据包大小的缓冲区。
-
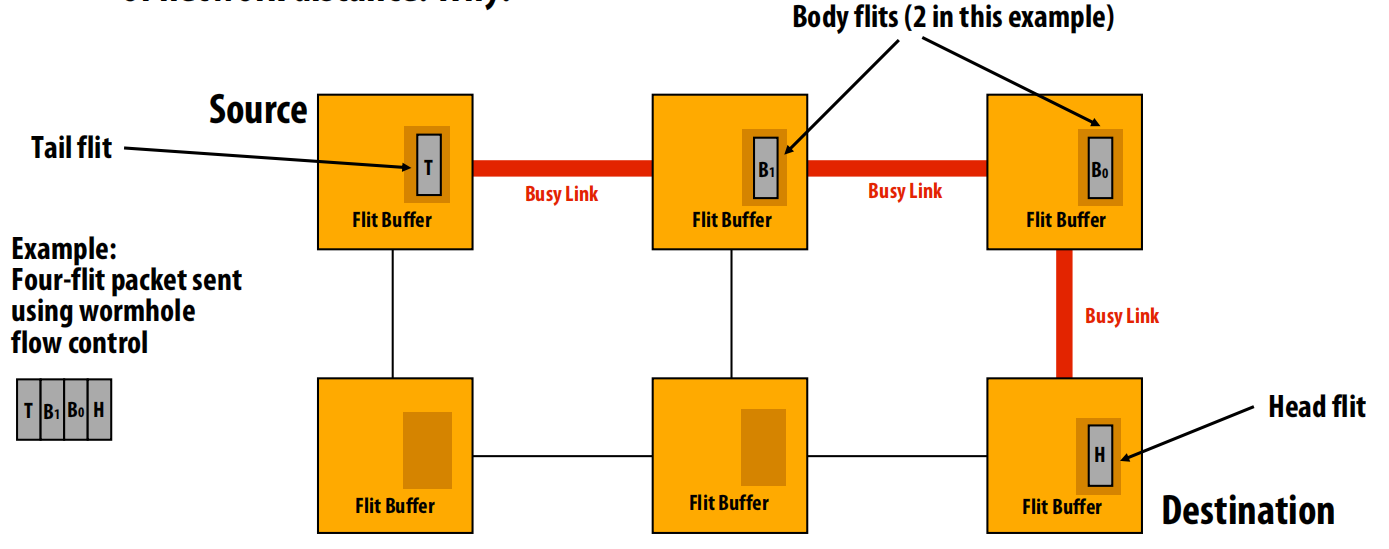
虫洞(Wormhole)
- 机制:这是基于Flit的流控。一个包被拆分成多个Flits。只有头Flit包含路由信息,身体Flits和尾Flit紧随其后,像一条虫子一样在网络中“蠕动”。
- 特点:极大地减小了对缓冲区大小的要求,每个交换机只需缓冲几个Flits即可。传输被完全流水线化,对于长消息,延迟几乎与网络距离无关。

-
队头阻塞(Head-of-Line Blocking)
- 问题:在虫洞路由中,如果一个包的头Flit因为某个出口繁忙而被阻塞,它会占据缓冲区,导致排在它后面的、目标出口空闲的其他包也无法前进。
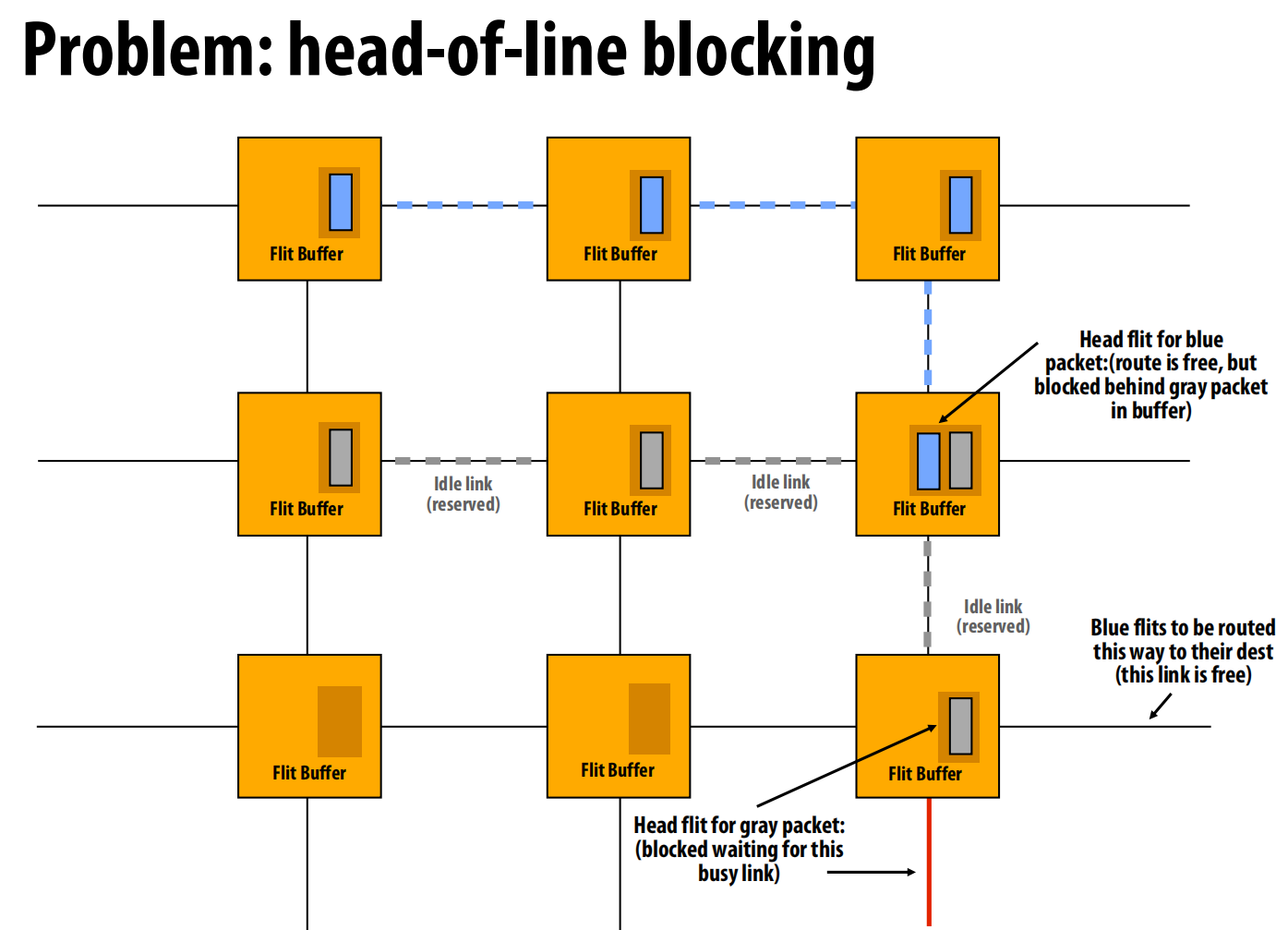
- 虚拟通道(Virtual Channels)
- 解决方案:为了缓解队头阻塞,可以将一个物理通道的缓冲区在逻辑上划分为多个独立的“虚拟通道”(VCs)。
- 机制:这样,一个被阻塞的包只占用其中一个VC,其他VC上的包仍然可以使用物理链路进行传输。
- 其他用途:虚拟通道还可用于避免死锁(通过为请求和响应分配不同VC)和提供服务质量(QoS,通过为不同类型的流量设置优先级)。
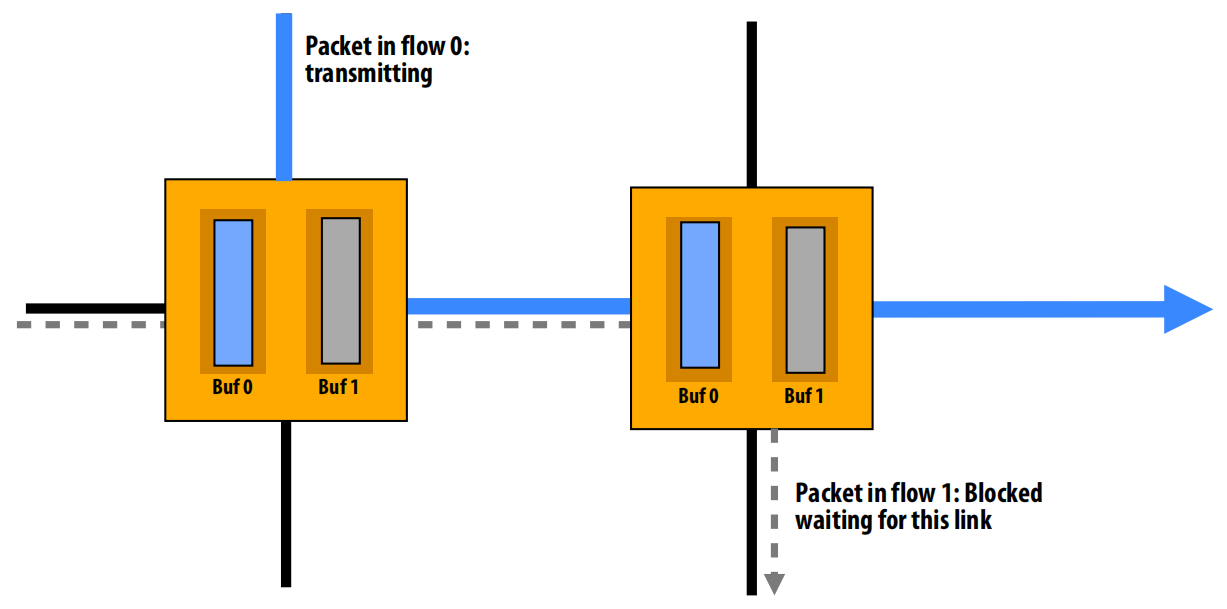
lec16 Implementing synchronization
同步事件的三个阶段
- 一个同步操作通常包含三个阶段:
- 获取方法(Acquire method):线程尝试获得受保护资源的访问权限 。
- 等待算法(Waiting algorithm):在资源被授予之前,线程如何等待 。
- 释放方法(Release method):当线程完成同步区域的工作后,如何使其他线程能够获得资源 。
忙等待(Busy-waiting),也称自旋(Spinning):线程在一个循环中持续检查某个条件是否为真,期间会一直占用CPU 。在传统操作系统课程中,这通常被认为是低效的,因为它浪费了CPU周期 。
阻塞(Blocking):如果一个线程因无法获取资源而不能继续前进,它会通知OS将自己挂起(de-schedule),让出CPU给其他线程使用 。pthread_mutex_lock 就是一个例子 。
何时忙等待更优? 在高性能并行计算中,忙等待往往是更好的选择,原因如下:
- 如果预期的等待时间很短,短于OS进行上下文切换的开销,那么忙等待更高效 。
- 当我们运行性能关键的并行程序时,通常不会超额订阅系统(即不会同时运行多个CPU密集型程序),因此CPU资源没有其他任务急需使用 。
pthread_spin_lock就是一个忙等待锁的例子 。
锁的实现
一个简单但错误的自旋锁
- 这个锁的逻辑是“加载-测试-存储” 。
- 问题:这个过程不是原子的,存在数据竞争 。

基于“测试并设置”(Test-and-Set)的锁
- 解决方法:使用硬件提供的原子指令,如
test-and-set(T&S) 。ts R0, mem[addr]这条指令会原子地将内存地址addr的值加载到寄存器R0,然后将该内存地址的值设置为1 。 - 性能问题:当多个处理器争用锁时,它们会反复执行
T&S指令。T&S是一个写操作,这引发了大量的总线流量,造成严重的总线争用 ,不仅增加了获取锁的时间,也拖慢了临界区的执行 。

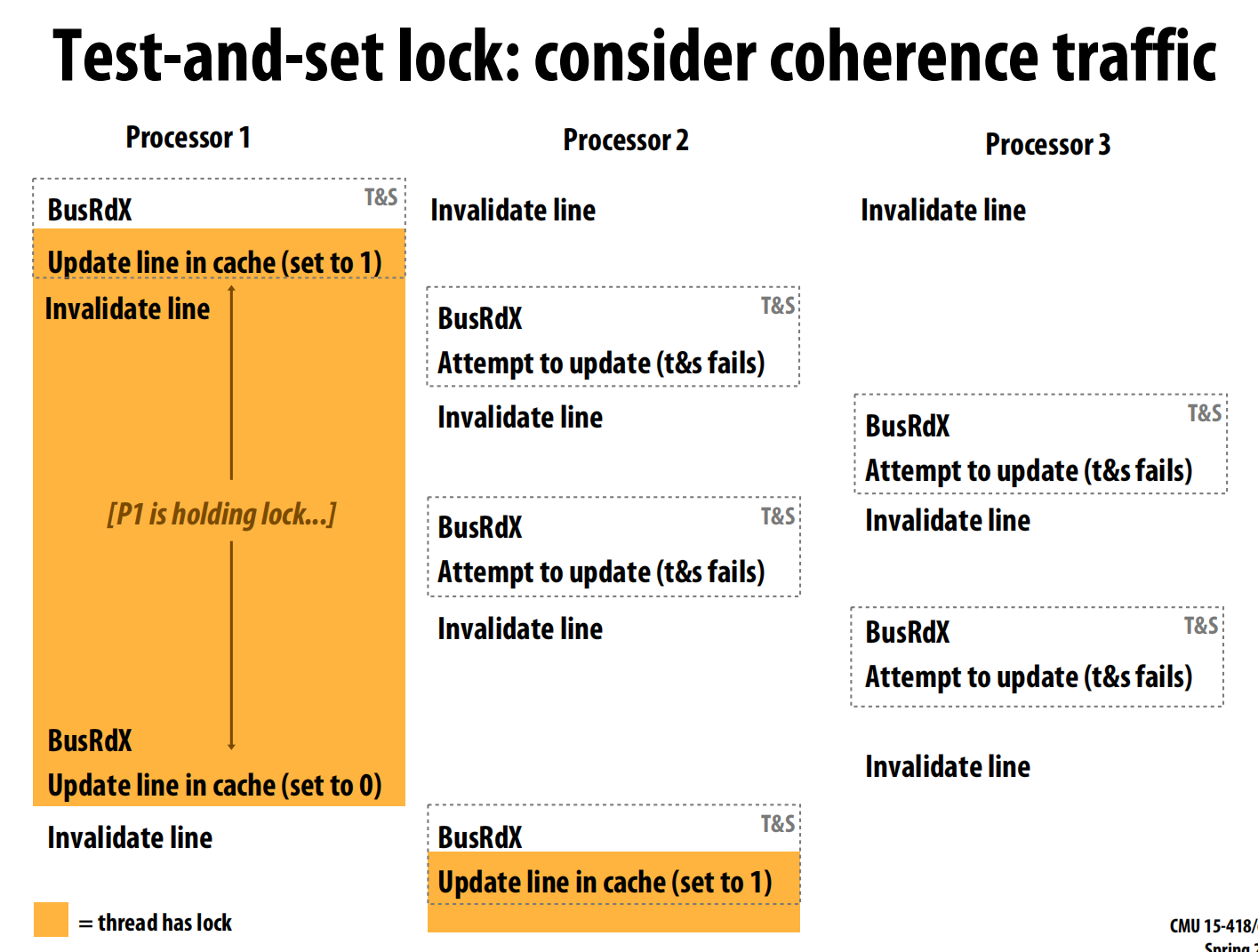
原子原语和期望的锁性能
- x86架构提供了
cmpxchg(比较并交换)指令,配合lock前缀可以实现原子操作 。 - 一个理想的锁应具备以下特性:
- 低延迟:在无竞争时能快速获取 。
- 低网络流量:在高竞争下,产生的通信流量要少 。
- 可扩展性:性能随处理器数量增加而不会急剧下降 。
- 低存储开销 。
- 公平性:避免某些线程饿死,最好能按请求顺序获取锁 。
T&S锁在低延迟和低存储方面尚可,但在流量、扩展性和公平性上表现很差 。
“测试并测试并设置”(Test-and-Test-and-Set)锁
- 优化思路:减少写操作。在尝试昂贵的
T&S之前,先在一个循环里用普通的读操作来“窥探”锁的状态 (while (*lock != 0)) 。 - 工作流程:线程首先在本地缓存上自旋(读操作),不产生总线流量 。一旦发现锁被释放(值为0),它才会去尝试执行一次原子的
T&S操作 。 - 性能:这种方法大大减少了网络流量。在锁被持有时,等待的处理器只在自己的缓存上读。只有当锁被释放时,会产生一次缓存失效广播,然后所有等待者会竞争一次
T&S。这比T&S锁的持续写操作要好得多。

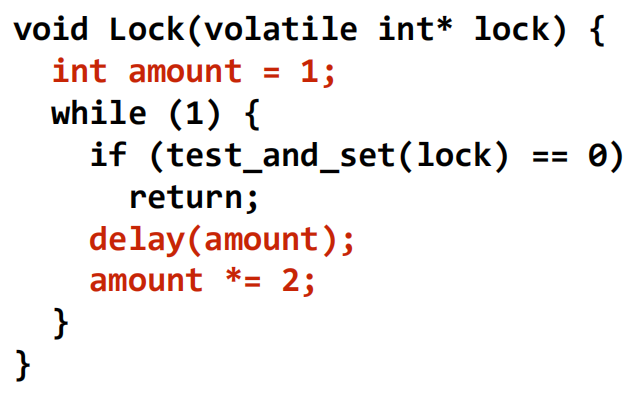
带退避(Back-off)的测试并设置锁
- 优化思路:在获取锁失败后,不要立即重试,而是延迟一段时间 。
- 实现:通常使用指数退避,即每次失败后将延迟时间加倍 (
amount *= 2) 。 - 性能:减少了网络流量和争用,但可能引入更高的延迟 。一个显著的缺点是不公平,后来的请求者因为退避时间短,反而可能比等待已久的线程更早获得锁 。
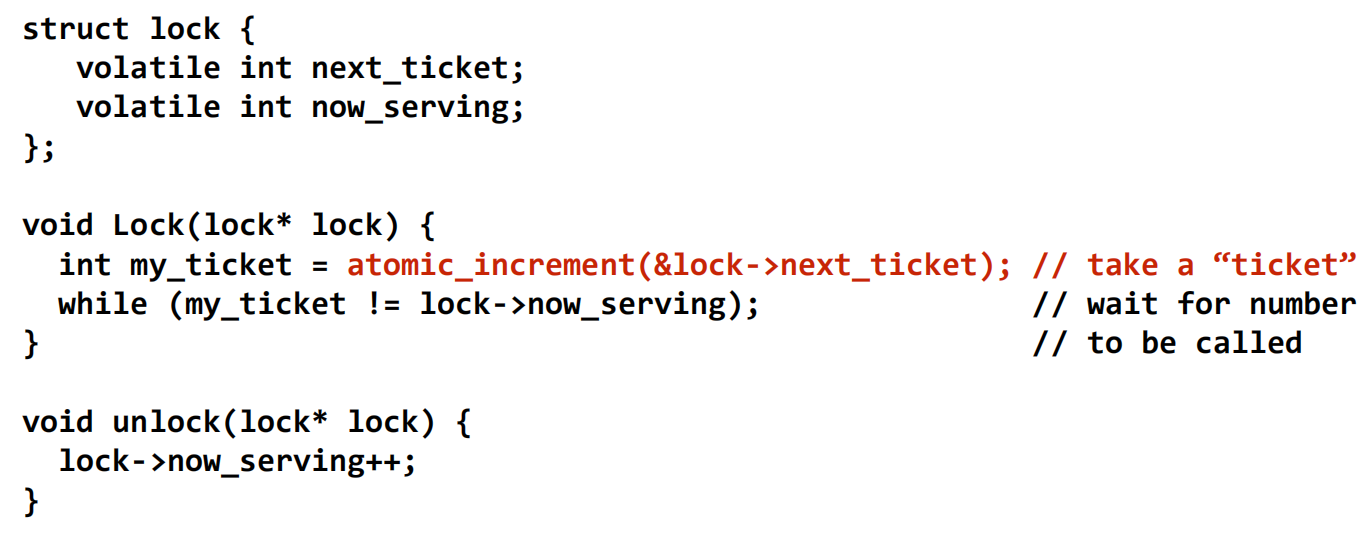
票号锁(Ticket Lock)
- 核心思想:解决
T&S类锁在释放时所有等待者“一拥而上”的问题 。其机制类似银行排队叫号。 - 实现:锁包含两个计数器:
next_ticket和now_serving。- 获取:线程原子地增加
next_ticket来领取一个“票号” (my_ticket) 。 - 等待:线程自旋等待,直到
now_serving的值等于自己的票号 。 - 释放:持有锁的线程将
now_serving加一 。
- 获取:线程原子地增加
- 优点:非常公平,实现了先进先出。等待过程是读操作,且每次释放只产生一次缓存失效(当
now_serving被更新时) 。
基于数组的锁
- 核心思想:让每个处理器在不同的内存地址上自旋,彻底消除因共享同一个自旋地址而产生的缓存失效风暴 。
- 实现:维护一个状态数组
status[P],每个处理器分配一个数组元素 。获取锁时,线程原子地获取一个数组索引,然后只在该索引对应的status位置上自旋 。释放锁时,持有者只需将下一个等待线程对应的status位置设置为0即可 。 - 性能:每次释放只产生O(1)的网络流量 。但缺点是空间开销与处理器数量P成正比 。

基于队列的锁(MCS Lock)
- 核心思想:显式地将等待的线程组织成一个队列(链表) 。
- 实现:每个线程在自己的本地内存空间上分配一个锁节点(mlock)并在此节点上自旋 。获取锁时,线程通过原子操作将自己的节点加入到全局队列的尾部。释放锁时,线程只需通知队列中的下一个节点即可 。
- 优点:结合了票号锁的公平性和数组锁的低流量特性,是目前性能最好的自旋锁之一。

屏障的实现
一个有问题的集中式屏障
- 实现:使用一个锁和一个共享计数器 。线程到达屏障时,先加锁,然后将计数器加一。最后一个到达的线程(
num_arrived == p)设置一个flag来释放所有其他正在等待flag的线程 。 - 问题:如果屏障被连续使用两次,会出问题 。速度快的线程可能已经循环回来进入第二个屏障,而此时速度慢的线程还没离开第一个屏障,导致
flag被过早重置。

正确的集中式屏障
- 修正方法1:使用两个计数器,一个记录到达的线程数,一个记录离开的线程数,确保所有线程都离开上一轮屏障后,才能为下一轮重置标志 。这个实现比较复杂。
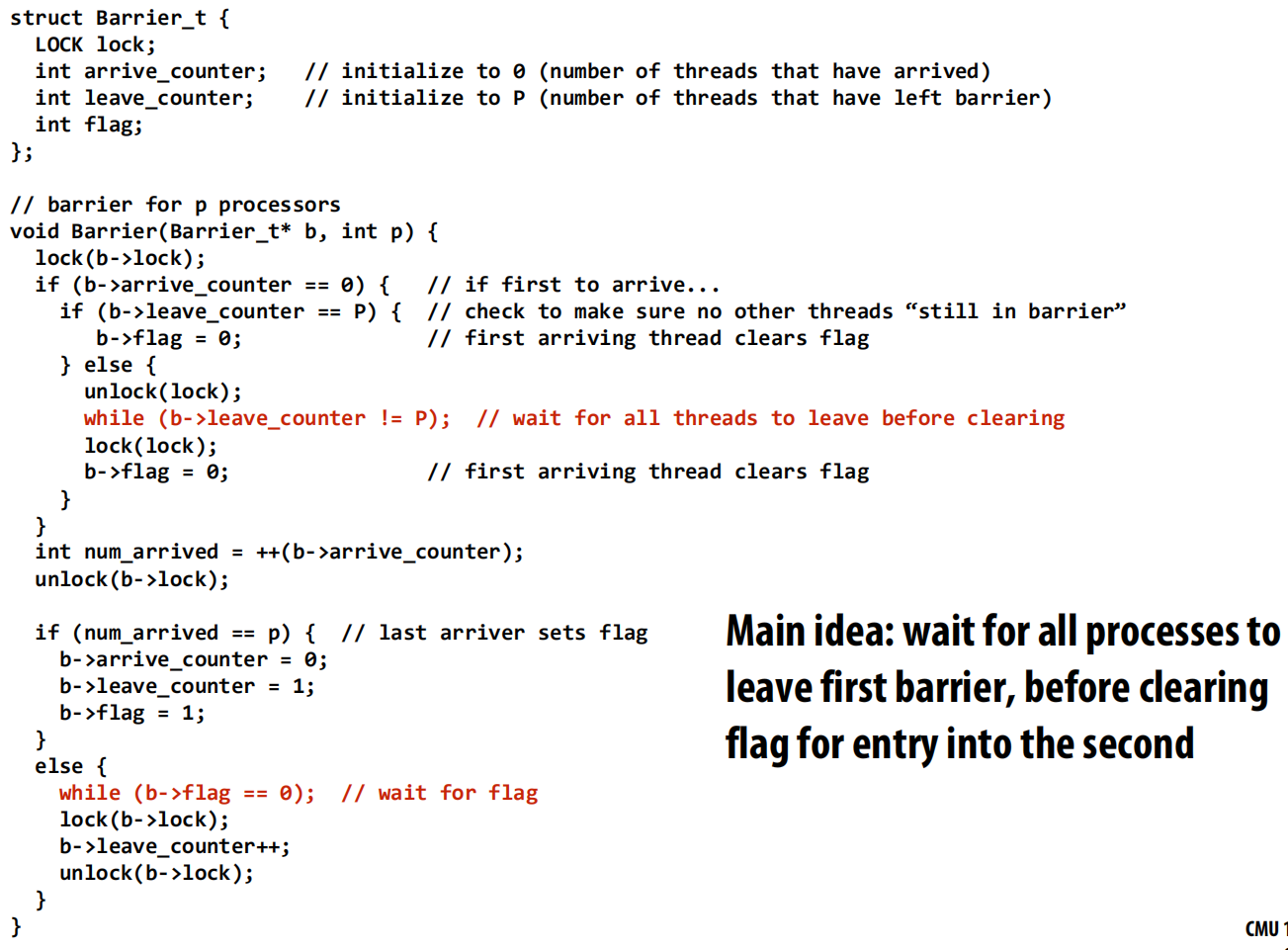
- 修正方法2(感觉反转 Sense Reversal):一种更优雅的实现。每个线程维护一个私有的
local_sense变量,其值在0和1之间切换 。线程到达后,等待全局的flag变得和自己的local_sense相等 。最后一个到达的线程负责翻转全局flag的值 。这巧妙地隔离了连续的屏障实例。

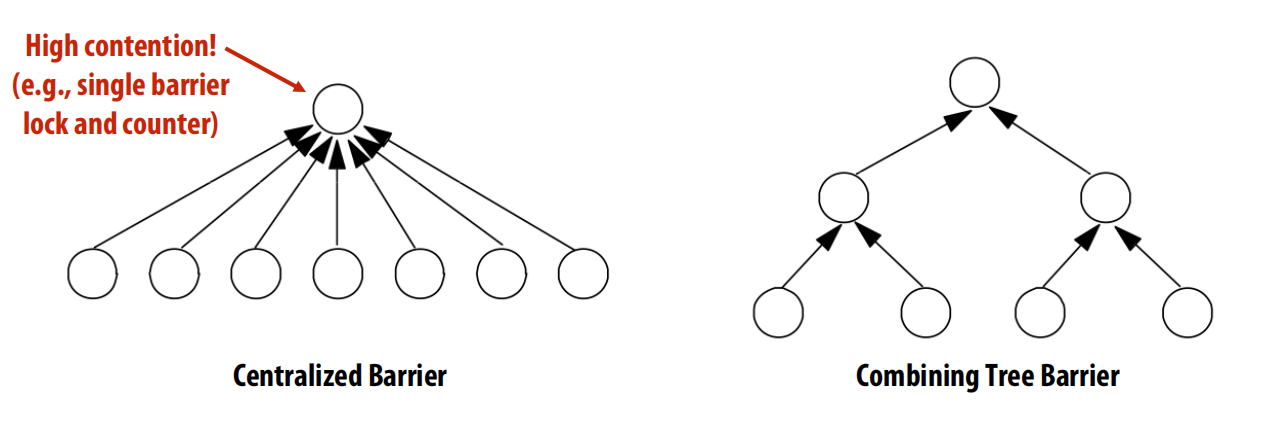
集中式屏障的性能与改进
- 性能瓶颈:所有线程都需要去获取同一个锁来更新计数器,这造成了序列化,导致整个屏障操作的延迟与处理器数量P成正比(O§) 。
- 改进(组合树屏障 Combining Tree Barrier):为了减少争用,可以将处理器组织成一棵树 。
- 到达阶段:线程只通知其在树中的父节点。这个过程逐级向上传递,直到根节点 。
- 释放阶段:信号从根节点开始,逐级向下广播给子节点 。
- 优点:将延迟从O§降低到O(log P) ,更具扩展性。
lec17 Fine-grained synchronization, lock-free programming
CUDA中的原子操作:
compare and swap


硬件如何保证原子性?
- 在x86架构上,通过给指令加上
LOCK前缀来实现 。 - 如果内存位置已在缓存中,处理器会锁定该缓存行直到操作完成 。
- 如果不在缓存中,在使用总线的系统中,处理器会锁定总线 ;在基于目录的系统中,处理器可能会拒绝(NACK)其他核心对该缓存行的请求,直到操作完成 。
细粒度同步
这部分探讨如何通过减小锁的粒度来提高数据结构操作的并行性。
- 问题案例:并发操作链表
- 如果没有同步机制,两个线程同时插入新节点(如线程1插入6,线程2插入7)会产生数据竞争 。
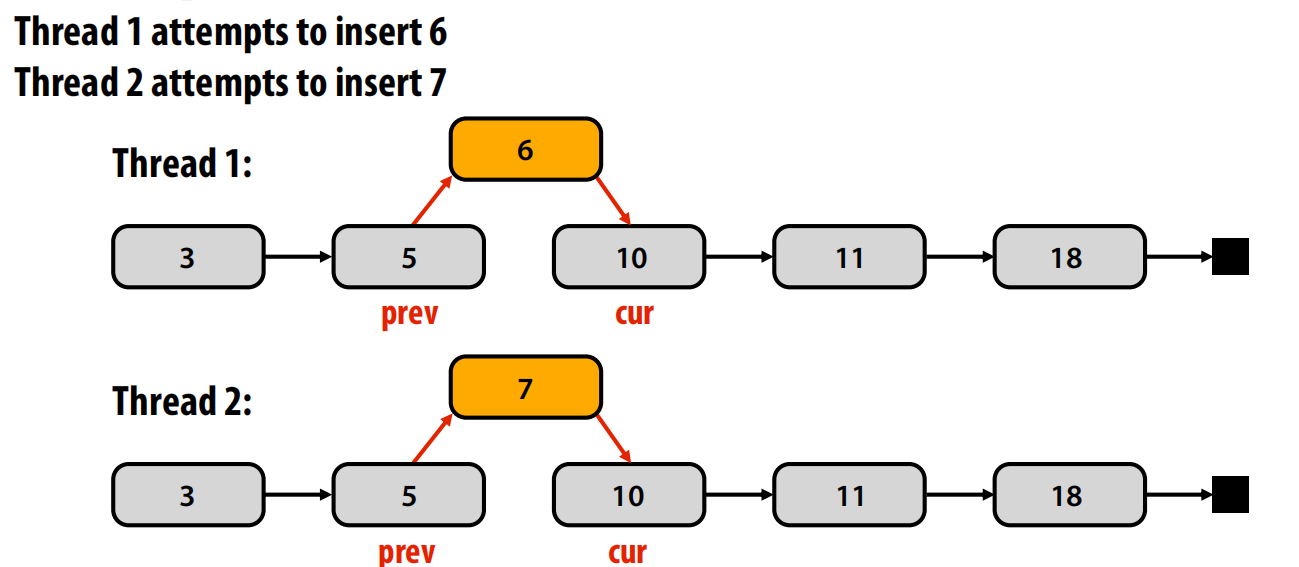
-
解决方案1:粗粒度锁。为整个链表设置一个全局锁 。在进行
insert或delete操作时,先获取这个锁,操作完成后再释放 。- 缺点:将对数据结构的所有操作序列化,严重限制了并行性能 。
-
解决方案2:细粒度锁(“手递手”式加锁)
-
核心思想:为链表中的每个节点分配一个独立的锁 。
-
“手递手”(Hand-over-hand)锁定:在遍历链表时,一个线程需要同时持有当前节点(
cur)和前一个节点(prev)的锁 。它的移动方式是:先锁住下一个节点,然后再释放更前一个节点的锁,就像手递手攀爬绳索一样。 -
这种方式允许多个线程在链表的不同部分并行地进行操作,只要它们操作的区域不重叠 。
-
开销:
- 执行开销:每次遍历都需要获取和释放锁,增加了指令开销 。
- 存储开销:每个节点都需要额外的空间来存储一个锁 。
-
折衷方案:可以考虑一种介于粗粒度和细粒度之间的方案(例如,将链表分段,每段一个锁),这与任务粒度的选择问题类似 。
-
无锁编程
这部分介绍了一种完全不使用锁的并发编程范式。
- 阻塞算法 vs. 无锁算法
- 阻塞算法(Blocking):一个线程可以无限期地阻止其他线程在共享数据结构上完成操作 。例如,一个线程获取了锁,然后被操作系统换出、崩溃或遇到页错误,那么其他所有需要该锁的线程都将停滞不前 。所有使用锁的算法都是阻塞的 。
- 无锁算法(Lock-free):保证在任何时候,系统中至少有一个线程能够取得进展(“系统级进展”) 。它不会因为某个线程被意外抢占而导致整个系统停顿 。但这并不保证单个线程不会饿死 。
- 无锁队列实例
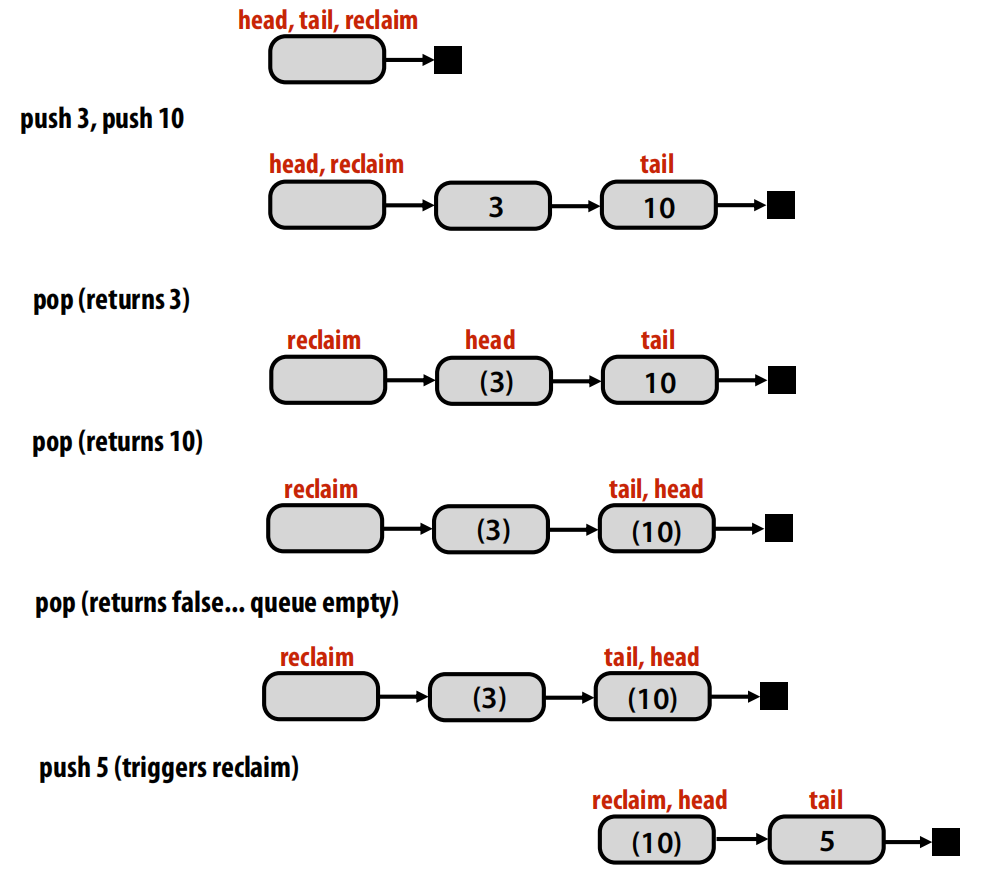
- 单生产者、单消费者队列:这是一个可以自然实现无锁的特例。因为生产者只修改队尾指针(
tail),而消费者只修改队头指针(head),两者操作不同的内存位置,因此在顺序一致性内存模型下无需同步 。
- 单生产者、单消费者队列:这是一个可以自然实现无锁的特例。因为生产者只修改队尾指针(
- 无锁栈(首次尝试)
- 核心思想:使用
compare_and_swap(CAS)来实现。无论是push还是pop操作,线程都会在一个循环中进行:- 读取当前的栈顶指针
old_top。 - 计算出新的栈顶
new_top。 - 使用
CAS尝试原子地更新s->top。只有当s->top的值仍等于old_top时,CAS才会成功,表明在操作期间没有其他线程修改过栈 。
- 读取当前的栈顶指针
- 这种方法完全不持有锁 。
- 核心思想:使用
- ABA问题
- 这是无锁编程中的一个经典且棘手的问题 。
- 过程描述:
- 线程0准备
pop,读取到栈顶是A,下一节点是B 。 - 线程0被抢占。
- 线程1介入,执行了
pop(A)、push(D)、再push(A) 。此时栈顶指针的值又变回了A,但栈的结构已经改变(A现在指向D,D指向B)。 - 线程0恢复执行,它的
CAS检查发现栈顶指针的值仍然是A(等于它的old_top),于是CAS成功了,将栈顶设置为B 。
- 线程0准备
- 后果:栈结构被破坏,节点D被丢失了 。
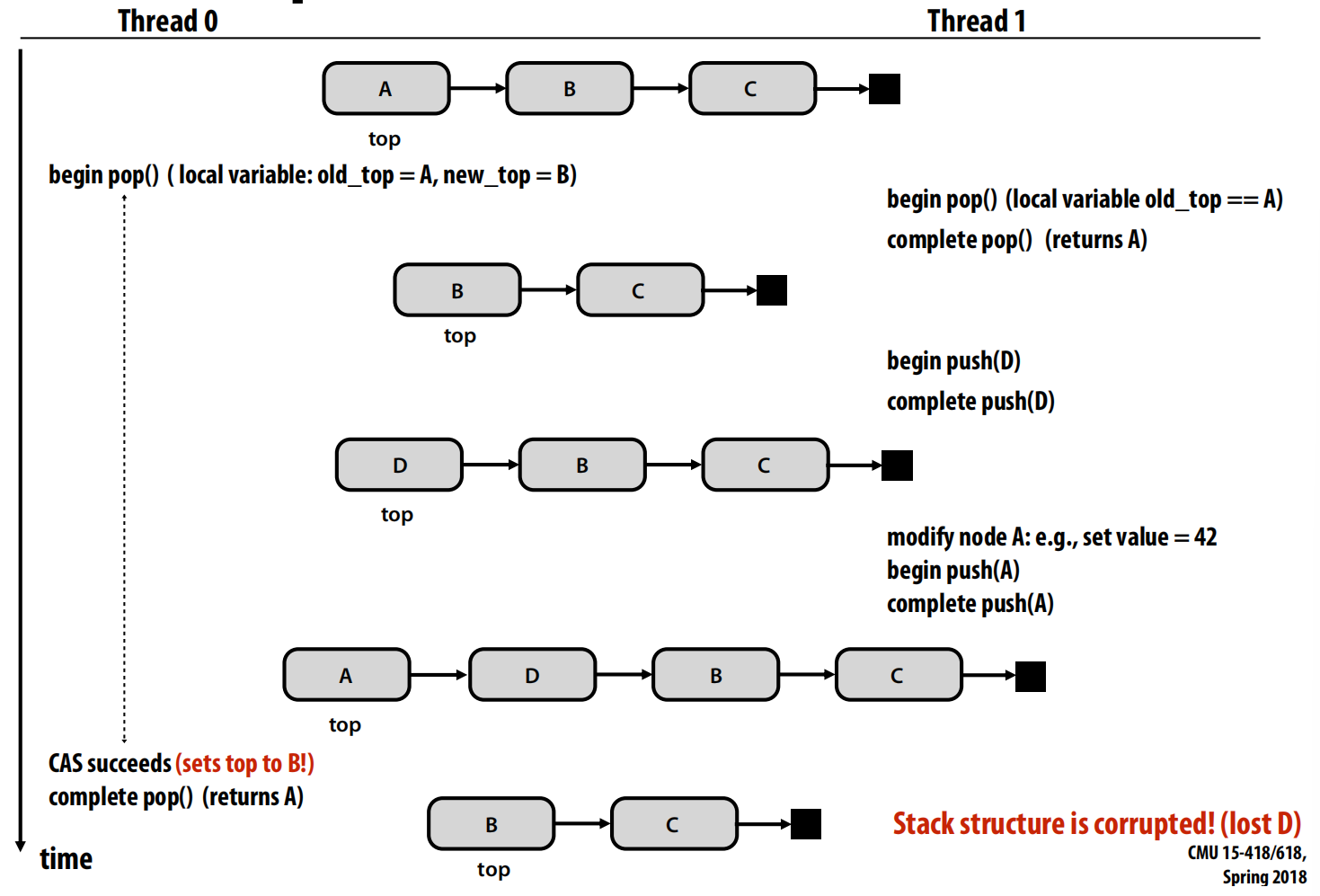
-
ABA问题的解决方案
- 方案1:双字比较并交换(DCAS)
- 将指针与一个计数器(如
pop_count)绑定在一起 。CAS操作现在需要同时比较指针和计数器。即使指针值变回A,计数器也已经改变,从而使CAS失败 。这需要硬件支持“双字宽”的CAS指令,如x86的cmpxchg8b或cmpxchg16b。
- 将指针与一个计数器(如
- 另一个问题:引用已释放的内存。当一个线程pop出一个节点并释放其内存后,其他线程可能仍持有指向该已释放内存的指针,如果解引用就会导致错误 。
- 方案2:危险指针(Hazard Pointers)
- 每个线程在一个共享的
hazard数组中声明它当前正在访问的节点指针 。 - 内存回收机制在释放一个节点前,必须检查它是否出现在任何线程的危险指针列表中。如果是,则不能回收该节点 。
- 每个线程在一个共享的
- 方案1:双字比较并交换(DCAS)
-
无锁链表
- 插入:无锁插入相对简单,与无锁栈的
push类似,在prev->next指针上循环使用CAS即可 。会出现while(1)等待,但这比锁的那种要轻松很多。

- 删除:无锁删除非常复杂 。例子:当一个线程删除节点B的同时,另一个线程成功地在B之后插入了E,这会导致B的
next指针指向了E,但B本身已经不在链表中,造成数据结构不一致 。
- 插入:无锁插入相对简单,与无锁栈的

- 性能比较
- 无锁算法并不总是更快。其性能与具体的数据结构、操作模式(如仅插入、生产者/消费者、随机操作)以及线程数密切相关 。
- 为什么在实践中使用无锁数据结构?
- 在高性能计算等场景中,程序员通常假设独占机器资源,此时精心编写的锁代码可能比无锁代码更快 。
- 然而,在多任务环境(如通用操作系统)中,持有锁的线程可能会因为页错误、被抢占等原因而暂停,这会引发优先级反转、**护航(convoying)**等严重性能问题 。无锁数据结构对这些情况更具鲁棒性。
lec18 Transactional memory
事务性内存
事务性内存概述
- 编程范式:命令式 vs. 声明式
- 传统锁(命令式):程序员需要明确地指定如何实现同步,例如在代码块前后调用
lock()和unlock()。 - 事务(声明式):程序员只需声明需要原子性执行的代码块,使用
atomic { ... }这样的语法 。系统负责实现其原子性,而无需程序员管理锁 。 - 这种声明式的方法允许系统采用更优化的策略,比如乐观并发(optimistic concurrency),即只有在真正发生数据冲突时才进行序列化,而不是一概加锁 。
- 传统锁(命令式):程序员需要明确地指定如何实现同步,例如在代码块前后调用
- 内存事务的属性
- 内存事务是指一个原子且隔离的内存访问序列 ,其思想来源于数据库事务 。
- 原子性(Atomicity):事务中的所有内存写入要么全部生效(提交),要么全部不生效(中止),不存在部分更新的情况 。
- 隔离性(Isolation):在事务提交之前,其内部的内存写入对其他处理器是不可见的 。
- 可串行性(Serializability):并发执行的事务其最终结果看起来像是以某个单一的串行顺序执行的,但具体的顺序不被保证 。
- 内存事务是指一个原子且隔离的内存访问序列 ,其思想来源于数据库事务 。
- LL/SC指令
- 加载链接/条件存储(Load-Linked/Store-Conditional)是一种轻量级的事务性内存形式 。它由一对指令组成:
load_linked加载一个值,而store_conditional只有在该地址自上次load_linked以来未被修改过的情况下,才会成功写入 。就像是提交一个事务一样。
- 加载链接/条件存储(Load-Linked/Store-Conditional)是一种轻量级的事务性内存形式 。它由一对指令组成:
使用事务性内存的动机
- 案例分析:哈希表(HashMap)
- 一个普通的
HashMap不是线程安全的 。 - 粗粒度锁:给整个
HashMap加一个大锁。这虽然线程安全,但严重限制了并发,扩展性差 。 - 细粒度锁:给每个哈希桶加一个锁。这能提高并发性能 ,但实现复杂且即使在没有竞争时也会带来锁开销 。
- 事务性内存:只需将操作放在
atomic块中 。它易于编程 ,并且性能有望媲美细粒度锁,因为它只在有实际数据冲突时才序列化执行 。
- 一个普通的

- 案例分析:树的更新
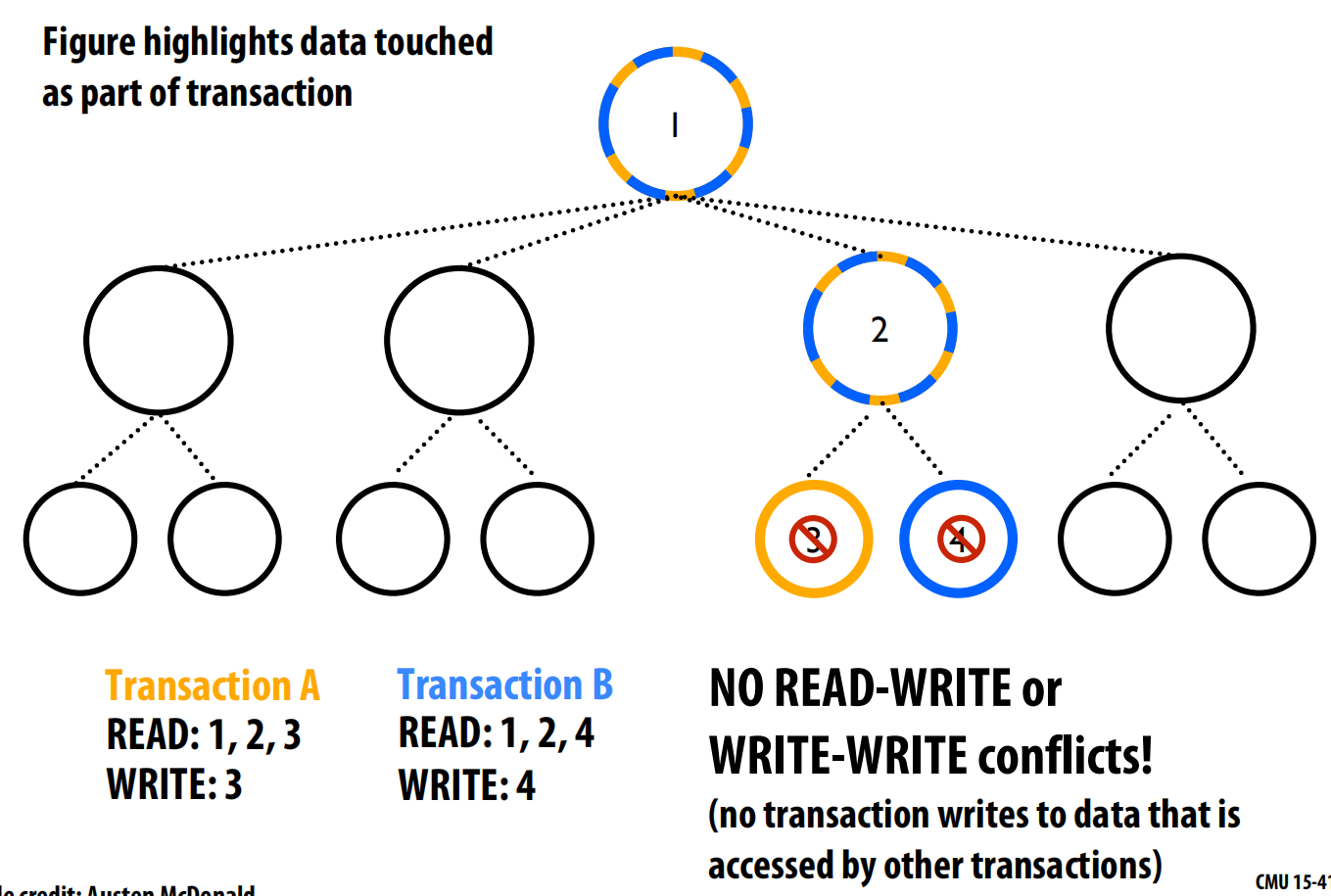
- 使用细粒度锁(如手递手式加锁)时,为了更新节点3,线程可能需要锁定其父节点(节点1和2),这会不必要地阻止另一个线程访问和更新完全不相关的节点4,从而限制了并发 。
- 使用事务性内存,系统会追踪每个事务的读集和写集。由于更新节点3和4的两个事务没有读写或写写冲突,它们可以并行执行 。只有当两个事务试图写入同一个节点时,系统才会检测到冲突并将其序列化 。
- 优势1:故障原子性(Failure Atomicity)
- 使用锁:如果在锁定的临界区内发生异常,程序员必须手动回滚状态 。比如用try-catch,在catch里面撤销操作。
- 使用事务:系统自动处理异常。任何未被捕获的异常都会导致事务中止(abort),所有内存更新都会被自动撤销,不会有部分更新泄露或锁未被释放的问题 。
- 优势2:可组合性(Composability)
- 使用锁:组合不同的带锁模块非常困难。例如,一个
transfer(A, B)函数内部锁定了A再锁定B,而另一个transfer(B, A)函数则顺序相反,同时调用它们就会导致死锁 。 - 使用事务:事务可以优雅地组合。一个外部事务会自动包含所有内部事务,形成一个更大的原子单元 。系统会自动管理并发和序列化,程序员无需关心实现细节 。
- 使用锁:组合不同的带锁模块非常困难。例如,一个
TM语义与实现基础

-
TM的语义辨析
-
重要区别:
atomic { }不等于lock() + unlock()。atomic是声明需要原子性,而不指定实现方式 。lock是一个特定的阻塞原语,它本身不提供原子性,只提供互斥 。- 因此,不能用
atomic块替换所有lock的用法,特别是当锁用于信令(signaling)而非原子性保护时 。如
1
2
3
4
5
6
7// 伪代码
lock(queue_lock);
while (is_empty(queue)) {
wait(condition_variable, queue_lock); // 消费者在此等待
}
task = pop(queue);
unlock(queue_lock); -
使用TM仍可能犯原子性违规的逻辑错误,例如将一个逻辑上完整的原子操作拆分到两个
atomic块中 。eg.
1
2
3
4
5
6
7
8
9// 错误!将一个逻辑操作拆分了
atomic {
account_A.balance -= 100;
}
// 在这两个atomic块之间,系统是无政府状态!
// 另一个线程可能在这里执行,读取到不一致的数据。
atomic {
account_B.balance += 100;
} -
-
TM实现的基本要求
- TM系统必须在提供原子性和隔离性的同时,不牺牲并发性 。
- 两大核心要求:
- 数据版本管理(Data Versioning):管理新旧两个版本的数据,以便在事务中止时可以回滚。
- 冲突检测(Conflict Detection):判断何时发生了冲突,决定何时需要中止事务。
- 实现方式主要有硬件(HTM)、软件(STM)和混合型三种 。
-
数据版本管理
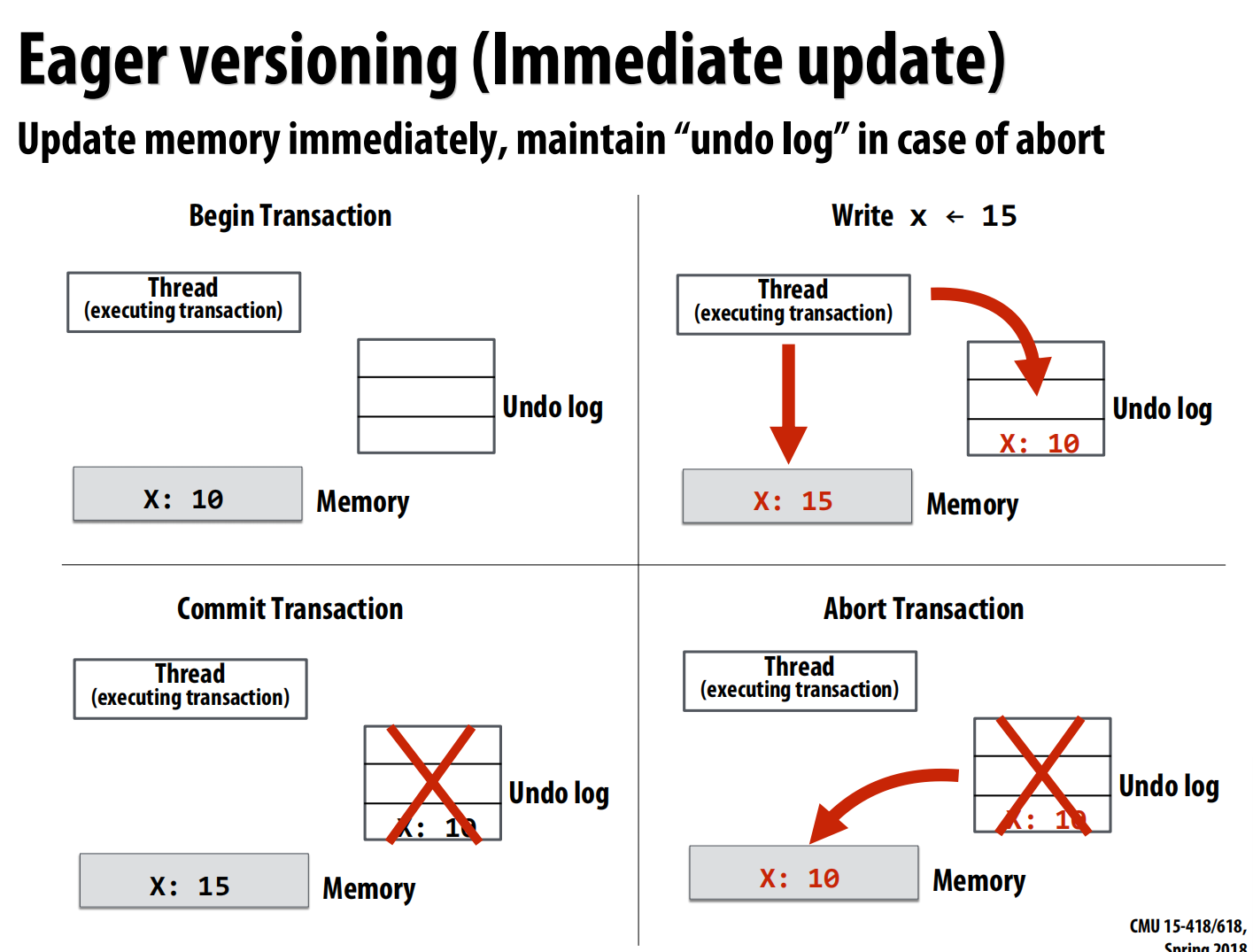
- 主动版本管理(Eager Versioning):
- 基于撤销日志(Undo Log) 。
- 写操作立即修改内存,同时将旧值保存在undo log中 。
- 优点:提交速度快(数据已在内存中) 。
- 缺点:中止速度慢(需要根据log恢复数据),容错性差 。
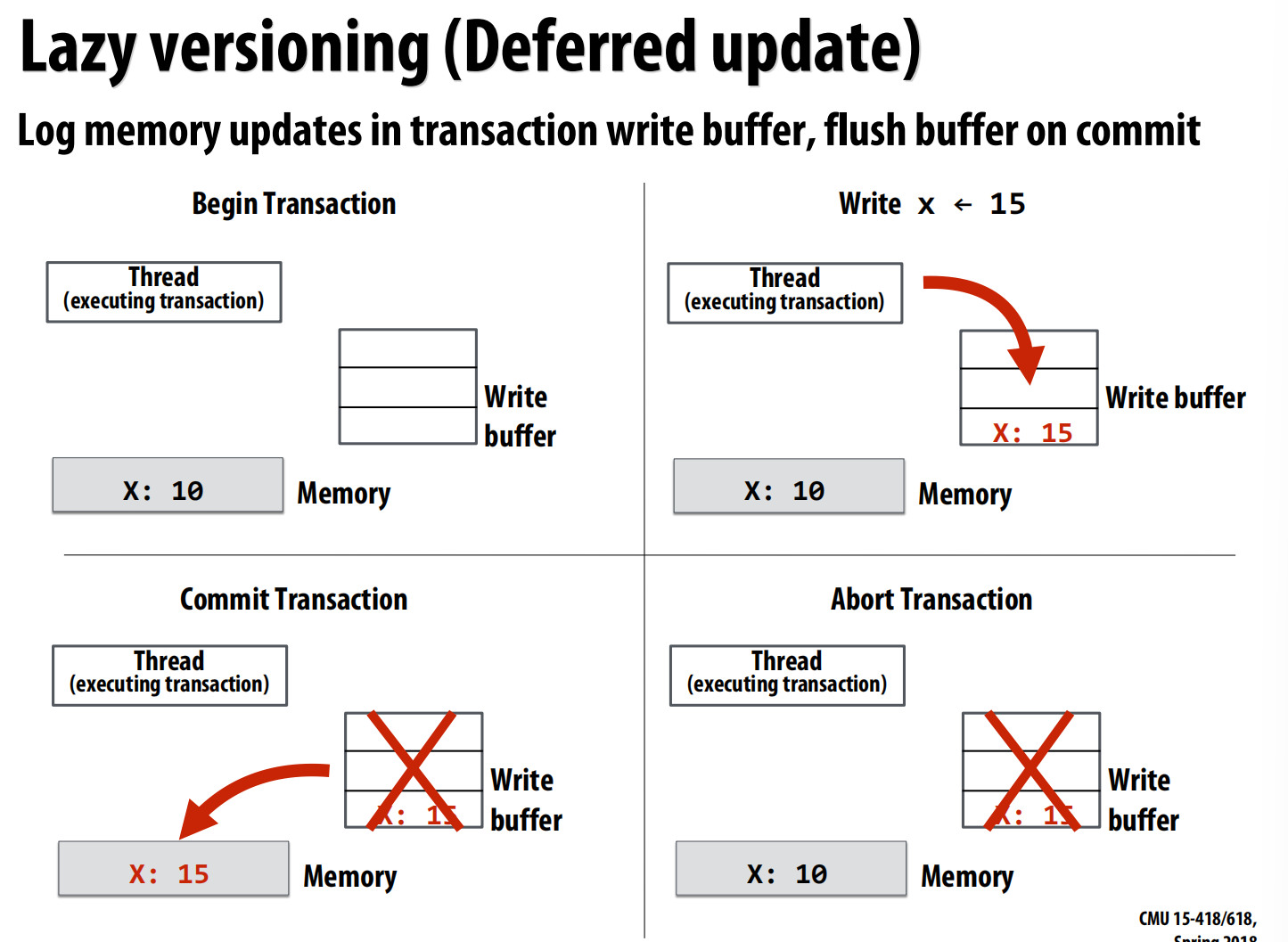
- 懒惰版本管理(Lazy Versioning):
- 基于写缓冲(Write Buffer) 。
- 写操作先保存在本地的write buffer中,直到提交时才一次性写入内存 。
- 优点:中止速度快(丢弃buffer即可),容错性好 。
- 缺点:提交速度慢(需要将buffer刷入内存) 。
- 主动版本管理(Eager Versioning):
-
冲突检测
- 系统需要追踪每个事务的**读集(read set)和写集(write set)**来检测冲突 。
- 悲观冲突检测(Pessimistic Detection):
- 在每次读写操作时都检查是否存在冲突 。
- 优点:能尽早发现冲突,可能将中止操作转为暂停等待 。
- 缺点:通信开销大,检测逻辑在关键路径上,且不保证系统能取得进展(可能导致活锁,如下图4) 。

- 乐观冲突检测(Optimistic Detection):
- 只在事务尝试提交时才检查冲突 。
- 优点:保证系统能取得进展,检测和通信是批量的 。
- 缺点:发现冲突晚,可能浪费了已做的工作 。

硬件事务性内存 (HTM) 实现
- HTM基本原理
- 数据版本管理在缓存中实现:通过修改缓存行元数据来追踪读集和写集 。
- 冲突检测通过缓存一致性协议实现:利用总线监听或目录消息来检测其他处理器对事务内数据的访问 。
- 缓存行元数据:在每个缓存行(或字)上增加
R(读)和W(写)比特位 。
- 一个懒惰-乐观HTM的执行流程
Xbegin(事务开始):对寄存器状态进行快照,初始化缓存状态 。Load A:将数据A加载到缓存,并设置其R位 。Store C <- 5:将新值5写入缓存行C,并设置其W位。数据此时仍在本地缓存中,未写入主存(懒惰版本管理) 。Xcommit(事务提交):这是乐观检测点。系统首先请求获取所有W-set中缓存行的独占所有权(进行验证)。成功后,原子地清除所有R/W位,事务正式提交 。- 冲突与中止:如果在事务提交前,该处理器监听到一个来自远端的写请求(如
upgradeX A),该请求与本地R-set中的A冲突,事务将立即中止。中止操作会丢弃W-set中的修改,并恢复寄存器快照 。
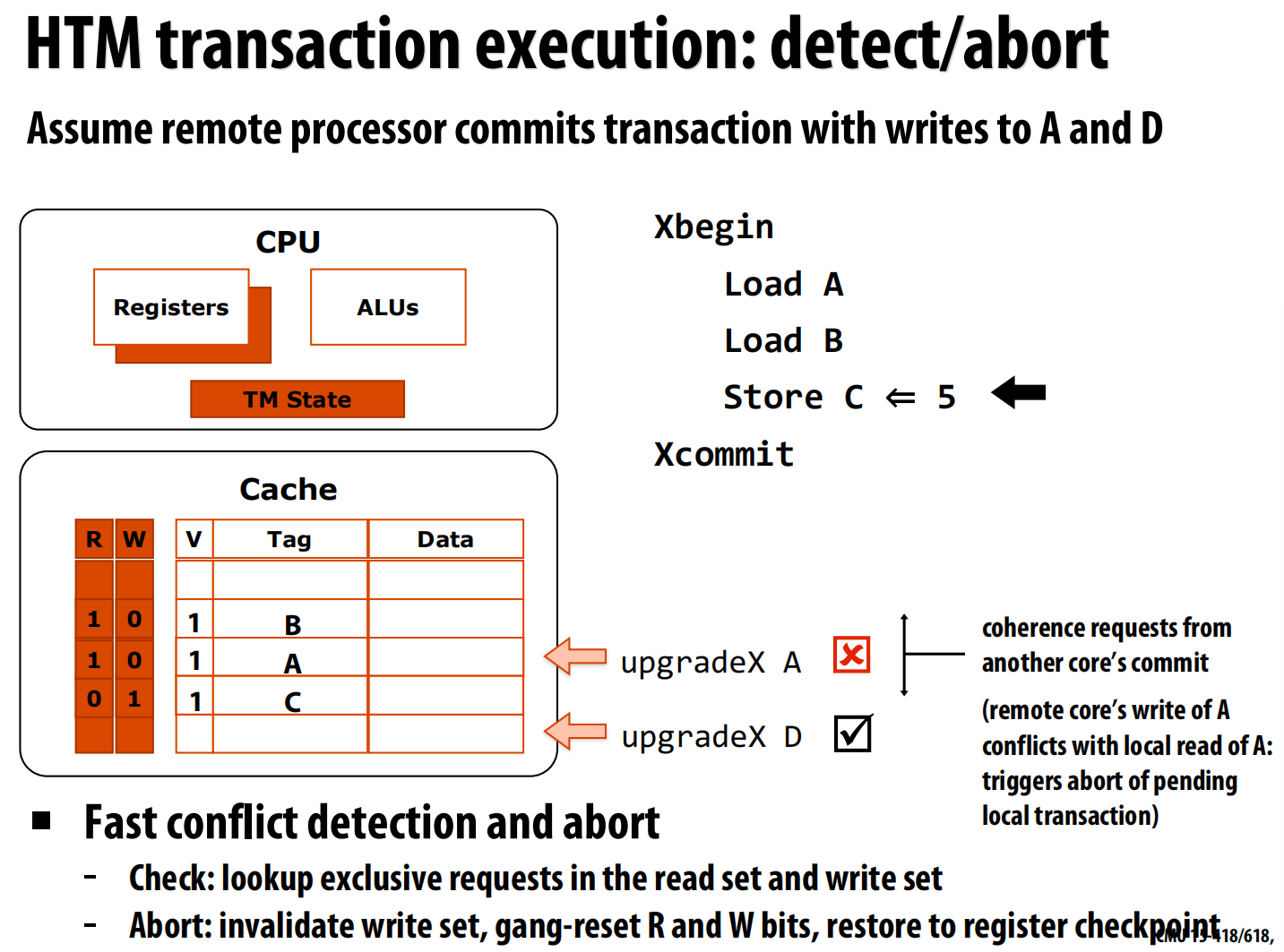
-
Intel TSX(事务同步扩展)
- Intel Haswell架构引入了受限事务性内存(RTM),提供了
xbegin,xend,xabort等指令 。
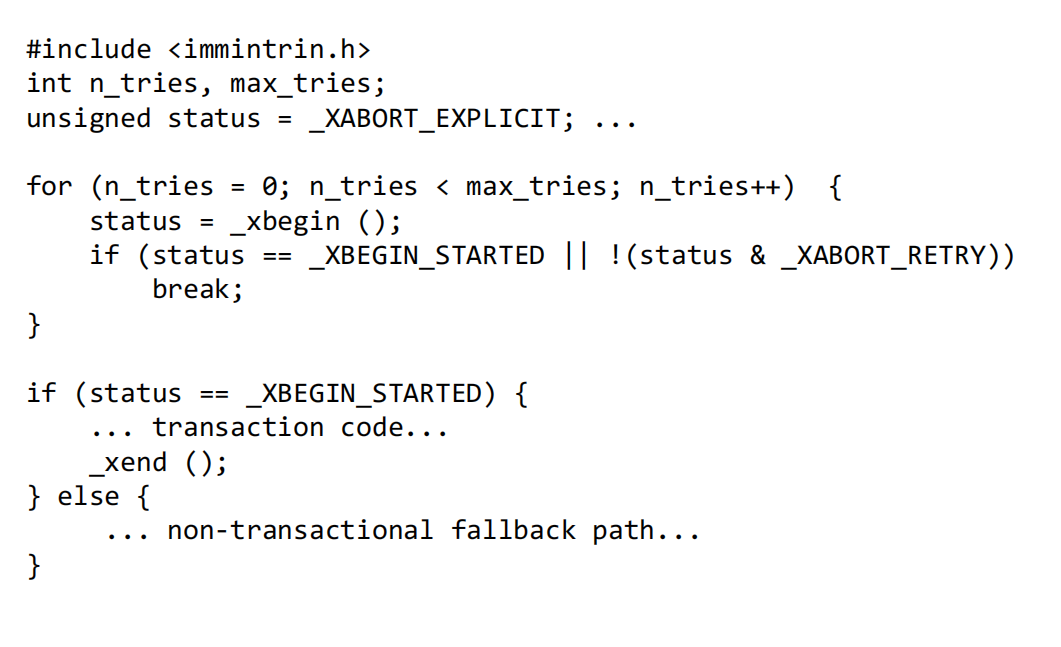
- 它在L1缓存中追踪读写集 。
- 核心限制:TSX不保证事务一定能成功。事务可能因多种原因(如缓存行被驱逐)而自动中止 。因此,程序员必须提供一个回退路径(fallback path),通常是使用传统锁的代码,以保证程序能继续执行 。
- 性能开销:一次TSX事务的开销约等于对同一缓存行执行6次原子操作 。
- Intel Haswell架构引入了受限事务性内存(RTM),提供了
lec19 Heterogenous parallelism
处理器架构的选择
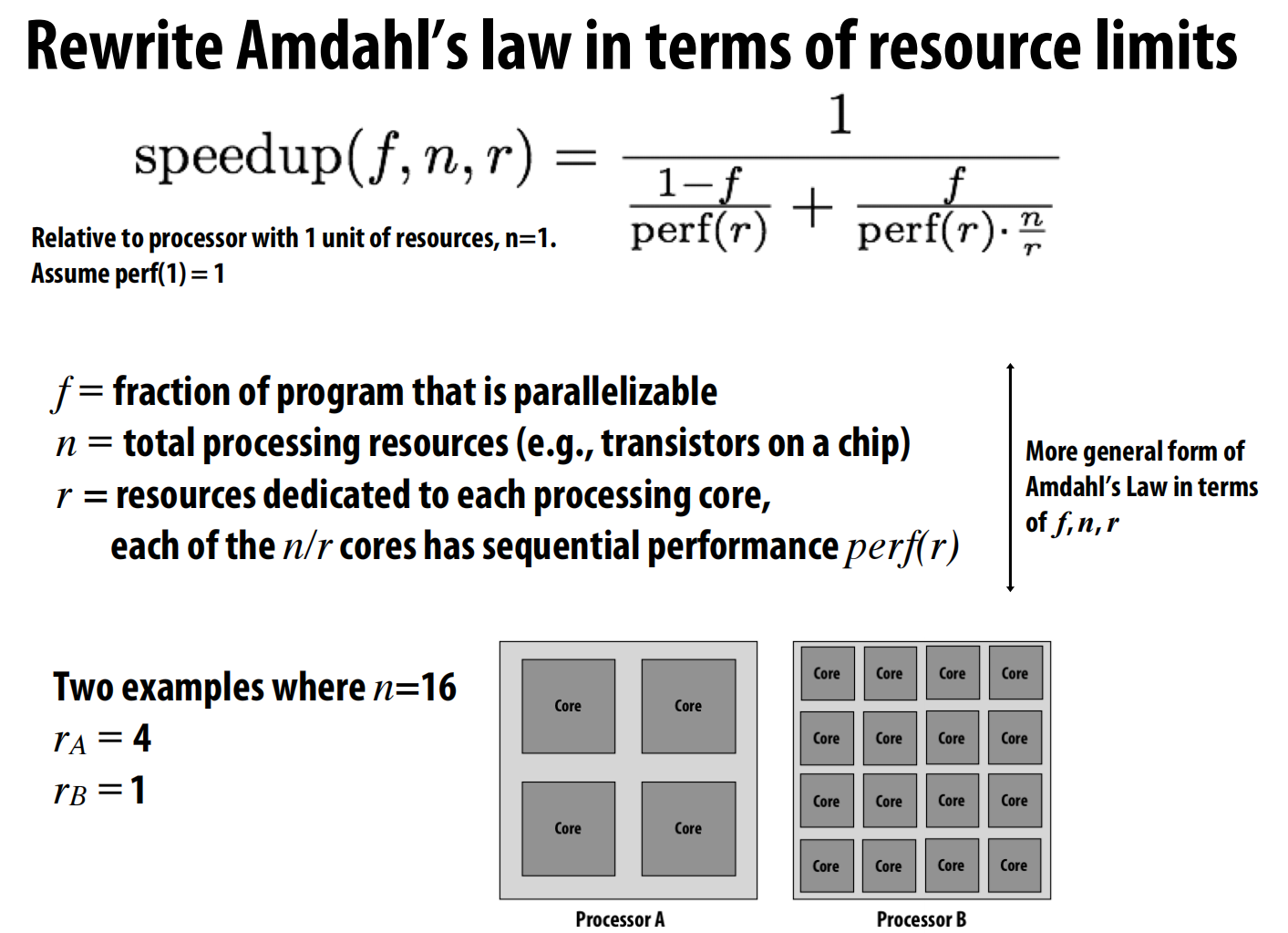
-
将芯片总资源
n和分配给每个核心的资源r作为变量 。-
核心数量为
n/r。 -
每个核心的性能被建模为
perf(r),这里假设perf(r) = √r。 -
结论:如果一个程序的可并行部分非常高(如
f=0.999),那么拥有大量“瘦”核心(r值小)会获得更好的性能。
-
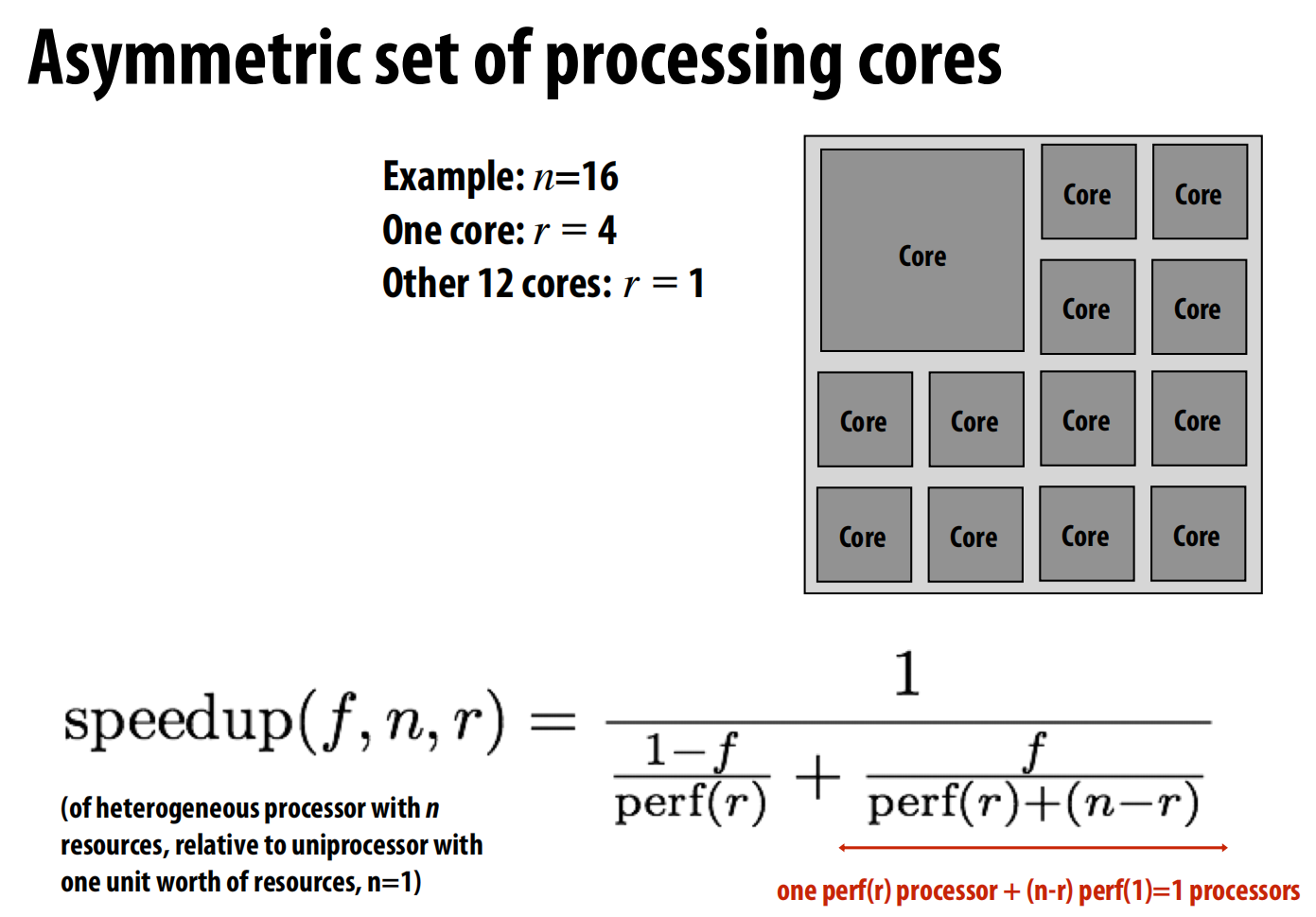
-
非对称(Asymmetric)多核架构
- 非对称架构:在一块芯片上集成一个或几个高性能的“胖”核心和大量低功耗的“瘦”核心 。
- 执行策略:程序的串行部分(
1-f)运行在“胖”核心上,以获得最快的执行速度;而并行部分(f)则可以同时利用“胖”核心和所有“瘦”核心来执行。
- 执行策略:程序的串行部分(
- 非对称架构:在一块芯片上集成一个或几个高性能的“胖”核心和大量低功耗的“瘦”核心 。
异构计算在现代系统中的应用
这部分展示了异构计算并非只停留在理论层面,而是已经广泛应用于从移动设备到超级计算机的各种现代系统中。
-
核心思想:最高效的处理器应该是不同处理资源的混合体,做到“用最合适的工具干最合适的活” 。
-
消费级产品中的异构计算
- Intel “Skylake” 处理器:将4个高性能CPU核心与一个集成GPU(包含众多并行处理单元)和专用媒体处理单元集成在同一芯片上 。CPU和GPU共享三级缓存(LLC),实现了两者之间低延迟、高带宽的通信 。
- 高端笔记本(如MacBook Pro):除了CPU自带的集成GPU,还额外配备一个独立的、性能更强但功耗也更高的GPU 。系统可以根据任务需求动态切换。
硬件专用化的驱动力:能效
这一部分深入探讨了为什么异构和专用化成为主流,核心驱动力是能源效率。
- 计算专用化的巨大能效优势
- 经验法则:
- GPU:对于适合并行处理的任务,其每瓦性能(perf/watt)约是CPU的10倍 。
- ASIC(专用集成电路):为特定功能设计的硬件,其每瓦性能可达到CPU的100-1000倍甚至更高 。
- 能耗分析:一个典型的处理器,其功耗主要花在**指令供给(42%)和数据供给(28%)**上,而真正用于算术运算的仅占6% 。专用硬件通过固化算法逻辑,极大地减少了指令和数据供给的开销。
- 经验法则:
异构设计的挑战与
- 异构设计的挑战
- 对硬件设计者:最难的是决定资源的正确组合 。如果为某个特定功能(如视频解码)分配的专用硬件过少(under-provisioning),它就会成为整个系统的瓶颈,导致昂贵的通用CPU核心处于空闲等待状态,大大降低整体效率 。这要求芯片设计师在设计阶段就能准确预测未来的工作负载。
- 对软件开发者:
- 如何将一个复杂的程序分解,并将其不同部分有效地映射到不同的处理单元上,是一个巨大的挑战 。调度问题变得更加复杂 。软件的可移植性和维护成为一场噩梦 。
- 节能计算的趋势与总结
- 趋势一:使用专用处理(已详细讨论)。
- 趋势二:减少数据移动 。
- 为了节能,重新计算一个值可能比从内存中加载它更划算 。充分利用数据局部性至关重要。
- 另一个策略是数据压缩:在传输数据前,花费一些计算资源进行压缩,以减少传输的数据量 。
lec20 Domain-specific programming languages
软件效率与硬件复杂性
-
软件性能的巨大差距
- 以C/C++代码为基准,许多流行的高级语言(如Python, PHP, Ruby)的执行速度要慢40到100多倍 。即便是一段普通的、单线程的C代码,与并行和向量化优化的版本相比,性能也可能相差20倍以上 。
-
编程的挑战
-
硬件趋势:为了在能源消耗受限的情况下提升性能,现代处理器正变得越来越并行化和异构化 。一块芯片上集成了多种处理单元 。
-
编程模型的碎片化:为了驾驭这种异构硬件,出现了一系列互不兼容的编程模型 。
- 核心内SIMD:需要用ISPC, Cuda, OpenCL等模型 。
- 多核间共享内存:需要用OpenMP, Cilk, TBB等模型 。
- 跨设备/节点:需要用MPI, Go, Spark等消息传递模型 。
-
我们如何才能让程序员**高效地(productively)编写出能够高性能地(efficiently)**利用当前及未来异构并行计算机的软件?
-
解决方案:领域特定编程系统
这部分提出了一个解决上述挑战的强大思路:领域特定语言(DSL)。
- 一个理想的编程语言希望能同时满足三个目标:
- 高性能 (High Performance):软件可扩展且高效 。
- 高生产力 (Productivity):易于开发和维护 。
- 完备性 (Completeness):能用于解决几乎所有类型的问题 。
- 现实是,没有语言能完美占据三角形的中心。
- C/C++ 追求高性能和完备性,但牺牲了生产力 。
- Python, JavaScript, Ruby 等脚本语言追求高生产力和完备性,但牺牲了性能 。
- 领域特定语言 (DSL) 和框架 的策略是:牺牲完备性,只专注于解决某一特定领域的问题,以换取同时达到高性能和高生产力 。
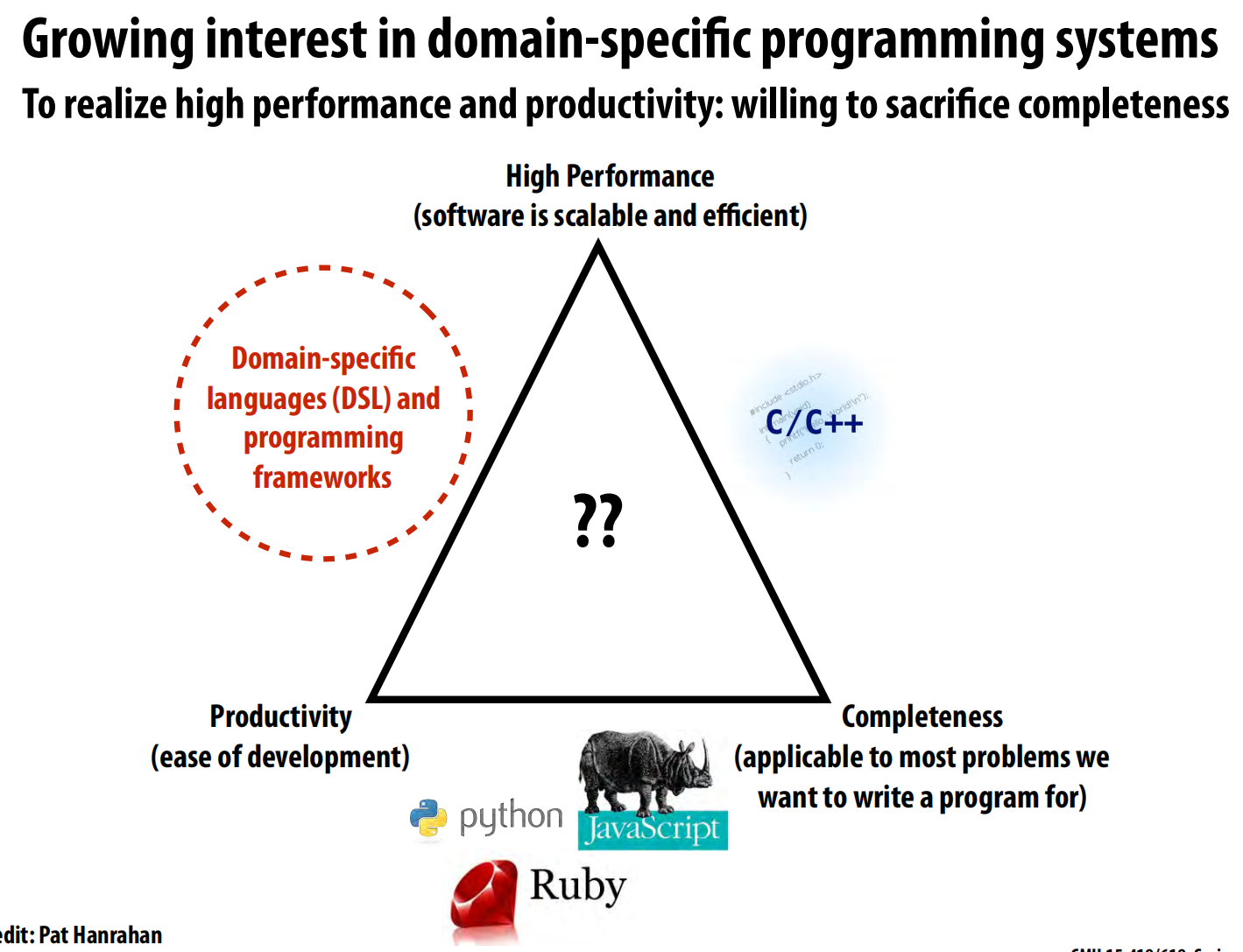
- 领域特定编程系统的核心思想
- 提高抽象层次:DSL提供一套与特定应用领域高度相关的编程原语(primitives),让程序员能用他们熟悉的术语来直观地描述问题 。
- 蕴含领域知识:系统(编译器和运行时)由于知晓这是在特定领域(如图像处理、科学计算)内编程,因此可以利用这些领域知识来自动进行复杂的优化,并生成针对不同硬件的高效代码 。
- 例子:SQL就是一种非常成功的数据库查询DSL。本讲座将重点介绍两个例子:Liszt(用于网格上的科学计算)和Halide(用于图像处理)。
案例学习1:Liszt
Liszt是一个为在非结构化网格上求解偏微分方程(PDE)而设计的DSL。
- Liszt程序的核心概念
- Liszt程序操作的对象是网格(mesh),它由顶点(Vertex)、边(Edge)、面(Face)等拓扑元素构成 。
- 程序员通过定义**场(Field)**来在网格元素上存储数据,例如在每个顶点上定义一个
Temperature(温度)场 。 - 程序通过拓扑操作符来访问网格数据,例如
head(e)返回边e的头顶点,vertices(mesh)返回网格中所有顶点的集合 。 - 关键设计:程序员只与抽象的网格和拓扑关系打交道,而无需关心网格在内存中的具体数据结构。这个数据结构由Liszt编译器根据程序的实际需求来决定 。

- 自动并行化的关键:依赖分析
- 并行编程的核心挑战在于依赖分析:确定哪些计算可以并行,哪些数据需要同步 。在通用语言中,编译器很难进行全局依赖分析(例如,
a[f(i)]中的索引f(i)在运行时才能确定)。 - Liszt通过语言限制(如数据只能通过拓扑操作符访问、无递归等)来确保编译器可以静态地分析出每个循环迭代所访问的网格元素集合,这个集合被称为“模板(stencil)” 。这个模板就代表了该次迭代的全部依赖。
- 并行编程的核心挑战在于依赖分析:确定哪些计算可以并行,哪些数据需要同步 。在通用语言中,编译器很难进行全局依赖分析(例如,
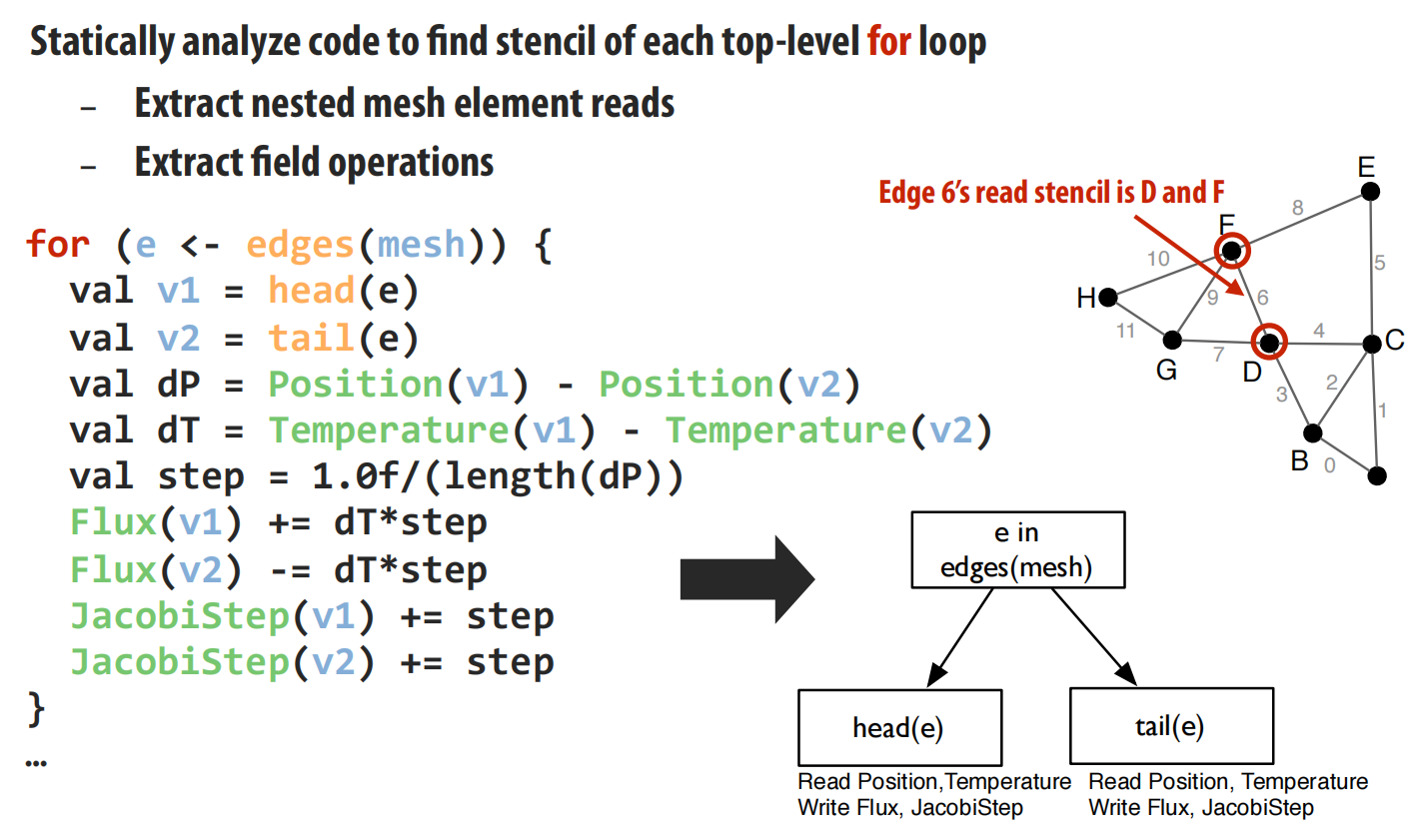
-
可移植的高性能:自动生成并行策略
- 一旦编译器知道了依赖关系,它就可以针对不同的硬件平台生成不同的、最优的并行执行策略。
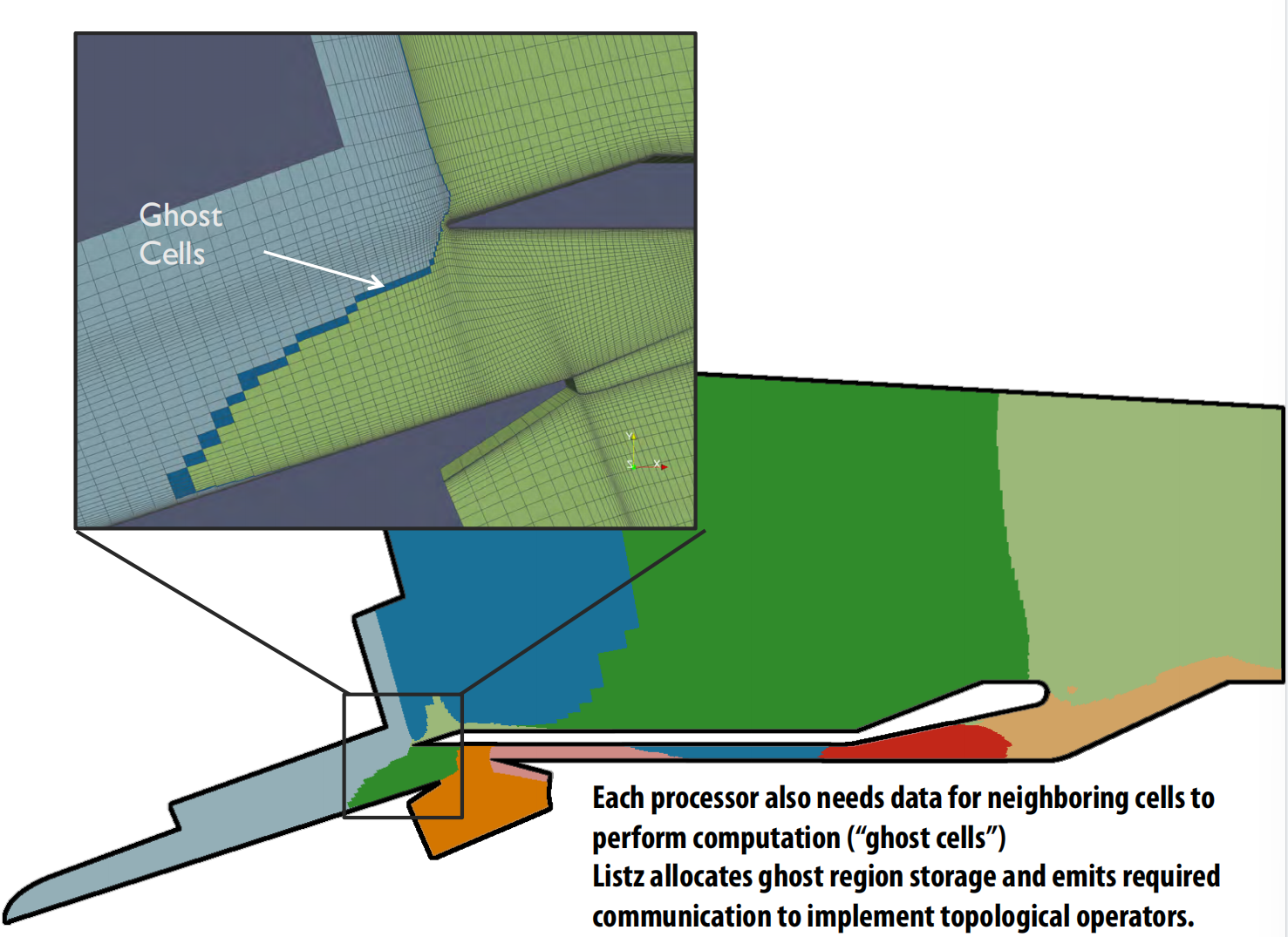
- 策略1:用于分布式集群(如MPI)——网格划分
- 编译器使用ParMETIS等工具将巨大的网格划分成多个子块,每个子块分配给一个计算节点 。
- 对于跨越边界的依赖,编译器会自动创建“影子单元(ghost cells)”并生成必要的通信代码来获取邻居节点的数据 。
- 策略2:用于GPU——图着色
- 在GPU上,自然的并行单位是让每个线程处理一条边 。
- 问题:多条边可能更新同一个顶点,需要用开销高昂的原子操作来同步 。
- 解决方案:编译器根据依赖关系构建一个冲突图,图中的每个节点代表一次循环迭代(一个线程),如果两次迭代会写入同一内存位置,则在它们之间连一条边 。然后,编译器对这个图进行“着色”,确保相邻节点颜色不同 。
- 执行时,所有相同颜色的迭代可以作为一个批次并行执行,因为它们之间保证没有冲突,从而避免了原子操作 。
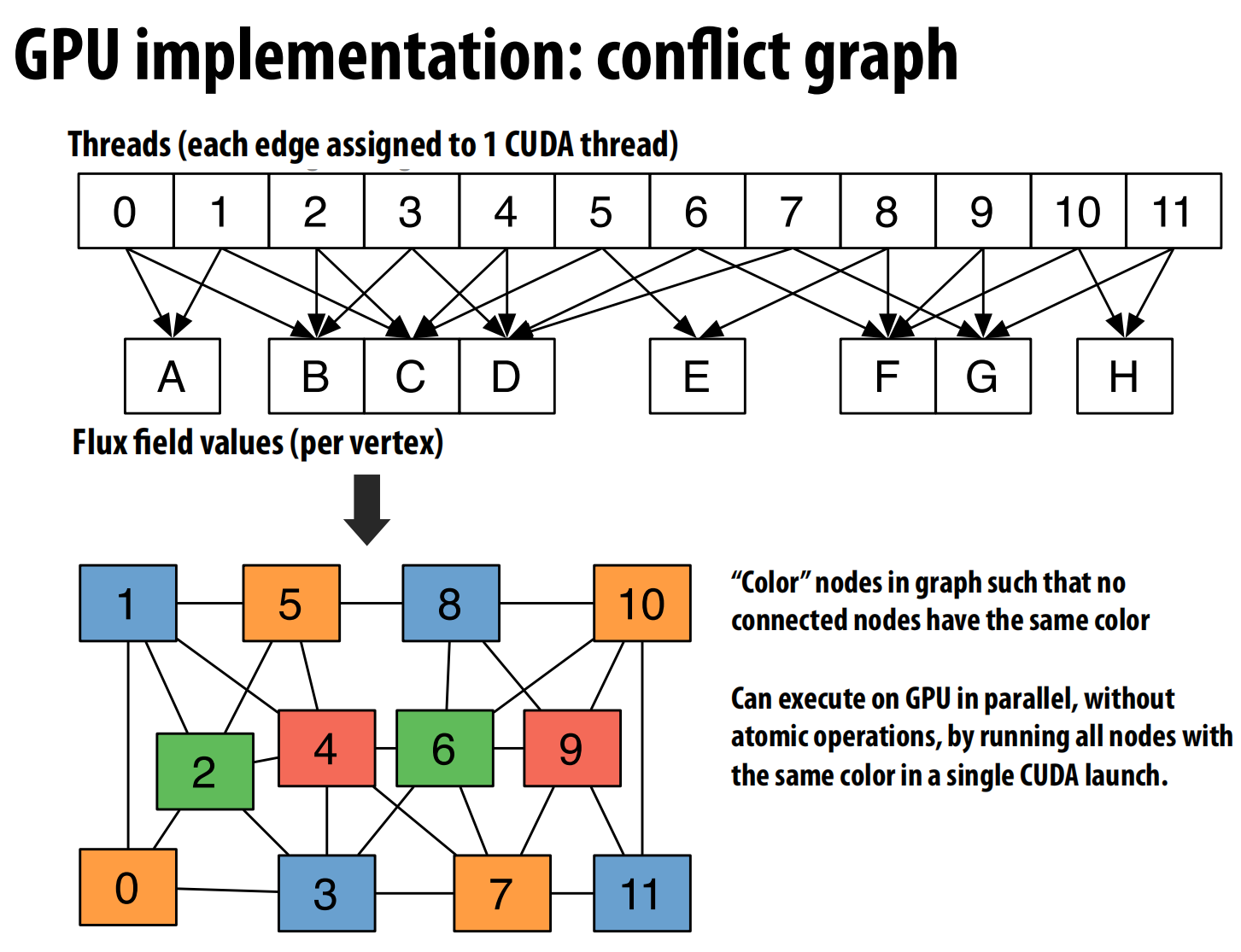
- 结果:同一份Liszt源代码,不加修改,既可以在CPU集群上高效运行(通过网格划分),也可以在GPU上高效运行(通过图着色),实现了真正的性能可移植性 。
案例学习2:Halide
Halide是一个为图像处理流水线(image processing pipeline)设计的DSL。
- Halide的核心思想:算法与调度分离
- 传统方式优化图像处理代码(如一个3x3的filter),需要手动进行复杂的代码转换,如循环分块(tiling)、SIMD向量化、多线程并行等。
- Halide的突破性思想是将“算法”(Algorithm)与“调度”(Schedule)彻底分离 。
- 算法:用简洁的函数式语言描述做什么(what)。程序员只需描述每个像素点的输出值是如何由输入值计算得来的。例如,
blurx(x,y) = (in(x-1, y) + in(x,y) + in(x+1,y)) / 3.0f;。 - 调度:用另一套简单的命令式语言描述怎么做(how)。程序员通过调用
tile,vectorize,parallel等函数来指定循环的顺序、分块的大小、并行化的方式等 。
- 算法:用简洁的函数式语言描述做什么(what)。程序员只需描述每个像素点的输出值是如何由输入值计算得来的。例如,
- 程序员不再需要手动重写复杂的循环嵌套和SIMD指令,只需调整调度代码,就可以快速地探索巨大的优化空间 。Halide编译器负责将算法和调度结合,机械地生成对应的高性能底层代码 。

- 调度原语与性能
- Halide提供了丰富的调度原语,允许程序员精细控制计算的顺序和数据的存储时机,从而在计算冗余和数据局部性之间做出权衡。
更广阔的前景与总结
- 更多DSL实例与实现方式
- DSL的思想正在被应用到更多领域,如:
- Darkroom:一个类似Halide的语言,可以直接从高级描述综合出用于图像处理的FPGA或ASIC硬件电路 。
- Hadoop (MapReduce):用于大数据并行计算的框架 。
- GraphLab:用于图机器学习的DSL 。
- DSL可以作为独立的语言(如SQL),也可以嵌入到一种通用语言中(如Halide和Liszt都可嵌入C++或Scala)。
- DSL的思想正在被应用到更多领域,如:
lec21 Domain-specific frameworks
大规模图计算
案例学习:GraphLab
这部分以GraphLab为例,深入探讨一个图计算领域特定框架的设计理念和编程模型。
- 图计算实例:PageRank
- PageRank是一种经典的迭代式图算法,用于评估网页的重要性。其核心思想是:一个页面的排名(Rank)是所有链接到它的其他页面的排名的加权总和。这个计算过程会在图上反复迭代,直到排名收敛。

- GraphLab简介与编程模型
- GraphLab:用于描述图上迭代计算的C++框架 。
- 编程模型:
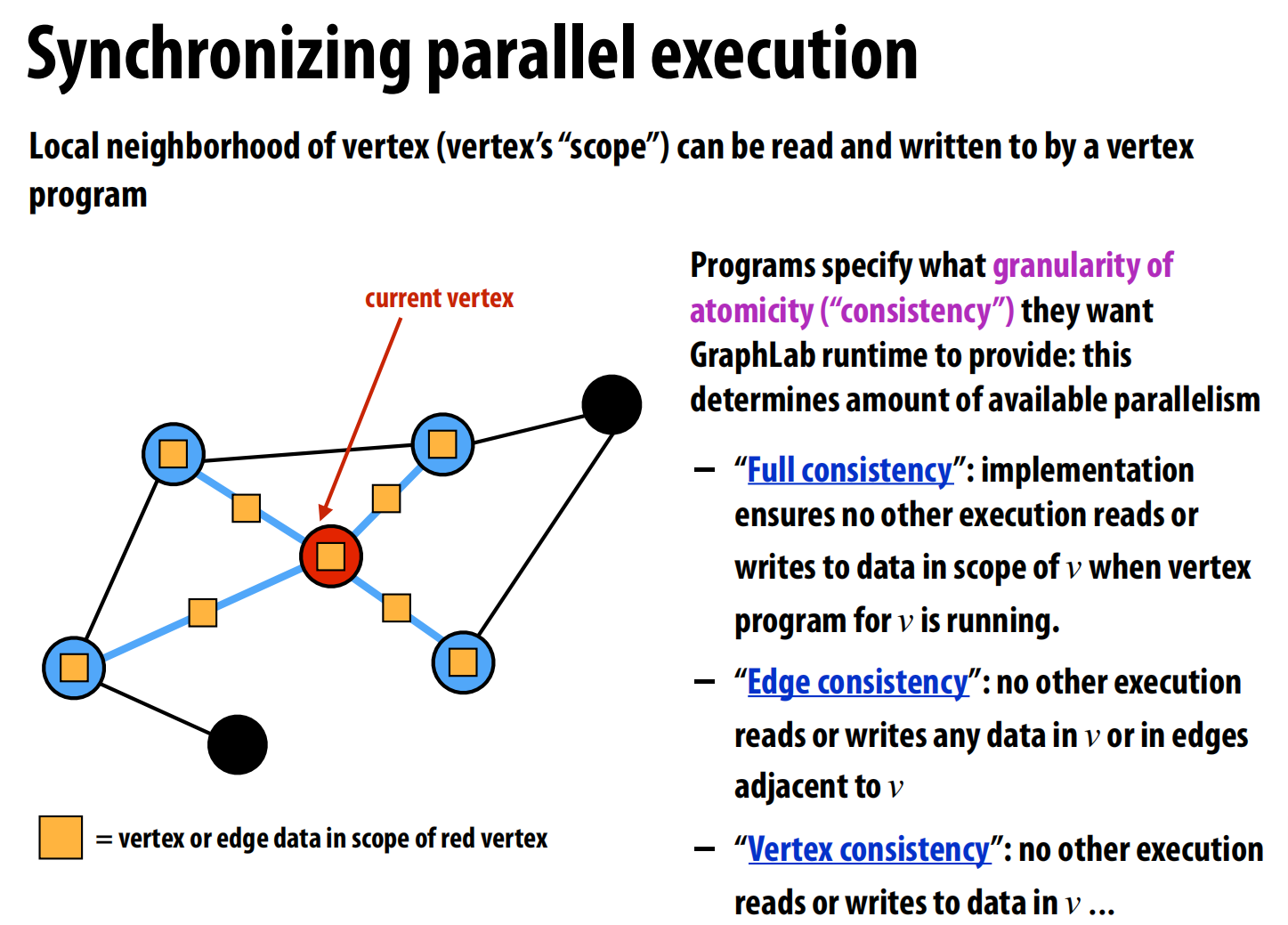
- 状态(State):程序的状态由图
G=(V, E)构成。程序员可以在每个**顶点(Vertex)和每条边(Edge)**上定义数据块 。此外还有只读的全局数据。 - 操作(Operations):核心操作是定义一个“顶点程序(Vertex Program)”。这个程序定义了在单个顶点上执行的计算,其能访问的数据范围被限制在该顶点的“局部邻域(scope)”内,即该顶点自身、其所有邻接边以及所有邻接顶点的数据 。
- 状态(State):程序的状态由图
- 用GraphLab实现PageRank
- 核心思路:将PageRank的数学公式转换为一个顶点程序。
- 一个典型的顶点程序分为几个阶段:
- Gather阶段:遍历所有入边(in-edges),从邻居顶点收集信息并进行累加。在PageRank中,就是收集邻居的
rank / num_out_neighbors值并求和。 - Apply阶段:使用Gather阶段得到的结果,更新当前顶点自身的数据。在PageRank中,就是根据公式更新自己的
pagerank值。 - Scatter阶段(可选):更新完自身后,可能会需要更新出边(out-edges)或邻居顶点的数据。
- Gather阶段:遍历所有入边(in-edges),从邻居顶点收集信息并进行累加。在PageRank中,就是收集邻居的
- 关键抽象:程序员只需从单个顶点的视角描述计算逻辑,而GraphLab系统则负责调度这些顶点程序的执行、处理并行化、以及在分布式环境下的图划分和节点间通信 。
- 动态调度:Signal机制
- 在GraphLab中,可以通过
engine.signal_all()来将所有顶点加入工作队列,让系统对所有顶点执行一次顶点程序。 - 更高效的方式是异步执行。许多图算法中,图的不同部分收敛速度不同。
- Signal机制:一个顶点程序在执行完毕后,可以调用
context.signal(neighbor_vertex)来动态地、有选择地将其他顶点(通常是它的邻居)加入到未来的工作队列中 。 - 优势:这种方式使得计算可以“按需进行”,只在图上真正需要更新的区域执行计算,从而大大提升了效率,尤其是在迭代直到收敛的算法中。
- 在GraphLab中,可以通过

-
同步与调度策略
- 一致性模型:由于多个顶点程序可能并行执行,它们的“邻域”可能会重叠,从而产生数据竞争。GraphLab允许程序员指定所需的原子性粒度,例如:
- Full consistency:完全串行化,执行一个顶点程序时锁定其整个邻域。
- Edge consistency:只锁定顶点本身和邻接的边。
- Vertex consistency:只锁定顶点本身。
- 调度策略:GraphLab提供了多种调度策略,如:
- Synchronous:同步执行,所有顶点程序在同一“轮次”中读取的都是上一轮次的数据。
- Round-robin:异步执行,顶点程序能看到其他程序最新的更新。
- Graph coloring:通过图着色避免相邻顶点被同时更新。
- 重要启示:在图计算领域,节点的处理顺序不仅影响性能,有时甚至会影响算法的正确性或结果质量。因此,将调度策略的选择权交给程序员是必要且常见的设计 。
- 一致性模型:由于多个顶点程序可能并行执行,它们的“邻域”可能会重叠,从而产生数据竞争。GraphLab允许程序员指定所需的原子性粒度,例如:
优秀DSL的设计原则与图计算优化
这部分从GraphLab的例子中提炼出通用的DSL设计原则,并探讨了图计算的核心性能瓶颈及优化方法。
- 优秀DSL的设计原则
- 抓住重点,贴合领域:系统的代码结构应与领域问题的自然结构相匹配(如图计算以顶点为中心)。最重要的操作应该易于表达且能被系统高效实现。
- 保持简洁:拥有少量但功能强大的核心原语(如GraphLab的“顶点计算”和“signal”)。这让系统可以将优化力量集中在这些核心原语上。
- 支持组合:好的原语应该可以灵活组合,以解决更广泛的问题,甚至是一些最初设计者未曾预料到的应用。
- 图计算的性能瓶颈:内存带宽
- 图计算通常是内存带宽受限的,而不是计算受限的。因为遍历图的边常常导致对内存的随机访问,这使得缓存的效率很低,处理器大部分时间都在等待数据从内存中加载 。
- PageRank算法的算术强度(Arithmetic Intensity)很低,每次求和循环只做一次乘加,却需要访问邻居顶点的数据。
- 因此,优化的关键在于改善数据局部性和减少数据移动。
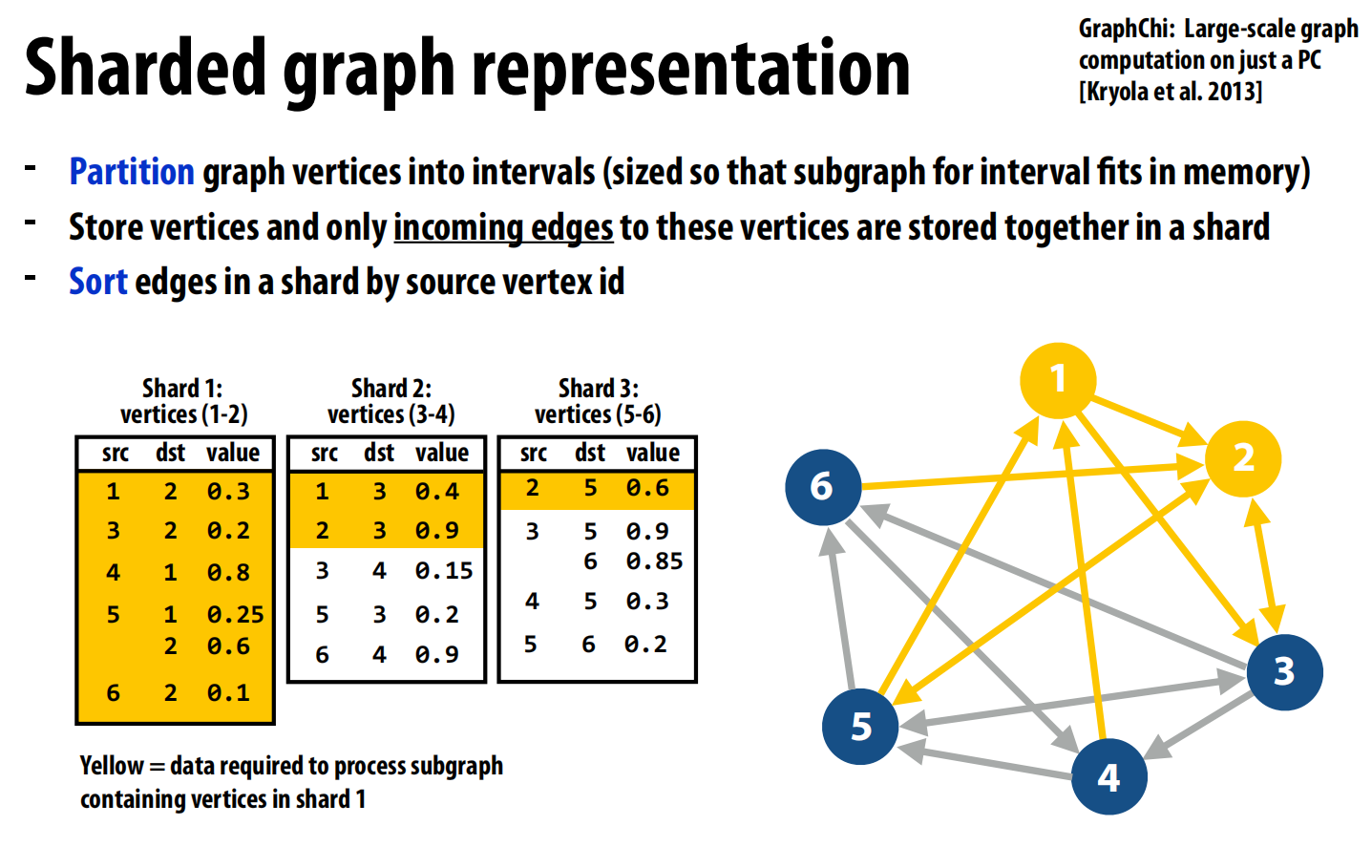
- 优化1:重组图结构以实现流式访问 (GraphChi)
- 问题:对于无法完全载入内存的超大图,随机访问磁盘的性能极差。
- GraphChi的解决方案:提出一种“分片(Sharded)”的图表示法,将随机访问转换为高效的流式访问。
- 将所有顶点
V划分为P个不相交的区间(shard)。 - 每个分片文件
i存储属于区间i的所有顶点,以及所有指向这些顶点的入边。 - 最关键的一步:将每个分片文件中的边,按照其源顶点ID进行排序。
- 将所有顶点
- 效果:通过这种精巧的布局,当系统需要处理分片
i中的顶点时,它只需完整加载分片i,然后从其他所有分片文件中顺序地、像滑动窗口一样读取一小部分连续的数据块即可。这完全避免了对磁盘的随机访问。
- 优化2:图压缩
- 动机:既然图计算是带宽受限的,那么花费一些CPU计算资源来动态解压缩图数据,以减少需要从内存读取的数据量,就是一笔划算的买卖。
- 压缩方法:以一个顶点的出边列表为例:
- 对邻居顶点的ID进行排序。
- 存储ID之间的差值(delta),这通常会产生大量较小的数值。
- 将这些差值根据其大小分组,并使用可变长度编码(如1字节、2字节、4字节)来存储,进一步减少空间占用。

lec22 Deep neural networks
网络结构与评估
高效评估卷积层
- 直接实现:一个卷积层的直接实现通常需要七层嵌套循环,虽然有大量的数据复用机会,但手写优化非常困难 。
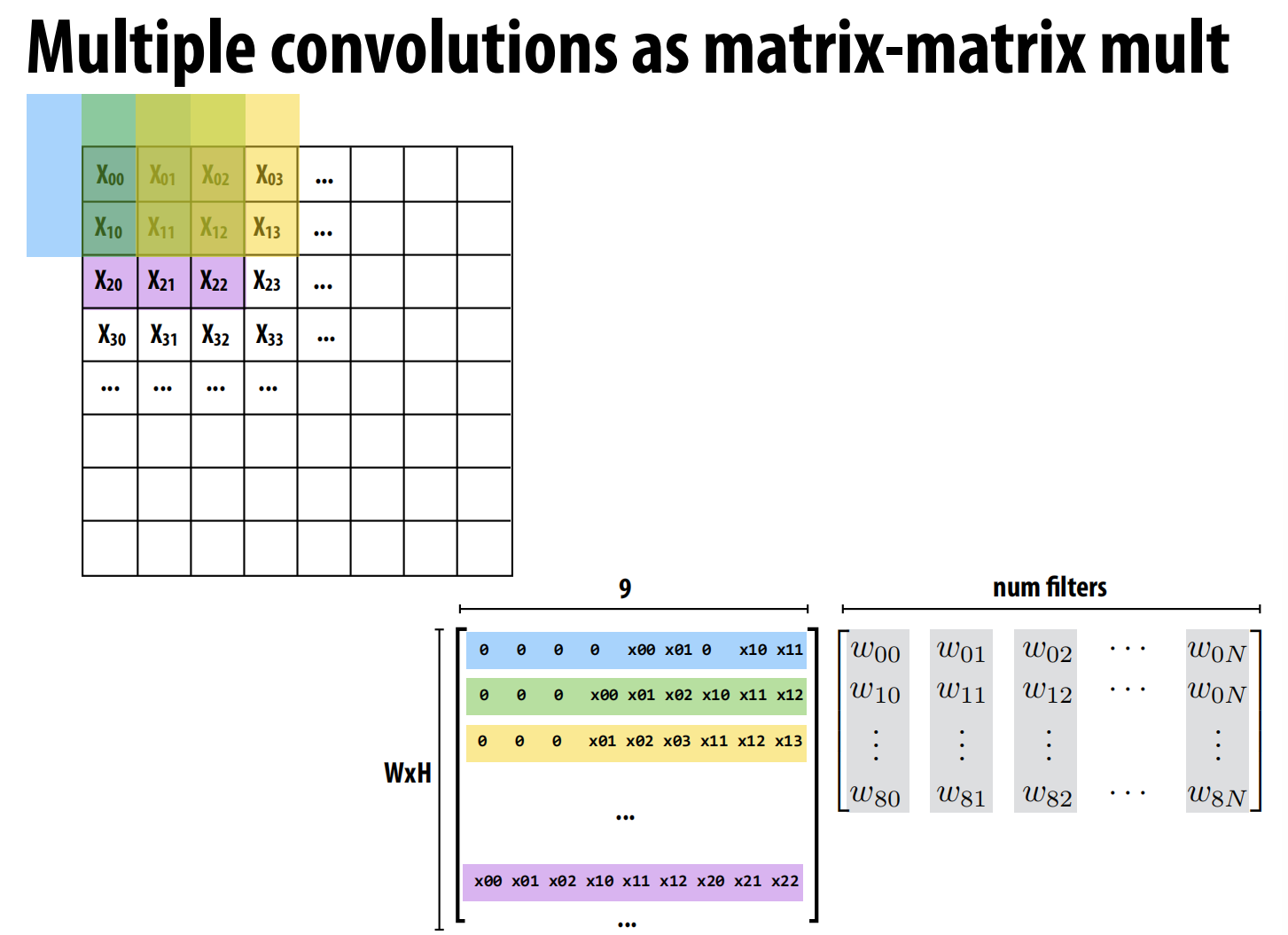
- 优化思路:转换为矩阵乘法(GEMM):
- 卷积运算可以通过一种名为
im2col的技术,巧妙地转换为一个大规模的通用矩阵乘法(GEMM) 。方法:将输入图像中每个卷积窗口覆盖的像素块“拉平”成一个列向量,将所有这些列向量组合起来,形成一个巨大的输入矩阵X。同时,将所有滤波器的权重也排列成一个权重矩阵W。这样,整个卷积层的计算就等价于Y = X * W。 - 下图中右边的矩阵每列就是一个filter,左边矩阵就是对应要乘的东西。
- 卷积运算可以通过一种名为
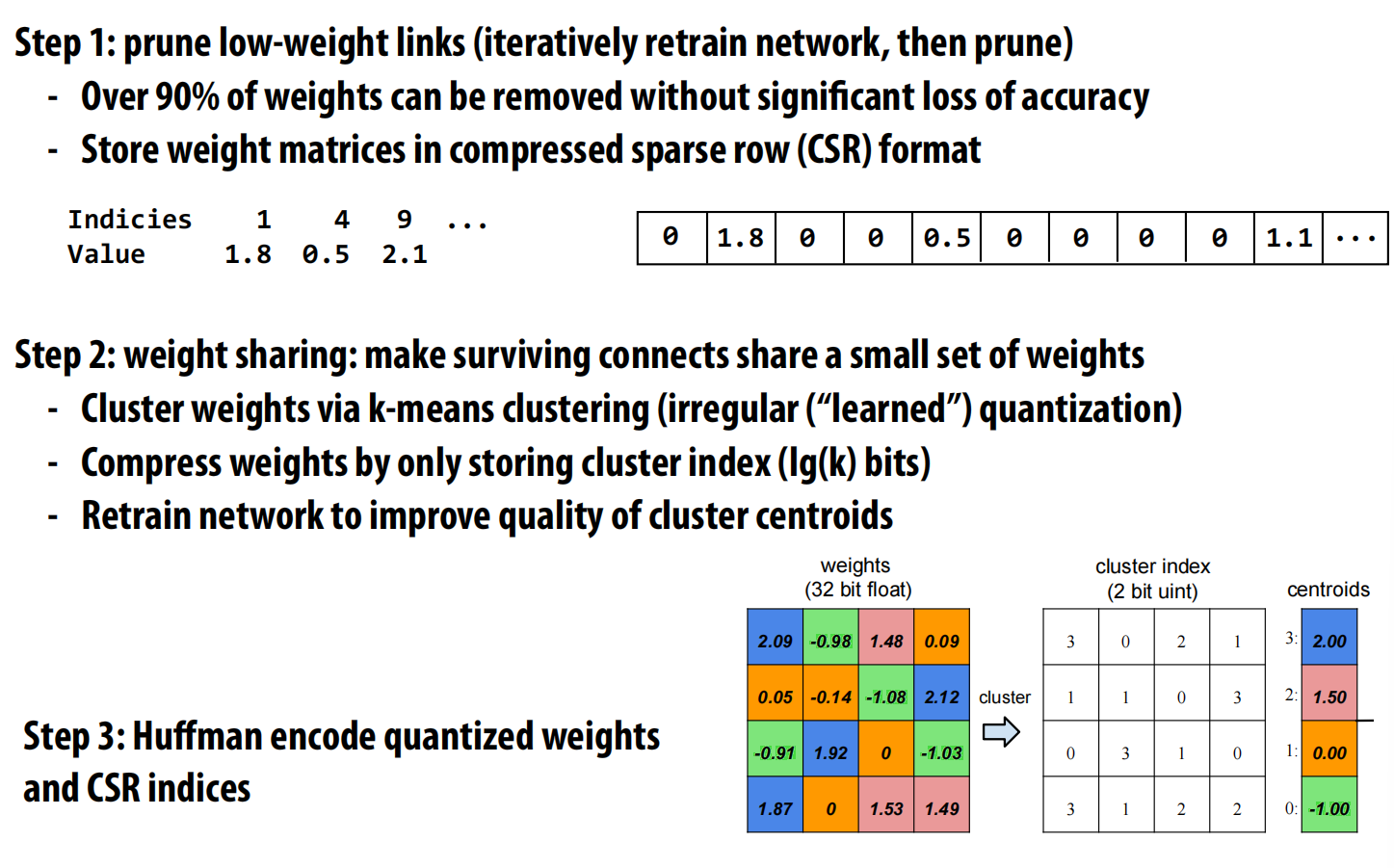
-
内存占用:现代DNN的参数量和中间结果都非常庞大。例如,VGG-16模型的权重参数本身就需要约500MB存储 ,而评估过程中产生的中间激活图则需要更多内存 。
-
网络压缩:为了在移动设备等资源受限的场景下部署大型网络,通常需要进行压缩 。
- 剪枝(Pruning):移除网络中权重较小的连接。
- 量化与权重共享(Quantization & Sharing):将剩余的权重用k-means等方法进行聚类,所有权重都用其所属类别的中心点来代替。
- 霍夫曼编码(Huffman Encoding):对量化后的索引和稀疏矩阵的索引进行无损压缩 。
- CS231n的最后一节课有讲。
硬件与框架
- GPU是目前执行DNN评估性能最好的平台,因为其拥有强大的浮点计算能力,非常适合矩阵乘法这样的高算术强度任务 。
- 新兴架构:为了进一步提升效率,业界正在研发专用硬件,如Google的TPU(Tensor Processing Unit)、支持低精度计算的GPU(如NVIDIA Pascal)、以及FPGA和ASIC方案 。
- 编程框架:为了简化开发,出现了许多流行的DNN框架(如Caffe, TensorFlow, PyTorch等)。它们让开发者可以通过高层API来构建网络拓扑,而底层的繁重计算则调用了为特定硬件(如NVIDIA GPU的cuDNN库)高度优化的内核库 。
网络训练与并行化
- 关键点:在反向传播过程中,计算某一层权重的梯度时,需要用到该层在前向传播时的输入数据 。这意味着,在训练时,必须保存所有中间层的输出,导致内存占用远大于评估过程。
并行化训练
- 训练的挑战:训练过程计算量巨大、内存占用高,并且步骤之间存在依赖(梯度下降的每一步都依赖上一步的结果),并非“易并行”问题 。
- 数据并行(Data Parallelism):这是最常见的并行策略 。
- 方法:将整个模型复制到多个工作节点(或GPU)上。将一个批次(mini-batch)的训练数据均分给各个节点。每个节点独立计算其分到的数据所产生的梯度。
- 同步:所有节点计算完毕后,通过一次全局的归约操作(如All-Reduce)将所有梯度相加,得到总梯度。然后用这个总梯度去同步更新所有节点上的模型参数 。
- 瓶颈:同步归约操作会产生大量的网络通信,成为扩展性的瓶颈。
- 模型并行(Model Parallelism):
- 方法:当单个模型大到无法装入单个节点(或GPU)的内存时,需要将模型本身进行切分,不同的层或同一层的不同部分放到不同的节点上 。
- 通信:在计算过程中,节点间需要频繁地进行细粒度的通信,以传递层与层之间的激活值和梯度 。这对于网络带宽的要求极高。
- 异步训练与参数服务器(Parameter Server):
- 动机:为了解决同步数据并行的通信瓶颈,并利用SGD算法对少量噪声不敏感的特性 。
- 架构:引入一个或多个“参数服务器”节点,专门用于存储和更新全局的模型参数。多个“工作节点”则负责计算梯度 。
- 异步更新:工作节点在本地计算完梯度后,不等其他节点,直接将梯度“推送(push)”给参数服务器。同时,它会从服务器“拉取(pull)”最新的参数来更新自己的本地模型。
- 优势:这种异步方式解耦了计算和通信,大大提高了集群的利用率和吞吐量,但可能会因为使用“过时”的梯度而影响收敛速度。
lec23 MPI, OpenMP, Cilk implementation
Part A: 实现消息传递 (Implementing Message Passing)
这部分的核心是理解线程/进程如何通过网络在独立的地址空间之间交换数据。
消息传递模型抽象
- 核心理念:每个线程(或进程)拥有自己私有的、独立的地址空间 。它们之间无法直接读取对方的变量 。
- 通信方式:唯一的通信方式是**发送(send)和接收(receive)**消息 。
send(data, destination_id, tag):将本地的数据data发送给指定的目标线程,并附上一个可选的标签tag用于区分消息 。recv(buffer, source_id, tag):从指定的源线程接收一个带有匹配标签tag的消息,并存入本地的buffer中 。
- 硬件要求:这种模型不要求硬件支持全局的共享地址空间,只需要节点间能够通信即可 。这使得它非常适合构建由大量独立计算机组成的**集群(cluster)**和超级计算机(如IBM Blue Gene)。
消息传递 vs. 共享地址空间
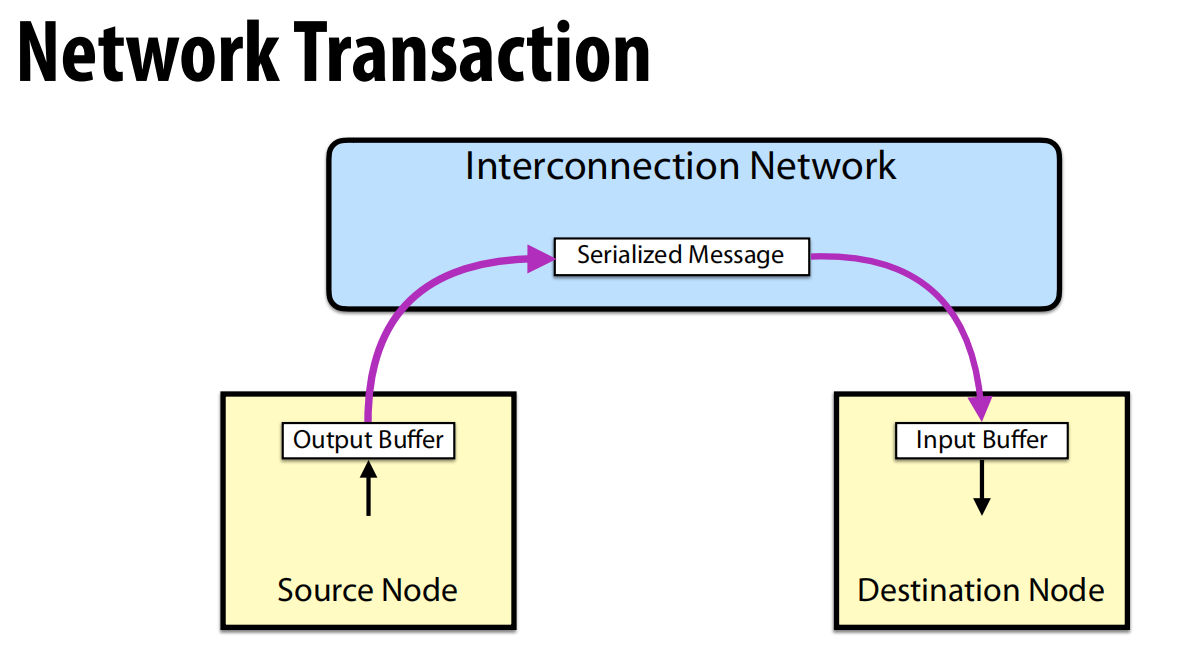
- 消息传递:本质上是一个单向的网络事务(Network Transaction) 。信息从源节点的输出缓冲区流向目标节点的输入缓冲区 。源节点无法直接看到操作在目标节点上是否发生 。
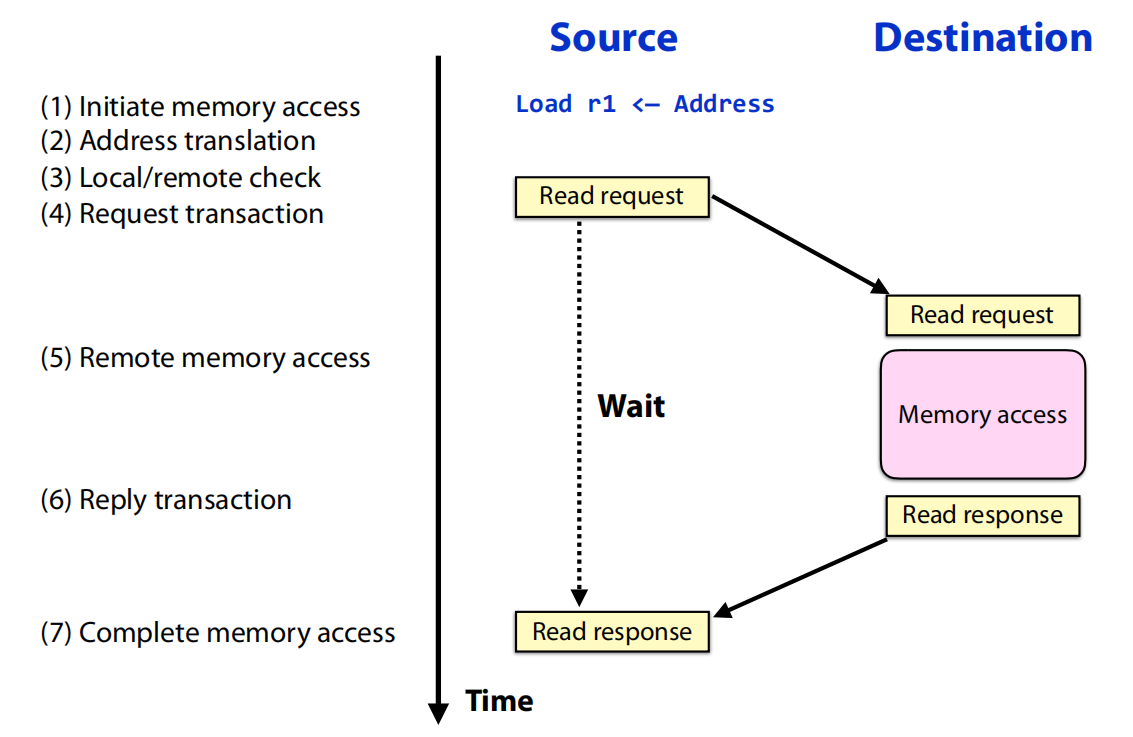
- 共享地址空间(Shared Address Space, SAS):本质上是一个双向的请求/响应(request/response)协议 。例如,一个读操作会发送一个“读请求”,然后等待一个“读响应”返回 。远程操作在逻辑上不需要远程CPU的干预 。
send/recv的实现协议
系统如何实现send和recv?这主要取决于何时进行真正的数据传输,有几种不同的策略。
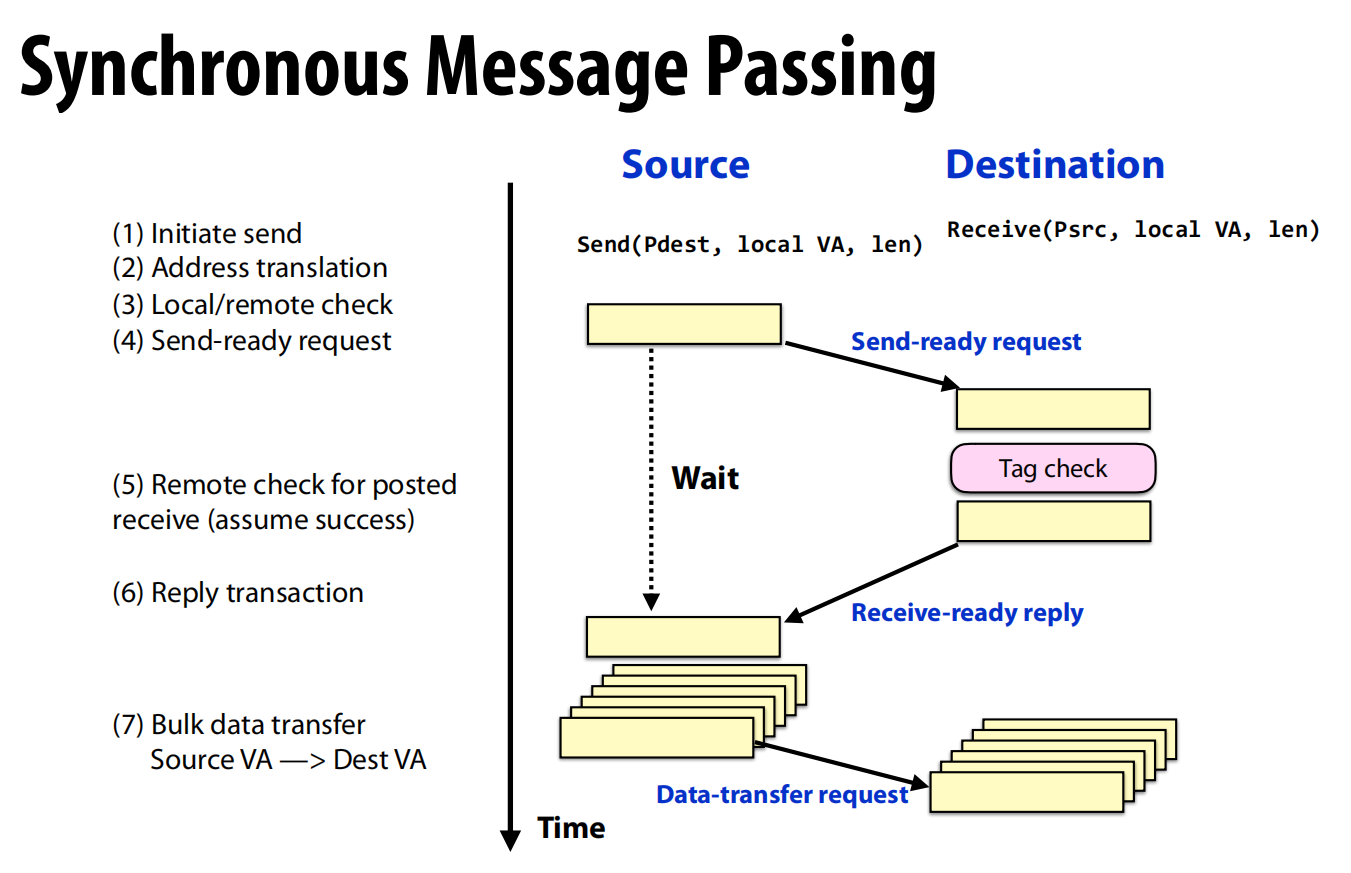
- 同步消息传递 (Synchronous)
- 这是一个**“握手”协议**。
Send方先发送一个“发送就绪”请求 (Send-ready request)。Send方暂停并等待(Wait)。Destination方收到请求后,检查自己是否已经准备好接收(即是否已调用recv),并进行标签匹配。- 匹配成功后,
Destination方回复一个“接收就绪”应答 (Receive-ready reply)。 Send方收到应答后,才开始进行批量数据传输(Data-transfer request)。
- 特点:数据只有在接收方准备好之后才被发送,这避免了在接收端需要大量缓冲 。但缺点是发送方需要长时间等待,延迟较高。
- 这是一个**“握手”协议**。
- 异步消息传递:乐观策略 (Optimistic)
- 这是一个“发射后不管”的策略。
- 过程:
Send方不进行握手,直接将数据和元信息(如tag)打包发送出去 (Data-transfer request) 。- 优点:发送方不会被阻塞,可以立即继续自己的计算 。
- 缺点:如果接收方还没准备好(未调用
recv),那么消息系统必须在接收端分配一个临时缓冲区来存储这些“提前到达”的数据 。
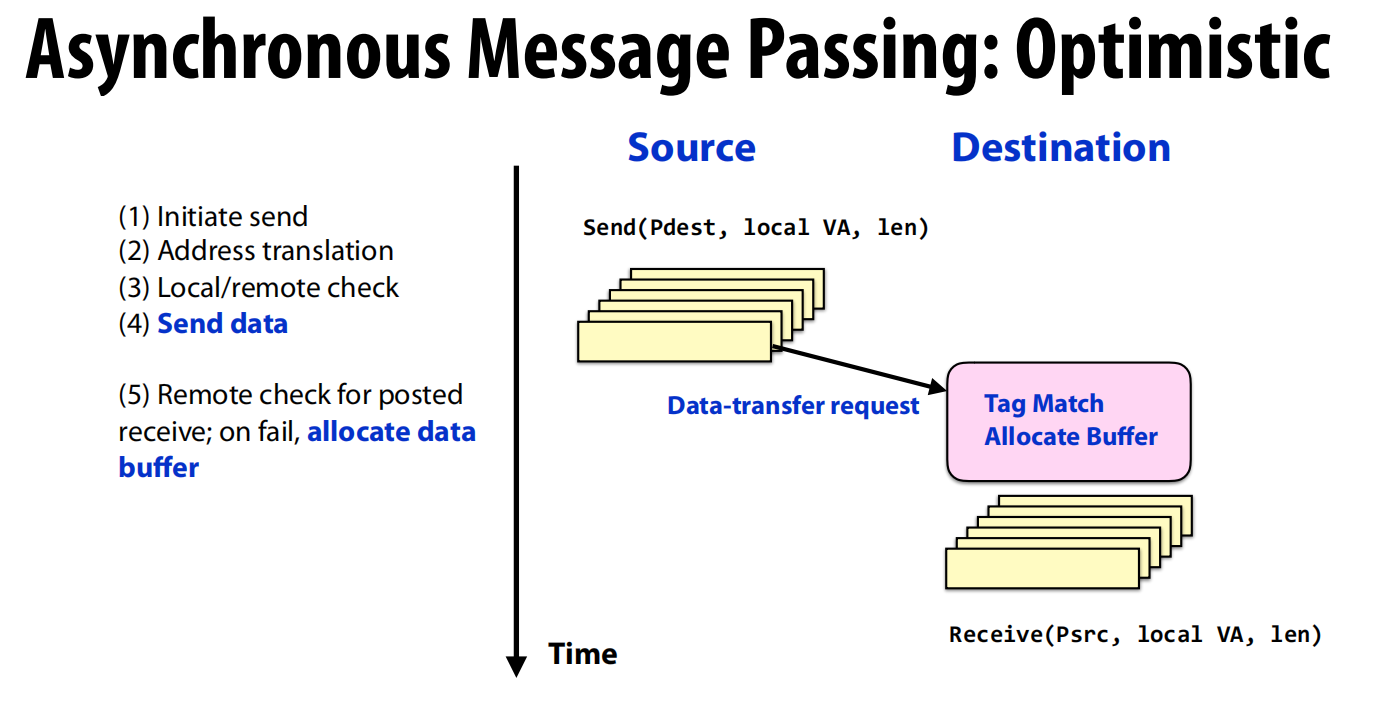
- 异步消息传递:保守策略 (Conservative)
- 这是一种折衷方案。
Send方发送一个“发送就绪”请求 (Send-ready request),然后立即继续自己的计算(Resume computing),不等待回复。Destination方收到请求后,如果还没准备好接收,就先将这个“发送意图”记录下来。- 当
Destination方调用recv并发现有匹配的“发送意图”后,它会主动发送一个“接收就绪”请求 (Receive-ready request) 给Send方。 Send方收到这个请求后,才把数据作为**应答(reply)**发送过去。
- 特点:发送方不会长时间阻塞,同时数据也不会在接收端堆积。缓冲的责任从接收方转移到了发送方。
- 这是一种折衷方案。
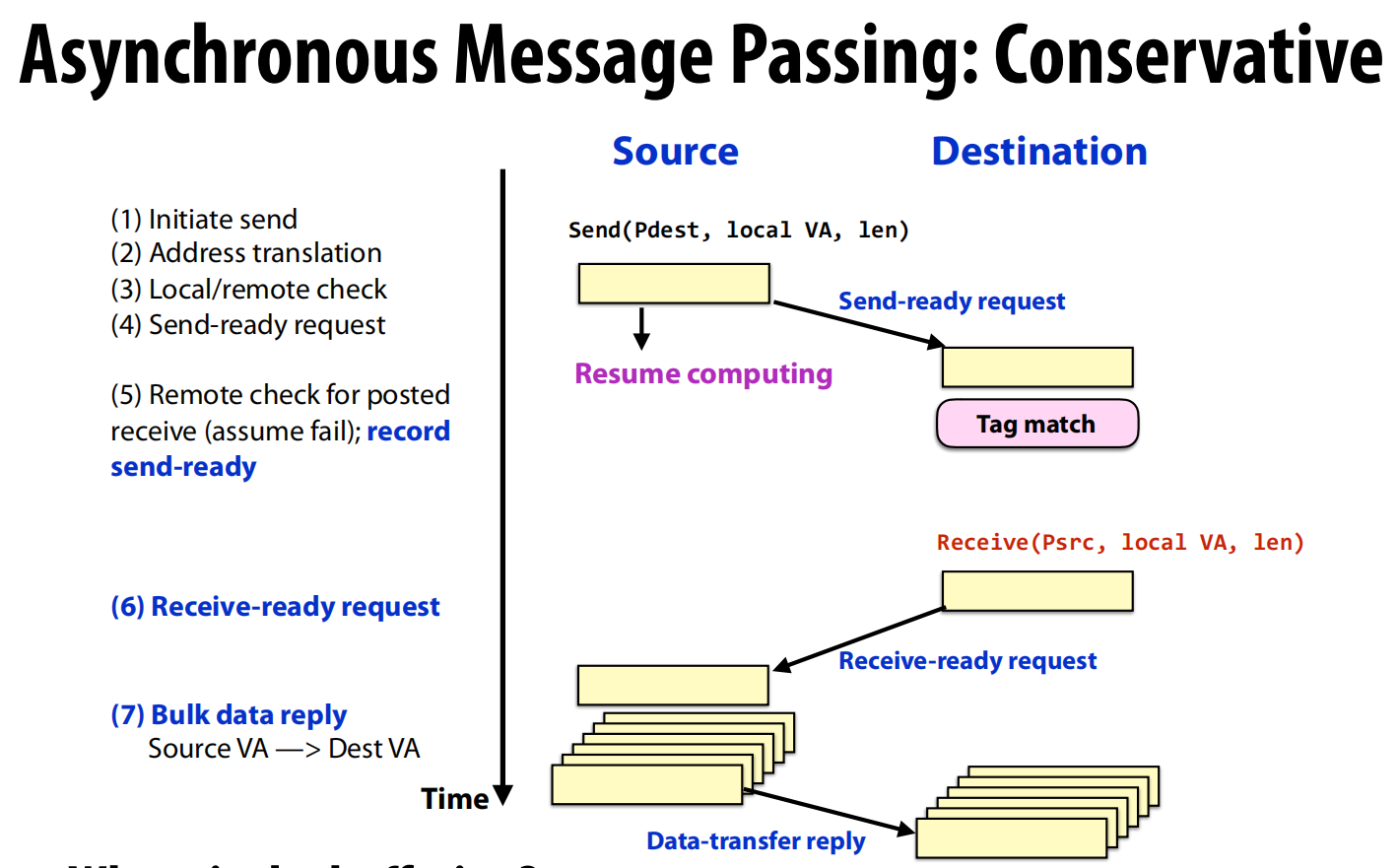
实现挑战
- 输入缓冲区溢出 (Input Buffer Overflow):如果多个发送方同时向一个接收方发送消息(尤其是在乐观策略下),接收方的输入缓冲区很容易被耗尽。
- 解决方案:需要流控机制,如基于**信用(credit)**的方案(发送方在有“信用额度”时才能发送)、反压(backpressure)(当缓冲区满时,网络会向上游传递压力,阻止更多数据流入)或在某些情况下直接丢包 。
- 死锁 (Deadlock):一个经典的“请求-响应”死锁场景。
- 问题:假设节点A和节点B的缓冲区都满了,且里面装的都是发给对方的请求。它们都在等待对方的响应。但因为缓冲区已满,它们无法接收对方的响应来处理自己的请求。同时,因为网络反压,它们也无法发送新的响应。系统就此卡死。
- 解决方案:
- 独立的请求/响应网络:使用物理上或逻辑上(通过虚拟通道)分离的网络来处理请求和响应,确保响应消息总有路可走 。
- 预留缓冲空间:为可能收到的响应预留足够的缓冲空间,保证不会因为缓冲区满而无法接收响应 。
Part B: 实现共享内存运行时 (OpenMP & Cilk)
这部分的核心是揭示像OpenMP和Cilk这样的高级并行编程抽象,是如何被编译器和运行时库翻译成底层线程操作的。
基础:万物基于pthreads
- 无论是OpenMP还是Cilk,它们在类Unix系统上的运行时库最终都是建立在**
pthreads**(POSIX线程)之上的 。 - 它们提供的好处是抽象:程序员使用简单的指令(如
#pragma omp或cilk_spawn),而将创建、管理、调度和同步线程的复杂工作交给了编译器和运行时库。
OpenMP 实现剖析
以一个带reduction的parallel for循环为例,看看编译器做了什么:
- 代码转换 :
- 编译器会将
#pragma omp parallel for ...块转换成对OpenMP运行时库(libkmp)函数的调用。 main函数中原来的循环不见了,取而代之的是_kmpc_begin、_kmpc_fork_call和_kmpc_end等函数调用。_kmpc_fork_call是核心,它会“派生”一个线程团队,并让每个线程去执行一个指定的函数,这个函数被称为微任务(microtask)。
- 编译器会将
- 微任务函数:
- 编译器会为原始的循环体生成一个新的函数(如
main_7_parallel_3)。 - 每个工作线程都会执行这个函数。函数内部:
- 动态调度:通过
_kmpc_dispatch_init和_kmpc_dispatch_next在一个while循环中动态地获取自己要处理的循环迭代块(chunk)。 - 局部归约:每个线程都一个私有的归约变量(如
reduce.r_10_rpr),在处理自己的迭代块时,将结果累加到这个私有变量上。 - 全局归约:所有迭代块处理完毕后,通过
_kmpc_reduce_nowait将所有线程的私有归约变量合并到全局变量上。这个合并过程本身需要同步,对于简单类型可以直接使用硬件原子指令(如lock add或lock cmpxchg),对于复杂类型则使用一个内部锁。
- 动态调度:通过
- 编译器会为原始的循环体生成一个新的函数(如
- 其他原语:
- 屏障(Barriers):运行时内部实现了高效的屏障,可能是线性的,也可能是树形或超立方体等分层结构,以减少同步开销 。
- 原子(Atomics):编译器会尽可能将其翻译成单条硬件原子指令(如x86的
lock add)。如果硬件不支持(例如浮点数的原子加法),则会生成一个使用compare-and-swap的循环来实现 。
Cilk 实现剖析
以经典的斐波那契数列计算fib(n)为例:
1 | int a = cilk_spawn fib(n-1); // 子任务 |
- 核心挑战:如何实现
cilk_spawn?当一个线程(父任务)spawn一个子任务时,它需要能够继续执行后续的代码(即“延续任务”)。 - 实现机制:
setjmp/longjmp:- 编译器将Cilk代码转换成一个控制流图,并使用C标准库中的
setjmp和longjmp来保存和恢复执行状态。 - 过程:
- 在执行
cilk_spawn之前,编译器插入一个setjmp(env)调用。这个调用会将当前的寄存器状态和栈指针保存在一个jmp_buf结构env中。这个被保存的上下文就代表了延续任务的起点。 setjmp首次调用返回0。此时,父任务将子任务(fib(n-1))的信息打包,放入自己的**工作队列(deque)**的底部。- 然后,父任务不会等待,而是直接继续执行延续任务(即计算
fib(n-2))。 - 与此同时,一个空闲的“工作者线程(worker)”会发现父任务队列中有新任务,于是它会“偷走(steal)”这个子任务(
fib(n-1))并开始执行。 cilk_sync:当父任务执行到cilk_sync时,它会检查所有它派生出去的子任务是否都已完成。如果没有,它会暂停当前的工作,并也去其他线程的队列中偷任务来做,直到自己的所有子任务都完成,它才会通过longjmp跳回到cilk_sync之后的位置继续执行。
- 在执行
- 编译器将Cilk代码转换成一个控制流图,并使用C标准库中的
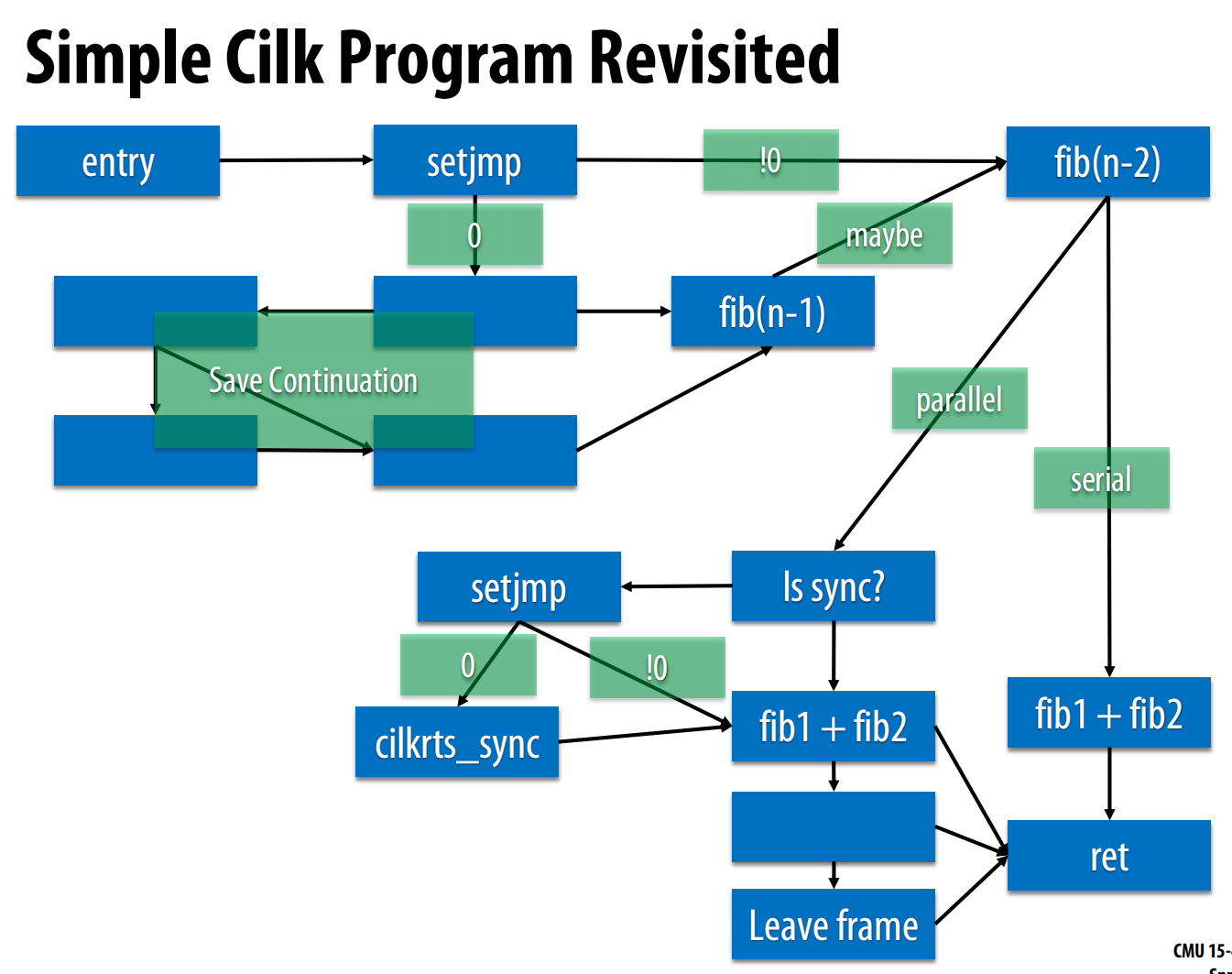
- 工作窃取(Work Stealing):每个工作者线程都有一个双端队列(deque)。它总是在自己队列的头部取任务(LIFO),但当队列为空时,它会随机选择另一个线程,并从其队列的尾部偷任务(FIFO)。这种策略被证明在理论和实践上都非常高效。
线程局部存储 (Thread Local Storage)
- 像Cilk的工作队列、OpenMP的线程ID等这些每个线程独有的数据,是通过**线程局部存储(TLS)**来实现的。
- 这是一种操作系统和编译器提供的机制(如C11的
_Thread_local关键字),它能为每个线程创建和维护一个变量的私有副本 。